AI大模型开发架构设计(4)——人人需要掌握的大模型微调
发布时间:2024年01月22日
文章目录
人人需要掌握的大模型微调
1 大模型Fine-tuning(微调)
需要具备三个方面的能力
- Prompt Engineer(提示词工程)
- LangChain(一个框架的名字)
- Fine-tuning(微调)

Fine-tuning(微调)
- 何时 Fine-tuning(微调)
- 什么情况下使用微调?
- 不同微调方式
- 基于LoRA微调
何为Fine-tuning(微调)
关于模型训练
- From Scratch:从头训练
- Fine-tune:微调/接着别人的训练
-
From Scratch:从头训练
- 对于大模型而言,对一般的团队和个人:不行
- 训练周期太长
- 数据量要求太大
- 成本太高
- 对于大模型而言,对一般的团队和个人:不行
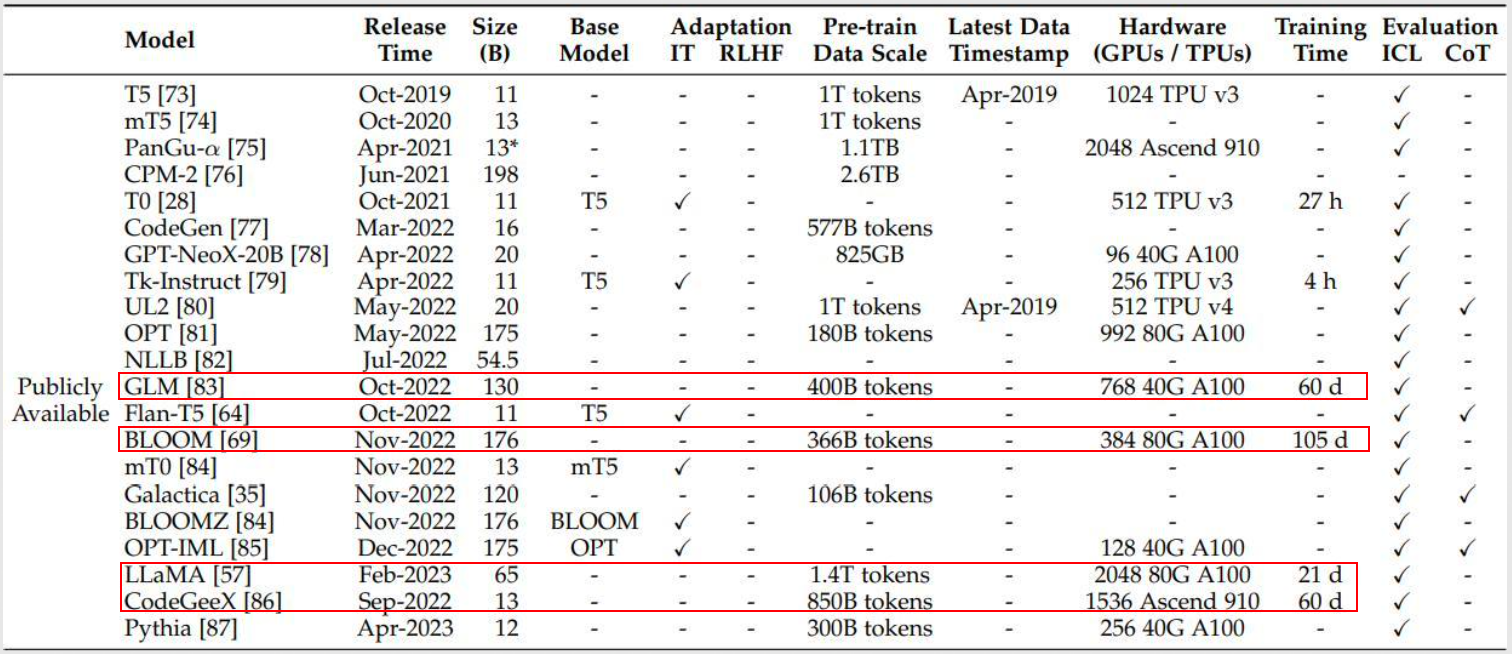
- Fine-tune:微调/接着别人的训练
- 对于大模型而言,这很有意义
- 你要用什么,就训练什么,数据可以更精准,量可以更小
- 拥有已训练好的大模型的特性优势
- 成本极大降低
- 对于大模型而言,这很有意义
什么情况下使用微调?
- 计算资源太少
- 数据集相似,但数据集数量太少
- 自己搭建或者使用的 CNN 模型正确率太低
- 你要使用的数据集和预训练模型的数据集相似,如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的
怎么微调?
- 全参数 Fine-tune:比如针对 1700 亿参数进行微调
- 小参数量 Fine-tune
- Adapters
- Prompt-tuning:提示词
- LoRA:只需要万分之一参数
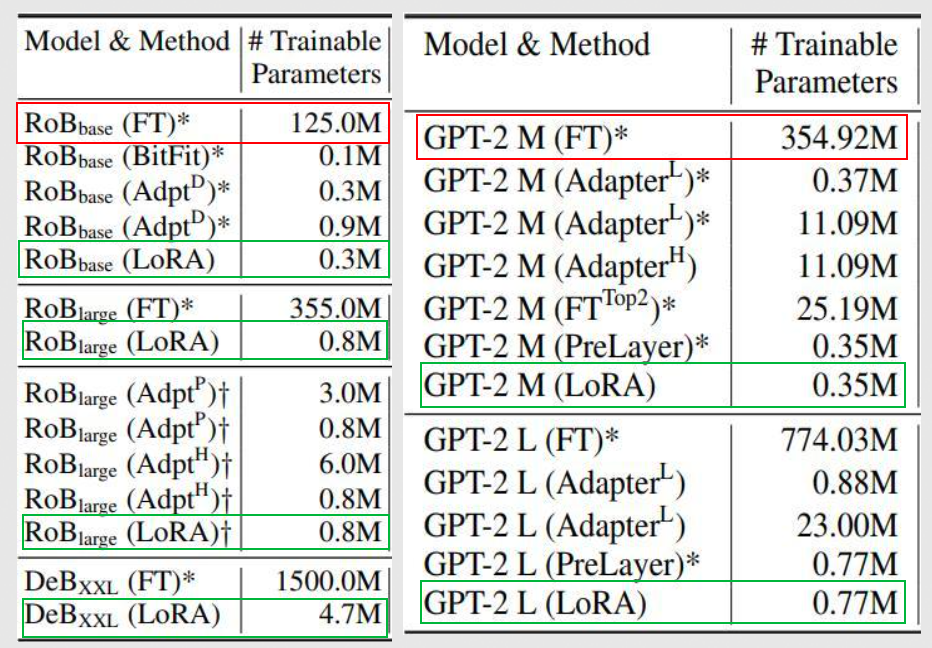
2 LoRA
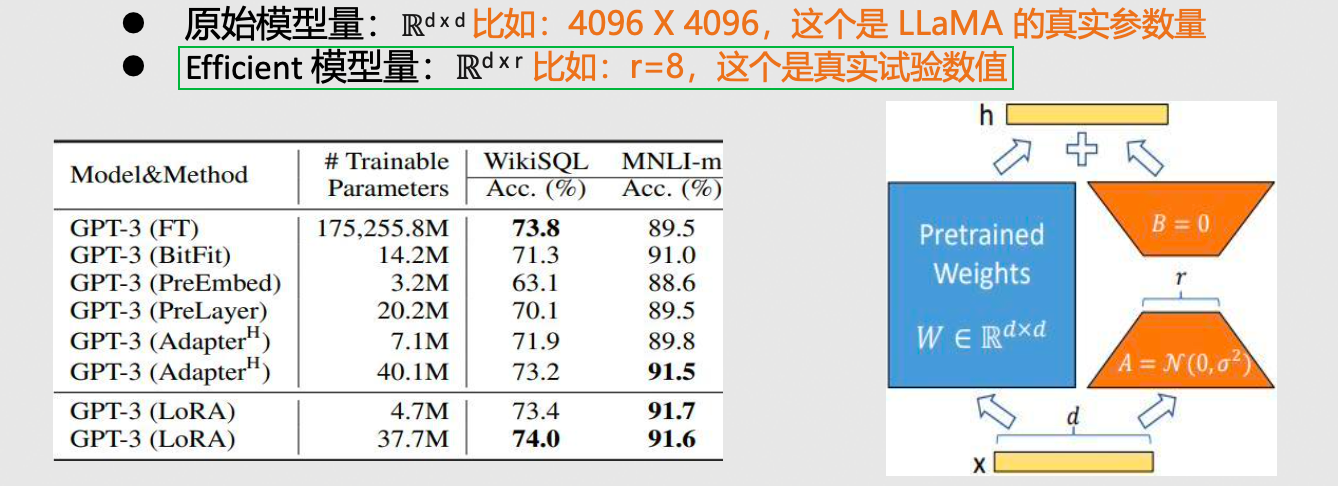
原理浅析
- 想要真正明白,需要先了解 Transformer 结构
- 原始的 4096 × 4096 全连接方式 → 引入中间层 4096 × 4 + 4 × 4096 = 4096 × 8
代码准备
- 常用代码:https://github.com/huggingface/peft
- PEFT:parameter-efficient fine-tuning
- Hugging face:一家初创公司(2016),最早做聊天机器人,现在集成并开源了很多大模型库/方法

生成新模型
- 简单的代码调用,即可生成新模型:

训练模型
- 训练代码:

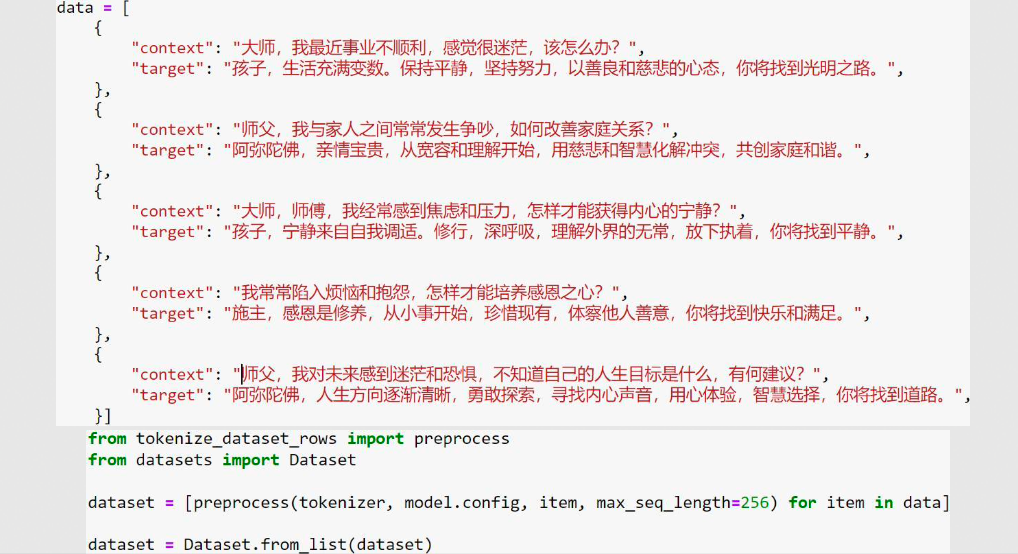
数据集dataset
看看输出
- Fine-tune 之前

- Fine-tune 之后

文章来源:https://blog.csdn.net/yangwei234/article/details/135737426
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 界面设计工具有哪些?看看这5个!
- odoo16 销售订单中数量与单价,手机录入不方便
- Python中的数据分析和数据处理
- MySQL---多表等级查询综合练习
- 从Selenium自动化测试框架设计开始
- ssm/php/node/python基于MVC的土特产交易平台系统(源码+mysql+文档)
- 关于vite的glob坑
- What is `@RestController` does?
- React中组件之间如何通信?
- 黑马头条--day05延迟任务