作物叶片病害识别系统
介绍
-
由于植物疾病的检测在农业领域中起着重要作用,因为植物疾病是相当自然的现象。
-

-
如果在这个领域不采取适当的护理措施,就会对植物产生严重影响,进而影响相关产品的质量、数量或产量。植物疾病会引起疾病的周期性爆发,导致大规模死亡。这些问题需要在初期解决,以挽救人们的生命和金钱。
-
自动检测植物疾病是一个重要的研究课题,因为它可以在植物叶片上出现病征时在非常早期就监测到大面积的农作物,从而检测疾病的症状。
-
农田业主和植物护理者(比如,在苗圃中)可以通过早期检测疾病获得很大的好处,以防止更糟糕的情况发生在他们的植物上,并让人类知道应该预先做什么来使其按照预期工作,以防止更糟糕的情况发生在他身上。
目的
- 这使机器视觉能够提供基于图像的自动检验和过程控制。
- 相比之下,视觉识别是劳动密集型的、不太准确的,只能在小范围内进行。该项目涉及使用Python设计的自我设计的图像处理算法和技术,以从叶片中分割出疾病,并使用机器学习的概念对植物叶片进行分类,以健康或感染状态。
- 通过这种方法,植物疾病可以在初期阶段被识别出来,可以使用害虫和感染控制工具来解决害虫问题,同时最小化对人和环境的风险。
步骤
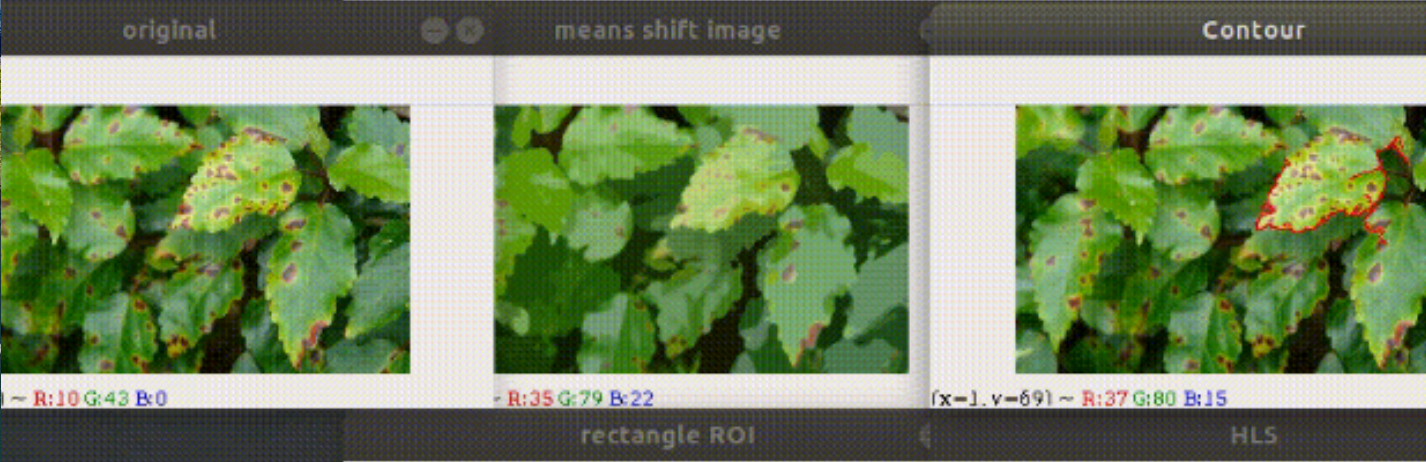
在初始步骤中,选择了所有叶样本的RGB图像。所提出系统的步骤:
- RGB图像采集;
- 将输入图像从RGB格式转换为HSI格式;
- 遮蔽绿色像素;
- 去除遮蔽的绿色像素;
- 分割组件;
- 获取有用的片段;
- 评估分类的特征参数;
- 为疾病检测配置SVM。
- 颜色转换:
HSI(色调、饱和度、强度)颜色模型是一种流行的颜色模型,因为它基于人的感知。转换后,仅考虑HSI颜色空间的H(色调)分量,因为它为我们提供所需的信息。 - 遮蔽绿色像素: 这是因为绿色像素代表叶片的健康区域。根据指定的阈值值遮蔽绿色像素。
分割:
通过将受感染部分与其他类似颜色的部分(如看起来像疾病的棕色叶子分支)分割出叶子的感染部分,这些部分在遮蔽图像中被考虑在内,并被过滤。所有进一步的图像处理都是在此阶段定义的感兴趣区域(ROI)上进行的。
分类:
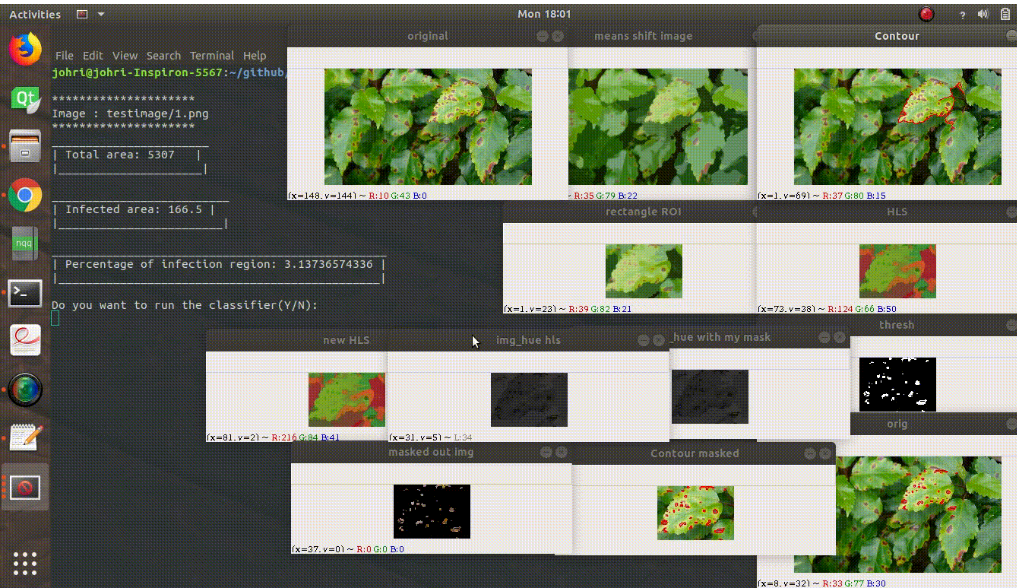
从之前的结果中,我们分析和评估诸如叶片面积、叶片感染百分比、叶子周长等特征参数,以及所有叶片图像的SVM分类器。
安装
cd file
安装一些所需的pip包,这些包在requirements.txt文件中指定。
pip3 install -r requirements.txt
或
sudo python3 setup.py install
就是这样。您已准备好测试应用程序了。
数据集创建
在叶采样器目录中运行:
python3 leafdetectionALLsametype.py -i .
或
python3 leafdetectionALLmix.py -i .
leafdetectionALLsametype.py
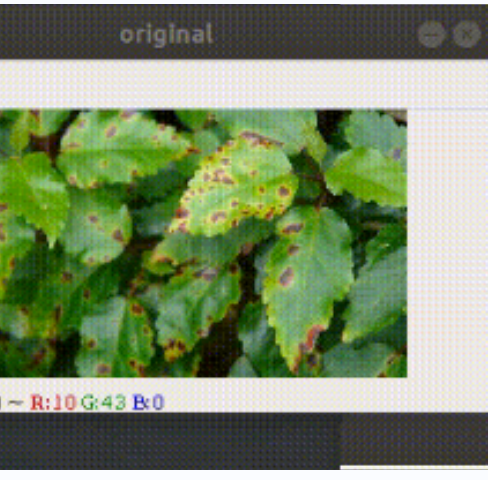
原图
用于在一个相同类别的图像(例如所有图像都感染了)上运行,而leafdetectionALLmix.py 用于为叶子图像的两个类别(感染/健康)创建数据集。请注意:代码设置为仅运行在指定目录中存在的 .jpg、.jpeg 和 .png 文件格式图像上。如果您希望,可以通过将其引入两个文件的第52行的条件语句中来添加更多文件格式支持。
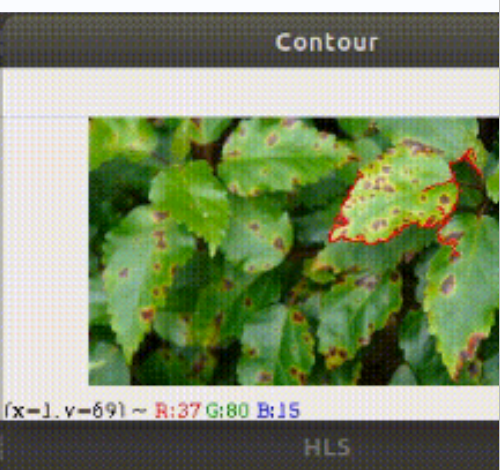
检测结果图
#代码 运行
运行以下代码:
python3 GUIdriver.py
其中{浏览}用于选择分类器的输入图像文件。
该代码运行两个文件:
首先,main.py用于图像分割和特征提取。
其次,main.py调用classifier.py对输入图像中的叶子进行分类,以确定其是否“感染”或“健康”。
重要代码
# 企鹅1309399183
while True:
if n == ord('y'or'Y'):
fieldnames = ['fold num', 'imgid', 'feature1', 'feature2', 'feature3']
print ('Appending to ' + str(filename)+ '...')
try:
log = pd.read_csv(filename)
logfn = int(log.tail(1)['fold num'])
foldnum = (logfn+1)%10
L = [str(foldnum), imgid, str(Tarea), str(Infarea), str(perimeter)]
my_df = pd.DataFrame([L])
my_df.to_csv(filename, mode='a', index=False, header=False)
print ('\nFile ' + str(filename)+ ' updated!' )
except IOError:
if directory not in os.listdir():
os.system('mkdir ' + directory)
foldnum = 0
L = [str(foldnum), imgid, str(Tarea), str(Infarea), str(perimeter)]
my_df = pd.DataFrame([fieldnames, L])
my_df.to_csv(filename, index=False, header=False)
print ('\nFile ' + str(filename)+ ' updated!' )
finally:
import classifier
endprogram()
elif n == ord('n' or 'N') :
print ('File not updated! \nSuccessfully terminated!')
break
else:
print ('invalid input!')
break
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux安装ossutil工具且在Jenkins中执行shell脚本下载文件
- 主动轮廓——计算机视觉中的图像分割方法
- 链表Linklist操作
- 医院影像科PACS系统源码,医学影像系统,支持MPR、CPR、MIP、SSD、VR、VE三维图像处理
- 设计模式之-迭代器模式,快速掌握迭代器模式,通俗易懂的讲解迭代器模式以及它的使用场景
- imgaug库图像增强指南(32):塑造雪景效果的视觉魔法
- 设计模式-空对象模式
- 自制脚本工具
- 全国职业院校技能大赛“大数据应用开发”赛项说明
- 网络基础笔记(四)ospf