softmax回归
softmax回归
我们从一个图像分类问题开始。 假设每次输入是一个2×2的灰度图像。 我们可以用一个标量表示每个像素值,每个图像对应四个特征x1,x2,x3,x4。 此外,假设每个图像属于类别“猫”“鸡”和“狗”中的一个。
但是一般的分类问题并不与类别之间的自然顺序有关。 幸运的是,统计学家很早以前就发明了一种表示分类数据的简单方法:独热编码(one-hot encoding)。 独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。 在我们的例子中,标签�将是一个三维向量, 其中(1,0,0)对应于“猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗”:

为了估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。
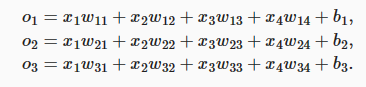
与线性回归一样,softmax回归也是一个单层神经网络。 由于计算每个输出o1、o2和o3取决于 所有输入x1、x2、x3和x4, 所以softmax回归的输出层也是全连接层。

为了更简洁地表达模型,我们仍然使用线性代数符号。 通过向量形式表达为o=wx+b, 这是一种更适合数学和编写代码的形式。 由此,我们已经将所有权重放到一个3×4矩阵中。 对于给定数据样本的特征x, 我们的输出是由权重与输入特征进行矩阵-向量乘法再加上偏置b得到的。
softmax运算
要将输出视为概率,我们必须保证在任何数据上的输出都是非负的且总和为1。 此外,我们需要一个训练的目标函数,来激励模型精准地估计概率。 例如, 在分类器输出0.5的所有样本中,我们希望这些样本是刚好有一半实际上属于预测的类别。 这个属性叫做校准(calibration)。
社会科学家邓肯·卢斯于1959年在选择模型(choice model)的理论基础上 发明的softmax函数正是这样做的: softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质。 为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。 为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。如下式:
让每个求幂后的结果除以它们的总和。如下式:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 政务大数据能力平台建设方案:文件全文30页,附下载
- 小型机故障案例
- 自动驾驶HWP的功能定义
- ip数据库.
- 架构师常用的ChatGPT通用提示词模板
- uniapp中如何使用image图片
- Python数据分析案例34——IMDB电影评论情感分析(Transformer)
- 【银联支付申请流程】一篇搞定,让你的生意飞起来!
- css的元素显示模式(有单行文字垂直居中,侧边栏等案例)
- 3个加密和保护U盘数据的工具,保障你的数据安全