19、Kubernetes核心技术 - 资源限制
目录
一、概述
当定义 Pod 时,我们可以定义多个容器,我们知道,容器的程序要运行肯定是要占用一定资源的,比如CPU和内存等,默认情况下,Pod运行没有CPU和内存的限额。如果不对某个容器的资源进行限制,那么它就可能消耗大量资源,导致其他容器无法运行。
针对这样情况,kubernetes提供了对内存和CPU资源进行配额的机制,这种机制主要通过配置spec.containers[].resources选项实现,resources提供了2个主要的参数,如下:
- limits
用于限制运行时容器的最大占用资源,当容器占用资源超过limit时就会被终止,并将进行重启。当为容器指定了 limit 资源时,kubelet 就可以确保运行的容器不会使用超出所设限制的资源,设置为0表示对使用的资源不做限制, 可无限的使用。
- requests
用于设置容器需要的最小资源,如果环境资源不够,容器将无法启动。当为Pod中的容器指定了 request资源时,调度器( kube-scheduler )就使用该信息来决定将 Pod 调度到哪个节点上,只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点。
如果 Pod 运行所在的节点具有足够的可用资源,容器可能(且可以)使用超出对应资源 request 属性所设置的资源量。不过,容器不可以使用超出其资源 limit 属性所设置的资源量。
例如,如果你将容器的 memory 的请求量设置为 256 MiB,而该容器所处的 Pod 被调度到一个具有 8 GiB 内存的节点上,并且该节点上没有其他 Pod 运行,那么该容器就可以尝试使用更多的内存。
如果你将某容器的 memory 限制设置为 4 GiB,kubelet (和容器运行时)就会确保该限制生效。 容器运行时会禁止容器使用超出所设置资源限制的资源。 例如:当容器中进程尝试使用超出所允许内存量的资源时,系统内核会将尝试申请内存的进程终止, 并引发内存不足(OOM)错误。
针对每个容器,你都可以指定其资源限制和请求,包括如下选项:
pod.spec.containers.resources:
requests: <map[string]string>
cpu: // 定义创建容器时预分配的CPU资源
memory: // 定义创建容器时预分配的内存资源
limits: <map[string]string>
cpu: // 定义cpu的资源上限
memory: // 定义内存的资源上限二、Kubernetes 中的资源单位
2.1、CPU资源单位
CPU 资源的限制和请求以 “cpu” 为单位。 在 Kubernetes 中,一个 CPU 等于 1 个物理 CPU 核 或者 1 个虚拟核, 取决于节点是一台物理主机还是运行在某物理主机上的虚拟机。
也可以表达带小数 CPU 的请求。 当定义一个容器,将其 spec.containers[].resources.requests.cpu 设置为 0.5 时, 所请求的 CPU 是请求 1.0 CPU 时的一半。 对于 CPU 资源单位,数量 表达式 0.1 等价于表达式 100m,可以看作 “100 millicpu”(“一百毫核”)。
CPU 资源总是设置为资源的绝对数量而非相对数量值。 例如,无论容器运行在单核、双核或者 48-核的机器上,500m CPU 表示的是大约相同的计算能力。
2.2、内存资源单位
以字节为单位。可以以整数表示,或者以10为底数的指数的单位(E、P、T、G、M、K)来表示, 或者使用对应的 2 的幂数:Ei、Pi、Ti、Gi、Mi、Ki(Ei、Pi、Ti、Gi、Mi、Ki)来表示。
三、Pod资源限制
vim resource-limit.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits: # 限制最大资源,上限
memory: 1Gi # 定义内存的资源上限
cpu: 1 # 定义cpu的资源上限
requests: #请求资源(最小,下限)
memory: 256Mi # 定义创建容器时预分配的内存资源
cpu: 100m # 定义创建容器时预分配的CPU资源cpu的单位m:代表“千分之一核心”,譬如100m的含义是指100/1000核心,即10%,表示每 1000 毫秒容器可以使用的 CPU 时间总量为 0.1*1000 毫秒。
注意:Gi和G,Mi和M的区别,官网解释:Mi表示(1Mi=1024×1024),M表示(1M=1000×1000)(其它单位类推, 如Ki/K Gi/G);
如上,nginx容器的request值为0.1个cpu和256MiB内存,nginx容器的limit 值为1个cpu和1GiB内存。
创建并查看pod:
$ kubectl apply -f resource-limit.yaml
deployment.apps/nginx created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-8c777cc7-6jj8x 1/1 Running 0 9s 192.168.1.3 node01 <none> <none>可以看到,pod被调度到node01节点,我们查看节点描述信息:
$ kubectl describe nodes node01 ?
?
四、namespace资源限制
4.1、为命名空间配置内存和 CPU 配额
默认情况下, Kubernetes 集群上的容器运行使用的计算资源没有限制。 使用 Kubernetes 资源配额, 管理员(也称为集群操作者)可以在一个指定的命名空间内限制集群资源的使用与创建。 在命名空间中,一个 Pod 最多能够使用命名空间的资源配额所定义的 CPU 和内存用量。
如果需要为命名空间设置容器可用的内存和 CPU 总量,可以通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。使用 ResourceQuota 限制命名空间中所有容器的内存请求总量、内存限制总量、CPU 请求总量和CPU 限制总量。
需要理解的是ResourceQuota是给命名空间去配额,而不是给pod去配额,是所有pod运行的总量和。
下面是 ResourceQuota 的示例清单:
vim resource-quota.yaml?
apiVersion: v1
kind: ResourceQuota
metadata:
name: my-resource-quota
spec:
hard:
requests.cpu: "1" # 所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。
requests.memory: 1Gi # 所有非终止状态的 Pod,其内存需求总量不能超过该值。
limits.cpu: "2" # 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。
limits.memory: 2Gi # 所有非终止状态的 Pod,其内存限额总量不能超过该值。创建并查看 ResourceQuota 详情:
$ kubectl create -f resource-quota.yaml --namespace=default
resourcequota/my-resource-quota created
$ kubectl get resourcequota my-resource-quota --namespace=default --output=yaml
apiVersion: v1
kind: ResourceQuota
metadata:
creationTimestamp: "2023-01-30T05:12:54Z"
name: my-resource-quota
namespace: default
resourceVersion: "1753"
uid: f6170a87-f22f-45f7-9dac-c721f9eb1a44
spec:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
status:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
used:
limits.cpu: "0"
limits.memory: "0"
requests.cpu: "0"
requests.memory: "0"ResourceQuota 在 default 命名空间中设置了如下要求:
- 在该命名空间中的每个 Pod 的所有容器都必须要有内存请求和限制,以及 CPU 请求和限制。
- 在该命名空间中所有 Pod 的内存请求总和不能超过 1 GiB。
- 在该命名空间中所有 Pod 的内存限制总和不能超过 2 GiB。
- 在该命名空间中所有 Pod 的 CPU 请求总和不能超过 1 cpu。
- 在该命名空间中所有 Pod 的 CPU 限制总和不能超过 2 cpu。
接下来,我们创建一个Pod,清单如下:vim quota-mem-cpu-nginx-pod.yaml?
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"创建并查看Pod:
$ kubectl apply -f quota-mem-cpu-nginx-pod.yaml
pod/nginx created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 17s 192.168.1.3 node01 <none> <none>?可以看到,Pod处于正常运行状态,接着再次查看 ResourceQuota 的详情:
$ kubectl get resourcequota my-resource-quota --namespace=default --output=yaml
apiVersion: v1
kind: ResourceQuota
metadata:
creationTimestamp: "2023-01-30T05:12:54Z"
name: my-resource-quota
namespace: default
resourceVersion: "1943"
uid: f6170a87-f22f-45f7-9dac-c721f9eb1a44
spec:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
status:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
used:
limits.cpu: 800m
limits.memory: 800Mi
requests.cpu: 400m
requests.memory: 600Mi输出结果显示了配额以及有多少配额已经被使用,可以看到 Pod 的内存和 CPU 请求值及限制值没有超过配额。
我们再次尝试创建另外一个Pod,清单如下:vim quota-mem-cpu-redis-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
resources:
limits:
memory: "1Gi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"在清单中,你可以看到 Pod 的内存请求为 700 MiB。 请注意新的内存请求与已经使用的内存请求之和超过了内存请求的配额: 600 MiB + 700 MiB > 1 GiB。
尝试创建 Pod:
$ kubectl apply -f quota-mem-cpu-redis-pod.yaml
Error from server (Forbidden): error when creating "quota-mem-cpu-redis-pod.yaml": pods "redis" is forbidden: exceeded quota: my-resource-quota, requested: requests.memory=700Mi, used: requests.memory=600Mi, limited: requests.memory=1Gi可以看到,第二个 Pod 不能被创建成功。输出结果显示创建第二个 Pod 会导致内存请求总量超过内存请求配额。
4.2、为命名空间配置默认的内存请求和限制
如果想对命名空间中的单个容器而不是所有容器进行限制,需要使用 LimitRange对象。
LimitRange 是限制命名空间内可为每个适用的对象类别 (例如 Pod 或 PersistentVolumeClaim) 指定的资源分配量(限制和请求)的策略对象。
一个 LimitRange(限制范围) 对象提供的限制能够做到:
- 在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
- 在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
- 在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
- 设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
当某命名空间中有一个 LimitRange 对象时,将在该命名空间中实施 LimitRange 限制。
以下为 LimitRange 的示例清单。 清单中声明了默认的内存请求和默认的内存限制。
vim memory-default.yaml?
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container在default命名空间创建限制范围:??
$ kubectl create -f memory-default.yaml --namespace=default
limitrange/mem-limit-range created如上,如果我们在default命名空间中创建Pod,并且该 Pod 中所有容器都没有声明自己的内存请求和内存限制,那么控制面会将内存的默认请求值 256MiB 和默认限制值 512MiB 应用到 Pod 上。
以下为只包含一个nginx容器的 Pod 的清单,该容器没有声明内存请求和限制。
vim nginx-without-resource.yaml?
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx?创建并查看pod:
$ kubectl apply -f nginx-without-resource.yaml
deployment.apps/nginx created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-748c667d99-gq5rs 1/1 Running 0 13s ?
?
可以看到,输出显示nginx容器已经被指定一个默认的最小内存请求256 MiB和一个默认的最大内存限制512 Mib。
4.3、为命名空间配置默认的CPU请求和限制
以下为 LimitRange 的示例清单。 清单中声明了默认 CPU 请求和默认 CPU 限制。
vim cpu-default.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Container在命名空间 default中创建 LimitRange 对象:
$ kubectl create -f cpu-default.yaml --namespace=default
limitrange/cpu-limit-range created如果在 default命名空间创建一个Pod,并且该 Pod 中所有容器都没有声明自己的 CPU 请求和 CPU 限制, 控制面会将 CPU 的默认请求值 0.5 和默认限制值 1 应用到 Pod 上。
以下为只包含一个nginx容器的 Pod 的清单,该容器没有声明 CPU 请求和限制。
vim nginx-without-cpu-resource.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx创建并查看pod:
$ kubectl apply -f nginx-without-cpu-resource.yaml
deployment.apps/nginx created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-748c667d99-p2mqk 1/1 Running 0 69s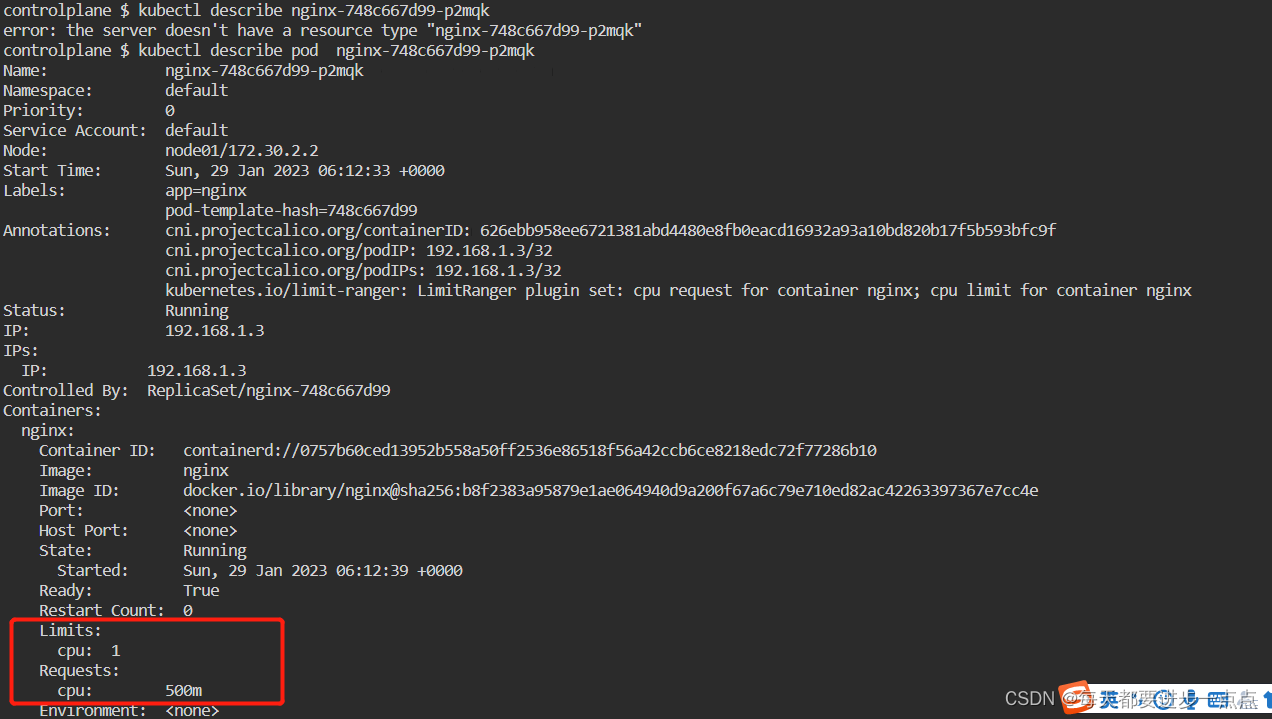 ?
?
可以看到,输出显示nginx容器已经被指定默认的 最小CPU请求为0.5和默认的最大CPU限制值为1。
五、超过容器限制的内存
当节点拥有足够的可用内存时,容器可以使用其请求的内存。 但是,容器不允许使用超过其限制的内存。 如果容器分配的内存超过其限制,该容器会成为被终止的候选容器。 如果容器继续消耗超出其限制的内存,则终止容器。 如果终止的容器可以被重启,则 kubelet 会重新启动它,就像其他任何类型的运行时失败一样。
我们看一个示例,资源清单如下:
vim oom-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: stress
spec:
containers:
- name: stress
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]这里定义了一个容器,该容器的内存请求为 50 MiB,内存限制为 100 MiB。并且在配置文件的 args 部分中,可以看到容器会尝试分配 250 MiB 内存,这远高于 100 MiB 的限制。
创建并查看Pod:
$ kubectl apply -f oom-demo.yaml
pod/stress created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
stress 0/1 OOMKilled 2 (26s ago) 30s 192.168.1.3 node01 <none> <none>可以看到,容器已经被杀死,并且kubelet 会尝试重启它。获取容器更详细的状态信息:
$ kubectl get pod stress -o yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
cni.projectcalico.org/containerID: b371e450fa7a62b0a3ad0744ef21c05aef265b049ad754ef6296f95c979fdb00
cni.projectcalico.org/podIP: 192.168.1.3/32
cni.projectcalico.org/podIPs: 192.168.1.3/32
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"stress","namespace":"default"},"spec":{"containers":[{"args":["--vm","1","--vm-bytes","250M","--vm-hang","1"],"command":["stress"],"image":"polinux/stress","name":"stress","resources":{"limits":{"memory":"100Mi"},"requests":{"memory":"50Mi"}}}]}}
creationTimestamp: "2023-01-30T06:20:50Z"
name: stress
namespace: default
resourceVersion: "2112"
uid: a2ee4e2f-2e12-4403-89ba-502956ab4f70
spec:
containers:
- args:
- --vm
- "1"
- --vm-bytes
- 250M
- --vm-hang
- "1"
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
limits:
memory: 100Mi
requests:
memory: 50Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-sckdb
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: node01
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: kube-api-access-sckdb
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2023-01-30T06:20:50Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2023-01-30T06:21:38Z"
message: 'containers with unready status: [stress]'
reason: ContainersNotReady
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2023-01-30T06:21:38Z"
message: 'containers with unready status: [stress]'
reason: ContainersNotReady
status: "False"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2023-01-30T06:20:50Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: containerd://a735f113298aa42255bda94e798291330e9db922ebdc820855be290a049e9dad
image: docker.io/polinux/stress:latest
imageID: docker.io/polinux/stress@sha256:b6144f84f9c15dac80deb48d3a646b55c7043ab1d83ea0a697c09097aaad21aa
lastState:
terminated:
containerID: containerd://a735f113298aa42255bda94e798291330e9db922ebdc820855be290a049e9dad
exitCode: 1
finishedAt: "2023-01-30T06:22:19Z"
reason: OOMKilled
startedAt: "2023-01-30T06:22:19Z"
name: stress
ready: false
restartCount: 4
started: false
state:
waiting:
message: back-off 1m20s restarting failed container=stress pod=stress_default(a2ee4e2f-2e12-4403-89ba-502956ab4f70)
reason: CrashLoopBackOff
hostIP: 172.30.2.2
phase: Running
podIP: 192.168.1.3
podIPs:
- ip: 192.168.1.3
qosClass: Burstable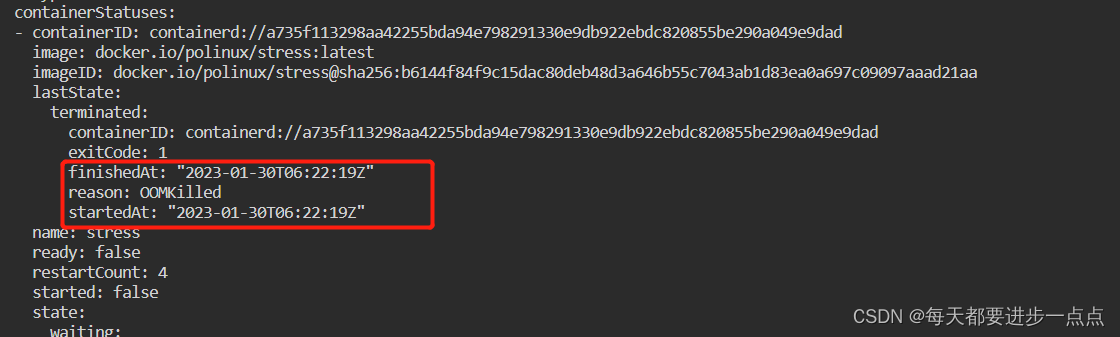 ?
?
输出结果显示:由于内存溢出(OOM),容器已被杀掉。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- QT_01 安装、创建项目
- C语言float何时表达6位有效数字,何时表达7位有效数字?
- 微信小程序分销商城制作源码系统:全部搭建好直接使用 带完整的安装代码包以及搭建教程
- Spring-JdbcTemplate
- 2023年最新版的linux运维面试题(三)
- 【日积月累】Mysql性能优化
- 【Docker】Linux中Docker数据管理的数据卷及挂载
- 批量重命名软件,一键批量重命名多个文件
- 计量校准方案分享No.8——千分尺校准方案
- 比较全面的vcruntime140_1.dll丢失的解决方法,4招搞定缺失的vcruntime140_1.dll