统计学-R语言-7.1
前言
本章主题是假设检验(hypothesis testing)。与参数估计一样,假设检验也是对总体参数感兴趣,如比例、比例间的差异,均值、均值间的差异等,
估计的主要任务是找出参数值等于几,
假设检验的兴趣主要是看参数的值是否等于某个特定值,或者比较两组数据,
在数学推导上,参数的假设检验和区间估计有很大的联系,
对于假设检验,人们是做出一个关于未知参数的假设,然后根据观察到的样本判断该假设是否正确,
而区间估计主要是通过数据推断未知参数的取值范围,
在R中,区间估计和假设检验使用的是同一个函数。
假设检验的原理
假设检验的原理
假设检验的大致思路是:
首先对所关心的总体提出某种假设,然后从待检验的总体中抽取一个样本并获得数据,再根据样本提供的信息判断假设是否成立。
如果已知总体分布或能对总体分布做出假定,而所关注的仅仅是总体的某个参数,并对参数的某个假设做检验,称为参数检验( parameter test);
如果是对总体的其他特征(如分布的形式)做检验,或者是样本数据不满足参数检验条件,不依赖于总体分布的形式对总体参数做检验,这样的检验称为非参数检验( nonparametric test)。
提出假设
假设( prothesis)是对总体的某种看法。在参数检验中,假设就是对总体参数的具体数值所做的陈述。
比如,虽然不知道一批灯泡的平均使用寿命是多少,不知道一批产品的合格率是多少,不知道全校学生生活费支出的方差是多少,但可以事先提出一个假设值,比如,这批灯泡的平均使用寿命是8500小时,这批产品的合格率是95%,全校学生月生活费支出的方差是1000等等,这些陈述就是对总体参数提出的假设。
假设检验( hypothesis test)是在对总体提出假设的基础上,利用样本信息判断假设是否成立的统计方法。
比如,假设全校学生月生活费支出的均值是2000元,然后从全校学生中抽取一个样本,根据样本信息检验月平均生活费支出是否为2000元,这就是假设检验。
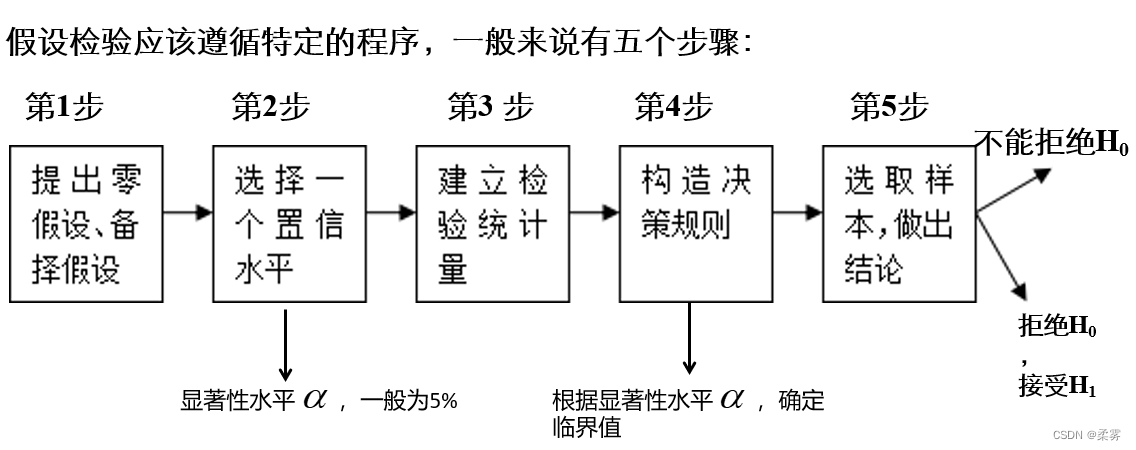
做假设检验时,首先要提出两种假设,即原假设和备择假设 。
原假设(null hypothesis)
又称“0假设”,研究者想收集证据予以推翻的假设,用H0表示
所表达的含义总是指参数没有变化或变量之间没有关系或总体分布于某种理论分布无差异
最初假设是成立的,之后根据样本数据确定是否有足够的证据拒绝它

备择假设(alternative hypothesis)
也称“研究假设”,研究者想收集证据予以支持的假设,用H1或Ha表示
所表达的含义是总体参数发生了变化或变量之间有某种关系或总体分布于某种理论分布有差异
备择假设通常用于表达研究者自己倾向于支持的看法,然后就是想办法收集证据拒绝原假设,以支持备择假设

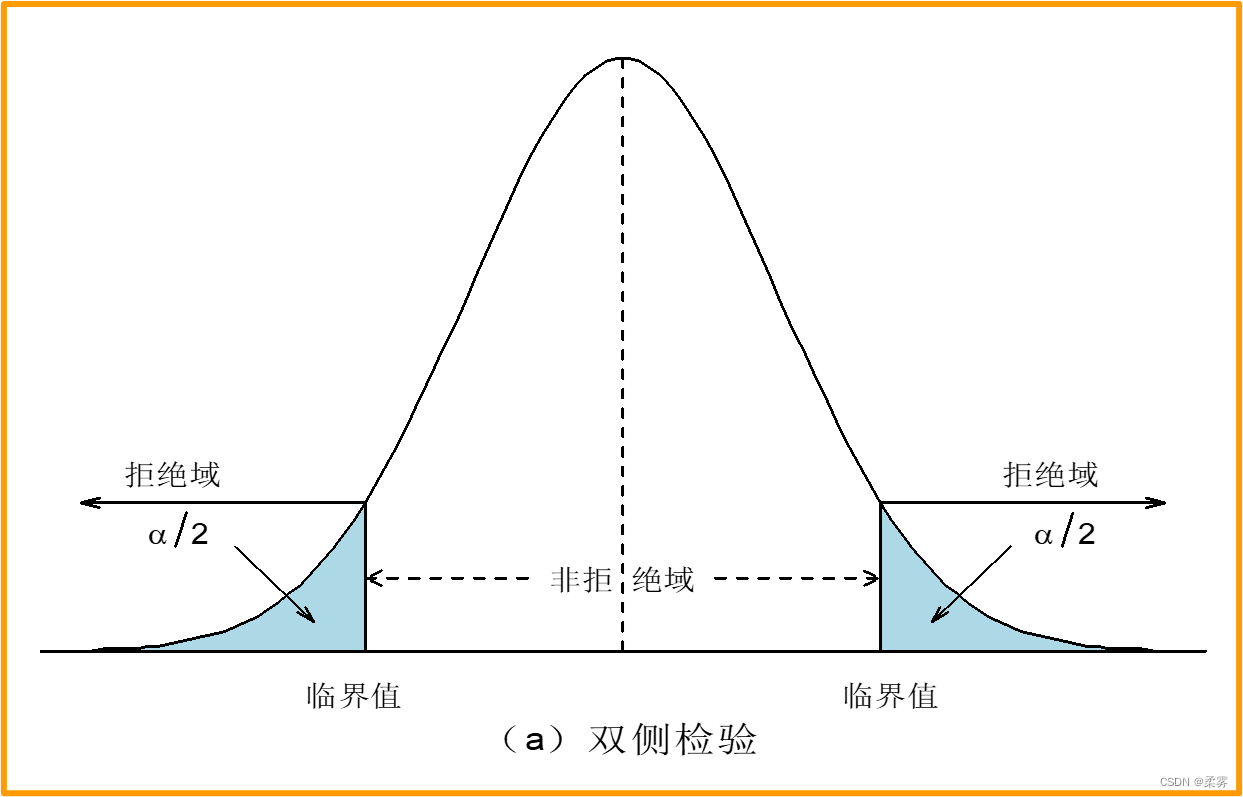
备择假设没有特定的方向性,并含有符号“?”的假设检验,称为双侧检验或双尾检验(two-tailed test)
备择假设具有特定的方向性,并含有符号“>”或“<”的假设检验,称为单侧检验或单尾检验(one-tailed test)
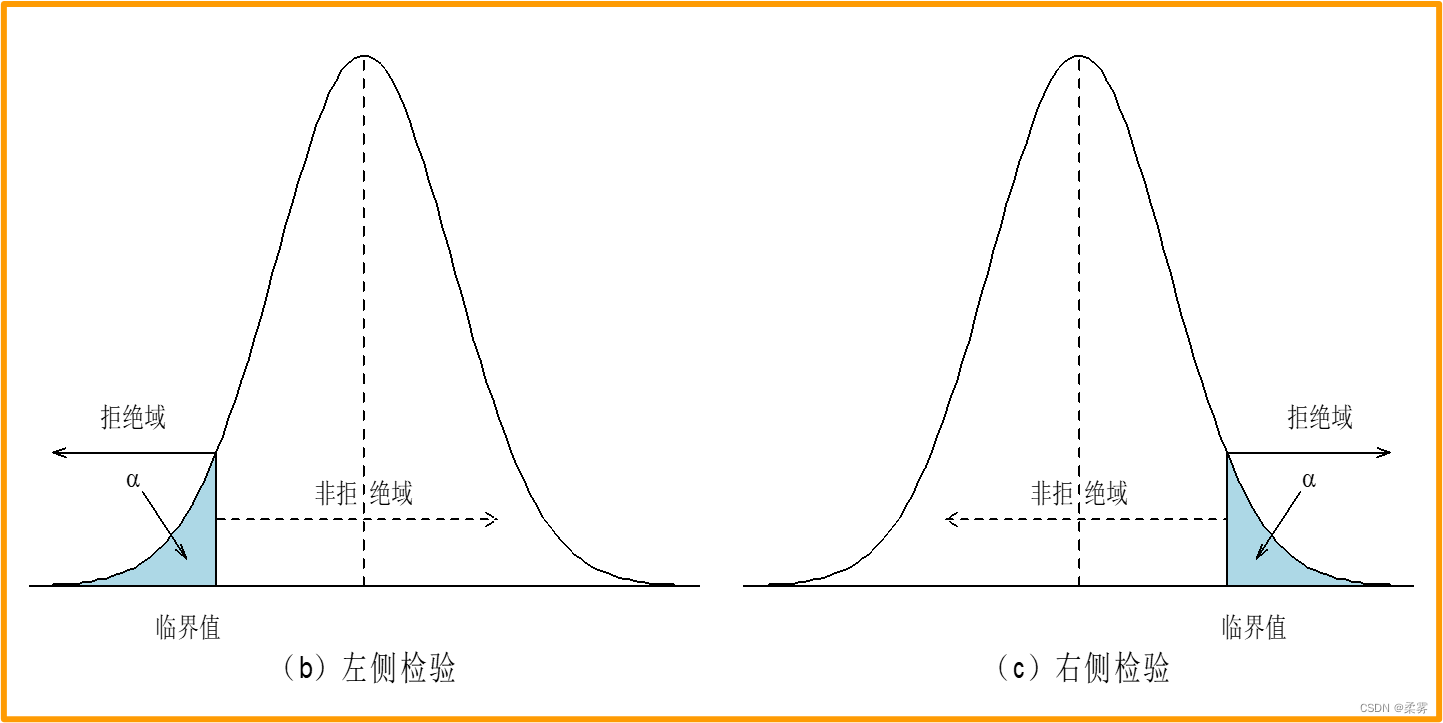
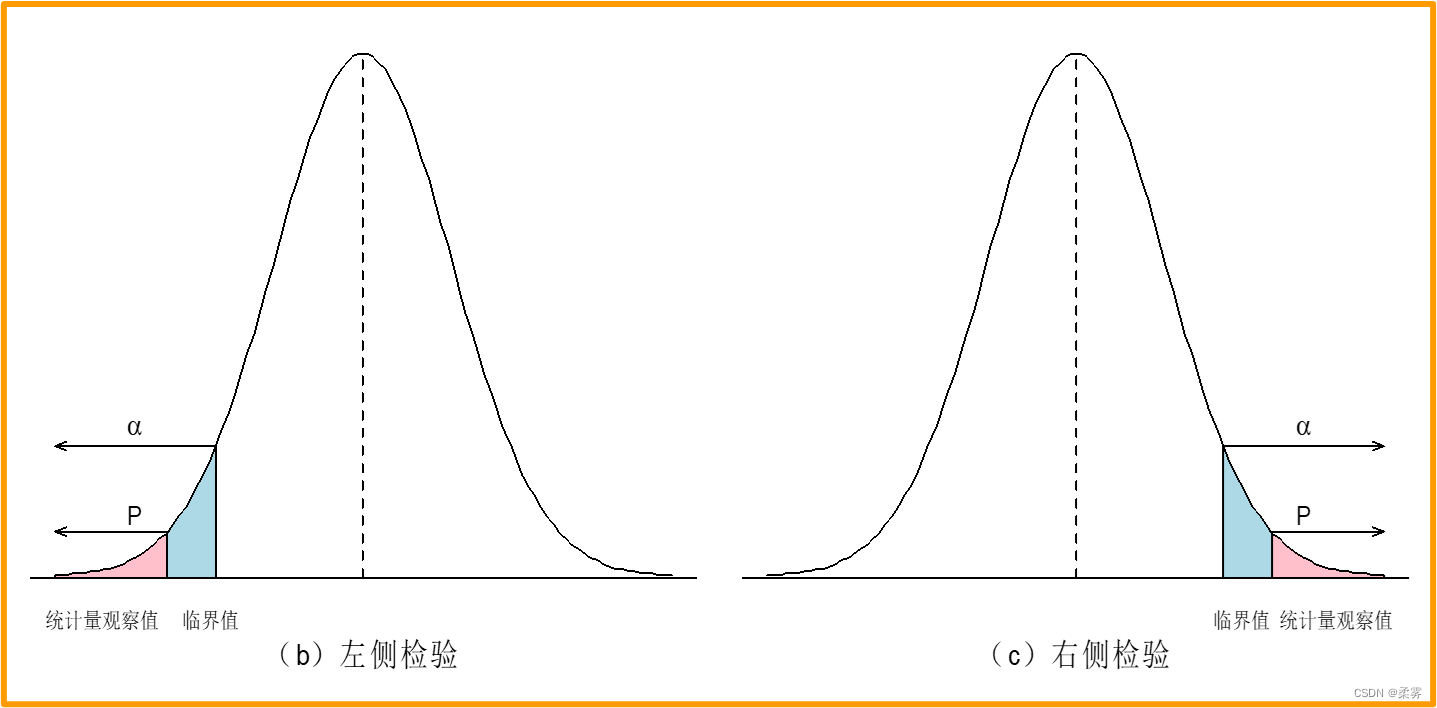
备择假设的方向为“<”,称为左侧检验
备择假设的方向为“>”,称为右侧检验

例题:
一种零件的生产标准是直径应为15cm,为对生产过程进行控制,质量监测人员定期对一台加工机床检查,确定这台机床生产的零件是否符合标准要求。如果零件的平均直径大于或小于15cm,则表明生产过程不正常,必须进行调整。试陈述用来检验生产过程是否正常的原假设和备择假设。
设这台机床生产的所有零件平均直径的真值为μ。若μ=15,表示生产过程正常,若μ>15或μ<15表示生产过程不正常,研究者要检验这两种可能情形中的任何一种。因此,研究者想收集证据予以推翻的假设应该是“生产过程正常”,而想收集证据以支持的假设是“生产过程不正常”(因为如果研究者事先认为生产过程正常也就没有必要进行检验了),所以建立的原假设和备择假设应为
解:研究者想收集证据予以证明的假设应该是“生产过程不正常”。建立的原假设和备择假设为
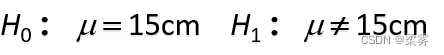
例题:
产品的外包装上都贴有标签,标签上通常标有该产品的性能说明、成分指标等信息。农夫山泉550ml瓶装饮用天然水外包装标签上标识每100ml水中钙的含量 400μg。如果是消费者来做检验,应该提出怎样的原假设和备择假设?如果是生产厂家自己来做检验,又会提出怎样的原假设和备择假设?
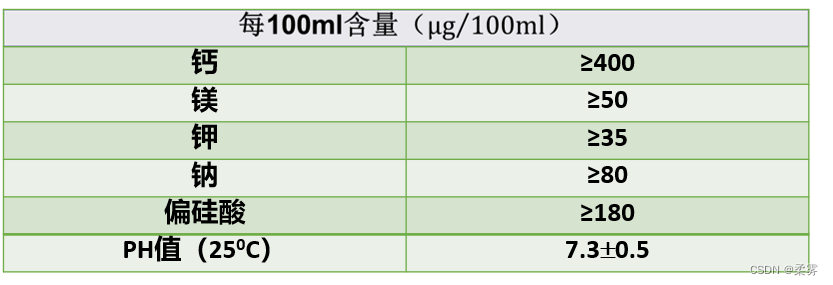
解:设每100ml水中钙的含量均值为μ。消费者做检验的目的是想寻找证据推翻标签中的说法,即μ≥400μg(如果对标签中的数值没有质疑,也就没有检验的必要了),而想支持的观点则是标签中的说法不正确,即μ<400g。因此,提出的原假设和备择
假设应为:
解:研究者抽检的意图是倾向于证实瓶子上标签的说法并不属实 。建立的原假设和备择假设为
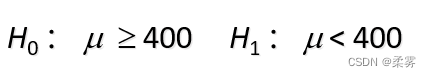
解:如果是生产厂家自己做检验,生产者自然是想办法来支持自己的看法,也就是想寻找证据证明标签中的说法是正确的,即μ>400μg,而想推翻的则是μ≤400μg。因此会提出与消费者观点不同(方向相反)的原假设和备择假设:
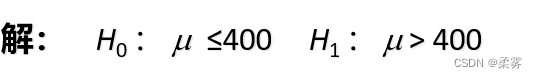
通过上面的例子可以看出,原假设和备择假设是一个完备事件组,而且相互对立。这意味着,在一项检验中,原假设和备择假设必有一个成立,而且只有一个成立。
此外假设的确定带有一定的主观色彩,因为研究者想推翻的假设和研究者想支持的假设最终仍取决于研究者本人的意向。所以,即使是对同一个问题,由于研究目的不同,也可能提出截然不同的假设。但无论怎样,只要假设的建立符合研究者的最终目的便是合理的。
做出决策
假设检验是根据样本信息做出拒绝或不拒绝原假设的决策。
依据什么做出决策?
所做的决策是否正确?
研究者总是希望能做出正确的决策,但由于决策是建立在样本信息的基础之上,而样本又是随机的,因而就有可能犯错误
原假设和备择假设不能同时成立,决策的结果要么拒绝H0,要么不拒绝H0。决策时总是希望当原假设正确时没有拒绝它,当原假设不正确时拒绝它,但实际上很难保证不犯错误
第Ⅰ类错误(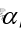 错误)
错误)
原假设为正确时拒绝原假设
第Ⅰ类错误的概率记为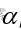 ,被称为显著性水平
,被称为显著性水平
第Ⅱ类错误(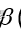 错误)
错误)
原假设为错误时未拒绝原假设
第Ⅱ类错误的概率记为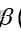 (Beta)
(Beta)
这两类错误的概率之间存在这样的关系:在样本量不变的情形下,要减小α就会使β增大,而要减小β就会使α增大。
要使α和β同时减小的唯一办法是增加样本量,但样本量的增加又会受许多因素的限制,所以人们只能在两类错误的发生概率之间进行平衡。
一般来说,对于一个给定的样本,如果犯第Ι类错误的代价比犯第Ⅱ类错误的代价相对较高,则将犯第Ⅰ类错误的概率定得低些较为合理;反之,如果犯第Ι类错误的代价比犯第Ⅱ类错误的代价相对较低,则将犯第Ⅰ类错误的概率定得高些
一般来说,发生哪一类错误的后果更为严重,就应该首要控制哪类错误发生的概率。但由于犯第Ι类错误的概率是可以由研究者控制的,因此在假设检验中,人们往往先控制第Ι类错误的发生概率。
事先确定的用于拒绝原假设H0时所必须的证据
能够容忍的犯第Ⅰ类错误的最大概率(上限值)
原假设为真时,拒绝原假设的概率
抽样分布的拒绝域
表示为 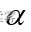 (alpha) 常用的
(alpha) 常用的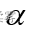 值有0.01, 0.05, 0.10由研究者事先确定。
值有0.01, 0.05, 0.10由研究者事先确定。

在样本量固定的情况下,减少α将增大β,减少β将增大α,即不能同时减少犯两类错误的概率。
由于通常将希望出现的结论作为备择假设H1,为使拒绝H0、接受H1具有较高的可信度,总是控制犯第一类错误的概率α
若要使犯两类错误的概率同时变小,则必须增大样本量。
提出具体的假设之后,研究者需要提供可靠的证据来支持他所关注的备择假设。
在上面的例5-2中,如果你想证实产品标签上的说法不属实,即检验假设:
Ho:μ≥400;H1:μ<400
抽取一个样本得到的样本均值为390μg,你是否拒绝原假设呢?
如果样本均值是410g,你是否就不拒绝原假设呢?
做出拒绝或不拒绝原假设的依据是什么?
传统检验中,决策依据的是样本统计量,现代检验中,人们直接根据样本数据算出犯第Ⅰ类错误的概率,即所谓的P值(p–value)。检验时做出决策的依据是:原假设成立时小概率事件不应发生,如果小概率事件发生了,就应当拒绝原假设。统计上,通常把P≤0.1的值统称为小概率。
(1) 用统计量决策(传统做法)-----样本数据算出用于决策的检验统计量(test statistic)
总体均值 样本均值(点估计量,不能直接作为评判标准)
自然想到:将点估计量标准化,用于度量它与原假设的参数值之间的差异程度
对样本估计量的标准化结果
原假设H0为真
点估计量的抽样分布

标准化检验统计量反映了点估计值与假设的总体参数之间想差了多少个标准误的距离。

如果统计量的值落在拒绝域内就拒绝原假设。样本量固定,拒绝域随α的减小而减小。
(1) 用P值决策(现代做法)-----使用“犯第Ⅰ类错误的真实概率”做决策
犯第Ⅰ类错误的真实概率就是P值,它是指当原假设正确时,所得到的样本结果会像实际观测结果那么极端或更极端的概率,也称为观察到的显著性水平(observed significalce level)或者实际显著性水平。
决策规则:若p值<α, 拒绝 H0, 若p值>α , 不拒绝 H0。
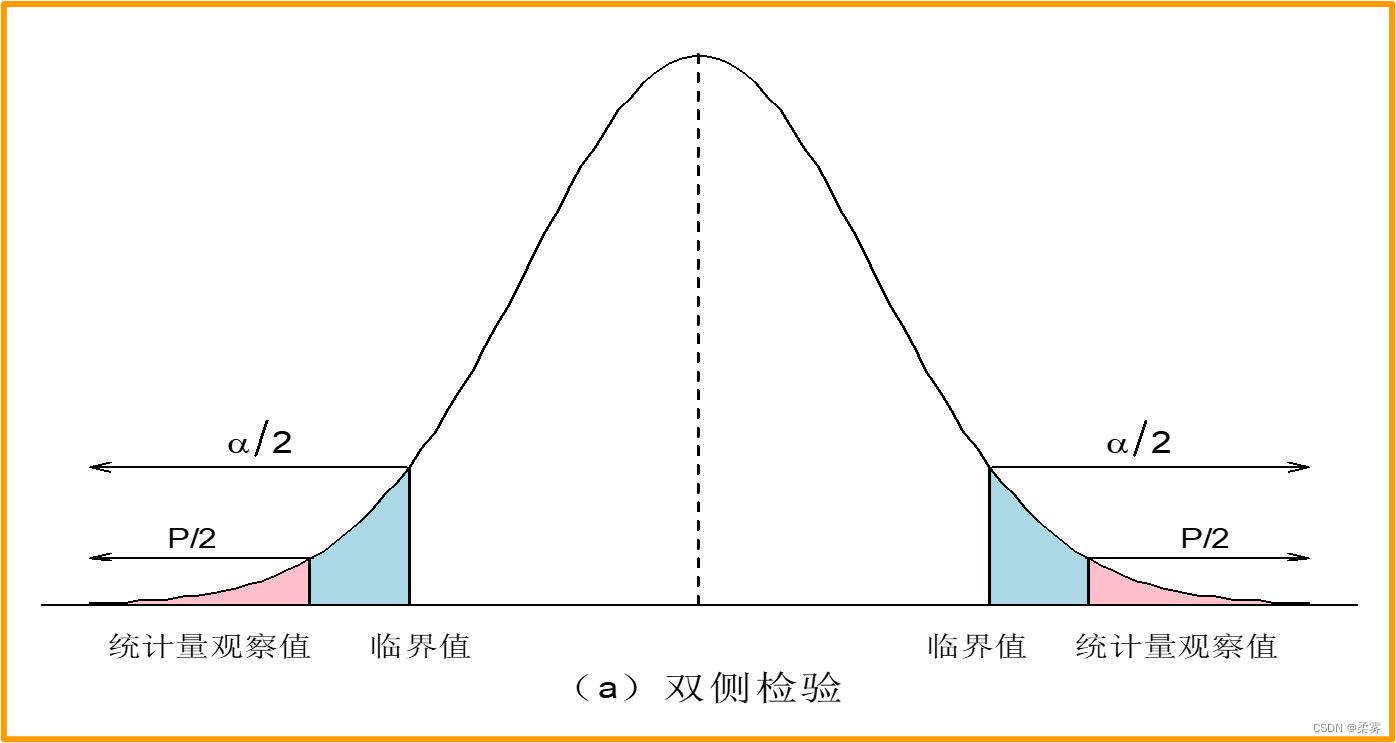
P值是关于数据的概率;P值原假设的对或错的概率无关
它反映的是在某个总体的许多样本中某一类数据经常的出现程度,它是当原假设正确时,得到目前这个样本数据的概率
比如,要检验全校学生的平均生活费支出是否等于500元,检验的假设为
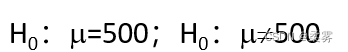
假定抽出一个样本算出的样本均值600元,得到的值为P=0.02,这个0.02是指如果平均生活费支出真的是500元的话,那么,从该总体中抽出一个均值为600的样本的概率仅为0.02。如果你认为这个概率太小了,就可以拒绝原假设,因为如果原假设正确的话,几乎不可能抓到这样的一个样本,既然抓到了,就表明这样的样本不在少数,所以原假设是不对的
值越小,你拒绝原假设的理由就越充分。
设立这些假设的动机主要是企图利用人们掌握的反映现实世界的样本数据(通常更接近于备择假设)来找出零假设与现实之间的矛盾,从而否定这个假设,并称该检验显著(significant),因此假设检验也称为显著性假设检验 (significant hypothesis testing)
所谓的矛盾,就是按照零假设, 现实世界数据的出现仅仅属于小概率事件, 是不大可能出现的。也就是假设的现实世界和观测的现实世界不符。
著名的统计学家费歇尔把1/20作为标准,也就是0.05,从此0.05或者比0.1小的概率都被认为是小概率。
在假设检验中,拒绝零假设时所允许的犯第一类错误的最大的概率称为显著性水平(level of significance或 significance level)。
表述结果
假设检验的目的主要是收集证据拒绝原假设,而支持你所倾向的备择假设
假设检验只提供不利于原假设的证据。因此,当拒绝原假设时,表明样本提供的证据证明它是错误的,当没有拒绝原假设时,我们也没法证明它是正确的,因为假设检验的程序没有提供它正确的证据。
当不能拒绝原假设时,我们也从来不说“接受原假设”,因为没有证明原假设是真的
没有足够的证据拒绝原假设并不等于你已经“证明”了原假设是真的,它仅仅意为着目前还没有足够的证据拒绝原假设,只表示手头上这个样本提供的证据还不足以拒绝原假设
“不拒绝”的表述方式实际上意味着没有得出明确的结论
拒绝原假设 or 不拒绝原假设。
当拒绝原假设时,我们称样本结果是统计上显著的(statistically Significant)
当不拒绝原假设时,我们称样本结果是统计上不显著的
在“显著”和“不显著”之间没有清楚的界限,只是在P值越来越小时,我们就有越来越强的证据,检验的结果也就越来越显著。
效应量
假设检验拒绝原假设后,表示参数与假设值之间差异显著,但这一结果并未有告诉我们差异的大小(程度)。度量这种差异的统计量就是效应量,它描述了结果的差异程度是小、中还是大。
效应量的提出者是Jacob Cohen(1988),他提供了不同检验效应量小、中、大的度量标准。如果假设检验拒绝了原假设,一般应给出相应的效应量。不同检验效应量的计算和具体应用将在后面的检验中陆续介绍。
总体均值的检验
当研究一个总体时,主要是检验该总体均值μ与某个假设值μ0的差异是否显著;当研究两个总体时,主要是检验两个总体均值之差(μ1-μ2)是否显著。
总体均值的检验(一个总体均值的检验)
检验总体均值时,采用什么样的检验统计量取决于所抽取的样本是大样本(n >=30)还是小样本(n<30),此外,还要考虑总体是否服从正态分布、总体方差 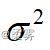 是否已知等几种情形。
是否已知等几种情形。
大样本的检验

例题:
(数据: example6-3. Rdata)为监测空气质量,某城市环保部门每隔几周对空气中的PM2.5(可吸入颗粒物)进行一次随机测试。已知该城市过去每立方米空气中PM2.5的均值是81μg/ 。在最近一段时间的40次检测中,每立方米空气中的PM2.5数值如下表所示:
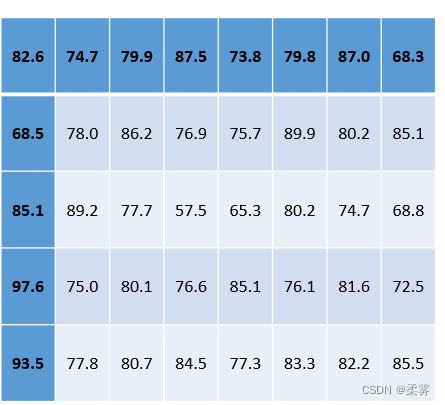
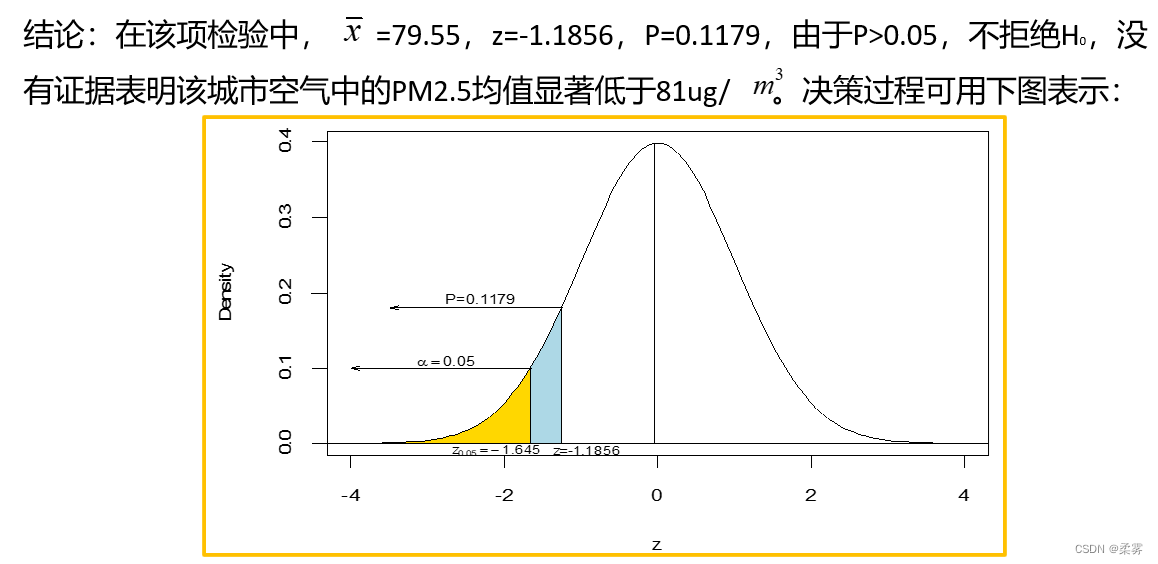
根据最近的测量数据,能否认为该城市每立方米空气中PM2.5的均值显著低于81μg/ ( =0.05)?
解:这里关心的是空气中PM2.5的均值是否显著低于过去的均值,也就是是否小于81μg/ ,属于左侧检验。提出的假设为
H0: μ≥81;H1:μ<81
检验的R代码和结果如下所示:
load("C:/example/ch6/example6_3.RData")
library(BSDA)
z.test(example6_3$PM2.5值,mu=81,sigma.x=sd(example6_3$PM2.5值),alternative="less",conf.level=0.95)

练习
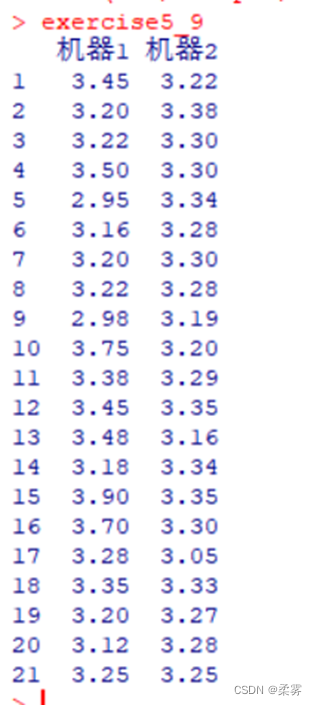
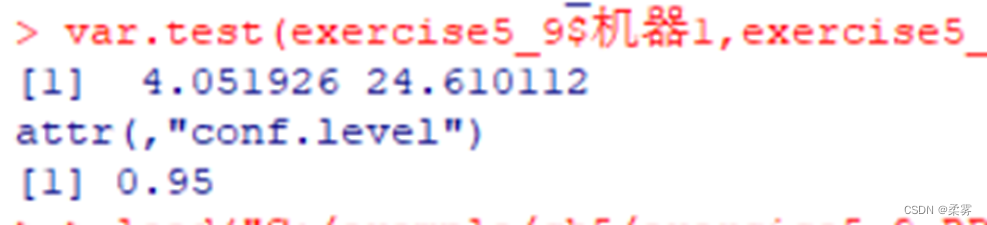
1、生产工序的方差是工序质量的一个重要测试指标。当方差较大时,需要对工序进行改进以减小方差。下面是两部机器生产的袋茶重量的数据(单位:克)
计算两个总体方差比的95%置信区间
load("C:/example/ch5/exercise5_9.RData")
var.test(exercise5_9$机器1,exercise5_9$机器2,alternative="two.sided")$conf.int
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!