rnn相关
构成
比之前多了一个圈
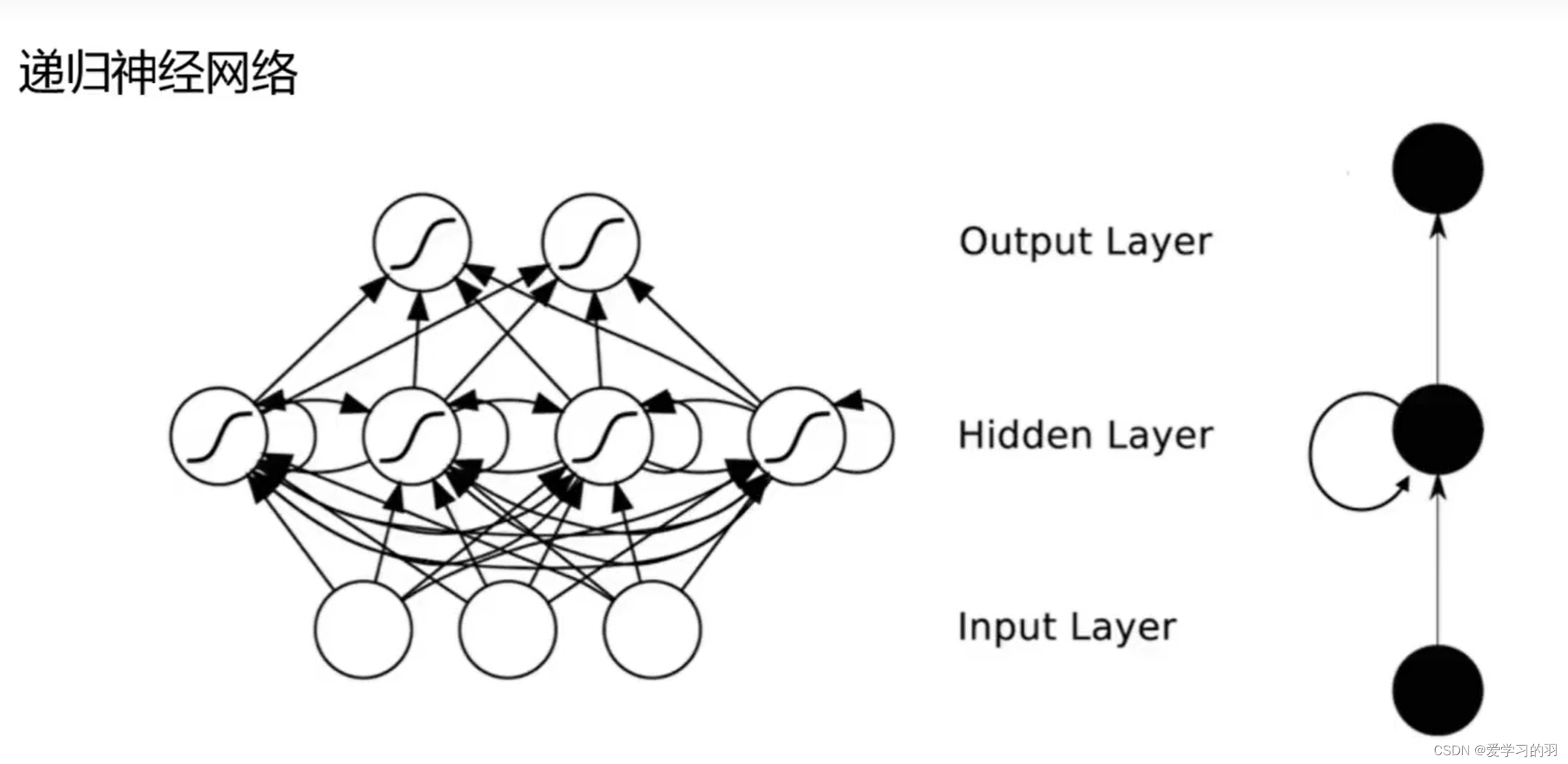
这个圈包含t时刻之前的数据特征,主要用在NLP自然语言处理中。

只用最后一个结果ht,前面的当做中间结果
特点
会把之前看到的都记下来,但第n句话和第一句话之间联系不太大,没必要
LSTM

自然语言处理
考虑词的 前后顺序和相关性

构建词向量,不断向后滑动学习
cbow 和skip-gram方法
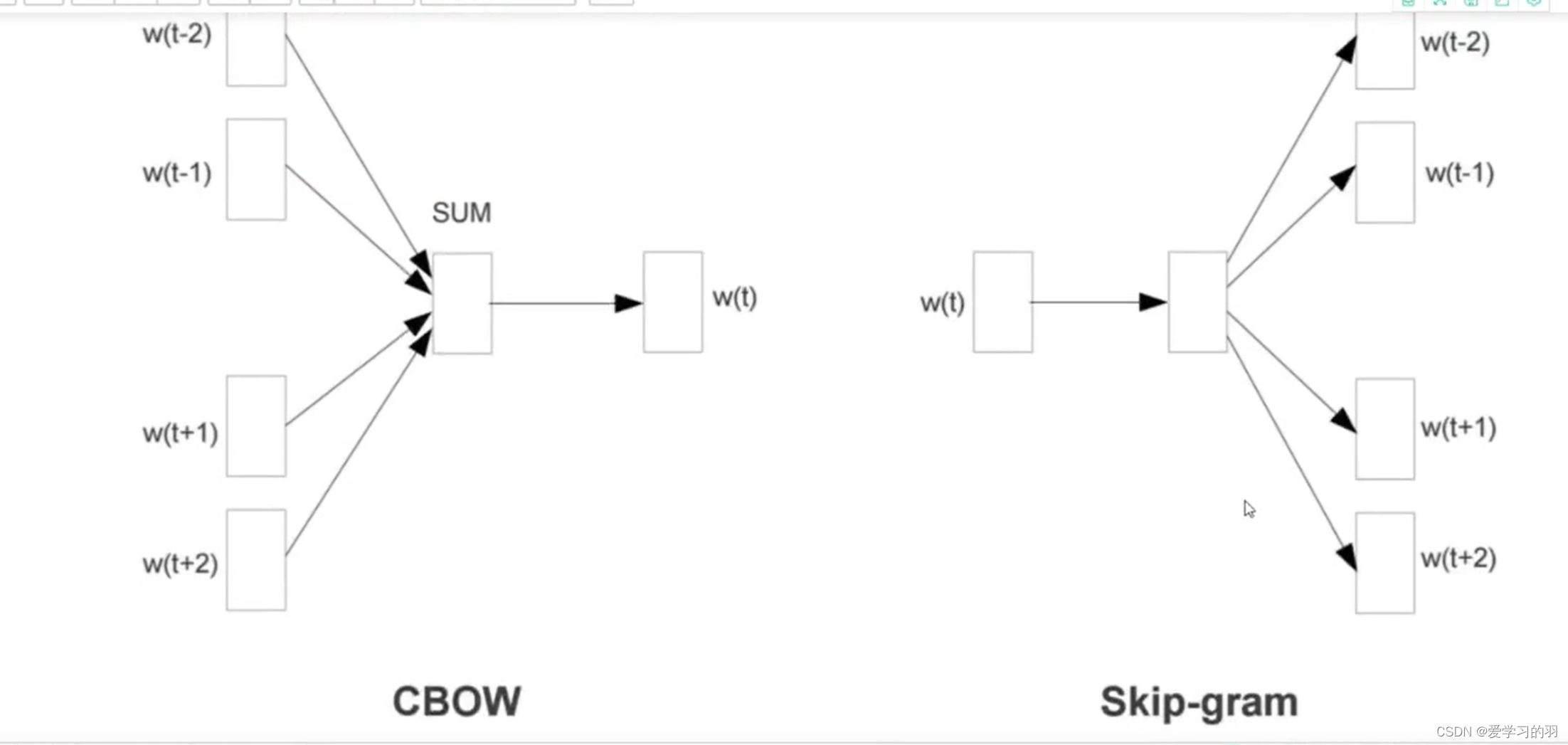
- cbow输入上下文,输出预测最中间的位置的词
- skip-gram 输入中间的词,输出预测的上下文
改进方法
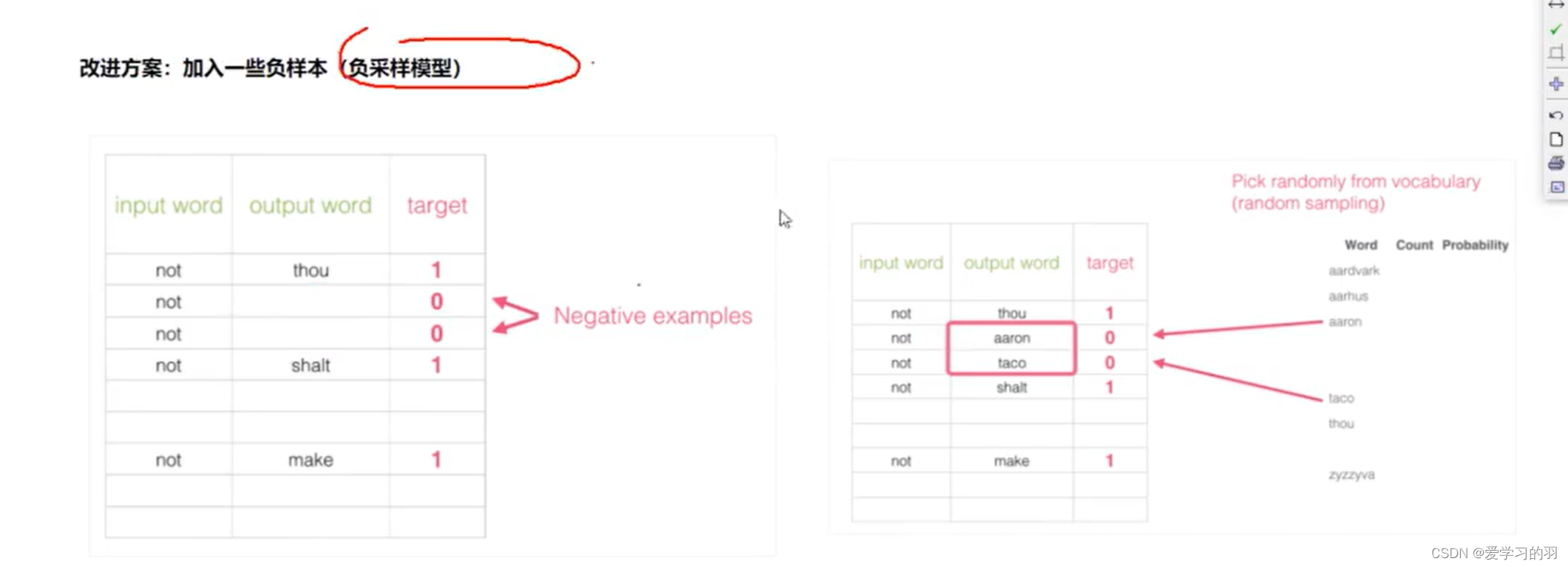
加入一些负样本(负采样模型) 顺序的词太多了,需要加乱序的词,作为负样本

skipgram的正负样本模型
实战
词嵌入:将词转化为向量
每个词用300维的向量表示,词大小为32
(batch,maxlen,featrue)
(同时处理多少标题或者文章,序列的最大长度,feature大小(300维))
基于字做的,在此数据集中有4000+个可能,而词更多,运算量大
LSTM

self.lstm = nn.LSTM(config.embed(300维的输入特征), config.hidden_size(128个隐藏神经元), config.num_layers(两层的LSTM),
bidirectional=True(是单向的还是双向的,双向的效果好), batch_first=True, dropout=config.dropout)
双向的LSTM
特征最后会拼接起来,维度更多了

上图是3层LSTM(淡蓝色部分),一般用最后一层最后一个输出作为最终输出,因为它包含并计算了前面神经元的特征信息
例子中的模型
Model(
(embedding): Embedding(4762, 300)
(lstm): LSTM(300, 128, num_layers=2, batch_first=True, dropout=0.5, bidirectional=True)
(fc): Linear(in_features=256, out_features=10, bias=True)
)
NLP任务大部分是分类任务
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Qt/QML编程学习之心得:读写GPIO(23)
- 基于Java的学习交流论坛系统论文
- 大带宽服务器怎么租 具体步骤总结
- 微服务 Spring Cloud 10,如何追踪微服务调用?服务治理的常见手段
- C语言第五十三弹----模拟使用strncmp函数
- c++整数二分代码实现
- 微信小程序(六)tabBar的使用
- 如何分析测试任务及需求(附分析流程)
- 现在做视频号小店晚吗?还有发展空间吗?
- 【RTOS】快速体验FreeRTOS所有常用API(2)任务管理