01-分库分表介绍-分库分表概述.wmv__ev
第一章 分库分表介绍
1、分库分表概述
分库分表本质上就是为了解决由于库表数据量过大而导致数据库性能降低的问题; 核心操作:
-
将原来独立的数据库拆分成若干数据库组成;
-
将原来的大表(存储近千万数据的表)拆分成若干个小表;
目的:使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的;
 ?
?
2、分库分表场景示例
2.1 场景说明
老王是一家初创电商平台的开发人员,负责卖家模块的功能开发,其中涉及了店铺、商品的相关业务,设计如下数据库:
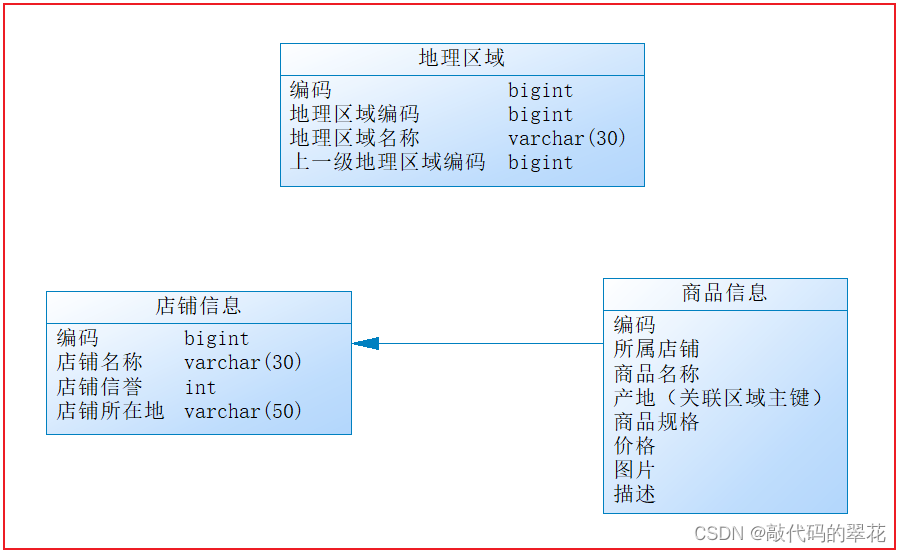 ?
?
实际业务中经常需要查询商品、商铺、地理位置等信息,效果如下:
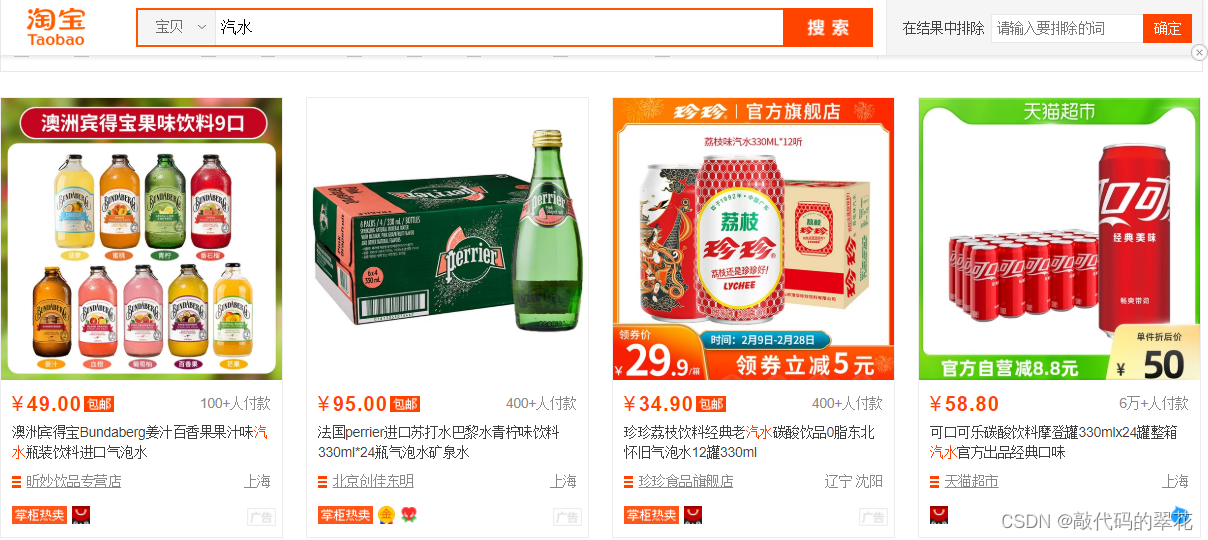 ?
?
通过以下SQL能够获取到商品相关的店铺信息、地理区域信息:
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息表] p
LEFT JOIN [地理区域表] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息表] s ON p.id = s.[所属店铺]
WHERE p.id = ?随着公司业务快速发展,数据库中的店铺、商品等数据量会猛增,大数据量且并发高的访问会导致数据库性能急剧下降;
2.2 数据库访问变慢原因分析
原因如下:
-
在系统应用中关系型数据库本身比较容易成为系统瓶颈(I/O),比如:单机存储容量、数据库连接数、处理能力等都有上限;
-
当单表的数据量达到1000W或100G以后(大表),即使做了优化索引等操作,查询性能仍会下降严重,更不要说复杂的多表关联查询了;
-
对于商家模块来说,当数据量过大是,会存在大表关联查询,导致查询性能急剧下降![尽量避免大表的关联查询-查询优化-反三大范式]
3、大数据存储下数据库性能分析
优化数据库要从硬件和软件层面优化:
-
硬件层面
-
提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU等;
-
提升硬件配置相对成本较高,且如果瓶颈在MySQL本身那么提高硬件带来的性能提升也是有限的;
-
-
软件层面
-
把大量数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题;
-
把大表拆分成若干小表,解决单张大表查询性能问题;
-
-
对于关系型数据库来说,磁盘I/O会成为其瓶颈,通过缓存热点数据,在一定程度来可提升系统性能;
如下图将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库拆分的方法来解决数据库的性能问题:
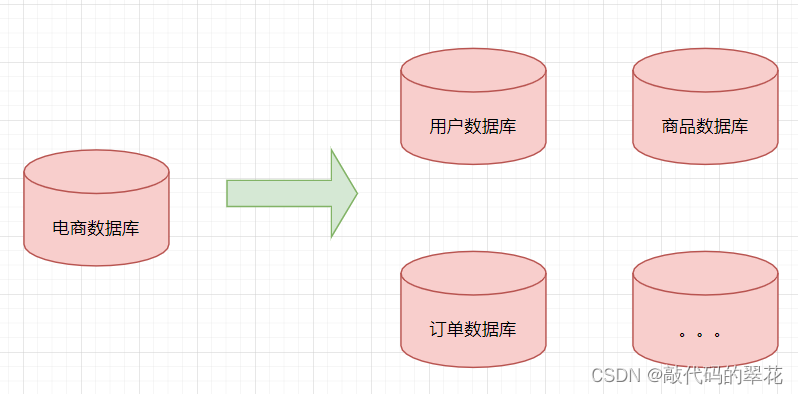 ?
?
?
小结
-
分库分表是为了解决由于数据量过大而导致数据库性能降低的问题;
-
分库分表是将原来独立的数据库拆分成若干数据库,将独立的大表拆分成若干小表过程;
-
分库分表最终使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的;
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!