论文笔记:Bilinear Attention Networks
1、摘要
多模态学习中的注意力网络提供了一种选择性地利用给定视觉信息的有效方法。然而,学习每一对多模态输入通道的注意力分布的计算成本是非常昂贵的。为了解决这个问题,共同注意力为每个模态建立了两个独立的注意分布,忽略了多模态输入之间的相互作用。在本文中,我们提出了双线性注意力网络(BAN),它可以找到双线性注意力分布来无缝地利用给定地视觉语言信息。BAN考虑两组输入通道之间的双线性交互,而低秩双线性池化提取每对通道地联合表示。此外,我们提出了一种多模态残差网络的变体,以有效地利用BAN的注意力图。在VQA 2.0和Flickr30k实体数据集上定量和定性地评估模型,表明BAN显著优于以前的方法,并在这两个数据集上达到了新的水平。
2、介绍
由于视觉和自然语言是人类互动的主要方式,对视觉和自然语言信息的理解和推理成为一个关键的挑战。例如,视觉问题回答涉及到视觉和语言的交叉问题。人们希望机器能够利用基于视觉的信息回答给定的问题,比如“谁戴着眼镜?”,“雨伞是不是倒了?”或者“床上有几个孩子?”。
由于这个原因,基于视觉注意力的模型已经成功地完成了多模态学习任务,在模型1定义的图像的空间地图中识别出选择性区域。此外,文本注意可以与视觉注意一起考虑。共同注意力网络的注意机制同时推断出每种模态的视觉和文本注意分布。除了部分图像区域外,共同注意网络还选择性地关注问题词。然而,共同注意忽略了单词和视觉区域之间的相互作用,以避免增加计算复杂度。
在本文中,我们将共同注意的思想扩展到双线性注意,双线性注意考虑了每一对多模态通道,如疑问词对和图像区域对。当给定问题涉及由多个词表示的多个视觉概念时,使用每个词的视觉注意分布比使用单个压缩注意分布的推理能更好地挖掘相关信息。
在这种背景下,我们提出了双线性注意力网络(BAN),在低秩双线性池化的基础上使用双线性注意力分布。BAN利用两组输入通道之间的双线性交互,而低秩双线性池化提取每对通道的联合表示。此外,提出了一种多模态残差网络(MRN)的变体,以有效地利用BAN的多个双线性注意图(通过连接被关注的特征来使用多个注意图)。由于所提出的残差学习方法利用残差求和而不是串联,因此可以有效地学习到参数高效和性能有效的八目BAN。关于双视图BAN的概述,参考图1.
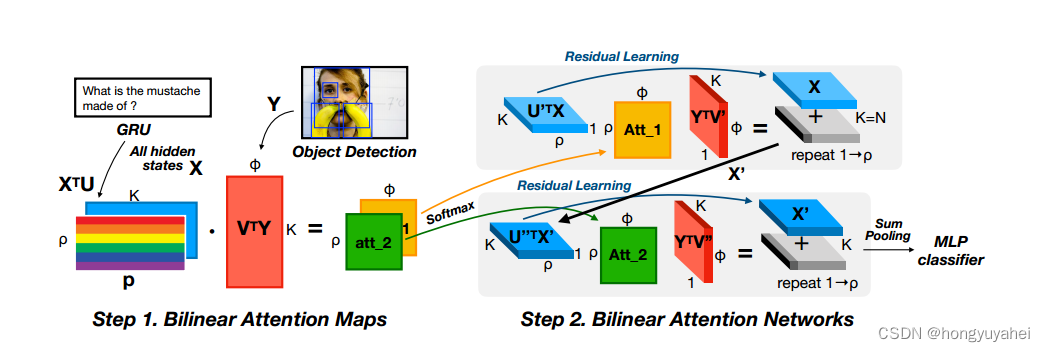
上图中,双目BAN,采用目标检测特征和GRU隐藏向量两个多通道输入,得到双线性注意图和联合表示,供分类器使用。
提出双线性注意力网络(BAN)来学习和使用双线性注意力分布,在低秩双线性池化技术的基础上。
- 提出一种多模态残差网络(MRN)的变体,以有效地利用我们的模型生成的双线性注意图。与以往的工作不同,我们的方法成功地利用了多达8个注意图
- 最后,在一个大型且竞争激烈的VQA2.0数据集上验证该方法。模型达到了保持模型结构简单性的新水平。
- 此外,在Flick30k实体上的双线性注意图的视觉基础优于先前的方法,同时,利用多通道输入的处理推理速度提高了25.37%。
3、低秩双线性池化
低秩双线性池及其在注意力网络中的应用,它使用单通道输入(问题向量)结合其他多通道输入(图像特征)作为单通道中间表示(出席特征)。
(1)低秩双线性模型
前人提出了一种低秩双线性模型,降低双线性权重矩阵Wi的秩,使其具有规律性。为此,Wi被替换为两个较小的矩阵Ui和Vi的转置的乘法。因此,这种替换使得Wi的秩最大为d<=min(N,M).对于标量输出fi(省略偏置项而不失一般性)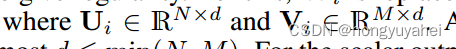
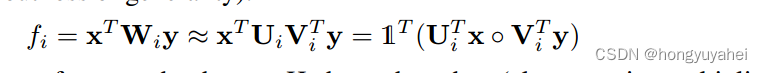
。表示哈德曼乘积(逐元素乘法)
(2)低秩双线性池化
对于输出向量f,引入池化矩阵P
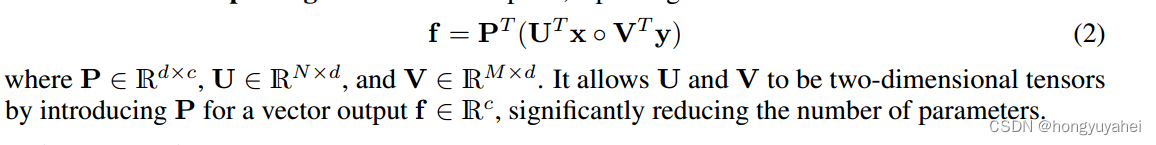
它允许U和V是二维张量,通过对于输出向量f引入向量P,显著减少参数的数量。
(3)单一注意力网络
注意力提供了一种有效的机制,通过选择性地利用给定的信息来减少输入通道。


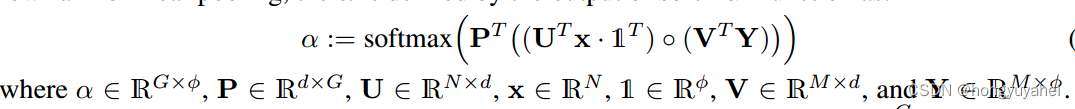
如果G>1,则使用多个注意头,则:
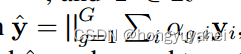
最后,两个单通道输入x、y可通过其他低秩双线性池化获得联合表示用于分类器。
4、双线性注意力网络


5、相关工作

6、实验
(1)数据集
- VQA2.0
-评估指标考虑人与人之间的可变性,定义:
Accuracy(ans) = min(#humans that said ans/3,1) - Flickr30k Entities
它由31783张图像和244035个答案组成,将句子中的多个实体映射到图像的方框上,以指示它们之间的对应关系。任务是为每个实体定位相应的框。通过这种方式,文本信息的视觉基础得到了定量测量。根据评价指标,如果一个预测框与其中一个真实基准框的重叠区域IoU大于等于0.5,则给定实体的预测是正确的,这个指标叫做Recall@1。如果允许K个预测找到至少一个正确的,则称为Recall@K。我们通过Recall@1、5和10来比较最新的技术水平。如果检测器提出候选盒进行预测,则性能的上界取决于目标检测的性能。
(2)预处理
- 问题嵌入
对于VQA,我们使用Glove词嵌入和门控循环单元的输出来得到问题嵌入,将问题最多嵌入为14个单词向量,短于14个单词的向量用0补齐。对于Flickr30k,使用完整的句子长度,最大82。我们标记每个答案短语末尾的标记位置。然后,我们使用这些位置选择GRU输出通道的一个子集,使通道的数量等于句子中实体的数量。单词嵌入和GRU在训练中进行了微调。 - 图像特征
我们使用自底向上的注意力机制提取图像特征。这些特征是Faster R-CNN的输出,使用Visual Genome进行预训练。设置每张图的目标数目范围介于[10,100]。为避免填充部分对于模型的训练产生负面影响,在logits中的填充位置使用负无穷大的值,这样在应用softmax后,这些位置对应的概率值就会趋向于0。
(3)非线性和分类器
- 非线性

- 分类器
在VQA任务中,采用两层的多层感知机(MLP)作为用于生成最终联合表示的分类器,激活函数采用ReLU。分类器的输出数量由数据集中某个答案在唯一问题的最小出现次数确定,而这个答案在整个数据集中出现了9次,因此分类器的输出维度为3129。损失函数采用二元交叉熵。
对于Flickr30k Entities任务,使用双线性注意力图的输出,采用二元交叉熵作为损失函数。
(4)超参数设置和正则化策略

7、VQA结果和讨论
(1)量化结果
- 与最先进技术的比较
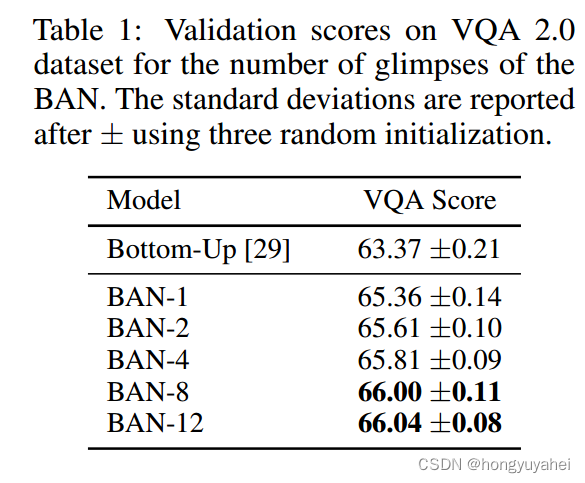
表格1中的第一行展示了2017年VQA挑战的获胜架构。BAN明显优于这个基准,并成功地利用了高达八个双线性注意力图,通过注意力的残差学习来改善性能。
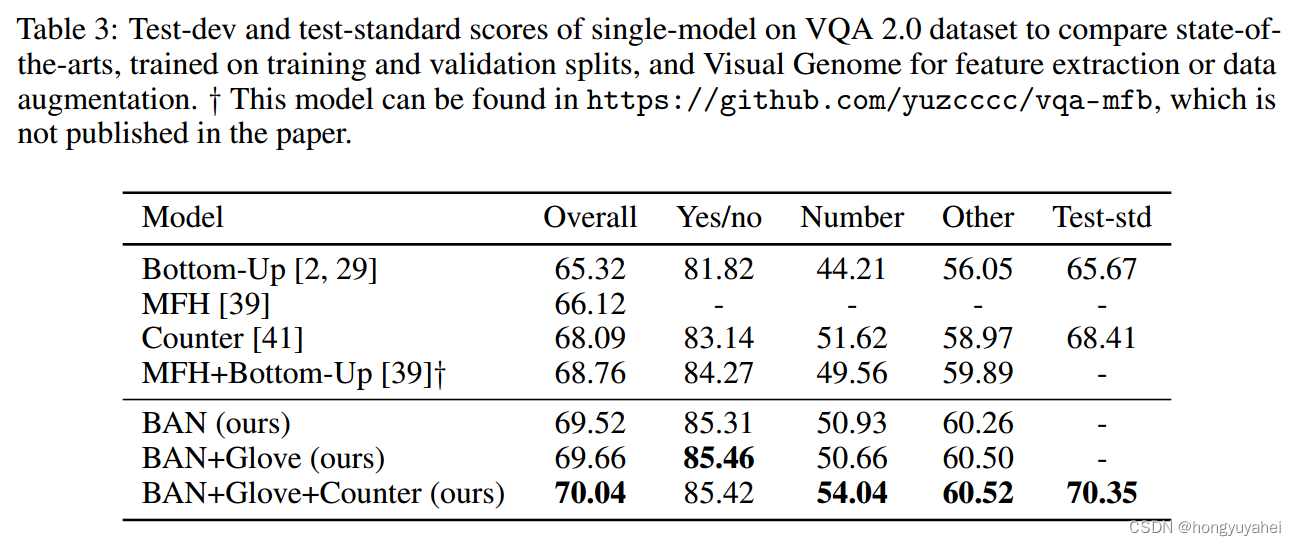
如表3所示,BAN在性能上远远优于使用相同bottom-up注意力特征的最新模型。BAN-Glove使用300维的Glove单词嵌入和这些嵌入的语义封闭混合的串联形式(见附录A.1)。请注意,表3中的竞争性模型中可以找到类似的方法,它们对相同的600维词嵌入采用不同的初始化策略。BAN-Glove-Counter同时使用了先前的600维词嵌入和计数模块,该模块利用来自特征提取器的检测到的对象框的空间信息。计数机制的学习表示c ∈ R^(φ+1)经过线性投影并在应用ReLU后添加到联合表示中(见附录A.2中的方程15)
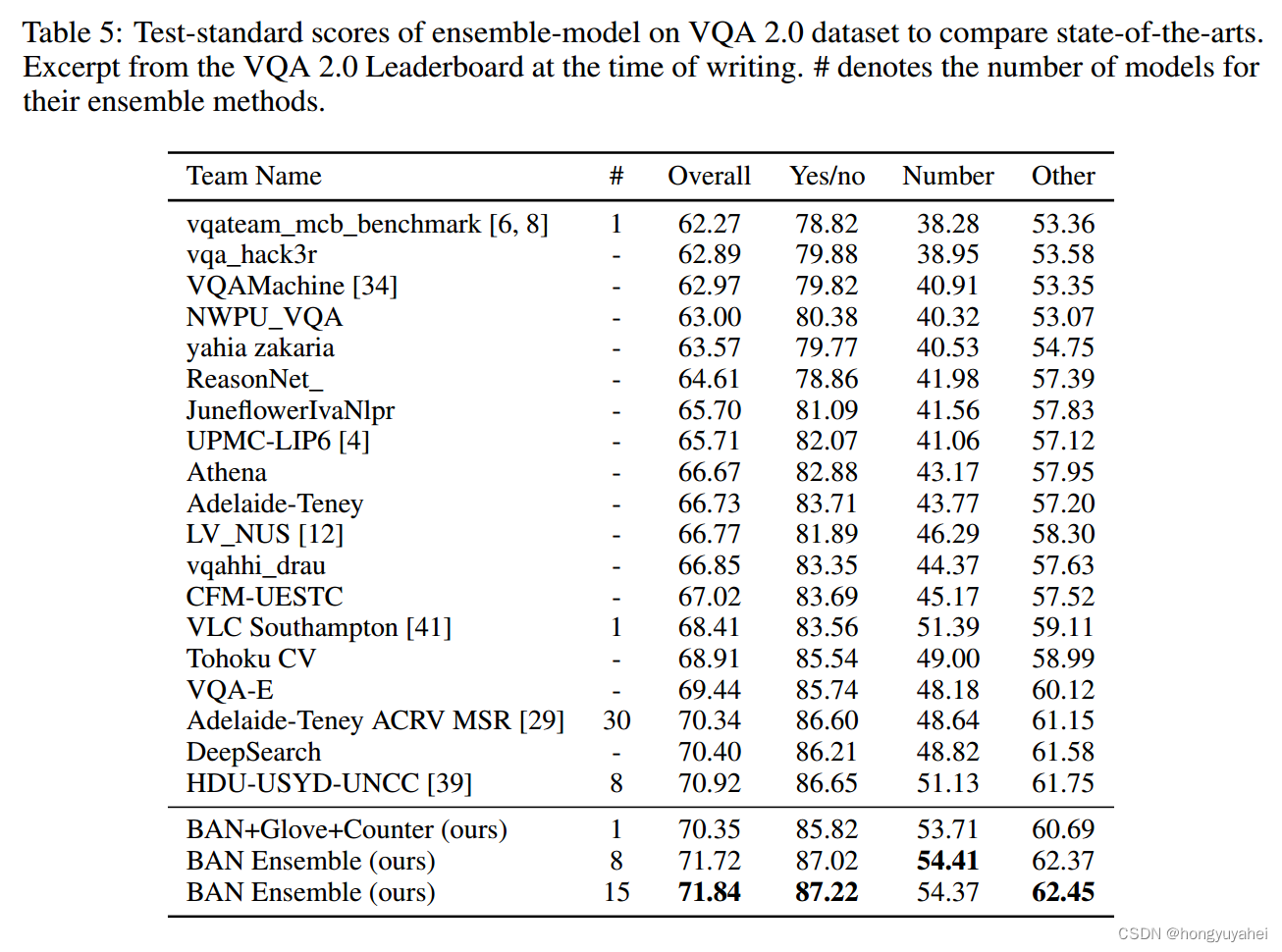
在表5(附录)中,我们与VQA Challenge 2017和2018的排行榜条目进行比较,我们在提交时获得了第一名(由于挑战条目不可见,我们的条目未显示在排行榜上)。
- 去其他注意力模型的比较
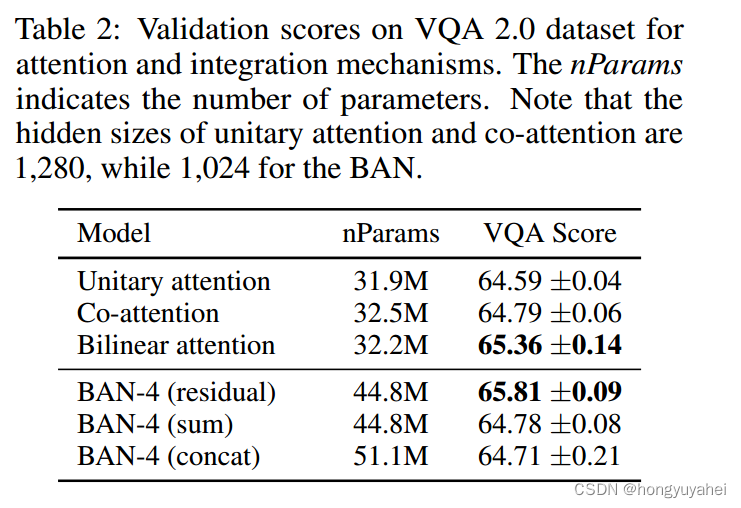
与其他注意力方法的比较。单一注意力与Kim等人的具有相似的架构,其中使用问题嵌入向量来计算图像的多个特征的注意力权重。协同注意力具有与Yu等人[39]相同的机制,类似于Lu等人,Xu和Saenko,其中多个问题嵌入通过自注意力机制组合为单个嵌入向量,然后应用单一视觉注意力。表2证实双线性注意力明显优于任何其他注意力方法。协同注意力略优于简单的单一注意力。
在图2a中,协同注意力(绿色)比其他方法更严重地受到过拟合的影响,而双线性注意力(蓝色)相比其他方法更加规范化。在图2b中,BAN是各种注意力方法中最有效的参数之一。请注意,四个glimpse的BAN比一个glimpse的BAN更节省参数的使用。
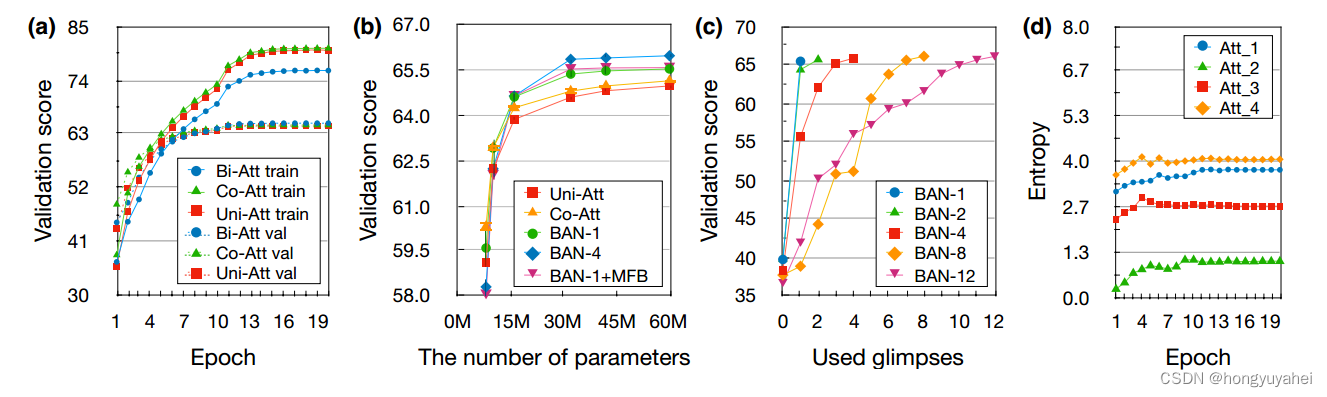
图2:(a)学习曲线。双线性注意力(bi-att)比单一注意力(uni-att)和协同注意力(co-att)更能抵御过拟合。 (b)参数数量的验证得分。误差栏表示在三个随机初始化模型之间的标准差,尽管对于超过15M个参数来说,它太小而难以注意到。 (c)用于评估的前N次glimpses(x轴)的剖析研究。 (d)四次glimpse BAN中每个注意力图的信息熵(y轴)。多个注意力图的熵趋于某些水平。
(2)注意力的残差学习
-
与其他方法的比较
在表2的第二部分中,注意力的残差学习明显优于其他方法,即sum和concatenation(concat)。然而,sum和concat之间的差异并不显著。请注意,concat的参数数量大于其他方法,因为分类器的输入尺寸增加了。
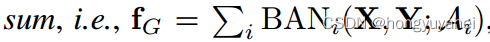
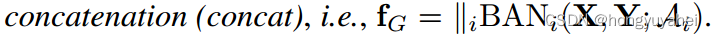
-
消融实验
残差学习的一个有趣特性是对于任意剖析都具有鲁棒性。为了了解相关贡献,我们观察进行增量消融时验证得分的学习曲线。首先,我们使用训练集训练{1,2,4,8,12}-glimpse模型。然后,我们使用前N个注意力图在验证集上评估模型。因此,中间表示fN直接馈送到分类器,而不是fG。如图2c所示,第一个glimpse的准确度增益最高,随着使用的glimpses数量的增加,增益逐渐减小。 -
注意力的熵
我们分析了四次glimpse BAN中注意力分布的信息熵。如图2d所示,验证集中每个注意力的平均熵趋于不同水平的值。这个结果在其他数量的glimpse模型中也可重复观察到。我们的猜测是,多个注意力图对模型的学习并不均等地做出相似的贡献,而是对多步骤注意力的残差学习有同样的贡献。我们认为这是一个新颖的观察,其中残差学习被用于堆叠的注意力网络。
(3)定性分析
图3展示了一个两次glimpse的BAN的可视化结果。问题是“滑板男子穿什么颜色的裤子”。问题中的关键词和内容词,例如“what”、“pants”、“guy”、“skateboarding”,以及图像中滑板者穿的裤子都受到了关注。请注意,框2(橙色)捕捉到了底部坐着的男子的裤子。
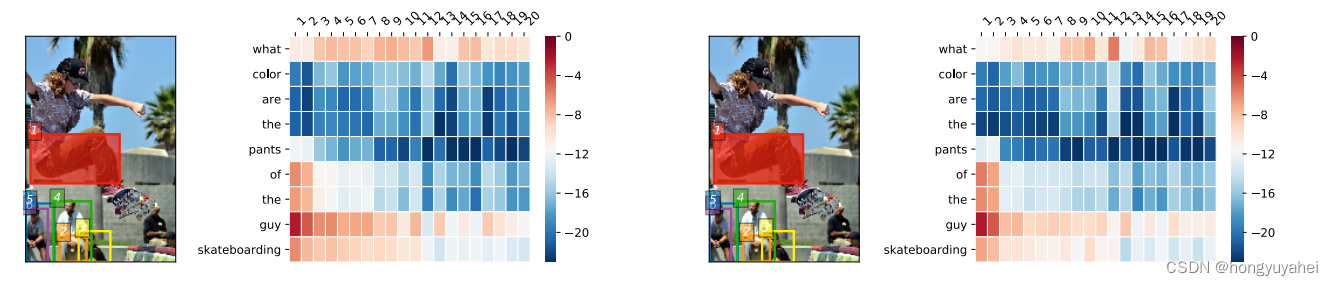
图3中的结果,即两次glimpse的BAN的双线性注意力图的可视化。图中左右两组分别表示第一个和第二个双线性注意力图,同时显示了可视化的图像。在每组中,右侧是对数缩放的注意力图,左侧是可视化的图像。通过边缘化确定的第一个注意力图中最显著的六个框在两个图像上都进行了可视化以进行比较。模型给出了正确的答案,即裤子的颜色是褐色。
8、Flickr30k的结果及讨论
为了检验双线性注意力图捕捉视觉-语言交互的能力,我们在Flickr30k Entities上进行了实验。我们的实验结果表明,在推理速度较高的情况下,BAN在短语定位任务上的性能远远超过了先前的最先进技术,差距达到了4.48%。
- 性能
在表4中,我们与其他先前的方法进行了比较。我们的双线性注意力图用于预测句子中短语实体的边界框,在Recall@1取得了69.69%的新水平。考虑到BAN没有使用任何额外的特征,如边界框大小、颜色、分割或姿态估计这个结果是显著的。请注意,Query-Adaptive RCNN和我们的现成对象检测器 都是基于 Faster RCNN 并在 Visual Genome上进行预训练的。与 Query-Adaptive RCNN 相比,我们对象检测器的参数是固定的,并且仅用于提取 10-100 个视觉特征和相应的边界框提议。
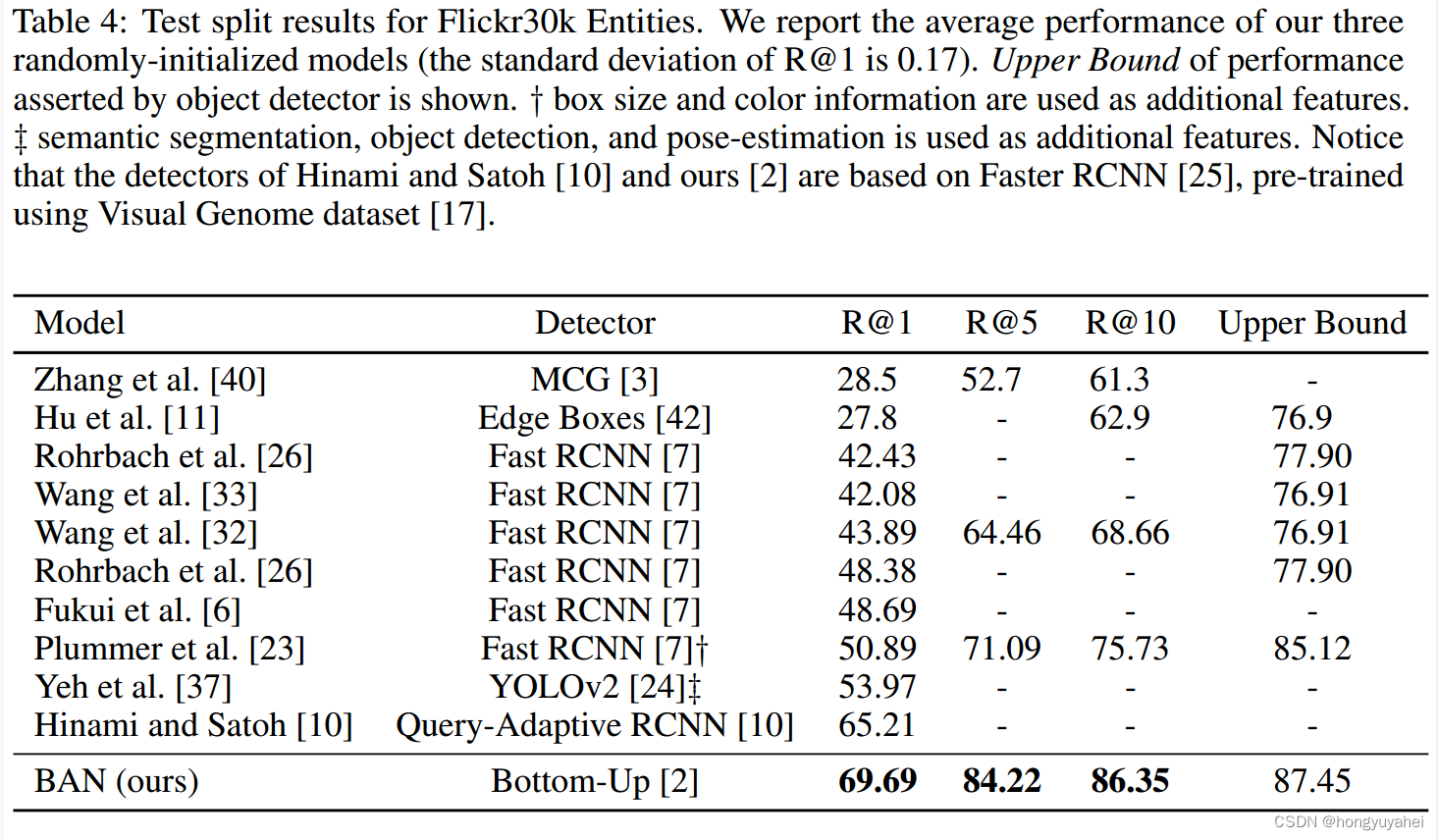
表4:Flickr30k Entities的测试分割结果。我们报告了我们三个随机初始化模型的平均性能(R@1的标准差为0.17)。给出了目标检测器断言的性能上限。请注意,Hinami和Satoh以及我们的检测器都基于 Faster RCNN,在 Visual Genome 数据集上进行了预训练。
- 类型
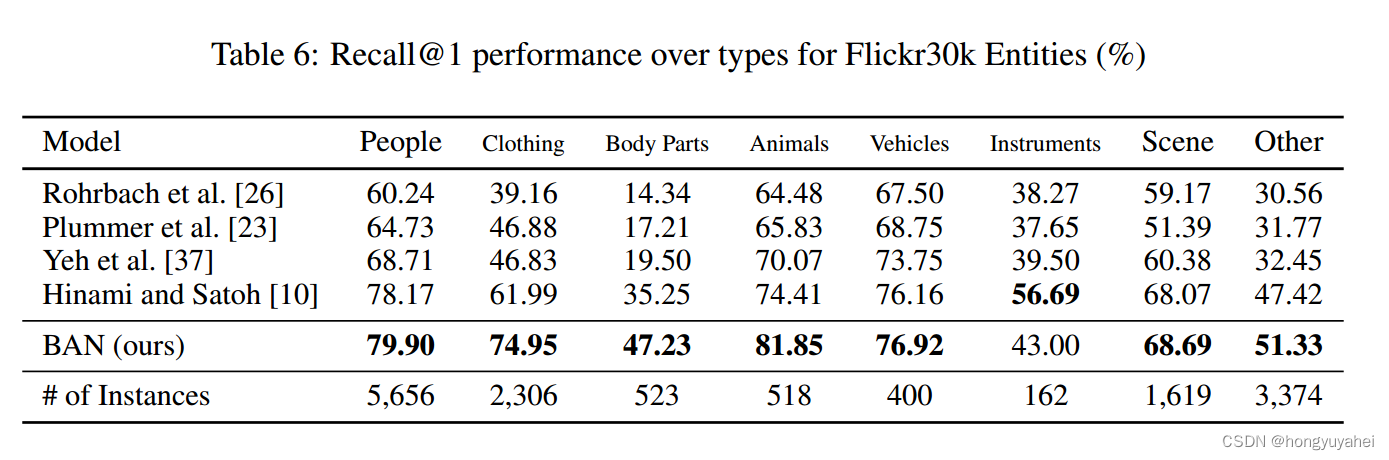
在表6中,我们报告了每种类型的Flickr30k Entities的结果。请注意,服装和身体部位的性能显著提高,分别达到了74.95%和47.23%。
- 速度
我们的BAN利用多通道输入实现了更快的推理速度。与先前的方法不同,BAN能够推断句子中的多个实体,这可以准备成一个多通道输入。因此,需要推断的前向传播次数显著减少。在我们的实验中,BAN每个实体花费0.67毫秒,而将单个实体作为示例的设置花费0.84毫秒,实现了25.37%的改进。我们强调这个性质在我们的模型中是新颖的,考虑了视觉-语言多通道输入之间的每种交互。
- 可视化
图4显示了来自Flickr30k Entities测试分割的三个例子。在图4a中,具有视觉属性的实体,例如黄色的网球服和白色的网球鞋,是正确的。然而,相对较小的对象(例如图4b中的香烟)和需要语义推断的实体(例如图4c中的男性指挥家)是不正确的。
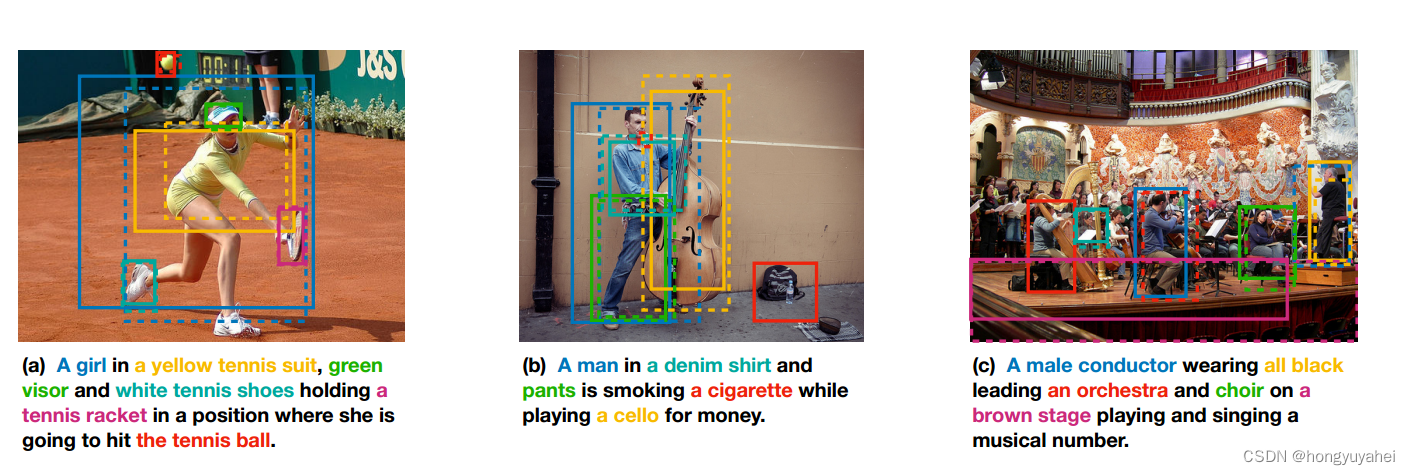
图4:显示了来自Flickr30k实体测试分割的可视化示例。实线框表示预测的短语本地化,虚线框表示基本事实。如果有多个接地真值框,则显示最近的框进行调查。短语的每种颜色都与预测框和基本真值框的相应颜色相匹配。最好的彩色视图。
9、结论
BAN通过优雅地扩展单一注意力网络,利用双线性注意力图,其中使用低秩双线性池提取了多模态多通道输入的联合表示。尽管BAN考虑了每一对多模态输入通道,但由于BAN采用了矩阵链乘法进行高效计算,计算成本仍然保持在相同的数量级。所提出的注意力残差学习有效地利用了多达八个双线性注意力图,保持了中间特征的大小不变。我们相信我们的BAN为学习更丰富的多模态多通道输入的联合表示提供了新的机会,这在许多实际问题中都有应用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 铝材生产ERP有什么用?能为企业带来哪些助力
- libcurl使用默认编译的winssl进行https的双向认证
- matlab画图坐标轴字母使用斜体\it
- 鸿蒙系列--属性动画
- 【Linux】vim配置
- 为什么说网络安全方向已经成为下一个风口?
- 蓝底白字车牌的定位与字符分割识别 MATLAB 仿真
- OpenCV 配置选项参考(二)
- QPushButton样式设置
- 无公网IP环境如何实现远程访问家里内网威联通QNAP NAS中存储的文件