suse ha集群多节点异常重启故障案例一则
??关键词
- suse linux hae 、pacemaker
- oracle、nfs
-
crm_failcount、timeout、trace
一、问题现象
接故障反馈,某业务几套suse ha集群系统,在某天不同时间点,分别发生了oracle数据库及主机异常切换重启的故障现象,数据库切换重启期间,业务作业受到影响。需排查具体切换原因,及故障风险问题解决。
二、问题分析
好几套集群差不多时间共同出现问题,从经验判断应该是某种共性问题导致。先跟一线了解下相关基础环境,得知,是有个6套suse ha的高可用集群,底层虚拟化平台支撑,业务使用oracle+nfs。梳理每套集群异常现象和时间点,发现有的集群只是重启了数据库,有的集群重启过主机,有的集群啥也没重启,之间是有些区别。
三、处理过程
了解完基本信息后,上每台主机看看日志吧,系统层优先检查/var/log/message。
多台主机日志中均记录了每次故障时HA双机资源超时事件日志:并且伴随有CPU高负
载告警;资源监控拉起失败多次后,节点发生切换SBD事件,主机节点操作系统被强制重启。
部分告警信息如下:
pacemaker-controld[7556]: error: Result of monitor operation for rsc_db_XXX?on node1: Timed out---集群监测到资源监控超时
pacemaker-attrd[7554]: notice: Setting last-failure rsc_db_XXX monitor_3000[node1]: 1685340011 -> 1685341059----超时后对资源计数值加1
pacemaker-controld[7556]:notice: Hig CPU load detected: 147.410004---集群伴随着有CPU负载异常增高的情况
sbd[7325]:emerg: do_exit: Rebooting system: reboot---最后切换失败的集群触发了sbd强制重启操作
分析到此,不难看出故障跟集群自身有些关联,都是有同类资源监控超时触发后续一系列问题现象,查看数据库双机资源参数配置情况,资源的定义如下,超时时间为180秒,每隔30秒探测一次,on-failed的动作为自动重启
primitive rsc_db_XXX? oracle \
????????params sid=XXX \
????????op monitor interval=30 on-fail=restart timeout=180 \
双机日志中可以看到在3分钟的时间里monitor监控没有获取到返回值。从HA的角度来看就意味着这个资源异常会尝试拉起资源,在尝试拉起的过程中,如果正常启动那么就会fail-count计数,如果尝试很多次依然失败就会触发切换动作,甚至会触发SBD将节点置于unclean的状态fence掉节点。?
并且在其中一套集群切换此次事件日志中,发现在资源异常的时间节点,作为nfs客户端也有无法连接到NFS 服务器的告警。检查NFS服务端,发现服务端也有异常告警。怀疑此次切换事件与nfs异常有一定关联。
再次核对6套集群架构中nfs的部署情况,得知有5套nfs部署在同一服务端,1套是另外nfs服务端,而出问题的集群均发生在这5套共用nfs集群上,这更加证实了nfs导致异常切换的可能性。
随后对nfs重点监控,发现此后每次集群日志出现异常后,nfs均伴随有相关短暂告警,最后业务在暂时无法调整nfs的情况下,把集群资源监控monitor超时时间从180s调整到300s后,临时解决了由于nfs短暂性异常导致的切换问题。最终根据评估,业务对nfs实施迁移调整,彻底根治这一隐患问题。
四、知识拓展
1、关于suse ha的failcount的机制
crm_failcount 命令可查询指定节点上每个资源的故障计数。此工具还可用于重设置故障计数,同时允许资源在它多次失败的节点上再次运行。
Heartbeat实现了一种复杂的方法来计算资源,并在资源出现故障时强制将其故障转移到另一个节点在当前节点上。资源带有resource_stickness属性,以确定它更喜欢在某个节点上运行的程度。它还携带resource_failure_stickness,该值确定资源应故障转移到另一个节点的阈值。
failcount属性将添加到资源中,并在资源监视失败时增加。故障计数的值乘以resource_failure_stickness的值决定了该资源的故障转移分数。如果此数字超过为此设置的首选项资源,则资源被移动到另一个节点,并且在重置故障计数之前不会在原始节点上再次运行。

生产上配置
rsc_defaults rsc-options: \
? ? ? ? resource-stickiness=100 \
? ? ? ? migration-threshold=3
primitive rsc_db_XXX oracle \
? ? ? ? params sid=XXX \
? ? ? ? op monitor interval=30 on-fail=restart timeout=180 \
? ? ? ? meta priority=1000 target-role=Started
生产上当前配置,资源在出现故障时会自动重启动。如果在当前节点上无法实现此操作,或者此操作在当前节点上失败了 3次,它将尝试故障转移到其他节点。每次资源失败时,其失败计数都会增加。您可以定义资源的故障次数(migration-threshold),在该值之后资源会迁移到新节点。如果群集中存在两个以上的节点,则特定资源故障转移的节点由 High Availability 软件选择。
? ?
综上failcount只是计数功能,这个计数是会和集群配置里面的migration-threshold值进行比对,如果大于定义的migration-threshold值,会将资源迁移到备机。迁移之前会不断尝试重启资源。
?
?2、监控timeout的机制

生产配置
特定资源的超时
primitive rsc_db_XXX oracle \
? ? ? ? params sid=XXX \
? ? ? ? op monitor interval=30 on-fail=restart timeout=180 \
? ? ? ? meta priority=1000 target-role=Started
全局的超时配置
op_defaults op-options: \
? ? ? ? timeout=600 \
? ? ? ? record-pending=true
Once a resource has a stop failure, the node is supposed to be fenced to recover from the failure. It is taking 10 minutes for the resource to detect and recover from the stop failure.
--一旦资源出现停止故障,就应该对节点进行隔离以从故障中恢复。资源需要10分钟才能检测到停止故障并从中恢复。?
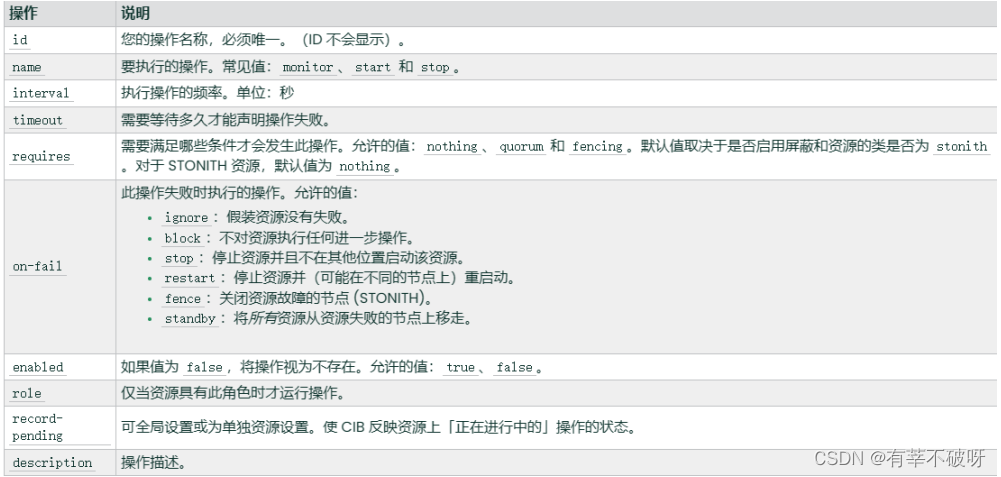
综上,当集群监控资源的role为启动状态的时候,每隔30秒会监测探测一次,
如果您发现系统中包含的资源需要的时间超过了系统允许的执行操作(如启动、停止或监视)的时间,请调查原因,如果预计执行时间过长,则可以增加此值。超时值不是任何类型的延迟,如果操作在超时期完成之前返回,集群也不会等待整个超时期。
资源目前定义是180秒超时,每隔30秒探测一次,当180秒还没有得到返回值时,会将资源置于失败状态。Failcount会增加资源计数一次。
官方手册参考:https://documentation.suse.com/zh-cn/sle-ha/15-SP3/single-html/SLE-HA-administration/#sec-ha-config-basics-monitoring?
3、关于trace资源监控
针对资源无法正常启动的状况,无法排查到原因的,可以打开资源的trace功能,方法如下:
参考 https://www.suse.com/support/kb/doc/?id=000019138
Enable resource tracing:
crm resource trace <resource name> <operation>
??????????????<resource name> - any defined primitive in the cluster
??????????????<operation>??- start, stop, monitor, probe
Disable resource tracing:?
crm resource untrace <resource name><operation>
Debug trace file location:
/var/lib/heartbeat/trace_ra/<resource>/*timestamp
然后根据trace文件看是否可以定位问题发生的原因。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 十二、K8S之污点和容忍
- C语言经典算法之顺序查找算法
- 大创项目推荐 深度学习卷积神经网络的花卉识别
- Java数据结构栈的实现(顺序结构) 以及相关练习题
- torch: 返回最大的几个值--topk()
- 设计模式——观察者模式(Observer Pattern)
- 生产管理MES系统+源码+技术支持,直接拿来搞钱的好项目
- Golang 的内存管理
- Spring boot封装rocket mq 教程
- 说说 Spring Boot 实现接口幂等性有哪几种方案?