Speech | 语音克隆Openvoice的论文解读及项目实现
本文主要介绍了语音克隆Openvoice的论文以及项目实现~
论文题目:OpenVoice: Versatile Instant Voice Cloning
论文地址:2312.01479.pdf (arxiv.org)
1.论文详解?
1.1.论文概述?
论文介绍了 OpenVoice,这是一种通用的语音克隆方法,只需要参考说话者的简短音频剪辑即可复制他们的声音并生成多种语言的语音。OpenVoice 在解决该领域的以下开放挑战方面取得了重大进展:1) 灵活的语音风格控制。OpenVoice 支持对语音风格进行精细控制,包括情感、口音、节奏、停顿和语调,以及复制参考扬声器的音调颜色。语音样式不会直接从参考说话人的风格复制并受其约束。以前的方法缺乏在克隆后灵活操纵语音样式的能力。2)零样本跨语言语音克隆。OpenVoice 实现了零样本跨语言语音克隆,适用于未包含在大规模说话人训练集中的语言。与以前的方法不同,以前的方法通常需要针对所有语言的大量说话人多语言 (MSML) 数据集,OpenVoice 可以将语音克隆为一种新语言,而无需该语言的任何大规模说话人训练数据。OpenVoice 的计算效率也很高,其成本比性能较差的商用 API 低数十倍。为了促进该领域的进一步研究,公开了源代码和训练模型。演示网站中提供定性结果。在公开发布之前,内部版本的 OpenVoice 在 2023 年 5 月至 10 月期间被全球用户使用了数千万次,作为 MyShell 的后端。
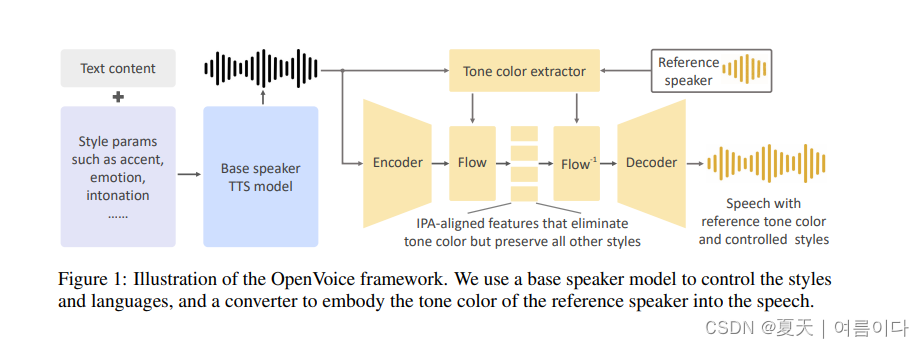
1.2.OpenVoice的模型结构
主要包括两个组件:基础语音合成模型和音色转换器。
基础语音合成模型可以是单一说话者或多说话者模型,允许控制风格参数(如情绪、口音、节奏、停顿和语调)、口音和语言。该模型生成的语音传递给音色转换器,将基础说话者的音色转换为参考说话者的音色。音色转换器采用编码-解码结构,并使用可逆归一化流来转换音色信息。
在基础语音合成模型中,可以选择各种灵活的模型,如VITS、InstructTTS或商业可用的模型(如Microsoft TTS)。论文中使用了VITS模型作为默认选择,但也提到其他选择完全可行。标记了基础模型输出为X(Lo, So, Co),表示语言、风格和音色三个参数。
音色转换器包含编码器和解码器,中间使用可逆的归一化流。编码器是一个一维卷积神经网络,接受基础模型输出的频谱作为输入,输出特征图Y(LI, SI, CI)。音色提取器则是一个简单的二维卷积神经网络,作用在输入声音的梅尔频谱上,输出一个编码了音色信息的单一特征向量。接着,归一化流层将特征Y(LI, SI, CI)和音色信息向量v(CI)作为输入,输出一个消除音色信息但保留所有其他风格属性的特征表示Z(LI, SI)。这个特征与国际音标(IPA)对齐,并且在接下来的步骤中,归一化流层逆向作用,将Z(LI, SI)和参考说话者的音色信息v(CO)转换为包含参考说话者音色的特征图Y(LI, SI, CO)。最后,Y(LI, SI, CO)被解码为包含目标音色的原始波形X(LI, SI, CO)。
作者提到了OpenVoice的创新之处在于其分离了语音风格和语言控制与音色克隆。这种分离的方法简单而有效,特别适合想要控制风格、口音或泛化到新语言的情况。相较于像XTTS这样耦合的框架,OpenVoice需要的数据和计算量更少,并且更容易实现流利的多语言语音合成。这种分离语音风格和语言生成与音色生成的核心理念是OpenVoice的特色。
项目复现
git clone https://github.com/myshell-ai/OpenVoice.git
cd OpenVoice
pip install -r requirements.txt
wget https://myshell-public-repo-hosting.s3.amazonaws.com/checkpoints_1226.zip
unzip checkpoints_1226.zip
# 修改demo_part1.ipynb中的openai key就可以直接运行
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【计算机网络 谢希仁 第八版笔记】第二章 物理层
- Kubernetes 架构原则和对象设计
- pytorch与cuda版本对应关系汇总
- 【安全学习】-网络安全靶场实训演练系统建设方案
- 计算机网络面试八股复习:常见的7/5/4层网络模型、各层协议以及键入网址到显示页面的流程
- 北重T型槽平台厂家介绍铸铁平台在业界有怎样的优势
- 2024山东健博会/济南大健康展/中国大健康展/营养健康展
- 【C++】内存管理
- 分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】
- Keil编译STM32工程,提示__align(4)处语法错误