对Transformer的理解。
要理解Transformer,需要先理解注意力机制,下面大部分内容来自台大教授李宏毅老师讲课资料。
注意力机制
之前使用的MLP,CNN,RNN模型可以解决一些简单序列问题,但当序列长度太长容易失去效果,原因是看了新的忘了旧的,网络很难关注到相距很远的 token 之间的联系,于是注意力机制被引入到深度学习中,并且目前已经一招鲜吃遍天了。
注意力的设计可以有很多方式,如下图的两种设计方式。绿色框表示两个token。

目前大部分采用第一种方式,下面来说说自注意力机制。
设想我们要在一大堆文档里面通过关键词快速搜索到最相关的文档,一个较为合理的做法就是首先通过词频-逆文档频率或其他方法得到所有文档对应的特征词语,然后使用关键词和每个文档的特征词之间的相似度,这个分数就叫做attention score,关键词就是q,特征词就是k,如果我们最终是要得到一个特征向量,那么就讲attention score和每个文档特征进行加权求和,当然首先需要对attention score 经过一个softmax层进行归一化。那么这里的文档特征就类似于v。
如下图这是Attention Score的计算方式
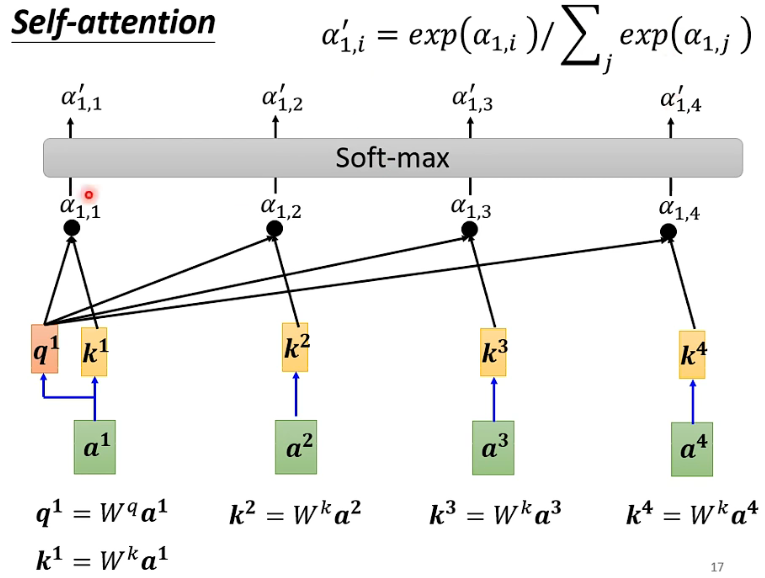
首先将每个token
(
a
1
,
a
2
,
a
3
,
a
4
)
(a^1,a^2,a^3,a^4)
(a1,a2,a3,a4)经过参数矩阵
W
q
W^q
Wq 计算得到
(
q
1
,
q
2
,
q
3
,
q
4
)
(q^1,q^2,q^3,q^4)
(q1,q2,q3,q4)和参数矩阵
W
k
W^k
Wk 计算得到
(
k
1
,
k
2
,
k
3
,
k
4
)
(k^1,k^2,k^3,k^4)
(k1,k2,k3,k4),然后将每个 q 与 k 进行计算得到 attention score 再经过softmax层进行归一化。
得到注意力特征向量
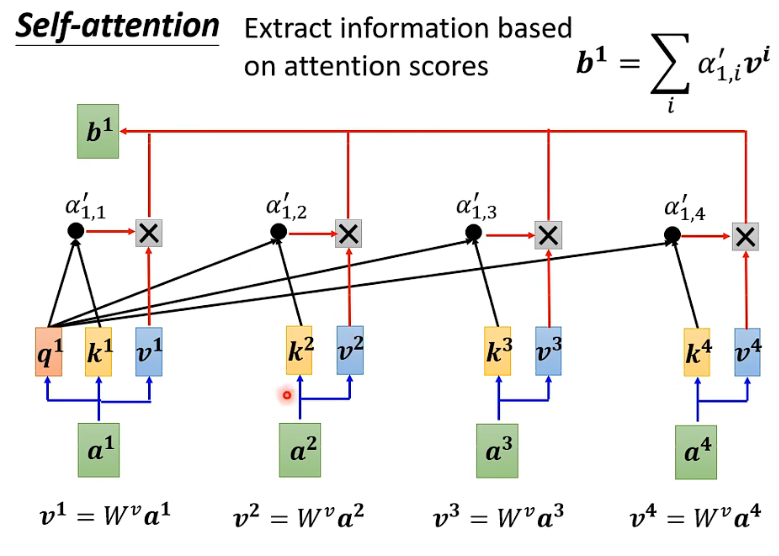
使用归一化的注意力分数乘以v再加权求和得到
a
1
a^1
a1 对应的全局特征向量
b
1
b^1
b1,后面的计算方式相似,相继得到
b
2
,
b
3
,
b
4
b^2,b^3,b^4
b2,b3,b4等等。
如果用矩阵来表示就是:
K
=
W
K
A
Q
=
W
Q
A
V
=
W
V
A
B
=
V
s
o
f
t
m
a
x
(
K
T
Q
)
K = W^KA\\ Q = W^QA\\ V=W^VA\\ B = V softmax(K^TQ)
K=WKAQ=WQAV=WVAB=Vsoftmax(KTQ)
其特点是可以并行运行、输入输出长度相同。
多头注意力
多头注意力就是每个词获得多个k,q,v对,这样做的主要目的是每个k,q,v对可能代表不同的侧重点,同时扩充网络参数。
Encoder层
Transformer的Encoder
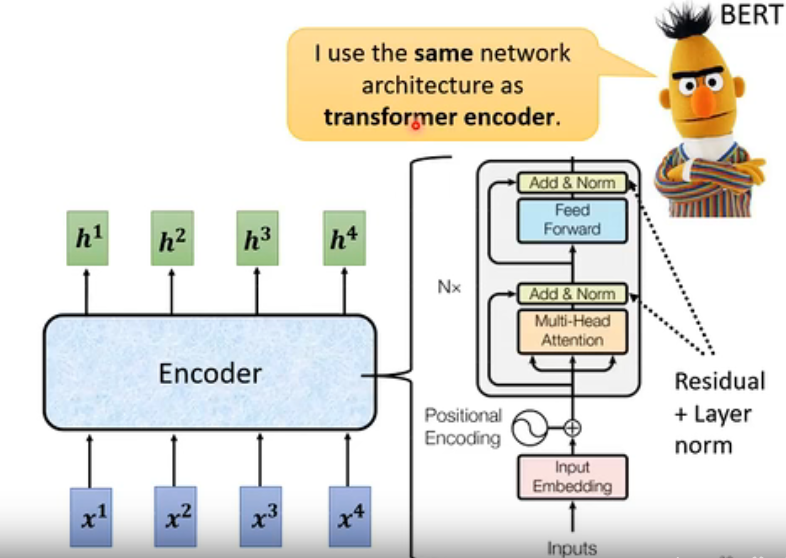
首先将原始token经过多头注意力注意力层得到注意力特征,然后经过残差加和和层正则化,将正则化结果输入到前馈网络里面再进行残差加和和层正则化。
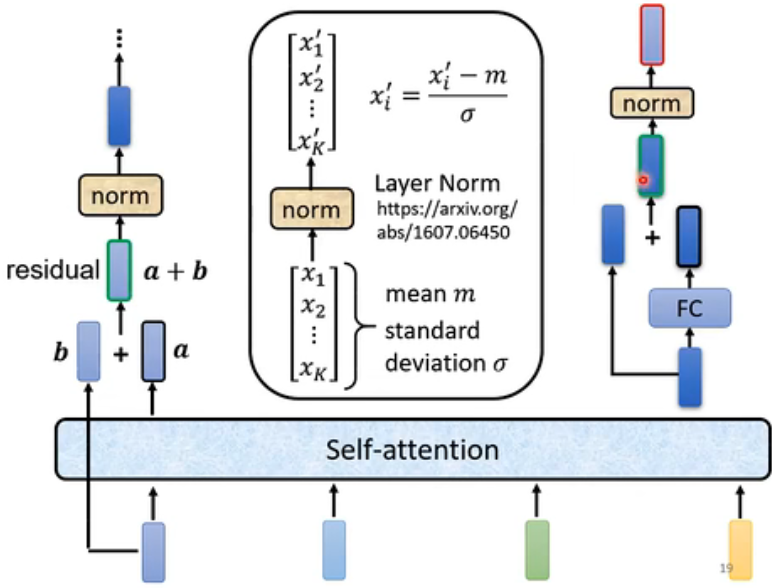
详细结构
Decoder层
Decoder层和Encoder很类似,如果不看交叉注意力的的话。
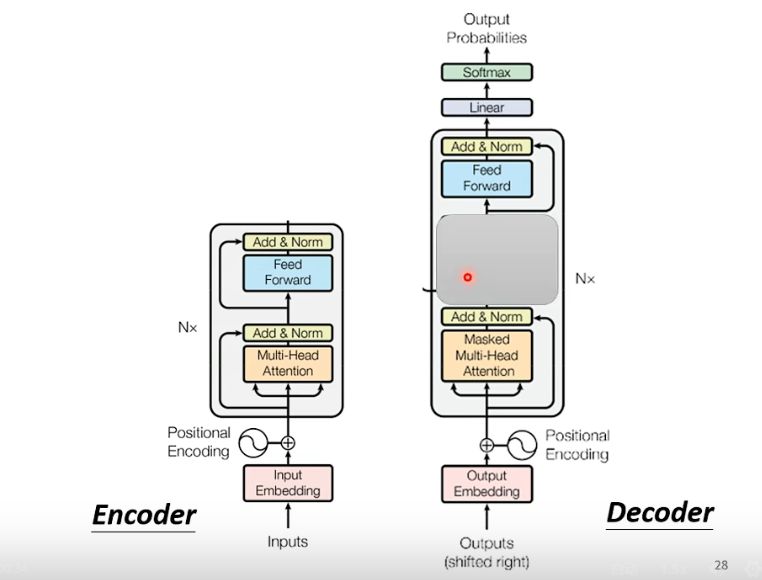
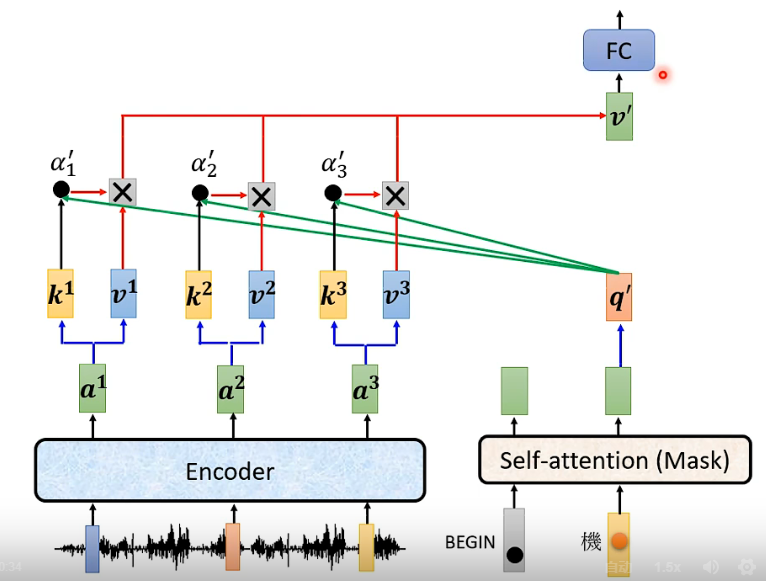
交叉注意力,用当前的查询向量q去计算对方的注意力分数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [足式机器人]Part2 Dr. CAN学习笔记-自动控制原理Ch1-3燃烧卡路里-系统分析实例
- Spring Cloud+SpringBoot b2b2c:Java商城实现一件代发设置及多商家直播带货商城 免 费 搭 建
- 【日志系列】什么是分布式日志系统?
- 解决IDEA自动生成返回值带有final修饰的问题
- ssm爱心慈善公益网站(开题+源码)
- QT开源类库集合
- git常用命令
- C语言例题3
- OpenNL线性系统求解库
- TablePlus 5 数据库管理工具 Mac 下载安装详细教程(保姆级)