读论文1:Towards Unsupervised Domain Generalization
记录读论文的过程,如果哪里不对,请各位大佬指正。
 标题:Towards Unsupervised Domain Generalization
标题:Towards Unsupervised Domain Generalization
Abstract:
Domain generalization (DG) aims to help models trained on a set of source domains generalize better on unseen target domains. The performances of current DG methods largely rely on sufficient labeled data, which are usually costly or unavailable, however. Since unlabeled data are far more accessible, we seek to explore how unsupervised learning can help deep models generalize across domains. Specifically, we study a novel generalization problem called unsupervised domain generalization (UDG), which aims to learn generalizable models with unlabeled data and analyze the effects of pre-training on DG. In UDG, models are pretrained with unlabeled data from various source domains before being trained on labeled source data and eventually tested on unseen target domains. Then we propose a method named Domain-Aware Representation LearnING (DARLING) to cope with the significant and misleading heterogeneity within unlabeled pretraining data and severe distribution shifts between source and target data. Surprisingly we observe that DARLING can not only counterbalance the scarcity of labeled data but also further strengthen the generalization ability of models when the labeled data are insufficient. As a pretraining approach, DARLING shows superior or comparable performance compared with ImageNet pretraining protocol even when the available data are unlabeled and of a vastly smaller amount compared to ImageNet, which may shed light on improving generalization with large-scale unlabeled data.
领域泛化(DG)旨在帮助在一组源领域上训练的模型更好地泛化到未见过的目标领域上。然而,当前 DG 方法的性能主要依赖于充足的标记数据,而这些数据通常成本高昂或不可用。由于无标记数据更容易获取,我们试图探索无监督学习如何帮助深度模型实现跨域泛化。具体来说,我们研究了一个新颖的泛化问题,称为无监督领域泛化(UDG),旨在利用无标记数据学习可泛化模型,并分析预训练对 DG 的影响。在 UDG 中,先用来自不同源域的无标记数据对模型进行预训练,然后再用有标记的源数据进行训练,最后在未见过的目标域上进行测试。然后,我们提出了一种名为 "领域感知表征学习(DARLING)"的方法,以应对未标注预训练数据中存在的显著和误导性异质性,以及源数据和目标数据之间的严重分布偏移。令人惊讶的是,我们发现 DARLING 不仅能抵消标记数据的稀缺性,还能在标记数据不足时进一步增强模型的泛化能力。作为一种预训练方法,DARLING 与 ImageNet 预训练协议相比,即使在可用数据为无标记数据且数据量远小于 ImageNet 的情况下,也能显示出优越或相当的性能。
0.abstract总结:
1.提出了UDG(无监督域泛化)问题
2.介绍了UDG问题训练的步骤:先用来自不同源域的无标记数据对模型进行预训练,然后再用有标记的源数据进行训练,最后在未见过的目标域上进行测试
3.提出DARLING(领域感知表征学习),解决的问题是:
(1)未标注预训练数据中存在的显著和误导性异质。
(2)源数据和目标数据之间的严重分布偏移。
(3)意外发现,该模型能在标记数据不足时进一步增强模型的泛化能力。
1.Introduction总结:
第一段:为了解决distribution shift的问题,DG的文献提出了一些算法,他们可以访问多个领域或环境中的标记数据,并能很好地泛化到未见过的测试领域 。
第二段:当前DG方法必须需要充足的数据,如果不够,可以通过数据增强来扩充。但是,基于增强的方法和经过仔细超参数调整的 ERM 都有一个假定:来自多个领域的充足标记数据可供表征学习使用。(作者想表达的是当数据不足或事不是来自多个领域的情况)
第三段:
(1)提出UDG(无监督领域泛化),
(2)目的:在无监督的情况下学习跨领域泛化能力强的判别表征,从而减少 DG 方法对标记数据的依赖。
(3)具体步骤:在对模型进行微调和评估之前,先用无标记的异构数据对模型进行训练。(作者说:这样就可以很容易地将 UDG 方法与当前的 DG 方法组合起来作为预训练,并研究预训练如何影响模型的泛化能力。)ps:这里不明白为什么作者这么说......
第四段:
(1)这里开始引入了对比学习,介绍什么是对比学习,(没有对比学习基础的小伙伴还是建议专门去学习一下对比学习的基础啊,可以去b站上看一下沐神的对比学习串烧,p s.本人为了给老师汇报特意整理了一下做了100页ppt,看了好几遍视频也没有做一个ppt记得这么印象深刻......)对比学习的目标是在与底片对比的同时,最大限度地提高给定图像及其变体在干扰下的相似度[16, 34, 67],这与 DG 的目标不谋而合。(为什么不谋而合???我感觉这里写的是有一点牵强的)
(2)介绍对比学习局限性:?目前的CL只能针对独立且同分布(I.I.D)假设下的预定扰动学习稳健表征,而无法考虑预定扰动类型之外的跨域严重分布偏移。 ? ??
(3)为什么当前对比学习不能解决UDG问题?解答:
第一:该对比学习中负样本对是来自不同领域的样本,当前的 CL 方法会同时利用与领域相关的特征(即与类别无关的特征)和类别 区分特征来推动其表征。(私密马赛实在不知道这句话说得什么意思,原文就是这么说的,我翻译了一下写在了这里)
第二:在 UDG 中,训练数据的跨领域分布偏移非常明显,无法通过数据转换完全抵消(例如,很难将草图中的狗转换为照片)。强烈的异质性会促使模型利用与领域相关的特征来区分一个样本和它的负样本对,从而阻碍了不变表征空间的学习,在这个空间中,跨领域的不相似性最小。
(这句话我个人的理解是,比如有两个域:彩色域和黑白域;正样本是小猫,负样本是一个小狗,模型会因为异质性使模型认为彩色的动物都是小猫,黑白的动物都是小狗,这导致了模型准确率的降低,ps,我也不知道对不对,我是这么理解的)
第五段:为了以上这个问题,我们提出DARLING(领域感知表征学习),这是一种用于 UDG 的新型对比学习算法,它将 DG 和对比学习的目标统一起来。
具体做法:选择有效的负样本(理论依据,原文:个领域越相似,负面对中的两个样本就越有可能分别来自这两个领域。直观地说,考虑来自两个领域的样本,它们的分布差异巨大,与领域相关的特征足以将它们区分开来,进而提高表征空间中跨领域的方差。相反,如果一对负样本来自单一领域,并且具有相同的领域相关特征,那么与领域无关的表征就会被学习出来,从而形成对比。)
第六段:暂时还没看懂...... ?感觉就是吹了一段他这个模型有多牛b
2.Related work:域泛化+无监督学习(略)
3. Methods
3.1. Unsupervised Domain Generalization

????????在有类别标签的情况下,我们将数据集描述为有标签的数据集,而其他数据集则描述为无标签的数据集。我们的目标是学习一个可通用于任何未知测试分布的模型。 问题的形式定义如下:(此处是上一段翻译)
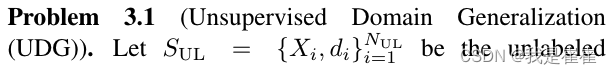

????????This setting is sound since we can consider the source or mechanism of data generation as the domain while the latent structure of data other than domains determines the categories. Accordingly, the domain label is significantly easier to access while category labeling can be expensive, leading to a large scale of data with domain label while without category label.(此处是原文)
????????这种设置是合理的,因为我们可以将数据生成的来源或机制视为领域,而领域之外的数据潜在结构则决定了类别。相应地,领域标签更容易获取,而类别标签的获取可能会很昂贵,从而导致大量数据有领域标签而无类别标签。(原文)
作者列出了有标签数据和无标签数据关于类、域、特征的几种可能:All correlated、Domain correlated、Category correlated、Uncorrelated

 ???????
???????
3.2. Domain-irrelevant unsupervised learning
? ? ? ? 提出了DARLING算法,步骤:(1)先用无标签数据在DARLING进行预训练(2)使用有标签数据对于数据进行微调(微调视为标准的DG设置)
? ? ? ? 介绍了一下传统对比学习的损失函数:
(但是这个传统的对比学习是有弊端的,前面说了)???????
作者又提出了MOCO这篇文章里的NCEloss函数(公式5)

传统的对比学习的classifier在不同的领域下,标签 D 下可能不同,这就导致了模型的错误规范。因此提出了下图新概率模型:
(a)以前的(b)改进版
X:特征 ;Y:类别?;D:域标签
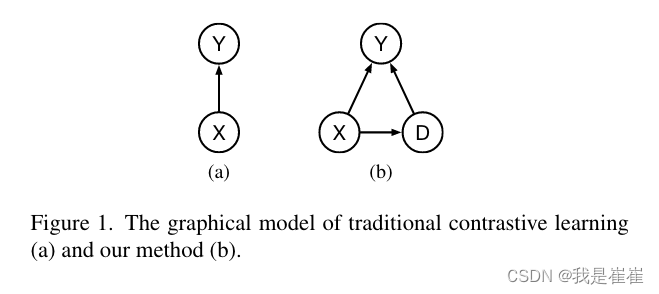
公式(6)说的是:第一行与相关的情况,第二行域无关的情况

编码器浅层的特征输出被送入额外卷积网络和相似性预测器的堆栈,以学习当前输入的领域相似性。我们采用交叉熵作为相似性损失。???????
作者的创新点是在下图中最上面这条线路加了一条相似性预测器,将编码器浅层输入的特征输入后预测与当前输入域的相似性。这时也很好的解释了Figure1里的(b)。并且最后以交叉熵作为损失函数。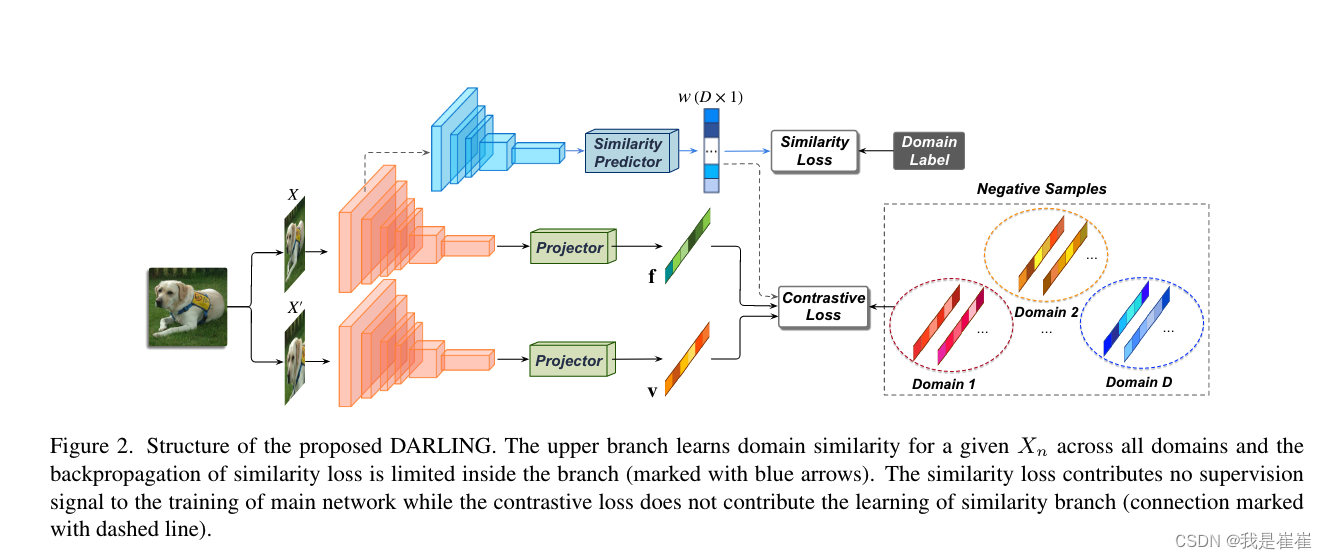
整合了一下公式:
并且最后在计算了领域相似性的同时通过重新加权不同领域的损失,消除领域的相关性(解决了问题)
定义负样本对:将k个负样本划分为D个域(这里其实正常人都没看明白负样本是怎么生成的,么事后面3.3这块他会单独讲)
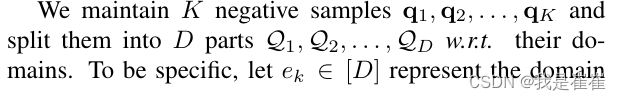

3.3. Domain Specific Negative Samples
? ? ? ? 这里作者开始单独说负样本对是怎么生成的
????????作者提出了一种具有对抗性更新方式的特定领域负面样本生成机制,以密切跟踪每个领域的表征变化。我们的目标可视为:
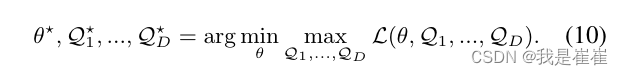

为了简化负样本的计算,作者特意人为定义一个公式进行限制使得一个给定的样本只有助于生成来自同一域的负样本。在这种情况下,作者给出损失函数为
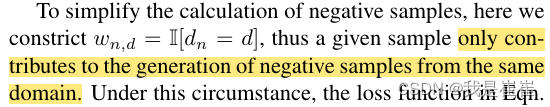

????????我们的目标是为每个领域中的正样本保留hard样本,因此特定领域中的负样本会被推向来自同一领域的query,从而优化 nk,d,使其与相应领域中的正query之间的相似性最大化。建议的特定域负样本生成方法有两方面的优越性。首先,它能生成恒定数量的负样本,而其他更新方法(如 [6] 方法)可能会生成来自不同领域的不同数量的样本。其次,建议的方法生成的hard负样本是每个领域中最容易混淆的负样本对,这与公式 9 一致。
这里的hard是最容易混淆、最顽固的样本,也应证了这里的对抗性学习。
这种方法有两个优点:(1)每次生成恒定的负样本 (2)找到了最hard的负样本(这里是本文的创新点也是一大亮点)
4. Experiments
4.1. Unsupervised Domain Generalization (UDG)
用了四个数据集:DomainNet 、PACS 、CIFAR-10-C 和 CIFAR-100-C?
作者对现实世界中比较常见的四种情况中的三种进行了广泛的实验,即全相关、域相关和非相关。(另一个不常见在附录里)
操作:实验设置中,未标记数据和已标记数据之间的相关性逐渐降低。(在图标里显示)
All correlated UDG
数据集: DomainNet 和 PACS。
如何操作:
对于 DomainNet,从 6 个域中随机选择 3 个作为源域,其余作为目标域。在 300 个类别中随机选择 20 个类别用于训练和测试。
对于 PACS,作者采用常见的 DG 设置,即每次运行时将一个域视为目标域,而将其他域视为源域。
两个数据集的标注数据与训练数据的比例从 1%到 10%不等。(见表格)
table1:DomainNet
table2:PACS
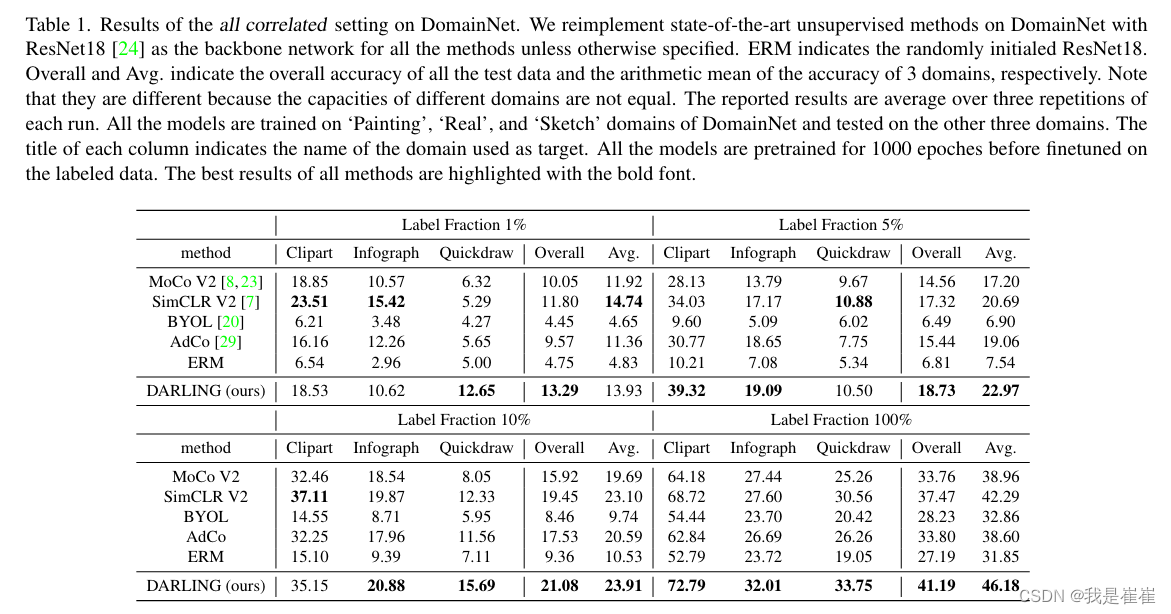
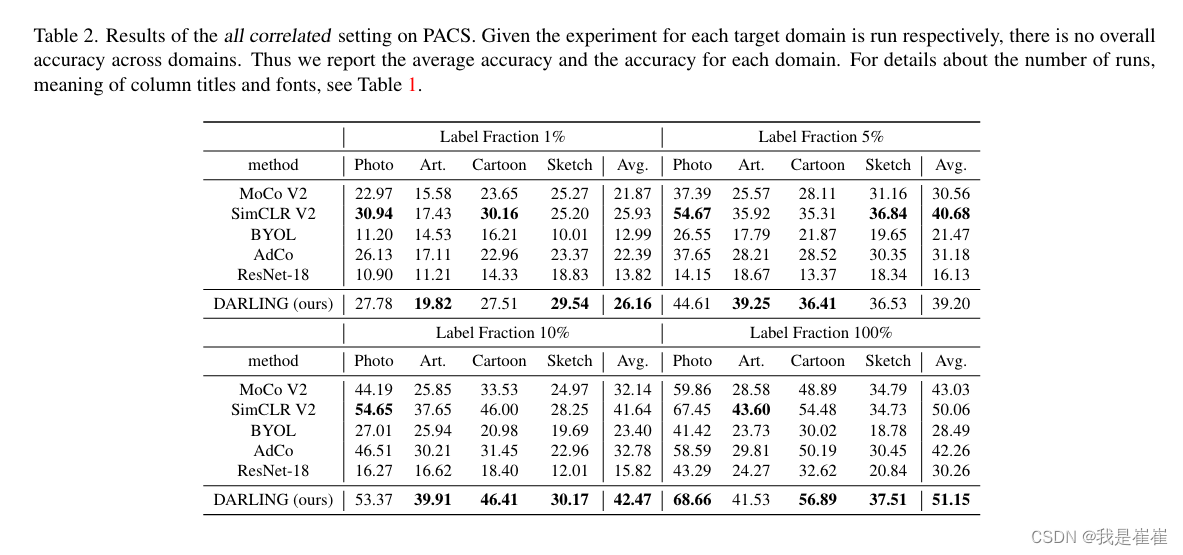
作者意外发现,当所有的训练数据都有标签时,使用相同数据进行无监督预训练可以明显提高目标域的预测准确率。这表明,当训练数据和测试数据之间存在严重的分布偏移时,源域的类别标签监督是不够的,因为它可以被视为目标域的偏差信息。源域中同一类别样本之间的无监督学习相似性可以为目标域中的类别区分引入有效的信息,而无监督学习自然符合 DG 问题。
????????从第 3.2 节中提到的图形模型的角度来看,源领域的监督有助于模型学习与领域相关的分类器,而这在目标领域可能会失败。而 DARLING 会学习与领域无关的表示空间,从而在新领域中获得更稳健的预测结果。(作者是这么说的,但是这句话我没看明白还)
当标注数据的比例低于 10% 时,我们只对所有方法的线性分类器进行微调,以防止过拟合。
对比以前模型和DARLING:随机初始化的 ResNet-18 和 BYOL 在标注分数为 1%和 5%时都无法学习到有效的模型,而 DARLING 则始终保持着相当大的改进。
Domain correlated UDG
Domain correlated UDG is a challenging setting with a great degree of flexibility, where ?unlabeled data can be sampled from other categories or even other datasets compared with labeled data as long as they share the same domain space. This setting is quite common in real-world scenarios, given that when category space is unknown, one can hardly assume that the unlabeled data share the same categories with labeled data. We use this setting to validate the generalization ability of unsupervised learning methods under both domain and category shifts.
领域相关 UDG 是一种具有高度灵活性的挑战性设置,与标注数据相比,未标注数据可以从其他类别甚至其他数据集中采样,只要它们共享相同的领域空间即可。这种情况在现实世界中很常见,因为当类别空间未知时,我们很难假设未标记数据与标记数据共享相同的类别。我们利用这种情况来验证无监督学习方法在领域和类别转移情况下的泛化能力。
数据集: DomainNet?
如何操作:从 6 个域中随机选择 3 个作为源域,其余域作为目标域。我们从 300 个类别中选择 20 个类别作为标注的训练和测试数据,另外 40 或 100 个类别作为未标注的数据。无标签数据和有标签数据的类别之间没有重叠。
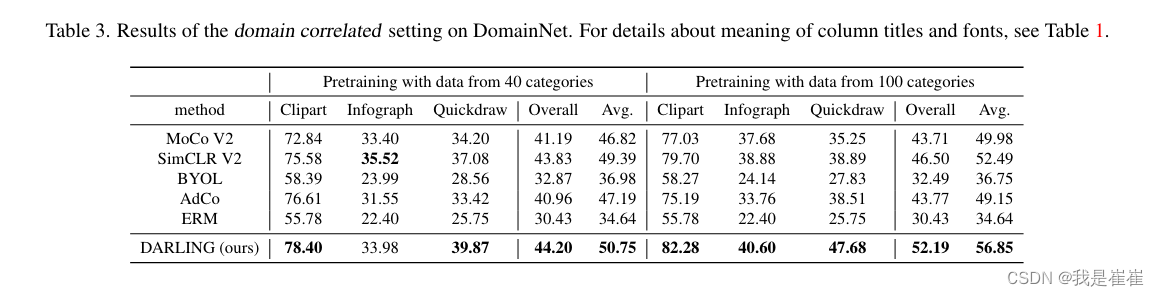
结果如表 3 所示。DARLING 在所有领域的泛化准确率都是最高的。如前所述,当前的对比损失不仅扩大了不同类别样本表征之间的距离,也扩大了不同领域样本表征之间的距离。然而,域的表征更易区分并不会给下游任务带来任何好处[43]。相反,DARLING 会迫使模型学习一个与领域无关的表征空间,在这个空间中,只有来自不同潜在类别的表征才容易区分。
DARLING 可以学习两种能力:
(1)选择最有可能与类别相关的与领域无关的特征,并用它们生成一个潜在的表征空间;
(2)分辨与领域相关的特征,并防止它们对表征空间做出贡献。
Uncorrelated UDG
数据集:CIFAR-100-C 和 CIFAR-10-C
如何操作:
将未标记的 CIFAR-100-C 作为预训练数据,将 CIFAR-10-C 作为微调数据和目标数据。为了使域空间足够大,我们为 CIFAR-100 和 CIFAR-10 生成了不同的域,并且未标记的训练数据、已标记的训练数据和测试数据之间没有重叠。
如表 4 ,随机选择了 4 个特定域,分别用于预训练、微调和测试数据,并将严重程度设为 3。由于 CIFAR 图像的大小为 32 × 32,因此采用 ResNet18 进行设置,并将第一层替换为内核大小为 3、步长为 1 的卷积层。
结论???????:类别相关特征之间的相似性可能有助于选择预测特征,而领域相关特征之间的相似性则有助于模型忽略与类别无关的特征。这在很大程度上拓宽了无监督学习的有效范围,因为无需对预训练数据和标记数据的类别和来源(领域)进行限制,就能提高模型在新领域的性能。

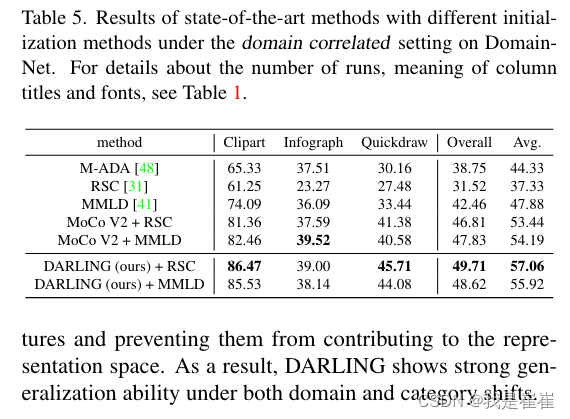
Finetuning with DG methods
表 5 显示了无监督预训练方法如何有利于 ERM 模型的泛化能力,因为这些方法的所有微调阶段都可视为 ERM 模型的训练阶段。在此,我们将进一步探讨无监督训练如何影响使用有效领域泛化方法训练的模型。我们在表 5 中报告了以无监督训练参数为初始状态的领域泛化先进方法的结果。
4.2. Comparison with ImageNet Pretrained Models
略,总体表达,我们的模型更强
4.3. Analysis
和moco v2和simclr做了一下对比,见图
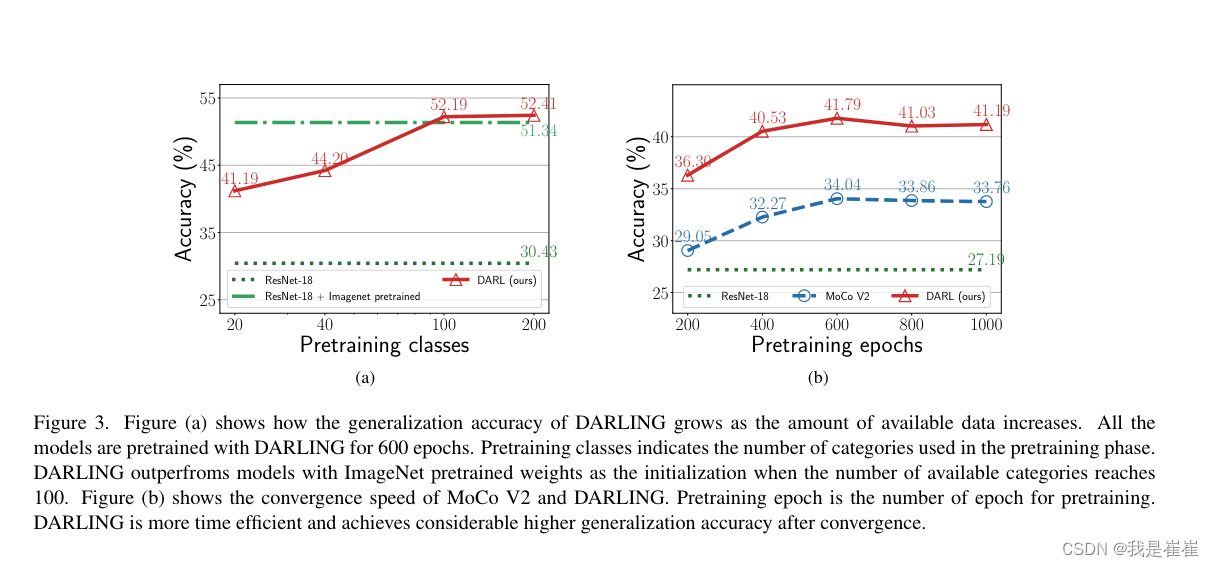
图 3b 显示了不同预训练历元下所有相关设置的准确率。为了进行公平比较,两种方法使用的所有参数和预训练协议都是相同的。在预训练历时较少的情况下,DARLING 比 MoCo V2 高出很多。随着预训练epoch的增加,MoCo V2 在预训练 600 个epoch后?MoCo V2 约 7.43%。该曲线表明,DARLING 不仅是一种高效的预训练方法,而且具有更好的收敛点。此外,图 3a 和 3b 表明,随着从不同领域采样的未标记数据的增多和训练历时的增加,强 UDG 方法可以逐步提高模型的泛化能力。因此,在不同数据集的数据上对模型进行预训练可以进一步提高泛化能力。
5. Conclusion
????????In this paper, we proposed a novel problem called unsupervised domain generalization (UDG), where unlabeled data are used to strengthen the generalization ability of models since labeled data are usually costly or unavailable. We also proposed a Domain-Aware Representation Learning method called DARLING to address the UDG problem. Extensive experiments clearly demonstrated the effectiveness of the proposed DARLING compared with state-ofthe-art unsupervised learning counterparts. As a pretraining approach, DARLING outperforms ImageNet pretraining approach with significantly less data, showing an encouraging way to initialize models for the DG problem.
? 在本文中,我们提出了一个名为 "无监督领域泛化"(UDG)的新问题,即利用无标记数据来加强模型的泛化能力,因为标记数据通常成本高昂或不可用。我们还提出了一种名为 DARLING 的领域感知表征学习方法来解决 UDG 问题。广泛的实验清楚地表明,与最先进的无监督学习方法相比,我们提出的 DARLING 方法非常有效。作为一种预训练方法,DARLING 在数据量明显较少的情况下就超越了 ImageNet 预训练方法,为 DG 问题提供了一种令人鼓舞的初始化模型的方法。
总结
此处未完待续,让我寻思寻思再写>>>
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 硬件成长之路-3
- P4411 [BJWC2010] 取数游戏 题解 简单dp+桶
- fastApi 项目部署
- 如何利用SD-WAN节省运维成本和简化运维工作?
- LLM Agent-指令微调方案
- 每日一练:LeeCode-503. 下一个更大元素 II (中)【单调栈】
- 【深度学习】Anaconda3 + PyCharm 的环境配置 5:手把手带你运行 predict.py 文件,史上最全的问题解决记录
- jdk安装及环境搭建
- [AFCTF2018]BASE解题思路
- Linux下误删除后的恢复操作测试之extundelete工具使用