读书笔记-《数据结构与算法》-摘要7[堆排序]
发布时间:2024年01月16日
堆排序通常基于二叉堆 实现,以大根堆为例,堆排序的实现过程分为两个子过程。第一步为取出大根堆的根节点(当前堆的最大值), 由于取走了一个节点,故需要对余下的元素重新建堆。重新建堆后继续取根节点,循环直至取完所有节点,此时数组已经有序。基本思想就是这样,不过实现上还是有些小技巧的。
堆的操作
以大根堆为例,堆的常用操作如下。
- 最大堆调整(Max_Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build_Max_Heap):将堆所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
其中步骤1是给步骤2和3用的。

—PS:
1、初始数据
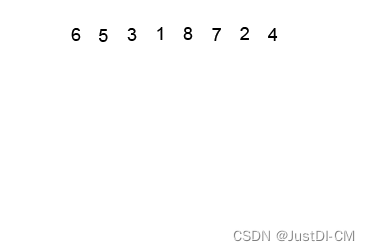
2、依据父节点大于等于所有子节点,创建大根堆完成后为
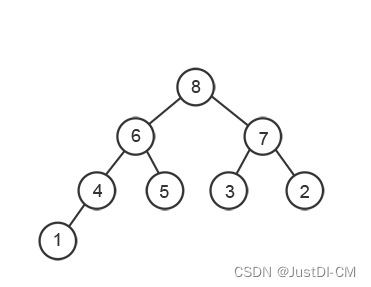
3、然后按照前序(pre-order):先根后左再右,将值取出
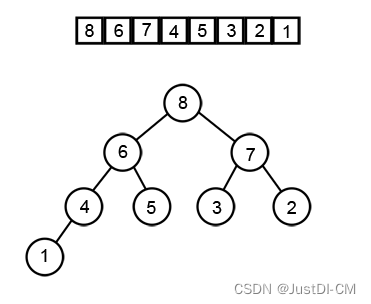
4、这时候数组的第一位就是最大值,与最末尾交换后,最大值就到了末尾,定死后去除节点
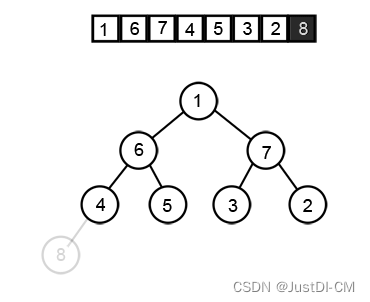
5、然后重复2->3->4
这次看这个算法是有吃力的,先知道个概念吧。看不明白的时候就去查些资料,会推荐些大佬的文章:
文章来源:https://blog.csdn.net/JustDI0209/article/details/135632917
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!