Spark---RDD依赖关系
1.1 RDD依赖关系

在Spark中,一个RDD的形成依赖于另一个RDD,则称这两个RDD具有依赖关系(一般指相邻的两个RDD之间的关系) ,RDD的依赖关系对于优化Spark应用程序的性能和可靠性非常重要。通过合理地设计RDD的转换和动作操作,可以避免不必要的Shuffle操作,提高计算效率。
//读取数据
val lines:RDD[String] = context.textFile("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\1.txt")
//执行扁平化操作
val words : RDD[String] = lines.flatMap((a: String) => a.split(" "))
words的形成依赖于lines,这两个RDD之间就有依赖关系
1.2 血缘关系
依赖关系是对于相邻的两个RDD来说的,如果多个RDD之间存在依赖关系,则称它们之间具有血缘关系。
血缘关系在Spark中起着重要的作用。血缘关系记录了RDD的元数据信息和转换行为,主要用于容错和优化。
由于RDD中是不存储数据的,当计算发生错误的时候,很难重新计算丢失的数据分区。通过记录RDD的血缘关系,Spark可以在数据分区丢失时重新读取数据源并进行计算,从而恢复丢失的数据分区。 这样,即使在处理大规模数据集时,也能保证Spark作业的可靠性和稳定性。
其次,血缘关系还有助于Spark优化查询计划和性能。
//执行业务操作
val lines:RDD[String] = context.textFile("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\1.txt")
//执行扁平化操作
//扁平化就是将多个集合打散为一个集合
val words: RDD[String] = lines.flatMap((a: String) => a.split(" "))
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy((word: String) => word)
//对分组后的单词进行转换(hello,1)
val wordToCount: RDD[(String, Int)] = wordGroup.map({
case (word, list) => {
(word, list.size)
}
})
如上述代码所示,words的形成依赖于lines,wordGroup依赖于words,wordToCount依赖于wordGroup。这些RDD之间就形成了血缘关系。
1.3 依赖关系分类
在Spark中的依赖关系,可以分为窄依赖和宽依赖(也称shuffle依赖)
1.3.1 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
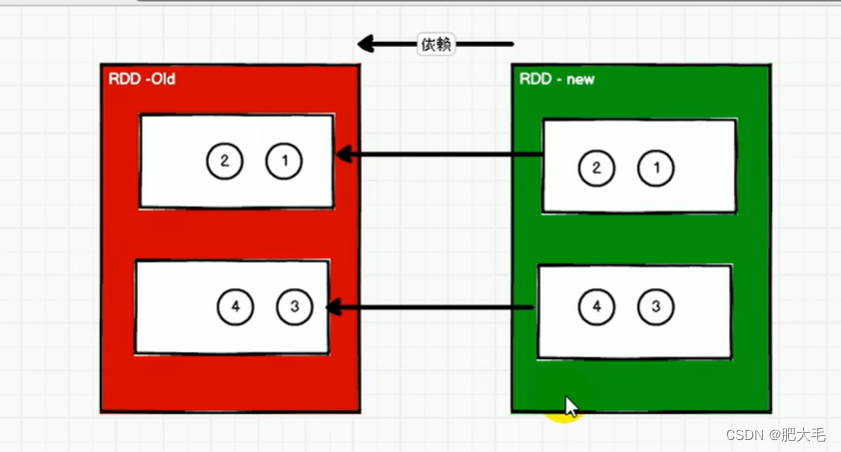
一个新的分区的数据依赖于一个旧的分区的数据,这样的依赖称之为OneToOne依赖,即窄依赖
1.3.2 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
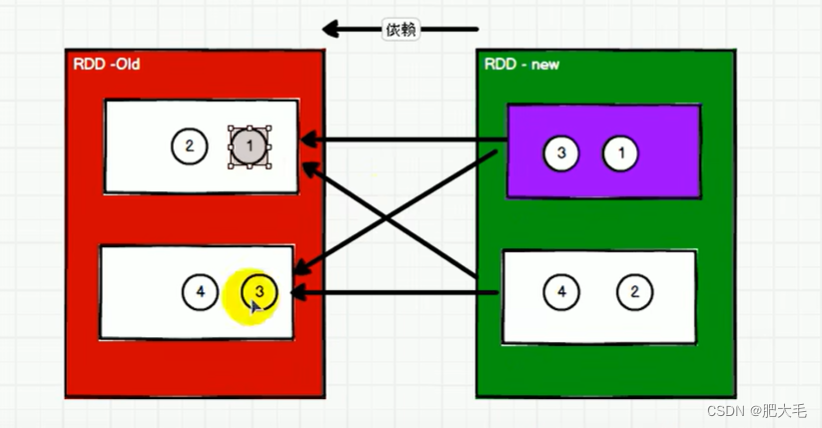
新的分区的数据依赖于多个旧的分区的数据,因为数据会被shuffle,所以宽依赖也被称为shuffle依赖。
1.4 RDD阶段划分和任务划分
1.4.1 RDD阶段划分
RDD(弹性分布式数据集)的阶段划分是在Spark中执行多个RDD时,根据RDD之间的依赖关系进行的。
通过分析各个RDD的依赖关系,可以生成一个依赖图(DAG,有向无环图)。然后,通过分析各个RDD中的分区之间的依赖关系,可以决定如何划分阶段。
Shuffle操作需要在不同的阶段之间进行,因此Spark会根据shuffle依赖关系将数据处理划分为不同的阶段。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。 例如,DAG 记录了 RDD 的转换过程和任务的阶段。
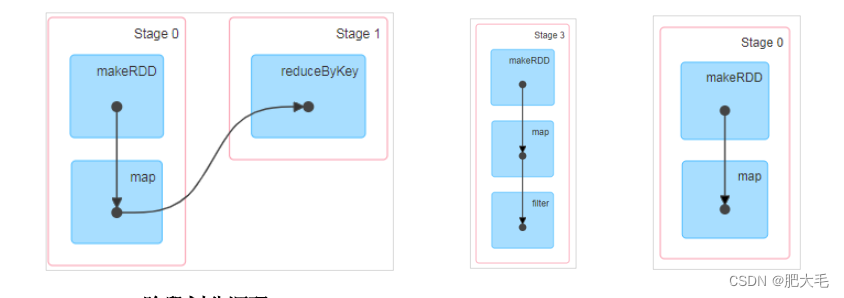
具体的划分方法如下:
1.对DAG进行反向解析,遇到宽依赖(ShuffleDependency)就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中。
2.将窄依赖尽量划分在同一个阶段中,这样可以实现流水线计算。
3.一个阶段等于宽依赖(ShuffleDependency)的个数加1。
4.一个阶段中的最后一个RDD的分区个数就是Task的个数。
简而言之,RDD的阶段划分就是在遇到宽依赖时划分出一个新的阶段,每个阶段的任务全部完成,每个分区元素准备就绪后才能进入下一个阶段。
划分出来的阶段的数量=shuffle依赖数量+1
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【日常记录】自动化部署与持续交付:GitHub Actions CICD
- K8s 重设解决 “The connection to the server xxx:6443 was refused” 问题
- HarmonyOS 组件生命周期
- [kubernetes]Kube-APIServer
- (leetcode)判断字符是否唯一 -- 使用位图(位运算)
- 群发邮件软件有哪些?好用的邮件群发软件?
- 进程管理:处理机调度例题
- “Softechcl““app Tech Support(URL)
- 《C++新经典设计模式》之第8章 外观模式
- mysql 23-2day 数据库查询(DQL)