Amazon SageMaker测评
Amazon SageMaker测评
(声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在
亚马逊云科技开发者社区、知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道)
1 前言
在2023亚马逊云科技 re:Invent上,发布了 Amazon SageMaker 的五项新功能,旨在加速构建、训练和部署大型语言模型和其他基础模型,以帮助用户更快地进行模型开发和应用部署,提供更强大的工具和资源。对于该产品的新功能,我进行了实际体验,在下文会详细讲述体验内容及感受。
打开亚马逊云科技的网站,搜索一下Amazon SageMaker就能直接进入这个功能的主页面了。作为第一次使用这个功能的新手,参考的文档是官方给出的教程,如下图1-1所示,我选择的是无代码:ML,即在不编写代码的情况下生成机器学习预测。教程很详细,给出了每一步的步骤并截屏,但是有一些功能截图与操作与实际界面不太符合,后续会详细说明,接下来我就从构建域开始体验这个功能并给出我的一些感受。
2 功能体验
2.1 构建域
构建域这边忘记截屏了,但是在进入主界面后右边有个非常醒目的“配置个人域”可以选择,并且其按钮是黄色的,视觉上一眼就能看到,入门也比较简单,在点击这个按钮后就会自动构建SageMaker域(如图2-1),大约等了十分钟左右就构建完成可以进行导入数据等下一步操作。
2.2 上传数据集
构建完成后搜索SageMaker Canvas进入主页面后,点击图3-1位置处的按钮"Launch SageMaker Canvas"就能自动构建SageMaker Canvas。

如图3-2,就是正在构建中,大约等15分钟左右就能进入主页面了(图3-3)。
按照教程,接下来就是上传数据后构建、训练与分析 ML 模型,这里我就选择下载官方教程中的两个数据product_descriptions和shipping_logs后搜索进入S3控制台后进入SageMaker Canvas创建的默认桶,并上传刚刚下载的数据(图3-4)。
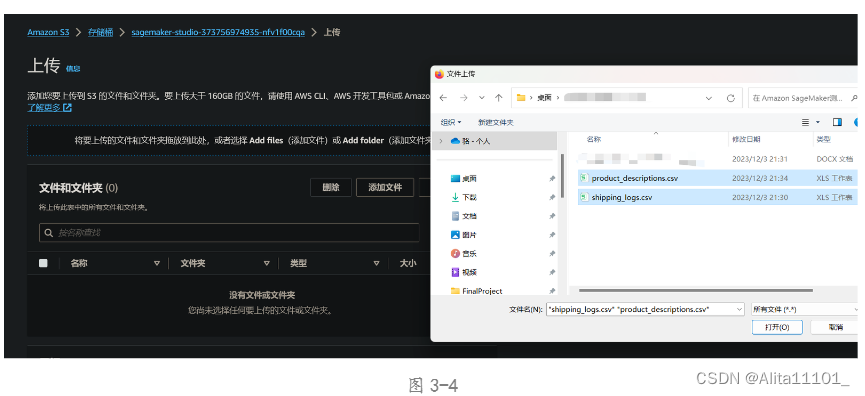
图3-5和图3-6分别代表是上传中和上传成功的截图,这样数据集就可以在后续操作中被访问到。上传数据响应速度也很快,即使数据量比较大也没有等待很久才能上传成功。
2.3 设置 SageMaker Canvas
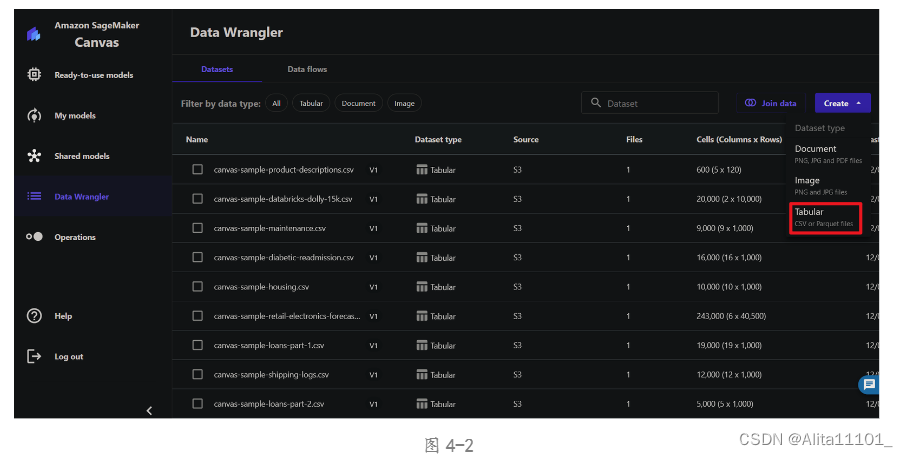
接下来就是和官方操作手册有一些些不同之处了。当重新打开canvas准备设置 SageMaker Canvas时,在操作手册中是这么写的:“在 SageMaker Canvas 界面上,选择左侧窗格中的 Datasets(数据集),然后选择 + Import(+ 导入)”但是在打开页面后,左侧窗格并没有找到Datasets,所以我选择了Data Wrangler(如图4-1)并选择其中的Datasets页面,准备将数据导入,但是在我的页面上没有"Import"按钮,只有"Create"按钮(如图4-2)点击按钮后,由于我下载的数据是.csv格式的,所以我选择新建Tabular,因为在Tabular下方有提示CSV。
然后按照操作手册,在Data Source中选择Amazon S3(图4-3),再选择前面包含上传数据的文件夹(图4-4)找到数据后即可上传,其操作简单,提示也很清晰,根据操作手册可以很轻松的完成这个步骤。
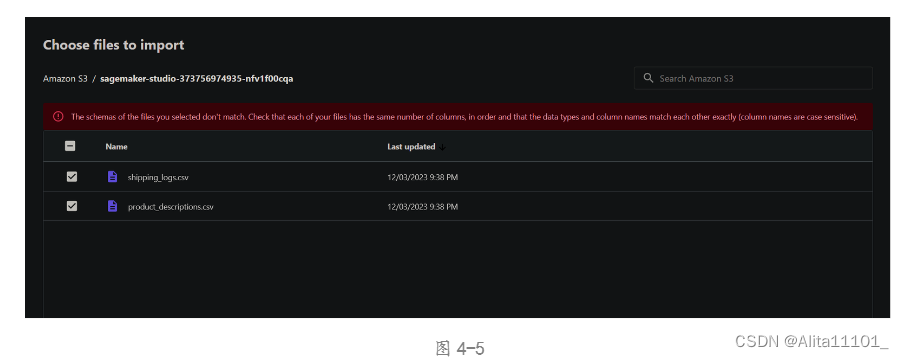
按照操作步骤应该是选择这两个下载好的数据集一起导入,但是提示列数不相同,无法导入(图4-5),不知道是不是升级了一下功能所以有些限制,所以我就回到了Data Wrangler页面,直接选择了官方给出的数据集进行合并。
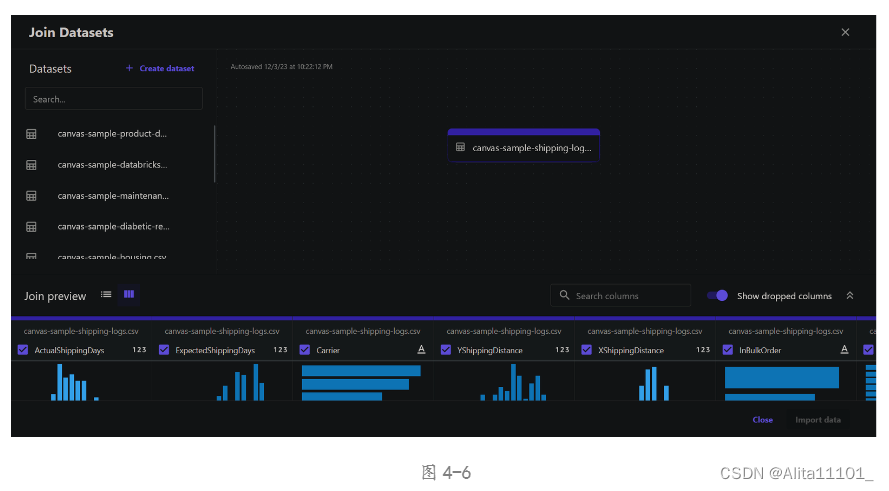
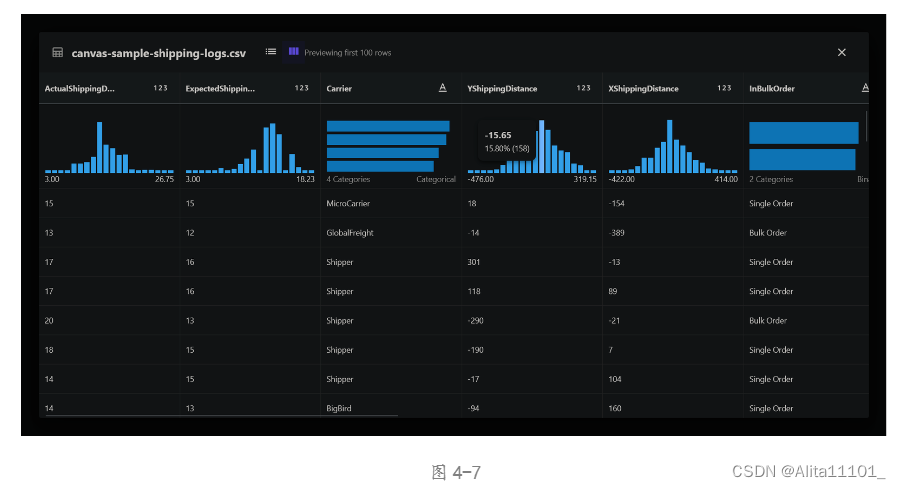
按照教程,在合并页面首先选择canvas-sample-shipping-logs.csv这个数据,并拖拽到右边的操作台上,点击这个文件,可以看到如图所示,每一列都进行了可视化操作,对每列的数据进行统计,并画出了分布图,将鼠标移动到每列蓝色的数据条上还能展现其具体数值(图4-6至图4-9),感官上来说可以更直观的对一个大批量的数据有个了解,在其它产品中暂时还没有类似的功能,感觉很新颖也很有价值。
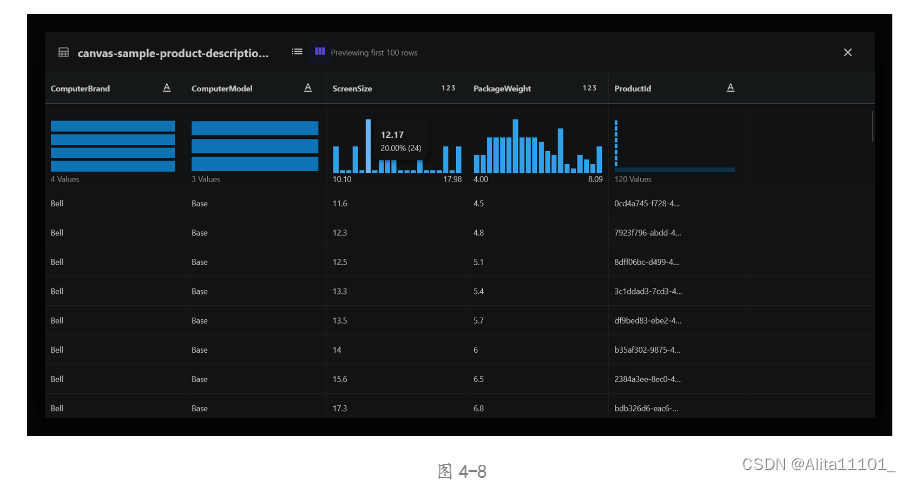
然后选择内连接,ProctedId作为合并列,但是依然没有成功,错误信息如下图4-9所示。
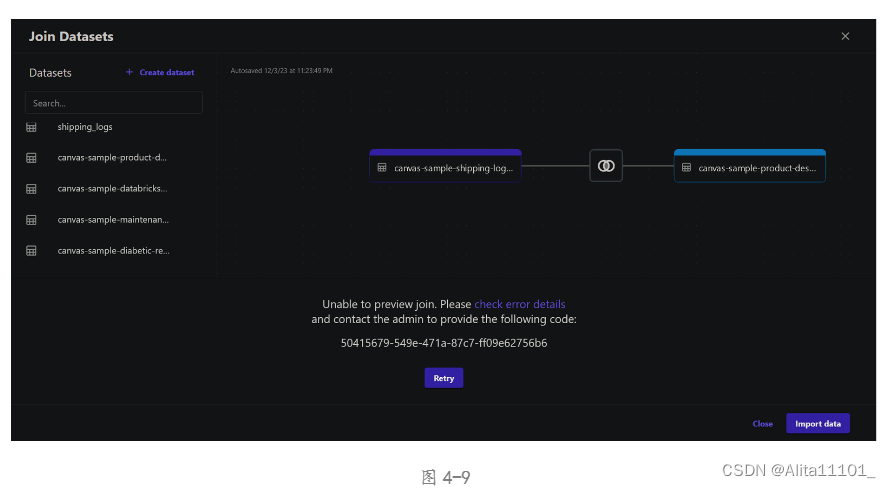
于是我选择将product_descriptions.csv导入数据集product_descriptions,将shipping_logs.csv导入数据集shipping_logs,再将这两个数据集进行合并,依然报错,报错信息(图4-10)。
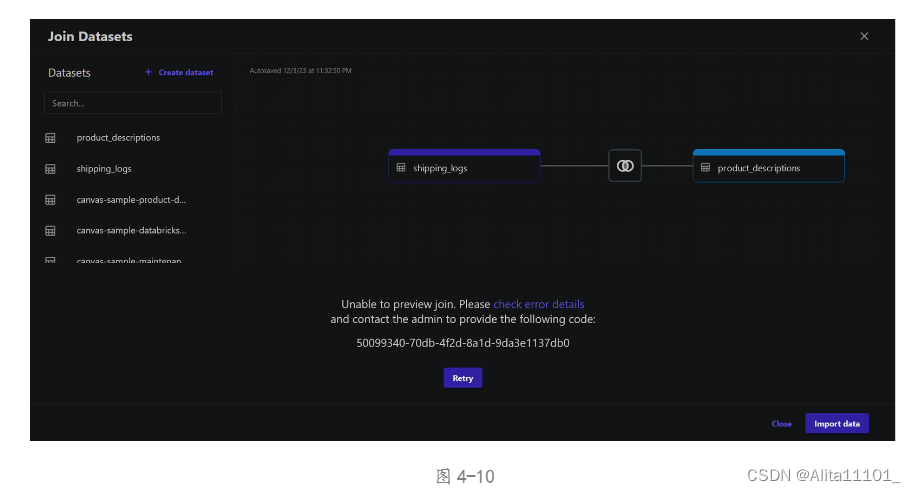
由于报错提示是无法预览合并的数据,于是我直接忽略这个报错,点击左下角的Import data,然后保存为ConsolidatedShippingData(由于之前试验过了两次,所以这里自动帮我后面加了(2)区分)(图4-11)。

2.4 构建、训练与分析 ML 模型
接下来就是构建、训练与分析 ML 模型了,同样,与操作手册不同的是,在左侧页面中没有找到"Models"窗格,但由于要新增一个模型,所以我选择左侧窗格中的"My models"后点击新建模型按钮(图5-1)。

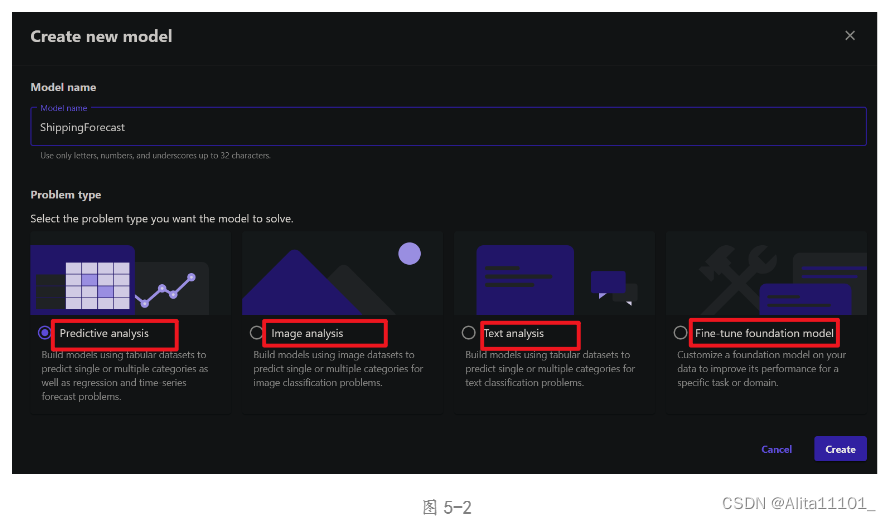
选择新建模型后跳出的界面是可以选择模型类型,不同的问题需要用不同的模型去解决分析,这里可以看到有四种类型的问题:预测分析、图片分析、文本分析 以及 微调基础模型。(图5-2)这是我觉得这个功能最大的亮点,在后续的评价章节中会详细讲述原因。这里选择第一个:预测分析,然后点击创建。
第一步
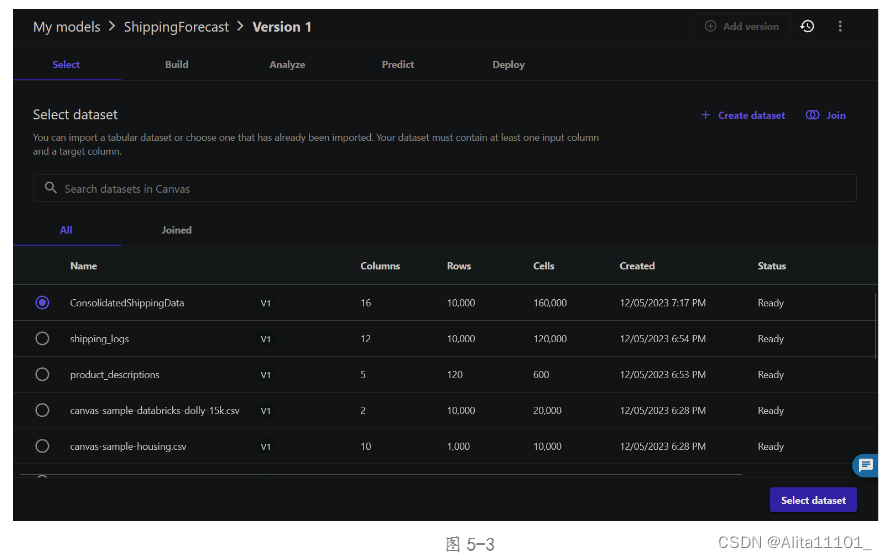
设置输入数据(Select),选择刚刚合并的数据集(图5-3)后选择 Select dataset进入下一步骤:Build。
第二步
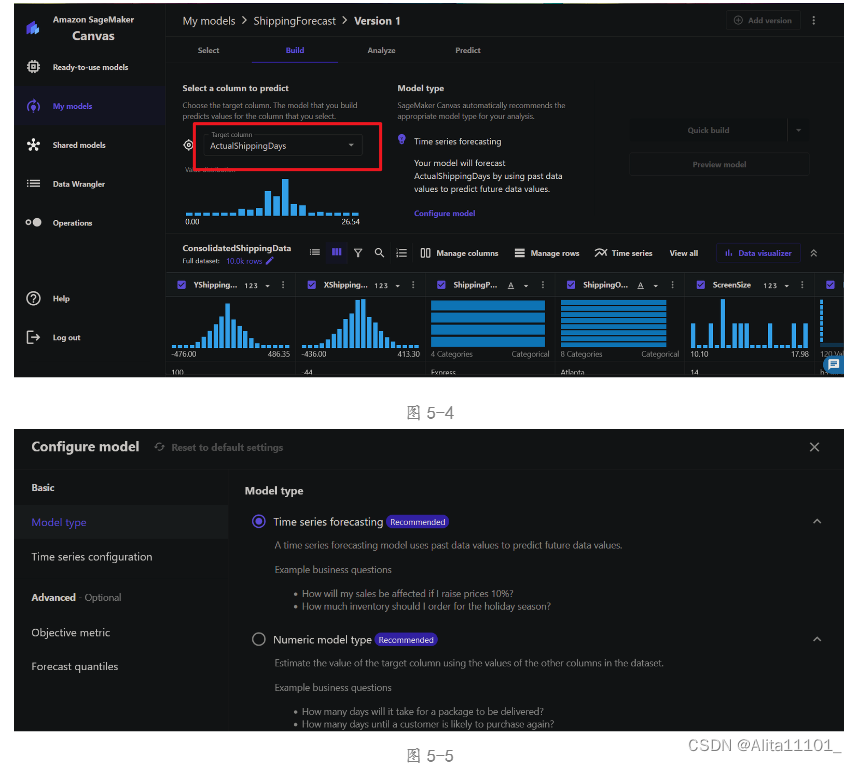
构建模型(Build)中,可以选择目标列,也就是选择我们需要预测的数据,这里选择ActualShippingDays字段,即预测货物到达目的地所用的时间(图5-4)。由于SageMaker Canvas 会自动尝试推理问题类型(图5-5),所以他会在检测到时间后将该问题推理为时间序列预测类型问题,但客户想知道的是所需时间,是一个具体的数字,因此在点击Configue model后可以在"Model type"中选择我们需要的类型,如果不知道具体选择哪个类型,在"Model type"中也有相对应的提示,举例说明该类型要解决的具体问题是什么,以供我们更加准确的选择模型,对新手来说很方便也很友好。
同时我们可以去掉一些不相关的字段,然后就可以选择构建模型了,这里有两种可选:Quick Build(快速构建)和Standard Build(标准构建)以满足不同的需求(图5-6)。如果想大致预测一下的话就可以选择快速构建,15分钟内就可以构建出一个模型,如果想要精准预测就可以选择标准构建,提供更加准确的模型。这个分类可以满足不同的需求,也是这个功能中的一个特别之处。
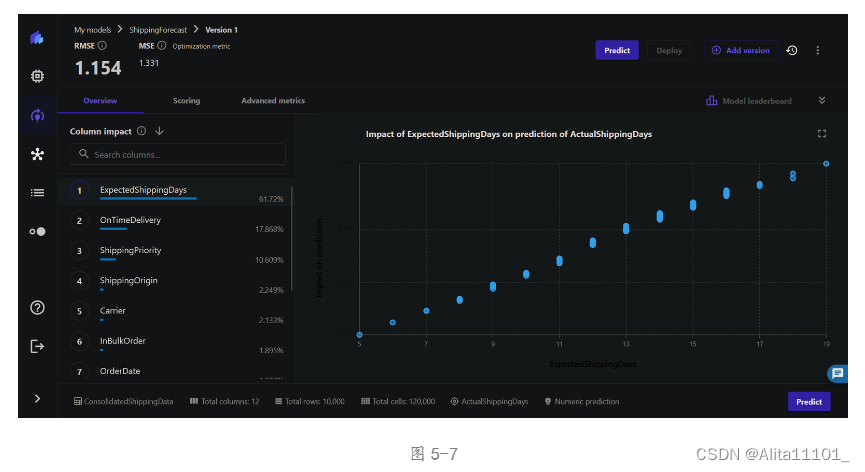
等待大约7-8分钟就有结果,其中有三个页面:预览Overview(图5-7、图5-8),得分Score(图5-9),高级指标(图5-10、图5-11)。在预览页面,SageMaker Canvas 会显示列影响或每个输入列在预测目标列中的预计重要性,即左侧的字段及其百分比。
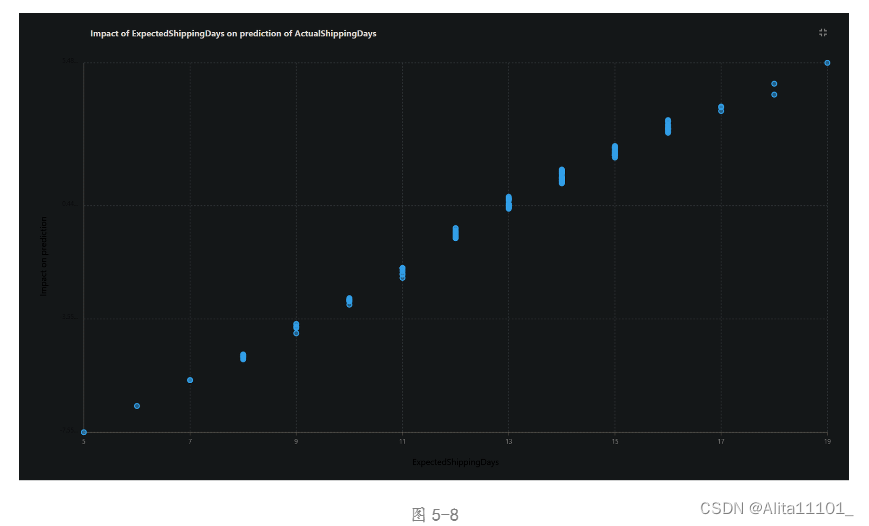
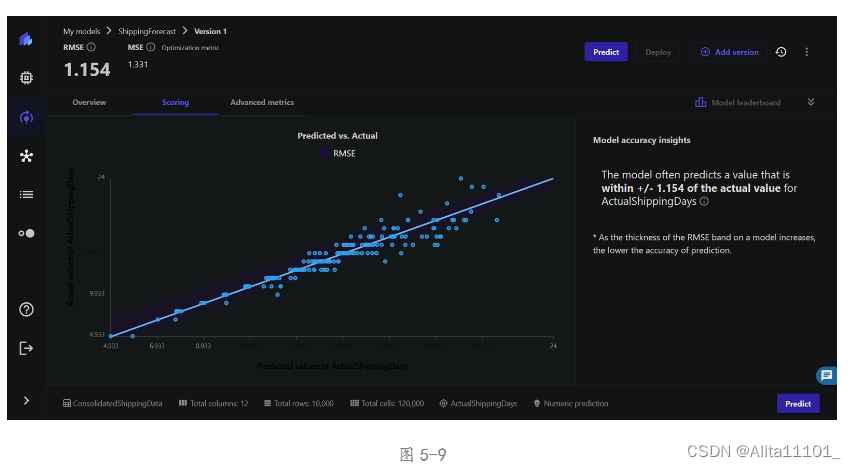
在得分页面,可以看到代表 ActualshippingDays 最佳拟合回归直线的图形(图5-9)。
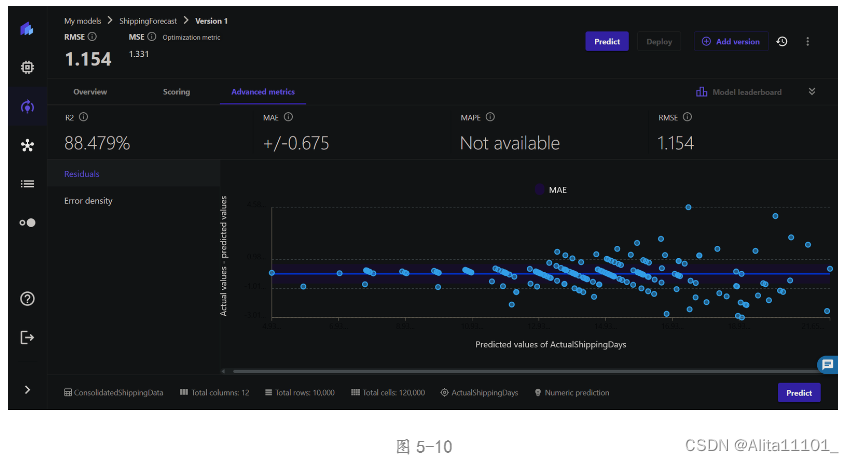
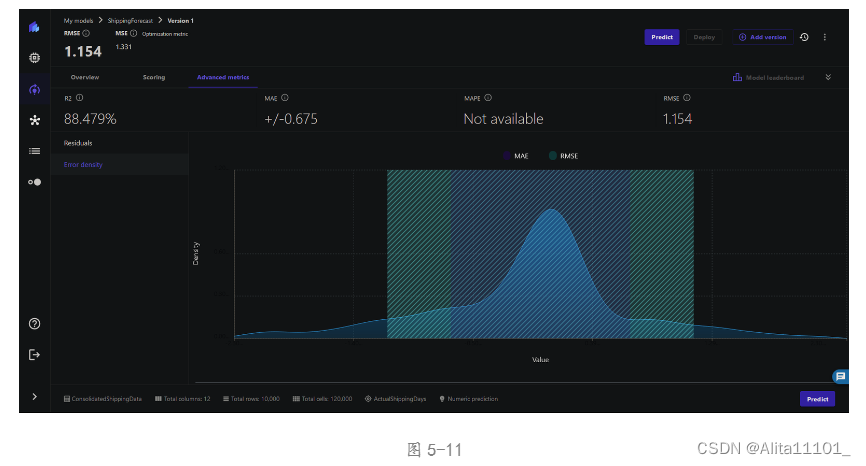
在高级指标页面上显示不同的指标,有 R2、平均绝对误差(MAE)、平均绝对百分比误差(MAPE),以及均方根误差(RMSE)(图5-10),还可以看到误差密度图(图5-11)。
2.5 生成预测模型
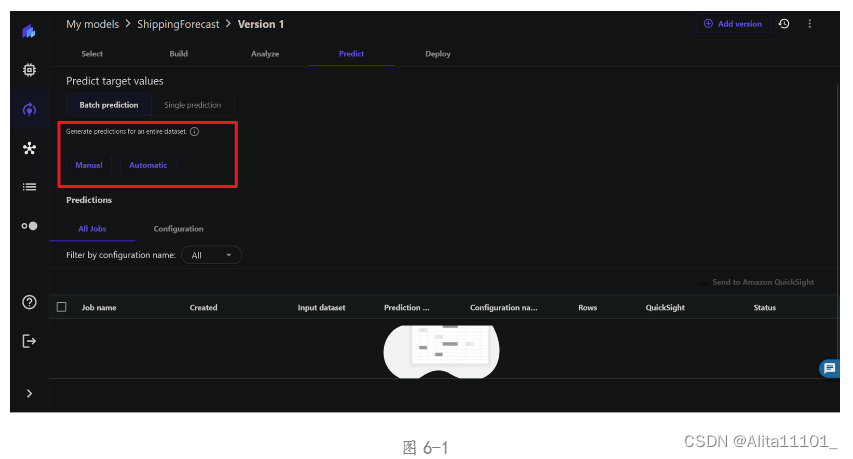
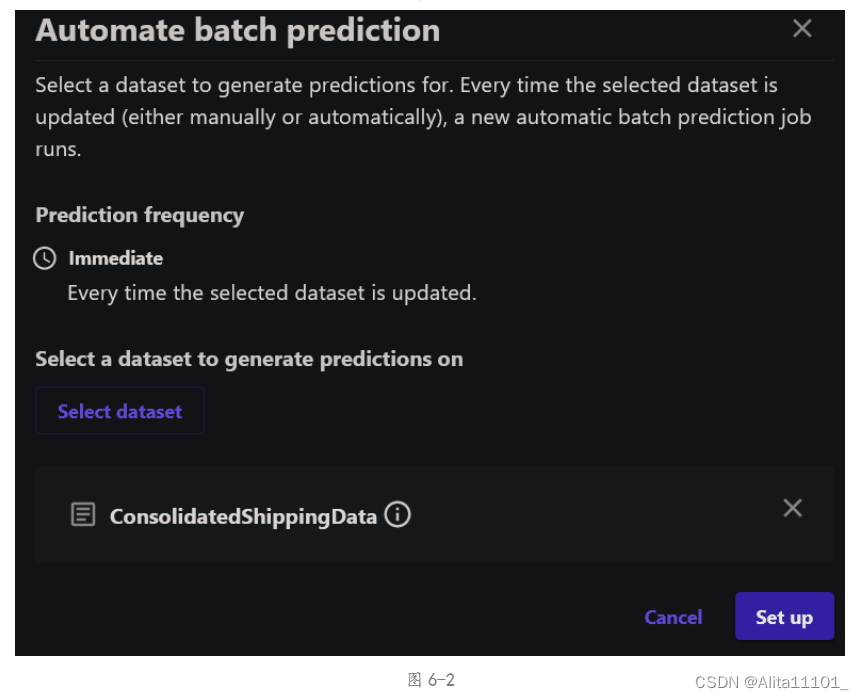
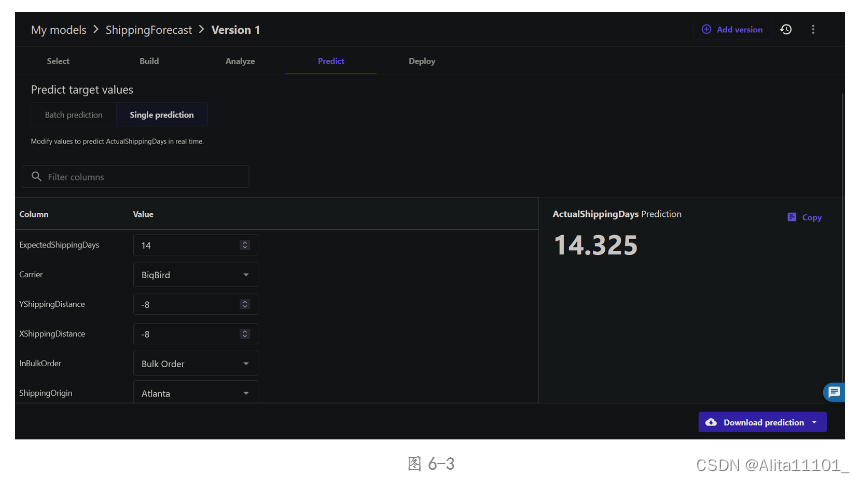
然后点击Predict生成预测模型,与操作手册不同的是,这里可以选择Automatic(图6-1)后选择前面合并的数据集(图6-2)可以进行自动预测,或者选择Manual再导入数据集,也可以生成预测结果(图6-3)。
3 评价及建议
在使Amazon SageMaker从零开始,预测数据的过程中,让我感觉非常的简便,即使是第一次接触,跟着操作手册一步一步也能完成预测,同时对于没有机器学习背景的用户来说非常友好,因为在很多操作按钮以及选项下都有提示字样,让用户在使用的适合不会非常茫然,同时操作界面非常清晰,页面转跳也很快。
在功能方面,上文提到在选择创建模型的类型时,有一个选项是微调基础模型,我觉得这是这个产品最大的亮点,因为大模型训练使用的都是其它数据进行预测,如果我作为一个企业的负责人,企业内有很好的数据能够进行训练,那么微调基础模型可以提升其预测的准确度,更符合我们的期望值。
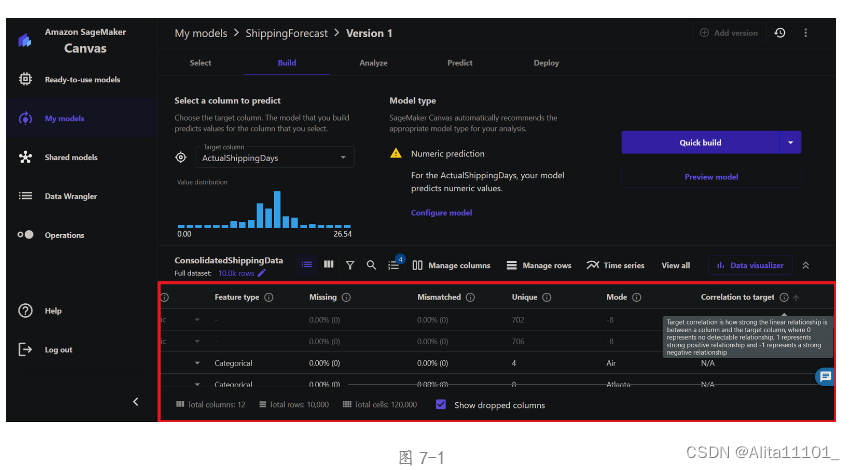
另一个产品的亮点是其在构建模型时,会给出一栏:Correlation to target,能够通过这个数值来判断这个字段对该模型的影响程度,以它给出的解释,如果该值为负数,那么这个字段就是对模型有消极影响,也可以理解为对预测模型没有什么帮助的字段,那么我们就可以通过这个字段的值去取消勾选一些字段,降低预测时间,提高效率(图7-1)。
在使用过程中,也发现了一些小瑕疵:比如功能栏的宽度是固定的,有时页面上的图片无法完整显示只能通过缩放页面来使其完整展示,另一处就是如果该产品支持自定义底色就更好了,这样浏览器页面是暗黑系的适合,界面会变得更加清晰。
总体来说是一个非常高效,对新手非常友好的产品,即使不写代码也能通过可视化界面进行机器学习预测。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 位乘积计数-蓝桥
- 自制c++题目《类操作综合》
- 9.1 Maven项目管理(????)
- 100000000!文心一言披露最新用户规模
- opencv009 滤波器01(卷积)
- 【Unity的实现好用的曲面UI_切角曲面边框流光效果_案例分享(内附源码)】
- ride无法使用open Browser关键字
- 企业级快速开发平台可以用在什么行业?优点多吗?
- 应用Dockerfile编写及部署使用
- 海格里斯HEGERLS仓储货架生产厂家|载荷1.5T运行速度1.7~2m/s的智能四向穿梭车系统