大模型实战营Day4 XTuner大模型单卡低成本微调实战
FINETUNE简介
LLM下游应用中,增量预训练和指令跟随是经常会用到的两种微调模式
指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话
训练数据:高质量的对话,问答数据
为什么需要指令微调?
因为在对话中模型只是根据我们的提问去拟合训练数据集中的分布,它并没有意识你的意图是在向它提问。
通过指令微调后,便可得到instructed LLM,可以输出我们更加相对满意的结果

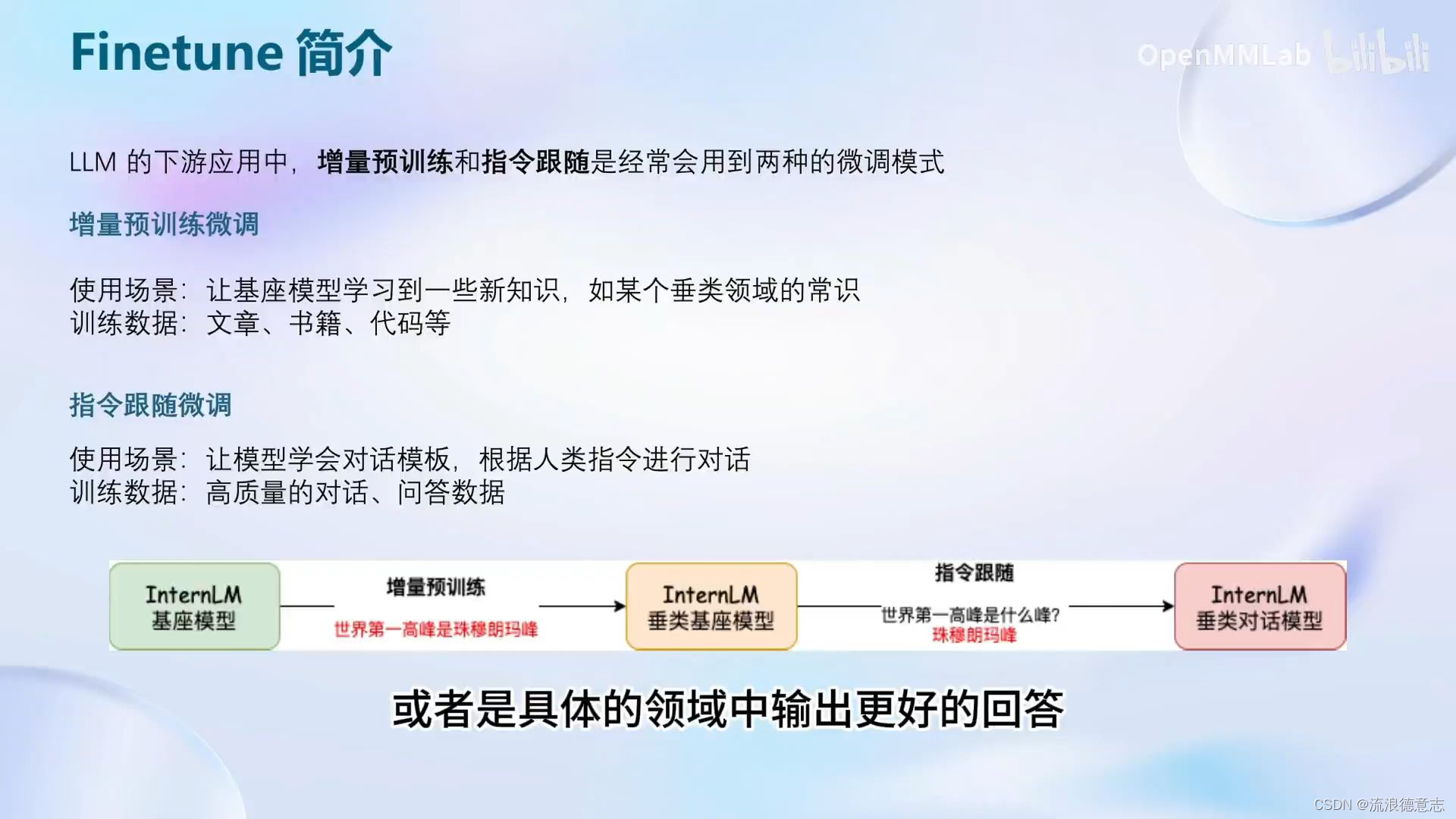
在进行指令跟随微调前,先定义三个角色
System:给定一些上下文信息,例如我们想微调一个安全的AI助手,那System就是“你是一个安全的AI助手”。
User:用户提问,在微调时将对话样本的提问赋予此角色
Assistant:根据用户提问,结合System上下文信息,输出回答,在微调时将对话样本的回答赋予此角色
这样便构建好了一个对话模板

不同的模型使用的指令各不同 Llama2 InternLM
指令跟随微调的训练
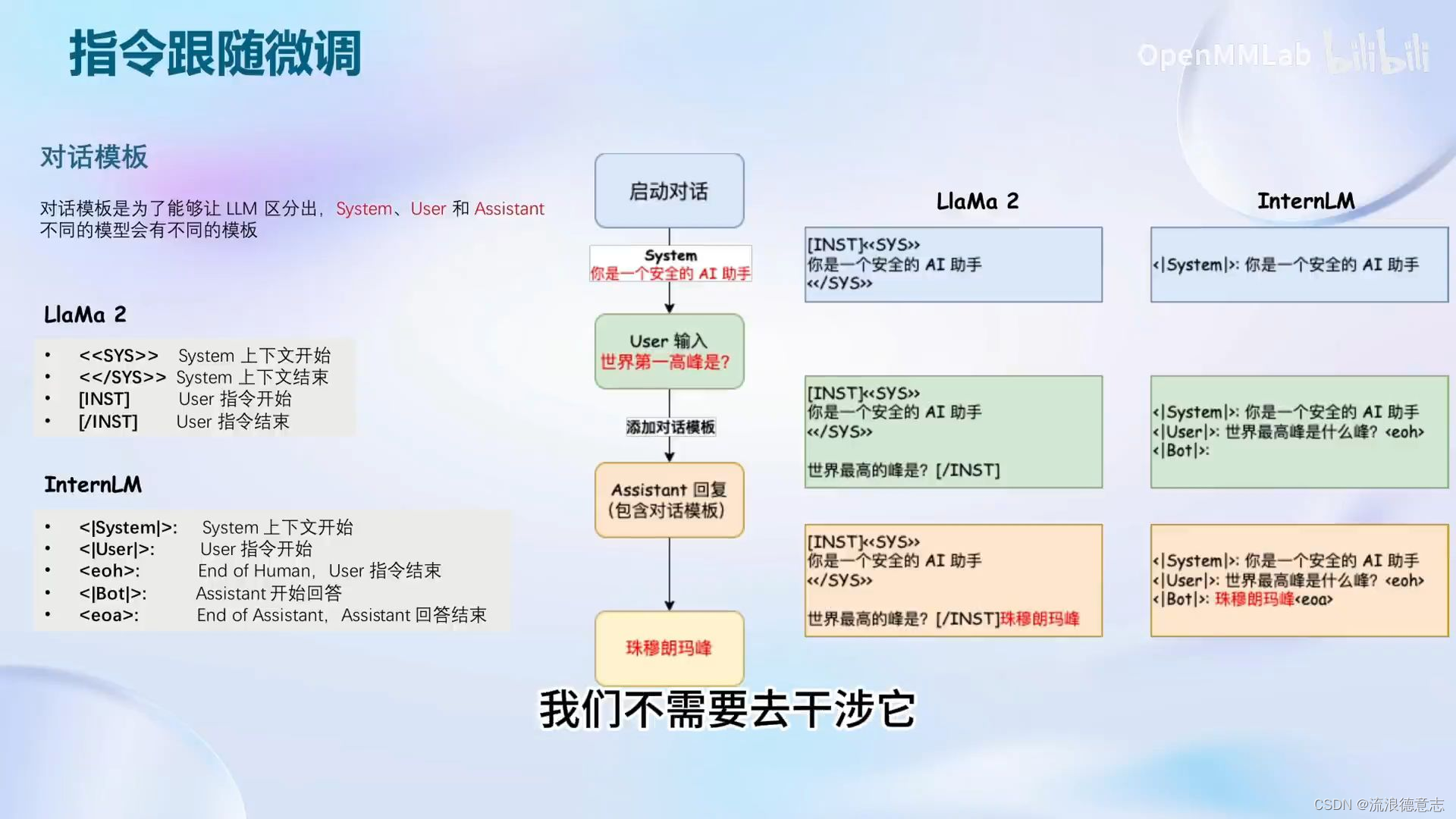
由于希望模型学会的是答案而不是问题,因此训练时只对答案计算损失
增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
训练数据:文章,书籍,代码等
训练LLM时,是为了让模型学会回答一个陈述句,因此相比指令跟随微调,增量预训练的对话模板中,system和user部分留空,只保留assistant。训练数据也不是对话数据,而是陈述句
计算损失时同样计算答案的损失即可。
LoRA & QLoRA
为什么要使用LoRA,如果不使用lora,那么微调时的显存开销会非常大。
lora的原理:比起对大模型的参数全面训练,lora则是在保持原模型参数不变的情况下,在原本的linear旁新增一些可训练分支(Adapter)使得输出结果拟合训练样本,Adapter参数量远小于原本的linear,能大幅减低训练的显存消耗
qlora是对lora的一种改进,使得加载模型到显存时直接量化成4bit,并且gpu满了就会到cpu上进行调度,虽然慢了,但是整个训练还能进行下去


XTuner简介
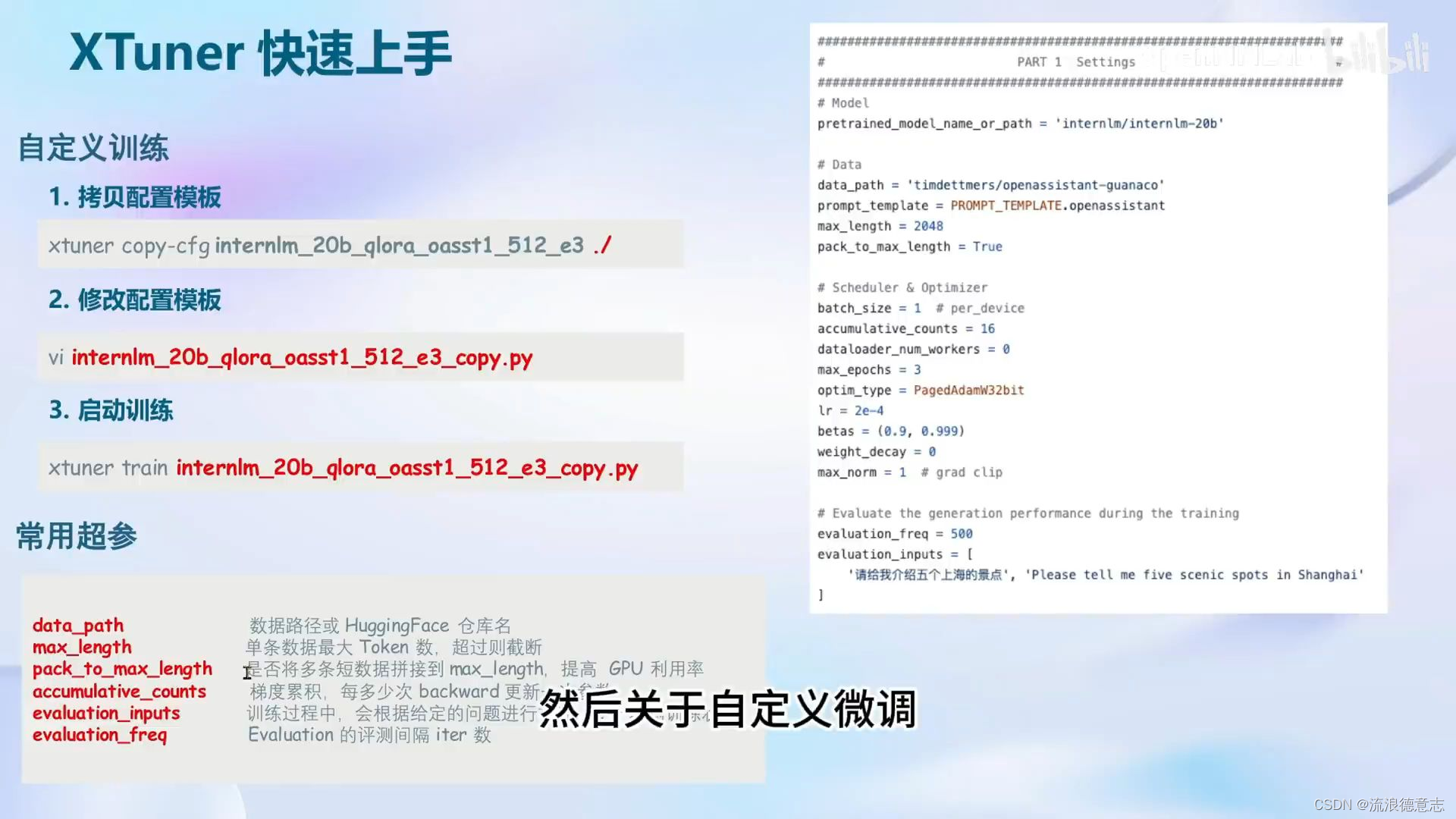
傻瓜式:以配置文件的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调
轻量级:对于7B参数量的LLM,微调所需的显存仅为8GB,满足大部分消费级显卡

功能亮点
适配多种生态
多种微调算法:多种微调策略与算法,覆盖各类SFT场景
适配多种开源生态:支持加载HuggingFace、ModelScope模型或数据集
自动优化加速:开发者无需关注复杂的显存优化与计算加速细节
适配多种硬件
训练方案覆盖NVIDIA20系以上所有显卡
最低只需8GB显存即可微调7B模型


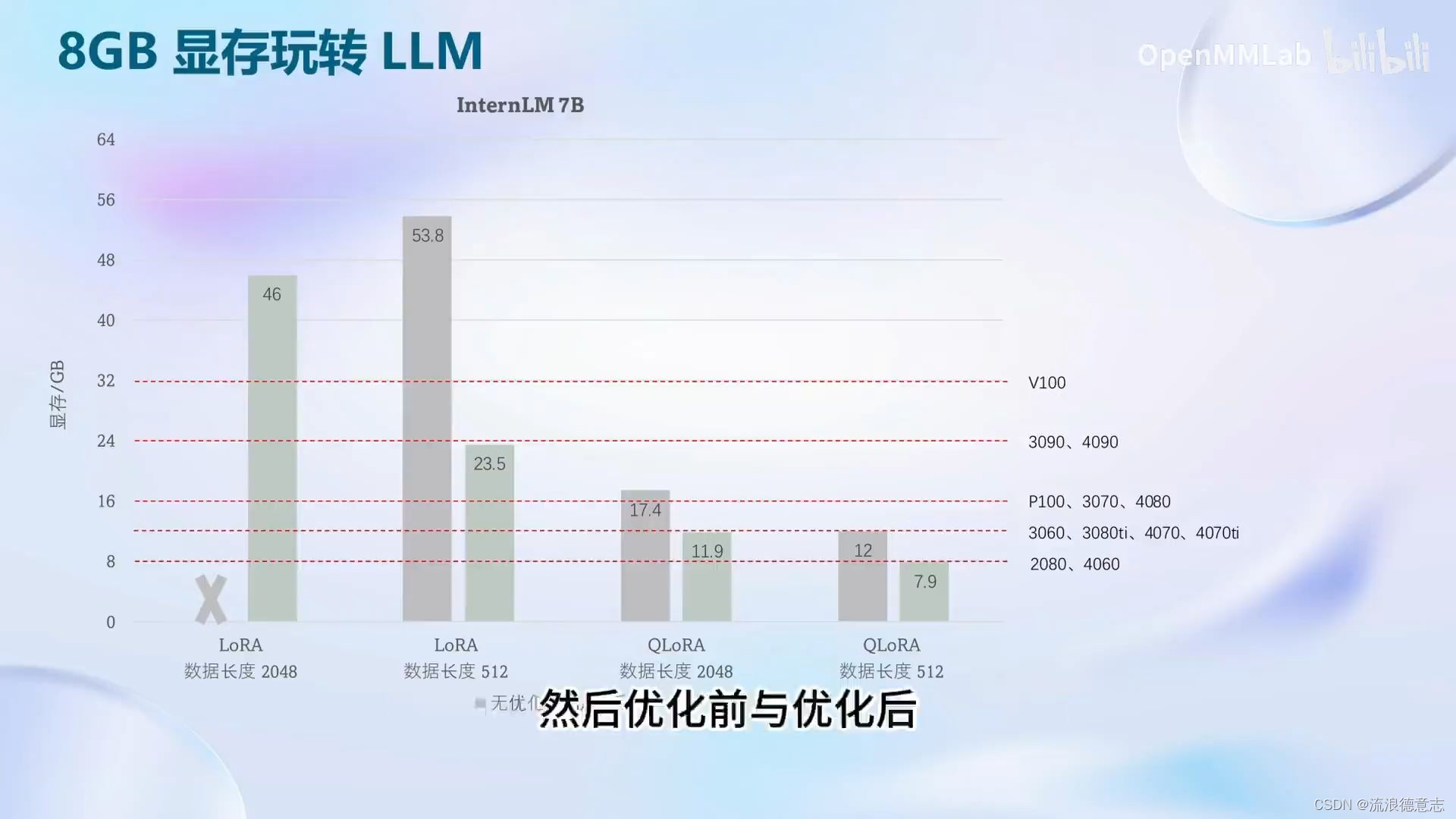
8GB 显卡玩转LLM
Flash Attention 和 DeepSpeed ZeRO 是 XTuner 最重要的两个优化技巧

Flash Attention
Flash Attention 将Attention 计算并行化。避免了计算过程中 Attention Score NxN的显存占用(训练过程的N都比较大)
DeepSpeed ZeRO
ZeRO优化,通过将训练过程中的参数,梯度和优化器状态切片保存,能够在多GPU训练时显著节省显存
除了将训练中间状态切片外,DeepSpeed 训练时使用FP16的权重,相较于Pytorch的AMP训练在单GPU上也能大幅节省显存。
为了能让开发者专注于数据,XTuner会自动dispatch Flash Attention,并一键启动DeepSpeed ZeRO
对于QLora,则在启动时使用参数 --deepspeed deepspeed_zero3
下面是优化前与优化后显存占用情况
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!