Kibana搜索数据利器:KQL与Lucene
一、搜索数据
默认情况下,您可以使用 Kibana 的标准查询语言,该语言具有自动完成功能和简单易用的语法。Kibana 的旧查询 语言(基于 Lucene 查询语法) 目前在查询栏中的选项菜单下仍然可用。当这个 选择传统查询语言,也可以使用完整的基于 JSON 的 Elasticsearch 查询 DSL。
提交搜索请求时,直方图、文档表和字段 列表将更新以反映搜索结果。默认情况下,匹配以反向列出 按时间顺序排列,最先显示最新文档。您可以反转 通过单击“时间”列标题来排序顺序。
二、KQL查询
Kibana Query Language(KQL)是一种用于在Kibana中进行搜索和过滤数据的查询语法
1、字段搜索
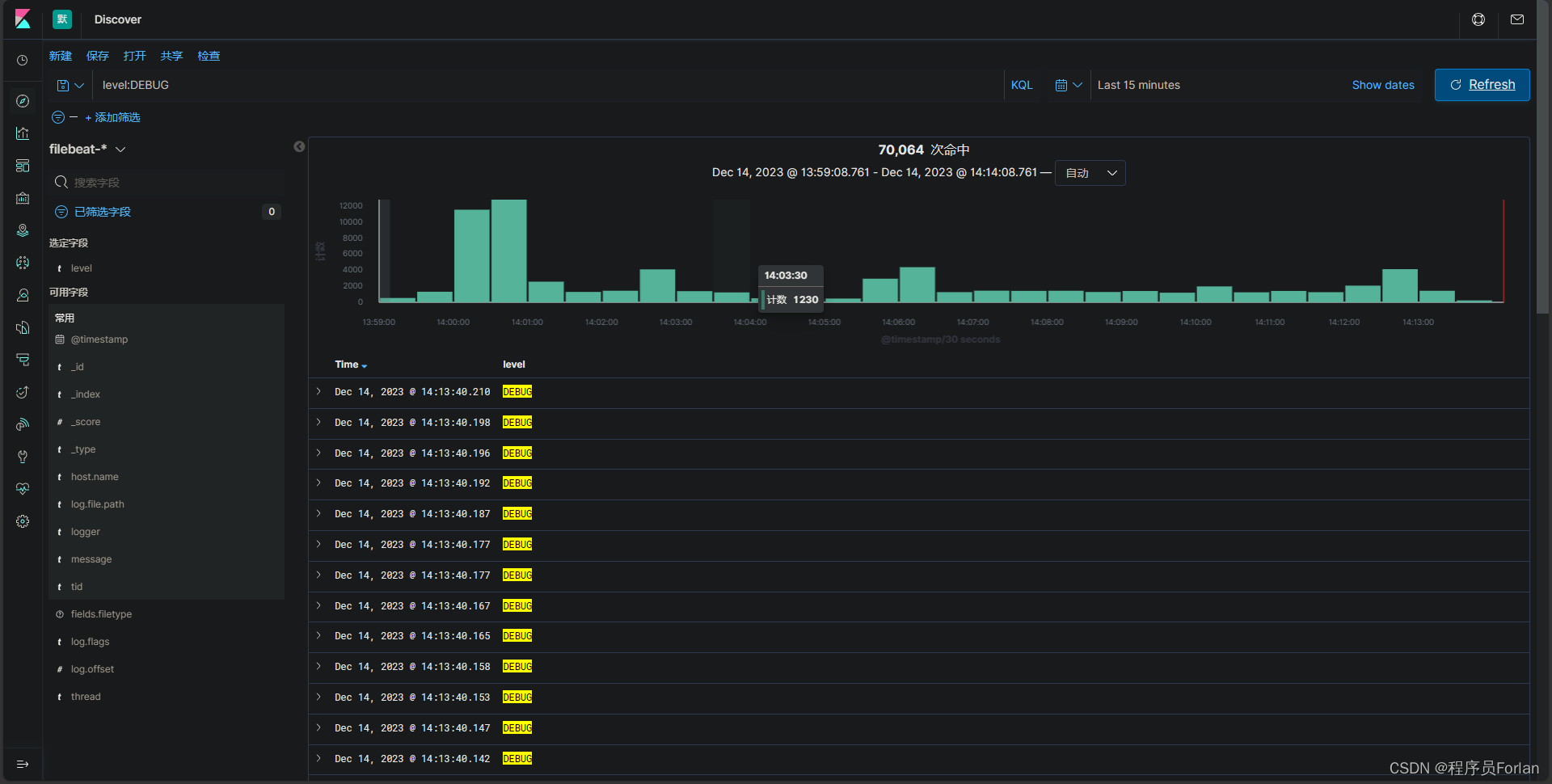
使用field:value的格式来搜索特定字段中的值。
例如,level:DEBUG,将返回level包含DEBUG的文档。
2、逻辑运算符
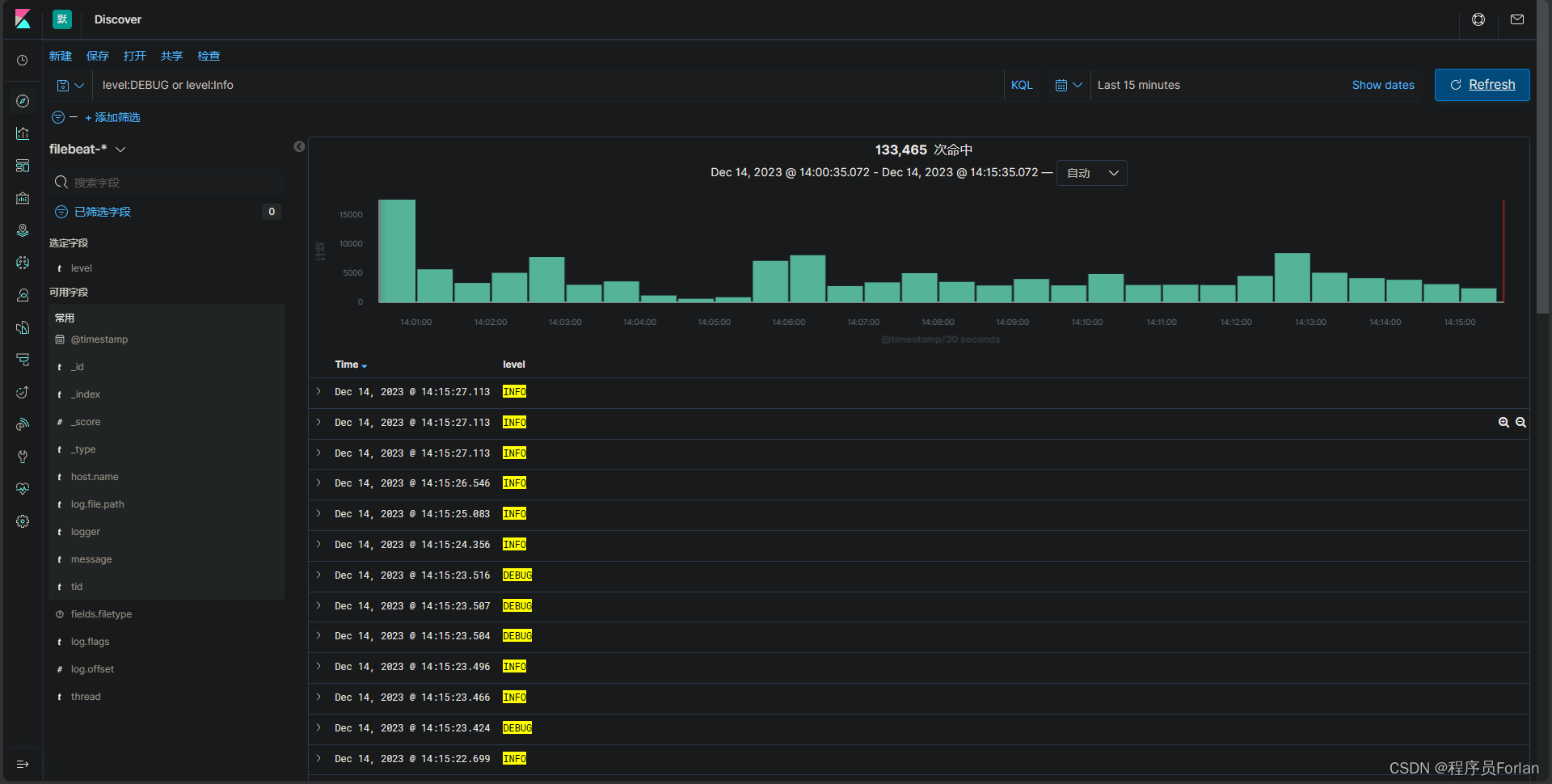
逻辑运算符:KQL支持逻辑运算符AND、OR和NOT来组合多个条件。
例如,level:DEBUG or level:Info,将返回level包含DEBUG或info的文档,不区分大小写。
3、通配符
通配符:使用*作为通配符来匹配任意字符。
例如,tid:*6199,将返回以"6199"结尾的tid的文档。

4、存在性检查
存在性检查:使用field:*来检查字段是否存在。
例如,@timestamp:*将返回具有`@timestamp字段的文档。

5、括号
括号:使用括号来分组条件。
例如,@timestamp:"2023-12-14T06:55:32.548Z" and (level:info or level:DEBUG)将返回指定时间的level是info 或DEBUG的文档。

三、Lucene查询
Kibana的旧查询语言基于 Lucene 查询语法。目前,此语法 在查询栏和高级设置中的选项菜单下仍然可用。
1、字段搜索
字段搜索:使用field:value的格式来搜索特定字段中的值。
例如,level:DEBUG,将返回level包含DEBUG的文档。

2、逻辑运算符
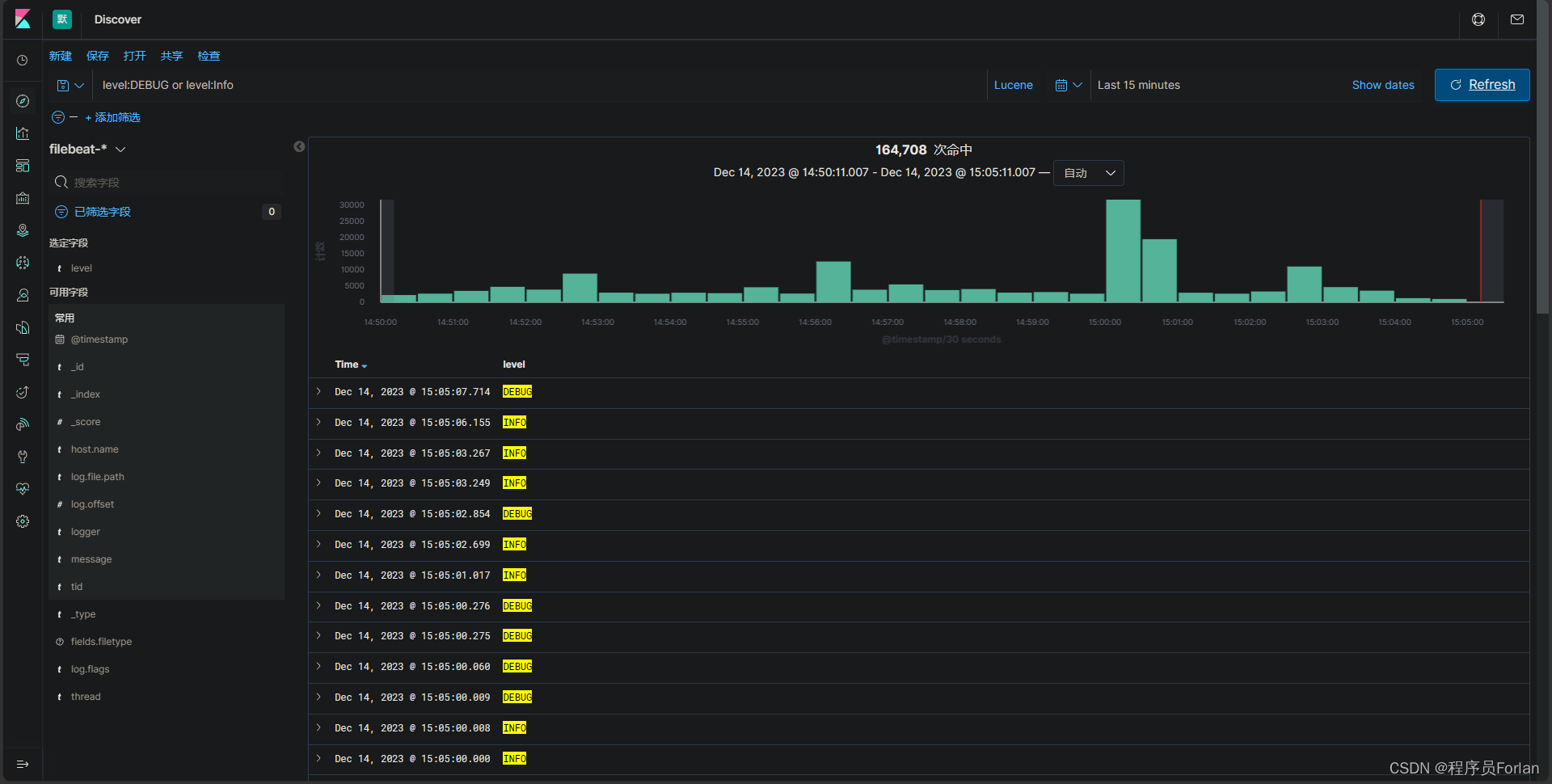
逻辑运算符:Lucene支持逻辑运算符AND、OR和NOT来组合多个条件。
例如,level:DEBUG or level:Info,将返回level包含DEBUG或info的文档,不区分大小写。
3、通配符
通配符:使用*作为通配符来匹配任意字符。
例如,tid:*0001,将返回以"0001"结尾的tid的文档。

4、范围搜索
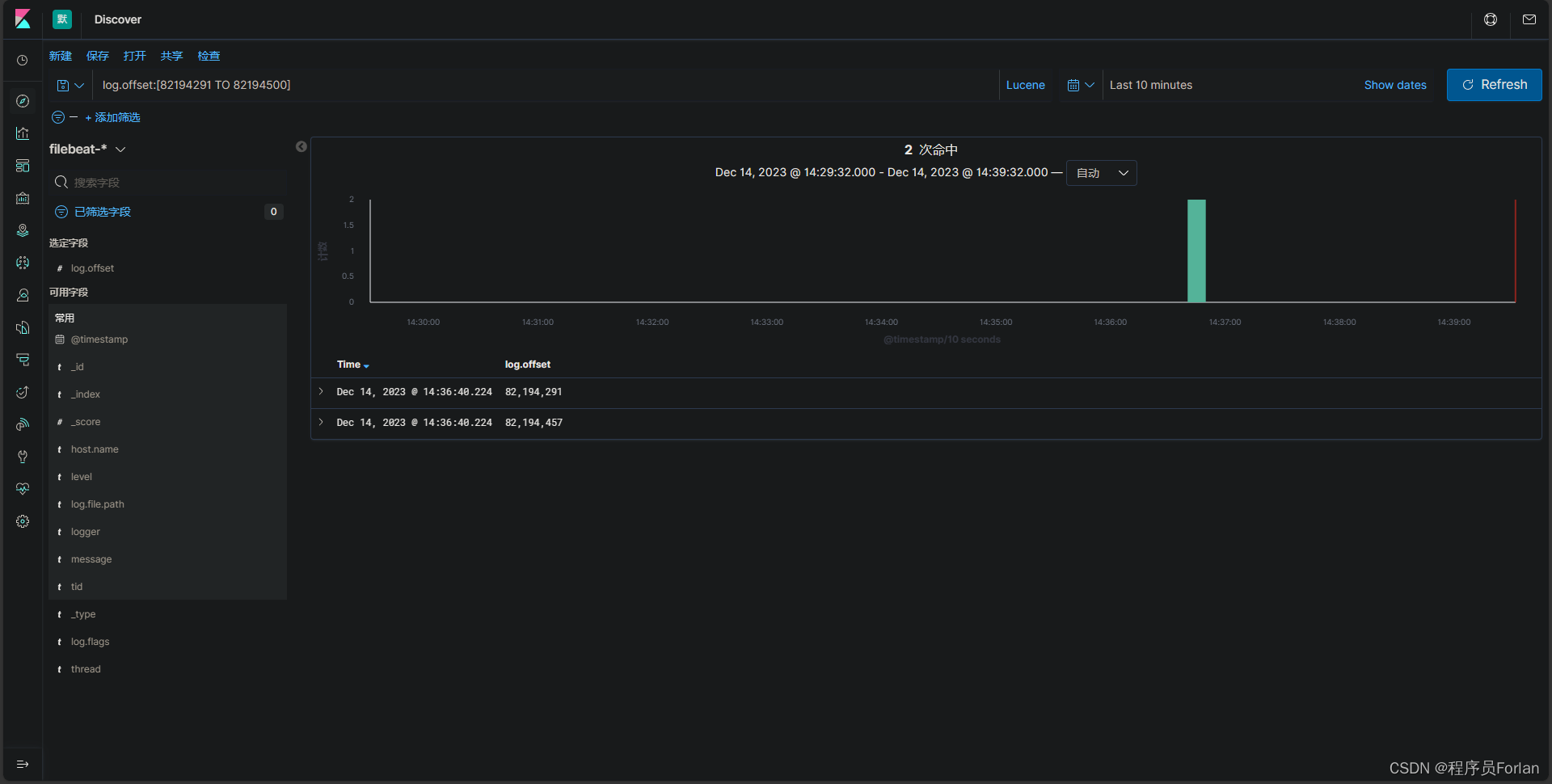
范围搜索:使用field:[start TO end]的格式来搜索字段中的范围。
例如,log.offset:[82194291 TO 82194500]将返回log.offset在82194291到82194500之间的文档。
5、存在性检查
存在性检查:使用field:*来检查字段是否存在。
例如,@timestamp:*将返回具有`@timestamp字段的文档。
6、括号
括号:使用括号来分组条件。
例如,@timestamp:"2023-12-14T07:06:40.472Z" AND (level:info OR level:DEBUG)将返回指定时间的level是info 或DEBUG的文档。
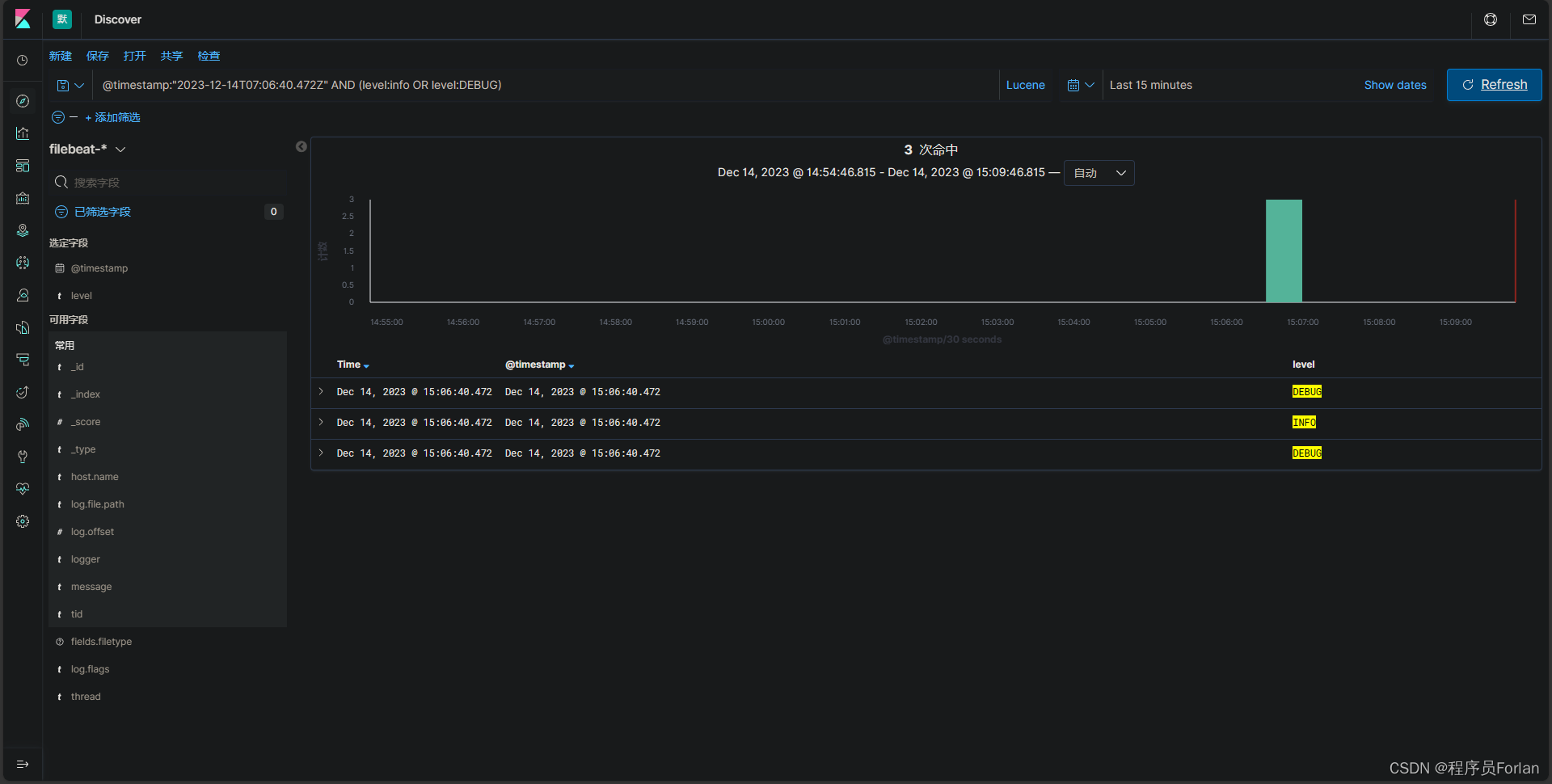
和KQL语法有区别,条件AND、OR需要大写
四、总结
KQL(Kibana Query Language)和Lucene查询语法在一些方面有一些区别:
语法结构:KQL使用更简洁和易于理解的语法结构,更接近自然语言,使得查询更易于编写和阅读。而Lucene查询语法则更为底层和灵活,需要更多的语法知识和操作。
功能支持:KQL在Kibana中内置了一些特定的功能,如直接在编辑器窗口中生成和编辑代码、支持自动调试和代码库全局理解等。而Lucene查询语法则更通用,可以更灵活地构建复杂的查询。
可扩展性:Lucene查询语法在Elasticsearch中更为底层,可以支持更多高级的查询操作和功能。而KQL是Kibana特定的查询语言,功能相对较为有限。
学习曲线:由于KQL的语法更简洁和易于理解,学习和使用起来相对较为容易。而Lucene查询语法需要更多的语法知识和经验,学习曲线相对较陡。
总的来说,KQL更适合在Kibana中进行简单和常见的搜索和过滤操作,而Lucene查询语法则更适合在Elasticsearch中进行更复杂和高级的查询操作。
详细可以参考官方文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python 神经网络归纳
- TCP 传输的三次握手、四次挥手策略
- Java代理设计模式--静态代理和动态代理
- 数字信号处理教程学习笔记1-第2章时域中的离散信号和系统
- 商家如何把小程序当做POS收款机使用
- 代码随想录算法训练营第二十天| 654.最大二叉树、617.合并二叉树、700.二叉搜索树中的搜索、98.验证二叉搜索树
- arm day7
- SSM 基础面试题
- 实时、精准:数字孪生水闸管理的未来
- 动态分区分配算法-第四十四天