Python爬虫之两种urlencode编码发起post请求方式
发布时间:2023年12月20日
背景
闲来无事想爬一下牛客网的校招薪资水平及城市分布,最后想做一个薪资水平分布的图表出来
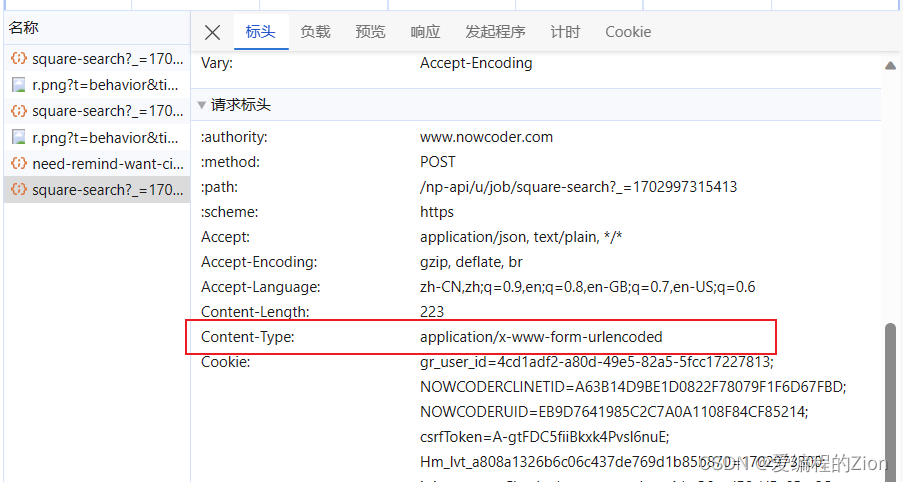
 于是发现牛客使用的是application/x-www-form-urlencoded的格式
于是发现牛客使用的是application/x-www-form-urlencoded的格式
测试
首先可以先用apipost等测试工具先测试一下是否需要cookie之类的,发现是不需要的,通过urlencode编码的方式也能够请求到数据

于是开始写代码
coding
这里给出两种方式:
首先使用错误的编码格式肯定是拿不到数据的

①通过urllib
import requests
import time
import json
from urllib.parse import urlencode
import urllib.request
timestamp = time.time()
timestamp_milliseconds = int(timestamp*1000)
newcode_job_url = f"https://www.nowcoder.com/np-api/u/job/square-search?_={timestamp_milliseconds}"
form_data = {
"careerJobId": "",
"jobCity": "",
"page": 1,
"query": "开发",
"random": "true",
"recommend": "false",
"recruitType": 1,
"salaryType": 2,
"pageSize": 20,
"requestFrom": 1,
"order": 0,
"pageSource": 5001,
"visitorId": "4cd1adf2-a80d-49e5-82a5-5fcc17227813"
}
form_data["jobCity"] = "北京"
# 需要手动编码
form_data = urlencode(form_data).encode()
request = urllib.request.Request(newcode_job_url)
response = urllib.request.urlopen(request,form_data)
print(response.read().decode())②通过requests(建议)
通过requests简直不要太方便,因为requests会自动使用合适的编码格式进行编码
import requests
import time
import json
from urllib.parse import urlencode
import urllib.request
timestamp = time.time()
timestamp_milliseconds = int(timestamp*1000)
newcode_job_url = f"https://www.nowcoder.com/np-api/u/job/square-search?_={timestamp_milliseconds}"
form_data = {
"careerJobId": "",
"jobCity": "",
"page": 1,
"query": "开发",
"random": "true",
"recommend": "false",
"recruitType": 1,
"salaryType": 2,
"pageSize": 20,
"requestFrom": 1,
"order": 0,
"pageSource": 5001,
"visitorId": "4cd1adf2-a80d-49e5-82a5-5fcc17227813"
}
form_data["jobCity"] = "北京"
response = requests.post(newcode_job_url, data=form_data)
print(response.text)结果
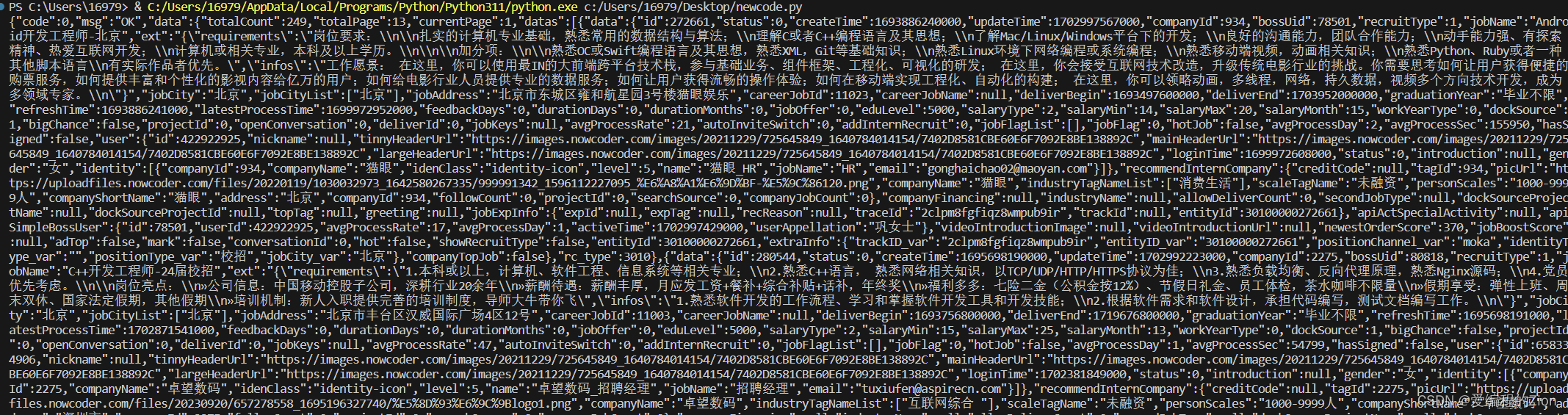
文章来源:https://blog.csdn.net/alianfibakic/article/details/135096387
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 训练营第五十一天 | ● 309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费 ●总结
- R语言生物群落(生态)数据统计分析与绘图教程
- 【云原生之kubernetes实战】在k8s环境下部署flatnotes笔记工具
- WPF实现拖拽获取文件
- HubSpot能不能对接微信公众号?
- 背会了常见的几个线程池用法,结果被问翻了
- 摄影企业网站搭建的作用是什么
- 50个开发必备的Python经典脚本(1-10)
- 求职小程序列表基础配置-移动端通用列表模块配置教程(1)
- 【树莓派4b的uboot编译移植】