【hcie-cloud】【12】华为云Stack故障处理【故障处理通用处理原则、常见华为云Stack故障处理(计算域故障场景)】【上】
发布时间:2023年12月24日
文章目录
- 前言
- 故障处理通用处理原则
- 常见华为云Stack故障处理
- 计算域故障场景
- 应知应会 - ECS创建的业务流
- 底层OpenStack创建ECS流程
- 常见ECS发放失败报错代码
- ECS创建失败故障信息收集方法
- 方法一 - ManageOne运营面订单提交异常排查
- 方法二 - 排查告警,收集故障信息
- 方法三 - 检查OpenStack服务日志记录
- 方法四 - 调用链工具辅助收集对应ECS信息
- ECS创建失败日志查看
- 故障定位 - 查看ECS创建失败组合API日志
- 故障定位 - 查看ECS发放失败组合API日志
- 故障定位 - 查看ECS发放失败组合API日志,请求是否到nova
- 如何获取创建失败虚拟机的id和创建操作req-id (1)
- 如何获取创建失败虚拟机的id和创建操作req-id (2)
- 故障一 - 选不到主机创建失败 (no valid host)
- 故障处理 - 查看Nova-scheduler日志
- 故障处理
- 故障二 - 已经选到主机但创建失败 (1)
- 故障二 - 已经选到主机但创建失败 (2)
- Nova过滤器HuaweiDiskFilter过滤失败 (1)
- Nova过滤器HuaweiDiskFilter过滤失败 (2)
- 查看nova-scheduler失败日志收集故障信息
- 常见华为云Stack故障处理(存储域故障场景、网络域故障场景)、华为云的OpenStack故障排查常用命令、缩略语
前言
- 本章主要讲述在各个场景中HCS常见的故障处理解决方案,以及利用工具辅助故障处理。
- 学完本课程后,您将能够:
- 熟悉使用工具辅助故障处理
- 熟悉常见故障的场景与现象
- 明确各种场景化故障的任务
- 执行进行相应的措施
- 熟悉常见问题底层排查思路
故障处理通用处理原则
故障处理流程
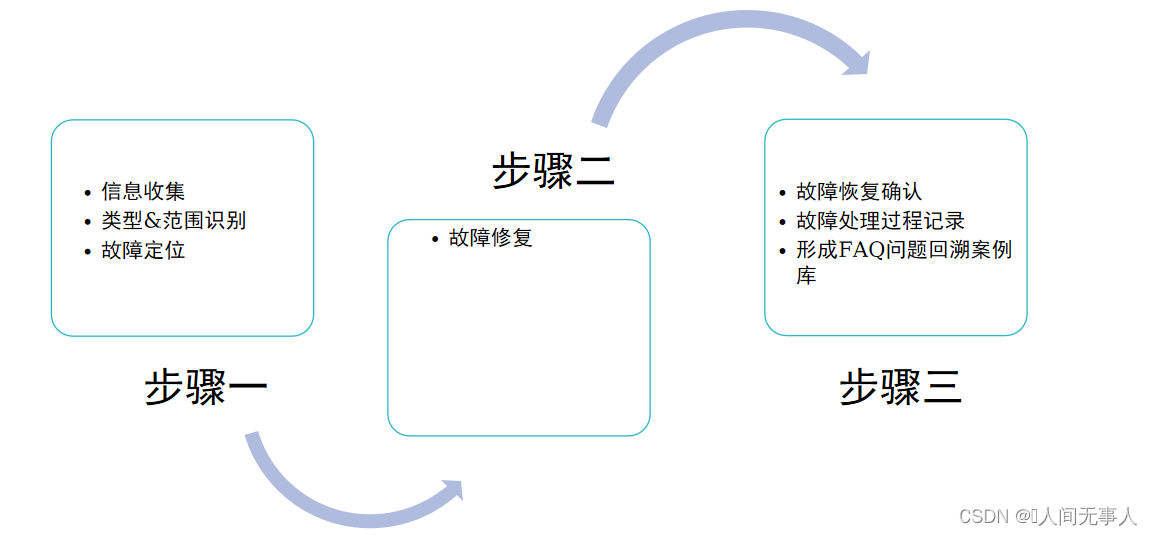
- 故障处理的总体流程包括: 故障信息收集、故障类型判断、故障定位、故障恢复、故障恢复确认、故障处理过程记录。
- 故障信息是故障处理的重要线索。系统维护人员应尽可能多地收集故障信息。
- 在排除故障之前,系统维护人员根据收集的故障详细信息,对故障范围和类型进行判断。
- 通过一定的方法或手段分析、比较各种可能的故障成因,不断排除非可能因素,最终确定故障发生的具体原因。
- 针对不同的故障原因,进行相应的故障处理。
- 确认设备状态正常、设备指示灯正常或告警已清除,通过业务相关测试确认业务正常。
- 故障排除后应记录故障处理要点,给出针对此类故障的防范和改进措施,避免同类故障再次发生。
故障信息收集及故障范围、类型识别
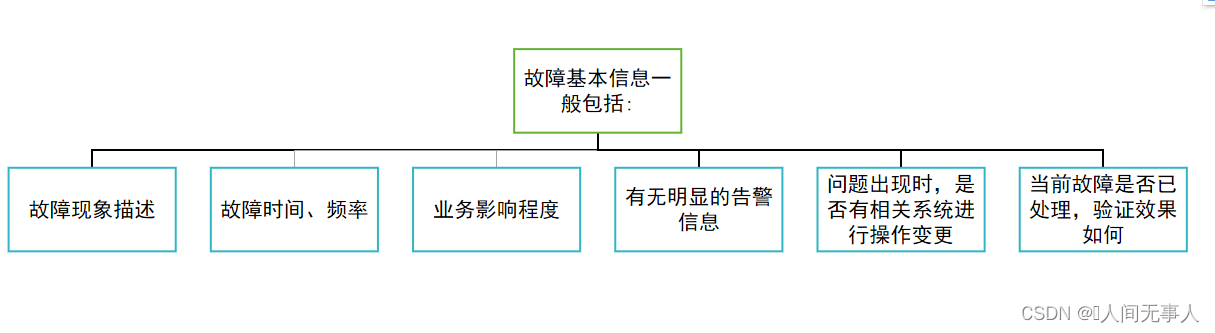
ManageOne运维面收集告警信息
华为云Stack运维面集中告警可以集中监控系统服务或第三方系统的告警,快速定位已发生的故障,从而保证业务正常运行。集中告警致力于适配不断演进的复杂网络的监控和运维,不仅能支撑传统网络的故障监控与处理,还能对新一代网络进行故障监控,不断缩短故障恢复时长,提升网络运维效率
 ## AutoOps工具采集故障的场景
## AutoOps工具采集故障的场景
- AutoOps提供内置常用的运维脚本库,这些脚本库足以满足日常运维的需求,如果内置的脚本库不满足需求,也支持编写适合自己业务场景的新脚本。华为云Stack解决方案维护和二线服务TAC基于现网情况梳理出TOP20高频问题,解决方案维护团队基于AutoOps平台开发如下编排工具
| 故障场景名称(中文) | 故障场景名称(英文) | 对应极限场景编码 |
|---|---|---|
| FS-01013 冷迁移虚拟机失败 | FS-01013 Failed to cold migrate a VM | FS-01013 |
| FS-05004 主机状态异常 | FS-05004 Abnormal Host Status | FS-05004 |
| FS-05006 虚拟机HA失败 | FS-05006 VM HA Failure | FS-05006 |
| FS-01006 热迁移虚拟机失败 | FS-01006 Failed to migrate a VM | FS-01006 |
| FS-01002 删除虚拟机失败 | FS-01002 Failed to delete a VM | FS-01002 |
| FS-01003 启动虚拟机失败 | FS-01003 Failed to start a VM | FS-01003 |
| FS-01004 停止虚拟机失败 | FS-01004 Failed to stop a VM | FS-01004 |
| FS-01005 重启虚拟机失败 | FS-01005 Failed to restart a VM | FS-01005 |
| FS-01007 克隆虚拟机失败 | FS-01007 Failed to clone a VM | FS-01007 |
| FS-01009 VNC登录失败 | FS-01009 Failed to login with VNC window | FS-01009 |
- AutoOps根据场景不同提供内置运维自动化脚本包,可至华为Support网站下站运维自动化脚本包,将相应软件包导入到ManageOne运维面的“日常运维 > 自动作业”界面,借助自动化运维平台,帮助运维人员自动化进行云信息收集、便于进行故障诊断初步定界定位等常见的故障处理工作,提升故障处理的效率。
- Support网站根据企业网和运营商提供ManageOne AutomationScripts 8.X.X发布了不同版本的运维自动化脚本包
- 企业网用户:https://support.huawei.com/enterprise/zh/cloud-computing/manageone-automationscripts-pid-250623328/software
- 运营商用户:https://support.huawei.com/carrier/productNewOffering?col=product&path=PBI1-21430725/PBI1-23710112/PBI1-21431666/PBI1-21782552/PBI1-250623328&resTab=SW
- 注意:
- 当内置操作里所提供的操作不能满足管理员需求是,AutoOps要使用自定义操作必须满足:已部署AutoOps服务;产品许可(License)模式,具有运维中心高级版许可。
- 租户侧ECS及BMS使用Auto功能必须满足条件:具有运维中心高级版许可,具有“运维自动化平台Auto组件”,即存在ManageOne-Auto节点。
AutoOps工具故障场景信息收集
-
AutoOps工具故障场景信息收集
- 云档案:HCS概览信息收集
- 基础公共服务:LVS、Nginx、HAProxy、GaussDB、NTP、DNS、CCS等服务信息收集
- 基础云服务:ECS、BMS、AS、IMS、VPC、EVS、FSM、OBS等服务信息收集
- 网络服务:EIP_IPV6访外网络、EBL网页节点信息、基础云专线网络信息、VPC_Peering网络信息、SNAT_DNAT等网络信息收集
- 基础底座:Nova、Cinder、Neutron、Glance、Ironic等组件信息收集
- 容器使能:CCE、SWR服务信息收集
- 应用使能:ROMA-Connect服务信息收集
- 平台升级:HCS升级前检查信息收集
-
使用AutoOps工具自动化信息收集,旨在优化运维模式,提升运维效率。支持:云档案、基础公共服务、基础云服务、网络服务、Openstack组件等信息的收集,内置的软件包提供的信息收集功能将可能会收集环境中的资源实例信息,包括但不限于:实例名称、IP地址、实例配置等(不包括租户相关账户、密码等)
-
利用自动化工具收集信息具有以下特点:
- 全,一次性收集全需要的信息;
- 易,一键式收集操作容易;
- 简,简化运维人员之间沟通过程;
AutoOps工具自动化采集HCS信息 (1)
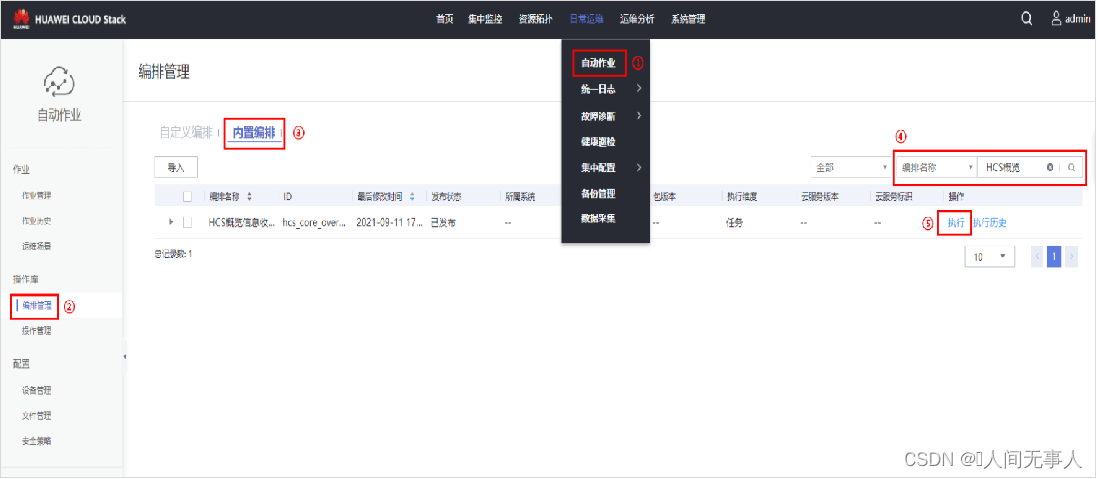
- 内置编排导入自动化软件包以后,可以采集相关信息辅助运维工作,大大提高运维工作效率。
例如:通过导入HCS概览信息自动化软件包后,可以通过编排管理执行自动化脚本采集HCS相关信息,通过“执行”,填入相关参数信息后。 - 能够采集ManageOne管理的所有Region的基本信息,包括ESN、Region列表、部署模型、云服务使用情况、资源使用情况、计算存储设备列表等信息(已脱敏处理)。
- 建议在需要收集云环境的概况信息时使用,以帮助了解环境的部署情况和业务规模等。
- 注意:收集结果中可能包含有设备列表、配置等信息,但不包含任何租户账户、密码、实例内部业务等信息,请将收集结果妥善保管,谨防敏感信息泄漏。
AutoOps工具自动化采集HCS信息 (2)
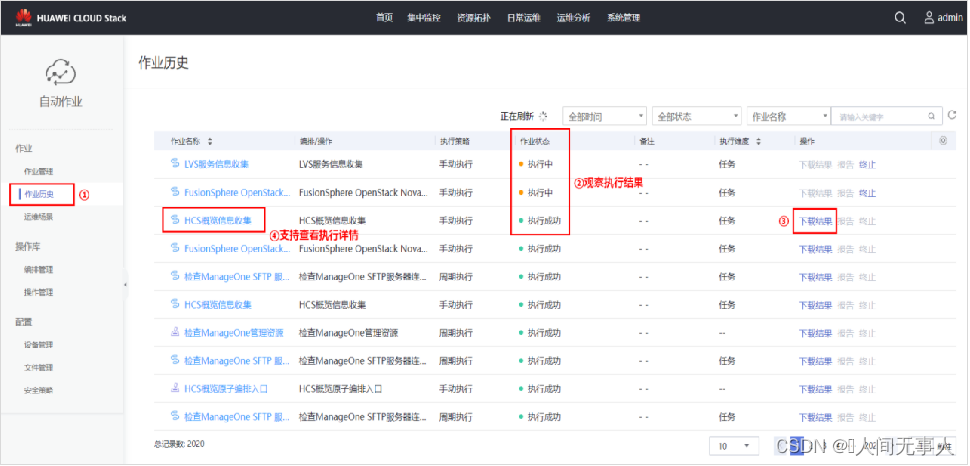
- 执行成功后,AutoOps提供一个采集完成后的“下载结果”的压缩包。假如采集失败,也可以通过执行详情查看失败原因进行分析。
故障初期定位方向

- 当出现故障已经影响了业务,首要是最快的找出问题点,缩短故障业务时间。常见有效的故障定位一般三个方向:
- 告警,一般故障产生会产生相应告警。例如,可以根据告警详情里面的IP地址,可以锁定故障点。另外华为大部分告警集成了相应的解决方案,可去产品文档、support等网站根据告警寻找相应案例。
- 操作日志:根据经验,现网中有很大一部分故障,都是由变更或者误操作导致。所以当出现故障时,查找操作日志,以及询问近期是否做过什么更改环境的配置的变更尤为重要,假如更改了,根据情况恢复原配置。能够极大缩减运维排查故障,以及解决故障的时间。
故障恢复
- 根据故障原因,处理故障
- 报警
如果报警符合故障现象,则根据告警帮助处理故障 - 监测
性能不足导致的问题,建议扩容 - 操作错误
如果操作日志提示错误,请恢复错误的操作 - 数据配置错误
如果数据配置不正确,可以通过重新配置来排除故障 - 硬件状态异常
当硬件设备发生故障时,请根据硬件设备指示灯的状态排除故障
- 报警
例行维护
- 日常维护有利于提前定位和解决问题
- 日常维护计划和维护文档,可以快速解决故障
讨论: 哪一环比较重要?为什么?
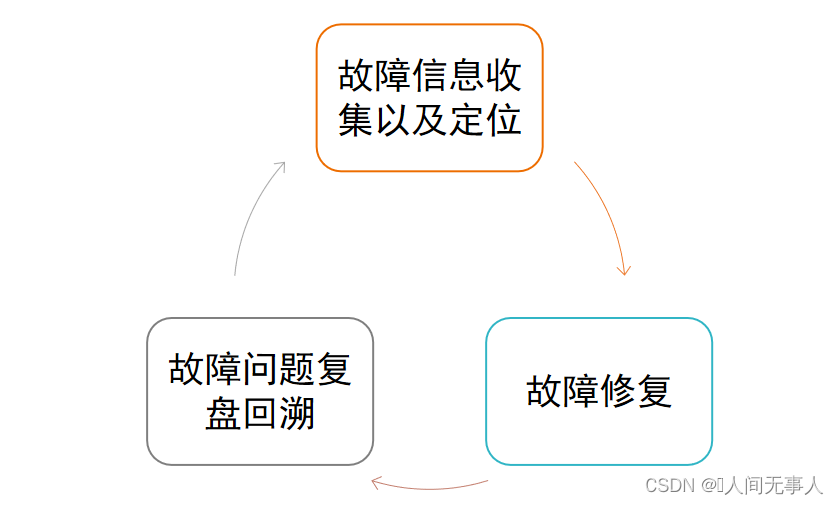
- 目前各大互联网公司会定期会根据平时的故障问题回溯,组建FAQ案例库、操作指引等文档输出,形成一个各种场景经验沉淀,避免或减少同样的问题复现以及减少业务中断,定期经典问题定期部门贯穿。
- 根据运维故障处理经验,在可控范围内进行故障演练,运维白屏化。
常见华为云Stack故障处理
计算域故障场景
应知应会 - ECS创建的业务流
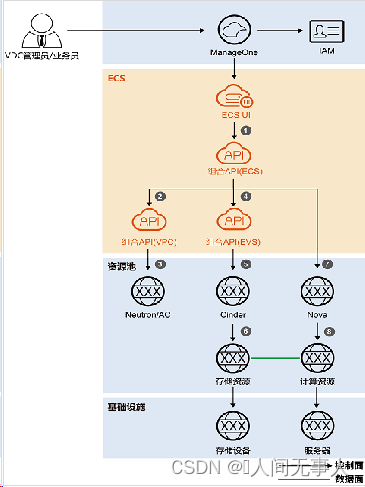
- ECS发放的逻辑架构:
- 在ECS界面上申请资源
- 组合API中ECS的接口调用组合API中VPC的接口
- VPC接口调用Neutron或AC创建EIP、端口等
- 组合API中ECS的接口调用组合API中EVS的接口
- EVS接口调用Cinder
- Cinder根据申请存储资源的策略在存储池创建卷
- ECS接口将需求下发至Nova
- Nova在计算资源池中创建虚拟机
底层OpenStack创建ECS流程
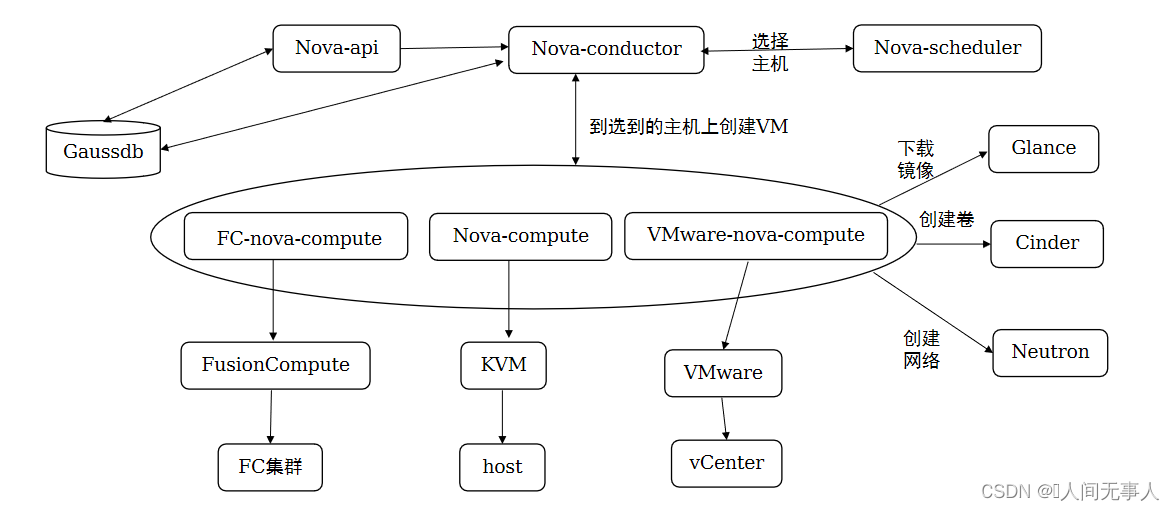
- nova-api接收到创建虚拟机请求,并进行基本的校验,包括: 入参,quota,规格,网络,虚拟机状态等
- nova-conductor接收到nova-api下发的请求之后调用nova-scheduler进行选主机,nova-scheduler通过各种过滤器过滤环境中的主机,最终选到一个最合适的主机,选到主机之后返回给nova-conductor,nova-conductor再发消息到该主机的nova-compute进程
- nova-compute进程收到创建虚拟机的消息之后,解析入参,进行下载镜像,创建卷,创建网络,然后在主机上启动虚拟机等操作;对接fc和vmware的场景则会调用fc和vmware提供的接口完成上面的这些操作。
常见ECS发放失败报错代码
- 任务中在创建ECS失败后会显示创建失败的原因
| 常见报错信息 | 可能原因 |
|---|---|
| create volume failed | 创建卷失败,云磁盘虚拟机创建分为2步:第一步,创建卷,第二步,根据卷创建虚拟机 |
| no valid host | 没有可用主机 |
| AvailabilityZoneFilter | 表示请求的az内没有找到合适的主机,注意az选择是否正确 |
| ComputeFilter | 表示备选主机的compute进程挂了,这个时候会有组件异常告警 |
| RamFilter | 表示备选主机的内存不足 |
| HuaweiDiskFilter | 表示备选主机的磁盘空间不足 |
| CoreFilter | 表示备选主机的vcpu数量不足 |
| HuaweiAggregateInstanceExtraSpecsFilter | 表示备选主机没有在指定的主机组中,这种一般都是在规格flavor中添加了主机组标签错误导致,去掉标签或者改为正确的标签即可 |
ECS创建失败故障信息收集方法
- ECS发放失败时,可以通过以下方法进行故障诊断和处理前的故障信息收集:

这些方法之间没有严格的先后顺序,需根据实际情况选择不同故障处理方法
方法一 - ManageOne运营面订单提交异常排查
- ManageOne运营面界面失败任务展开,查看错误提示信息,报错代码原因参考标题
常见ECS发放失败错误代码 - 假如运营面创建失败任务无法具体定位,使用F12打开web控制台,重新提交,查看报错接口,收集报错信息。如果不能复现,记录问题发生准确时间、虚拟机名,用于ManageOne和ECS联合定位
方法二 - 排查告警,收集故障信息
告警信息比较直观和重要,如果发现环境有异常,首先要看告警界面上的告警信息,特别是组件异常类、主机状态异常,存储链路中断、时间不同步,网络中断类等严重告警,这些将直接影响业务的发放,其他告警可根据情况判断是否影响创建虚拟机。若查看到这类影响业务发放的告警,按照对应的产品文档对告警进行相应的处理

方法三 - 检查OpenStack服务日志记录
- OpenStack的日志系统非常完善,大多数的故障都能从日志中找到原因
- OpenStack日志路径通常在
/var/log/fusionsphere/component/目录下
| 节点类型 | 服务 | 日志路径 |
|---|---|---|
| 控制节点 | nova-* | /var/log/fusionsphere/component/nova-*/ |
| 控制节点 | glance-* | /var/log/fusionsphere/component/glance-*/ |
| 控制节点 | cinder-* | /var/log/fusionsphere/component/cinder-*/ |
| 控制节点 | keystone-* | /var/log/fusionsphere/component/keystone-*/ |
| 控制节点 | neutron-* | /var/log/fusionsphere/component/neutron-*/ |
| 控制节点 | horizon | /var/log/fusionsphere/component/horizon/ |
| 计算节点 | libvirt | /var/log/fusionsphere/component/lIbvirt/ |
| 块存储节点 | cinder-volume | /var/log/fusionsphere/component/cinder-volume/ |
| CPT-SRV / 管理虚拟机 | Nova组合API | /var/log/apicom/taskmgr/ecm/ |
- OpenStack的组件日志存储在/var/log/fusionsphere/component/目录下
该目录下常见的日志:nova-api:nova是否接受到用户组合API下发的创建虚拟机的请求日志。Nova-scheduler:根据nova-api接受到的请求是否能够选择到一个合适的主机创建虚拟机日志;Nova-compute:根据虚拟机的创建规格,主机是否有足够资源或条件满足虚拟机创建。Cinder-api:接受创建卷请求日志Cinder-sheduler:选择合适的卷。Cinder-volume:创建卷的日志
方法四 - 调用链工具辅助收集对应ECS信息
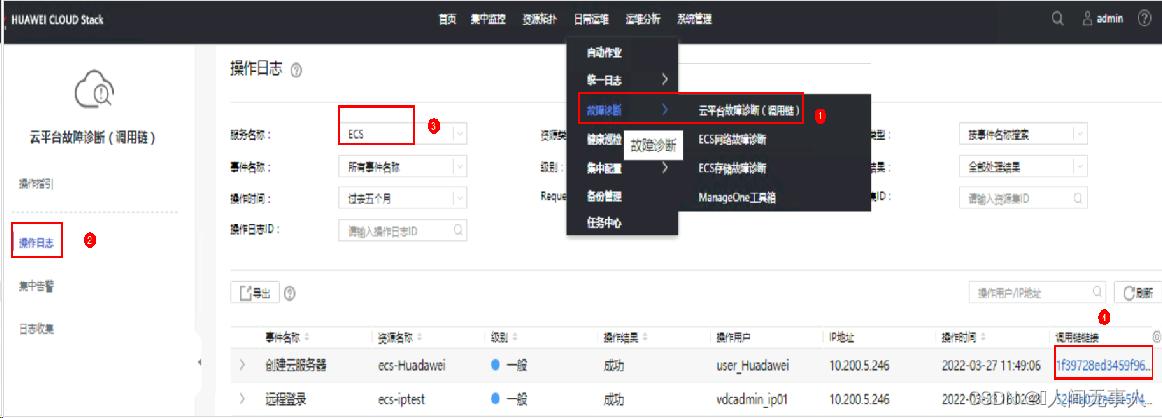
ECS创建失败日志查看
- ECS创建失败日志查看
- ManageOne运营面控制台查看创建ECS的任务是否失败,失败具体报错提示
- 查看名称为CPT-SRV的组合API管理虚拟机日志,可以查看到创建ECS的详情,以及请求是否下发到Nova-api
- Nova-scheduler日志可以判断是否选择到主机
- Nova-compute日志是否满足创建ECS条件
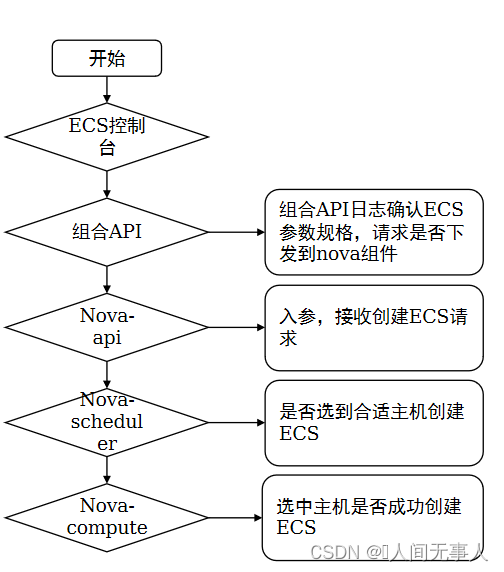
故障定位 - 查看ECS创建失败组合API日志
- 登录控制节点,导入环境变量后执行如下命令,获取apicom节点IP,登录组合API节点根据订单号获取Job_id信息
nova list --all-t |grep CPT-SRV

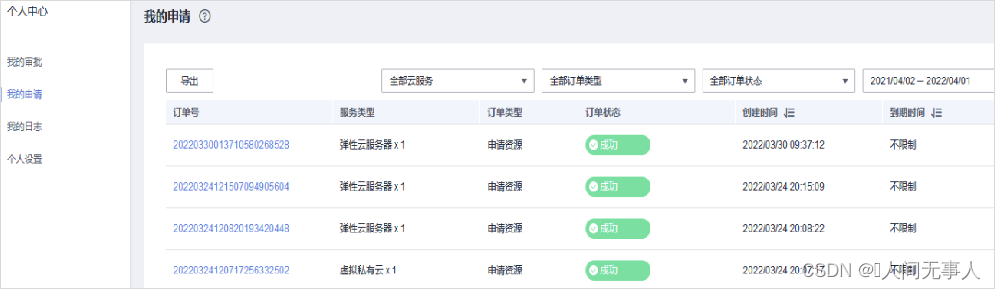
- 如果是通过ManageOne 运营面页面操作,且生成有订单号的话,执行命令
grep -rn订单号/var/log/apicom/taskmgr/找到以_api结尾的日志文件,然后进入该日志文件,根据订单号往下翻,找到与之相近的job_id;然后用job_id进入与之对应的executor.log里找日志;
故障定位 - 查看ECS发放失败组合API日志
- 根据创建ECS名称、创建时间点找出ECS的job_id,后续排查会一直使用
grep -rn 订单号 /var/log/apicom/taskmgr/

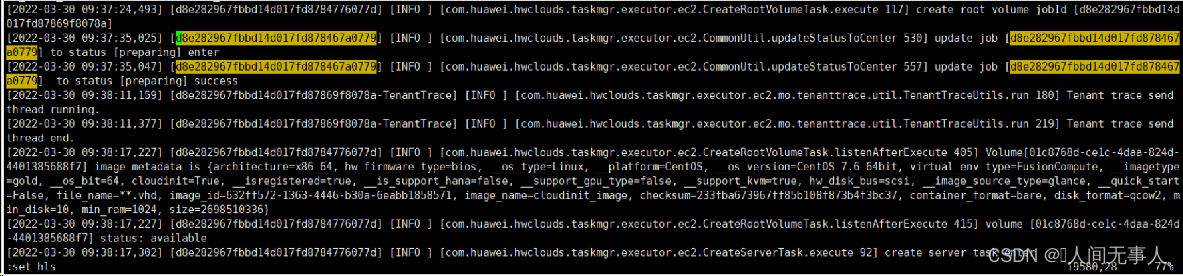
故障定位 - 查看ECS发放失败组合API日志,请求是否到nova
- 如果没有订单号,则直接进入如下目录,打开xxx_api.log和xxx_executor.log,找对应时间点的ERROR日志
- zgrep job_id /var/log/apicom/taskmgr/ecm/taskmgr_ecm_* | grep ERROR
- /var/log/apicom/taskmgr/ecm(虚拟机相关业务)
- /var/log/apicom/taskmgr/ims(镜像相关业务)
- /var/log/apicom/taskmgr/bms(裸机相关业务)
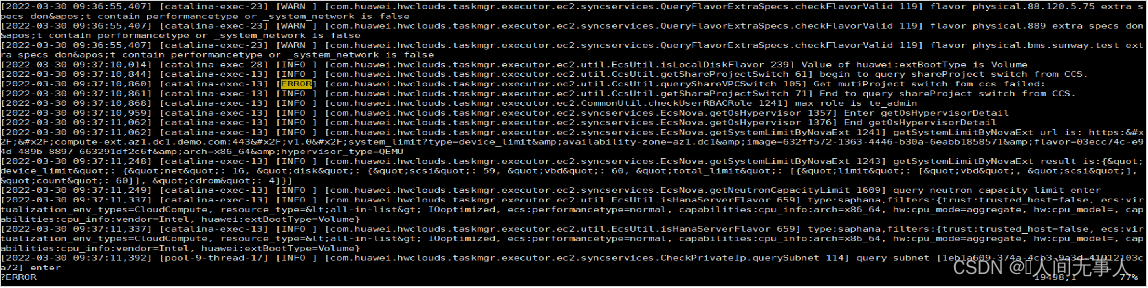
如何获取创建失败虚拟机的id和创建操作req-id (1)
- 步骤一:登录控制节点,source set_env导入环境变量
- 步骤二:获取虚拟机的ID,命令如下:
- 虚拟机未回滚:
nova list --all-t | grep vm_name - 虚拟机已回滚:
nova list --all-t --delete | grep vm_name
- 虚拟机未回滚:
- 步骤三:根据虚拟机id,找到创建虚拟机的操作req-id,命令如下:
nova instance-action-list vm_id
- 步骤四:在控制节点通过如下命令搜索nova-api日志:
zgrep vm_name /var/log/fusionsphere/component/nova-api/* |grep create
- 如果没有搜到,继续在其他两个控制节点上搜索,直到找到为止,找到之后要核对时间点,确认是本次创建虚拟机的时间点
如何获取创建失败虚拟机的id和创建操作req-id (2)
- 根据日志中的创建请求的req-id,后续通过这个id来搜索其他日志

- 在控制节点搜索nova-api日志,如果没有搜到,继续在其他两个控制节点上搜索,直到找到为止,找到之后要核对时间点,确认是本次创建虚拟机的时间点。
- Nova-api部署在控制节点1主2备,可通过
cps template-instance-list –-service nova nova-api确认,再根据回显优先登录active的nova-api所在控制节点查找日志。
- Nova-api部署在控制节点1主2备,可通过
故障一 - 选不到主机创建失败 (no valid host)
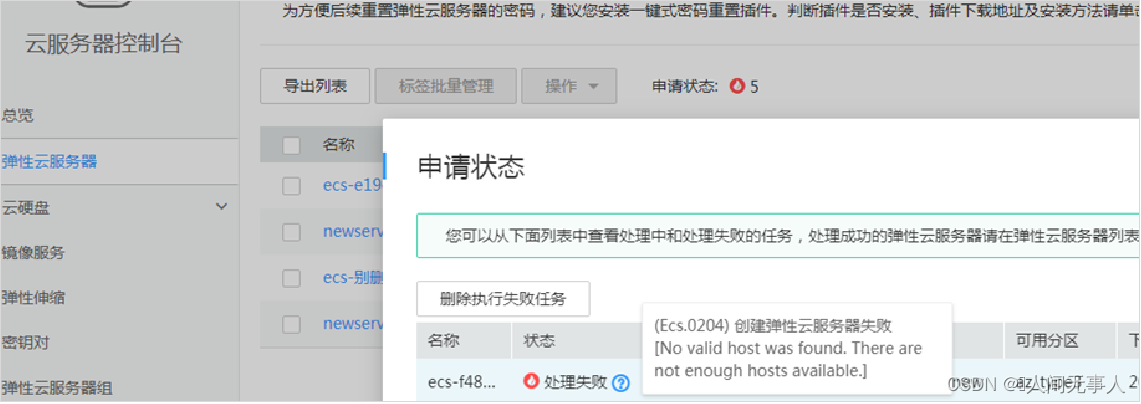
故障处理 - 查看Nova-scheduler日志
-
根据虚拟机ID,登录控制节点,导入环境变量后,执行如下命令,查看虚拟机create操作的req_id
- nova instance-action-list vm_id
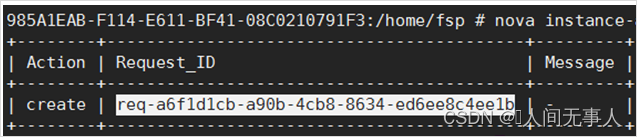
- nova instance-action-list vm_id
-
根据req_id,查看nova-scheduler日志查询失败过滤器,如失败则过滤器为HuaweiAggregateInstanceExtraSpecsFilter。失败代码原因参考第19张 “常见错误代码”,解决方法参考第下面标题
HuaweiAggregateInstanceExtraSpecsFilter过滤失败

HuaweiAggregateInstanceExtraSpecsFilter过滤失败
- 调度器原理
- 调度器主要通过将用户申请弹性云服务器所选择的规格中标签与主机对应主机组的标签进行比较(比较的时候不会对规格中标签的名称格式为“key:value”的标签进行比较,例如不会比较“ecs:performancetype”)
- 两种情况导致过滤器过滤失败
- 主机所属的主机组没有规格中的标签
- 主机所属的主机组中相同名称标签的值与规格中的不同
- 说明:主机组中的标签如果比规格中的标签多,并不会导致过滤失败
故障处理
- 查看nova-scheduler日志
zgrep req-id /var/log/fusionsphere/component/nova-scheduler/* | grep hw_agg_instance_extra_specs,req-id- 错误日志1:
'set([u'IOoptimized'])' do not match 'IOoptimized2' - 主机所属的主机组中存在标签的值(u’IOoptimized’)与虚拟机规格的标签的值(IOoptimized2)不一致

- 错误日志2:
Extra_spec resource_type is not in aggregate
主机所属的主机组没有名称key为“resource_type”标签,而虚拟机规格中有该标签

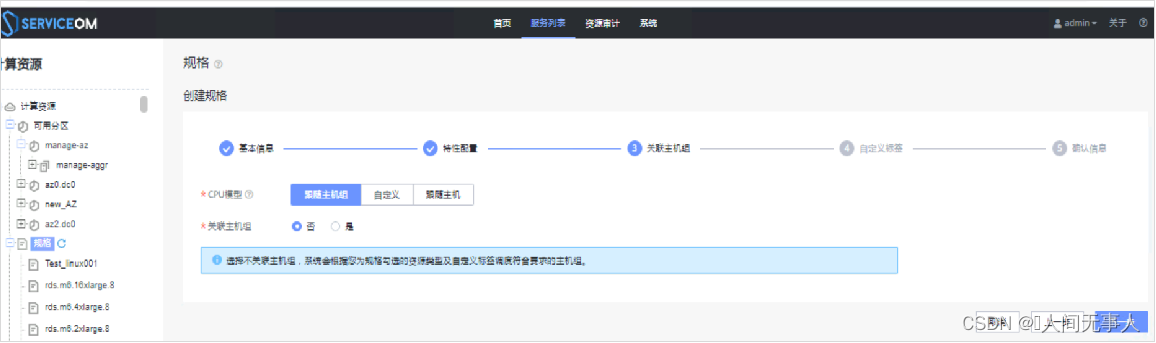
解决方案一 - 使用新的规格
- Service OM的服务列表—计算资源—规格,重新创建一个规格,设置标签的时候,设置与待发放的目标主机组相同的内容
- 规格申请成功后,重新发放业务
解决方案二 - 修改主机组的标签
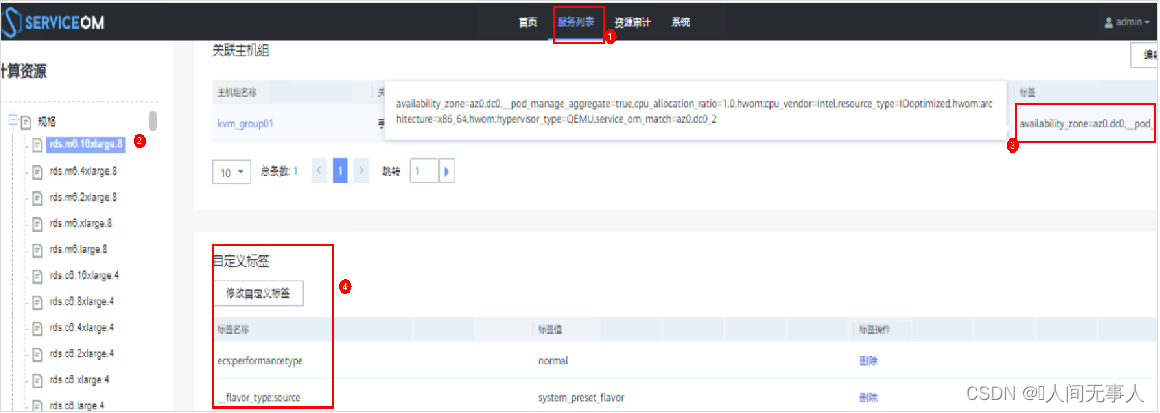
- 如果主机组已经下发过业务,不允许修改标签值。可以使用解决方案3
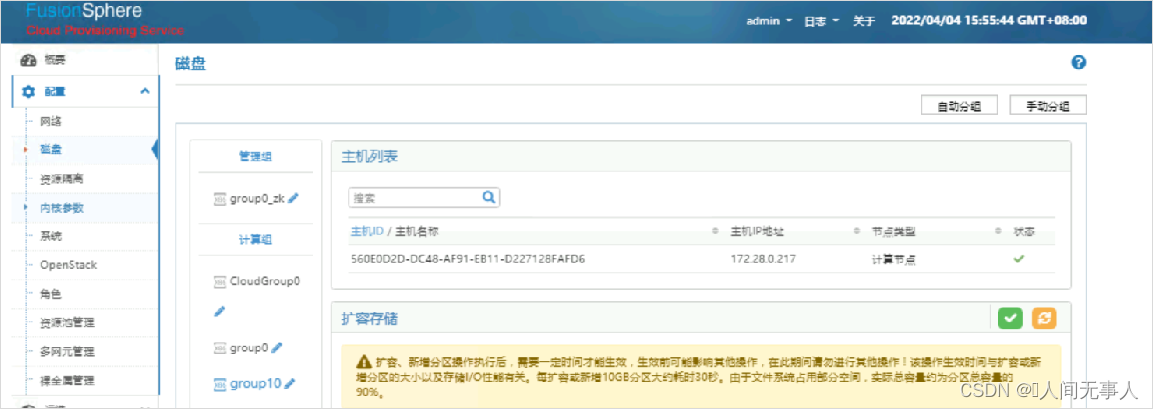
解决方案三 - 扩容新的主机组、扩容新的计算节点
CPS上创建一个新的主机组,新的主机组规格与ECS规格保持一致
故障二 - 已经选到主机但创建失败 (1)
- 故障原因
- 常见原因为指定主机创建虚拟机资源不足
- 根据req_id,使用如下命令查询nova-sheduler日志,是否选到主机,选到那台主机
zgrep req-9f7cbe5b-dac5-4ca1-a036-5173073ec764 /var/log/fusionsphere/component/nova-scheduler/* | grep Sele

故障二 - 已经选到主机但创建失败 (2)
- 登录Service OM查看选择到的主机节点和主机所在集群资源使用情况
- 根据req_id查看选择到的主机节点上的nova-compute组件ERROR日志。参考《HCS设备上架与扩容》课程内容进行扩容
cat var/log/fusionsphere/component/nova-compute/nova-compute_error.log.100 |grep error

Nova过滤器HuaweiDiskFilter过滤失败 (1)
- 调度器原理
- 虚拟机的规格disk或者swap有值,则会使用计算节点的image分区空间
- 故障原因
- 参考第上面标题
常见ECS发放错误代码为主机磁盘空间不足
- 参考第上面标题
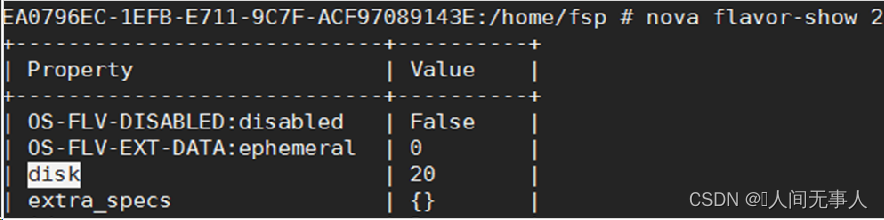
- 执行如下命令查看虚拟机规格
nova flavor-show flavor_id
Nova过滤器HuaweiDiskFilter过滤失败 (2)
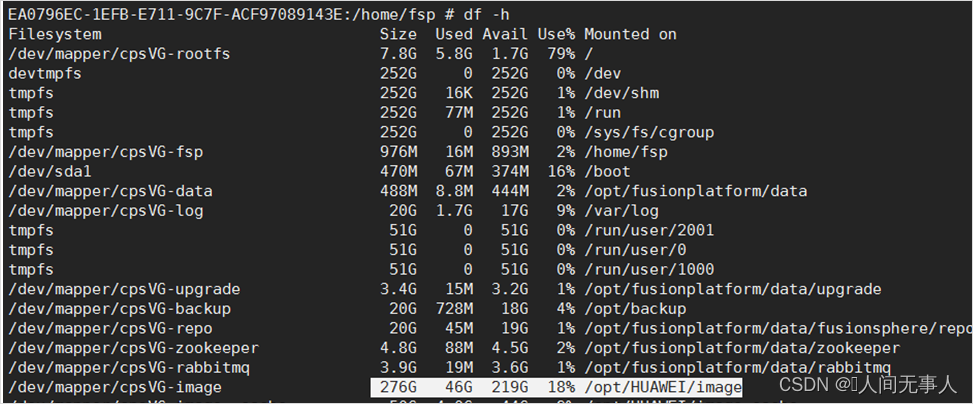
- 执行如下命令查询计算节点image空间大小
df -h
查看nova-scheduler失败日志收集故障信息
- 执行如下命令查看错误信息
zgrep (req-id) /var/log/fusionsphere/component/nova-scheduler/* | grep disk_filter req-id获取参考标题如何获取req-id”- 根据故障收集的信息分析为:虚拟机要求512000M空间,但该主机上image分区只有96256M空间

解决方案 - 扩容image空间
- 登录cps-web界面,配置>磁盘,选择相应分组或对该主机进行新建分组,修改image逻辑磁盘大小
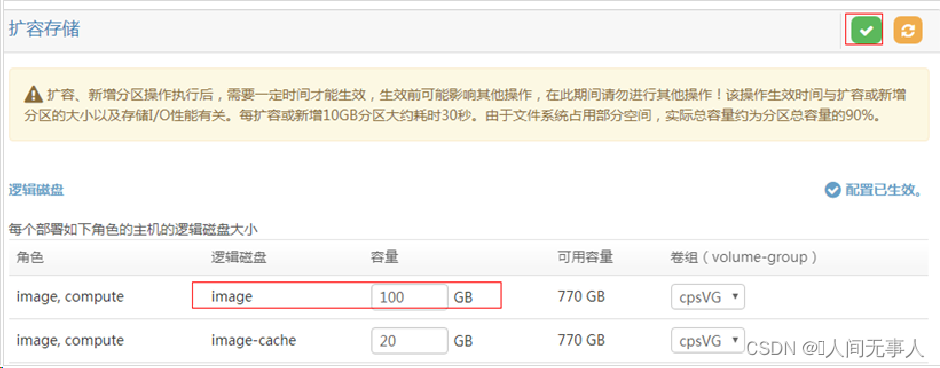
- 磁盘空间分区只能增,不能减。
常见华为云Stack故障处理(存储域故障场景、网络域故障场景)、华为云的OpenStack故障排查常用命令、缩略语
见下面博客
文章来源:https://blog.csdn.net/cuichongxin/article/details/135113526
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Python 零基础入门】 函数
- 新手为什么跟着大型机构交易?fpmarkets总结理由
- 淘宝API:连接消费者与商家的桥梁
- 一文搞懂 Python 文件读写操作
- JavaScript 中的双等号(==)和三等号(===)有何不同?何时使用它们?
- Spark一:Spark介绍、技术栈与运行模式
- 系统和应用的分布式实时性能和健康监控,对系统中实时发生的所有事情的全面检测,开箱即用、零配置、零依赖,高度互动的 Web 仪表板中查看结果
- 【C++PCL】点云处理最小二成三维球拟合
- 大神,你知道精密空调系统怎么监控吗?
- 如何打开wps的备份中心查找备份文件