基于K-Means聚类算法与随机森林模型评估信贷风险客户【500010101】
项目背景
本数据集来自一家德国银行,由加州大学霍夫曼教授于 2016 年收集整理,每条记录代表了一个接受银行信贷的客户,这也就说明了,这些客户都是通过了贷款申请的,通过可视化分析对数据进行初步探索,并利用聚类分析将客户分为不同的风险群体,由于数据集中缺乏直接的客户贷款风险标签,我们无法直接评估风险分类的准确性,因此,再次采用聚类分析(不考虑客户贷款风险特征),将数据分为四个类别,分类结果与实际相符,可以构建随机森林模型来识别风险分类的关键因素,虽然无法准确评估模型的精度,但该模型仍可作为初步风险评估的有效工具,从而提高风险识别的效率。
数据说明
| 字段 | 说明 |
|---|---|
| Age | 年龄 |
| Sex | 性别,male(男性),female(女性) |
| Job | 职业,0 - 无技能且非常驻,1 - 无技能且常驻,2 - 有技能,3 - 高技能 |
| Housing | 住房类型:own(自有房产),rent(租房),free(免租赁) |
| Saving accounts | 客户的储蓄账户状况 - little(少量),moderate(适中),quite rich(相对富裕),rich(富裕) |
| Checking account | 支票账户,little(少量),moderate(适中),rich(富裕) |
| Credit amount | 贷款金额,(单位:德国马克) |
| Duration | 贷款期限,(单位:月) |
| Purpose | 贷款用途,car(汽车),furniture/equipment(家具/设备),radio/TV(收音机/电视),domestic appliances(家用电器),repairs(修理),education(教育),business(商业),vacation/others(假期/其他)。 |
数据处理
Python库导入
# 导入需要的库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.model_selection import train_test_split
from sklearn.utils import resample
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report,confusion_matrix
数据导入
data = pd.read_csv(r"./data/german_credit_data.csv")
数据预览
# 查看数据维度
data.shape
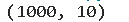
# 查看数据信息
data.info()

# 查看各列缺失值
data.isna().sum()
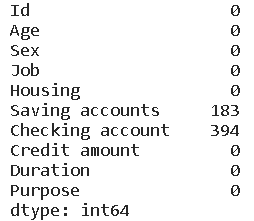
# 查看重复值
data.duplicated().sum()
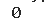
数据处理
# 处理Saving accounts和Checking account中缺失值。
# 考虑到缺失值占比比较大,不建议直接删除,同样的,也不建议用众数填充,这样可能会改变数据情况,这里先用unknown填充。
data['Saving accounts'].fillna('unknown', inplace=True)
data['Checking account'].fillna('unknown', inplace=True)
data.isna().sum()
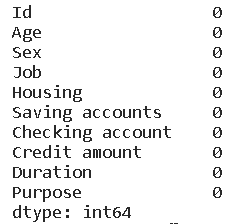
# 查看分类特征的唯一值
characteristic = ['Sex','Job','Housing','Saving accounts','Checking account','Purpose']
for i in characteristic:
print(f'{i}:')
print(data[i].unique())
print('-'*50)

#数据集重命名
data.columns=['Id','年龄','性别','职业','住房类型','客户的储蓄账户状况','支票账户','贷款金额','贷款期限','贷款用途']
data.info()

数据分析
客户基本情况分析
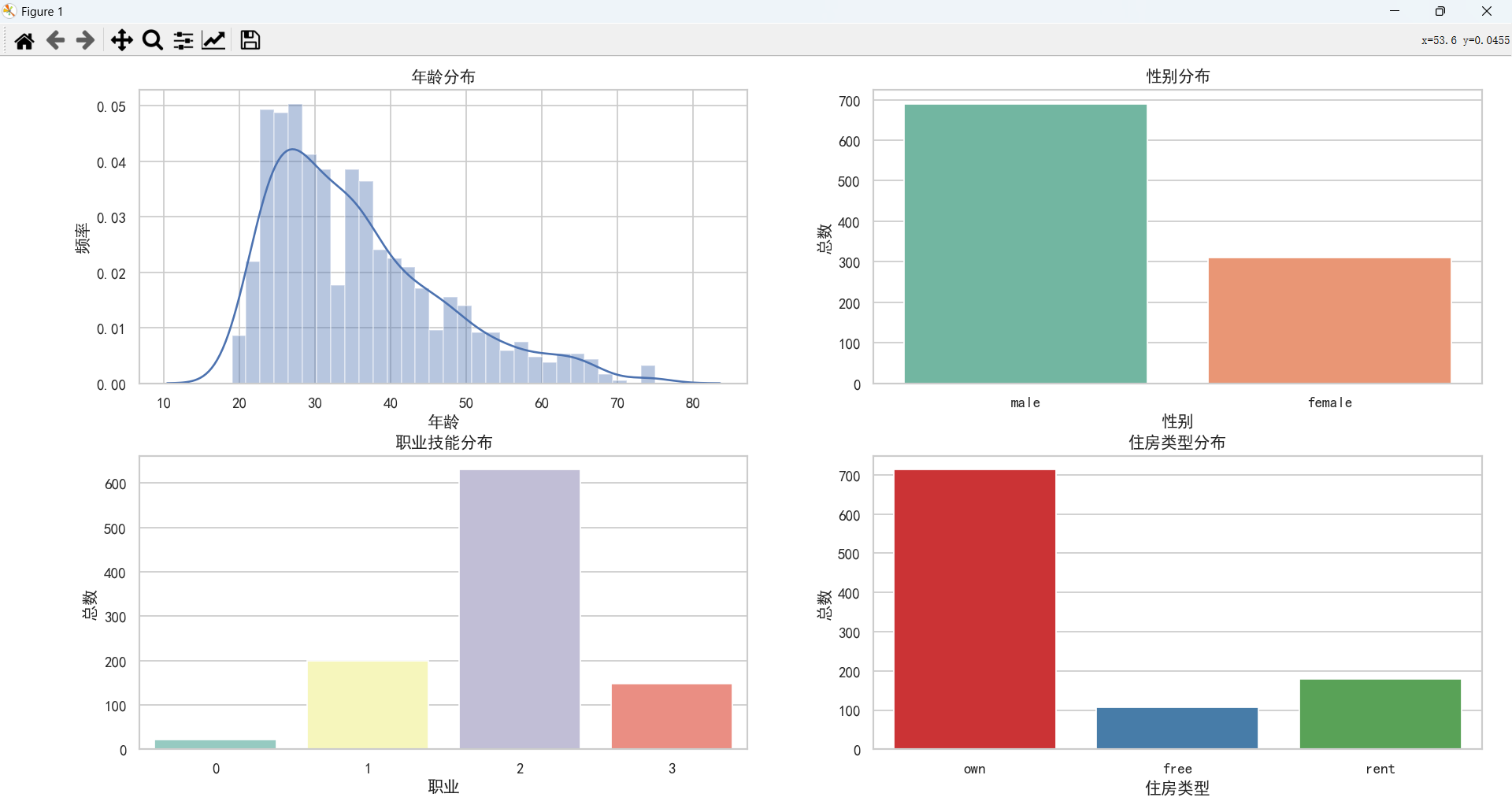
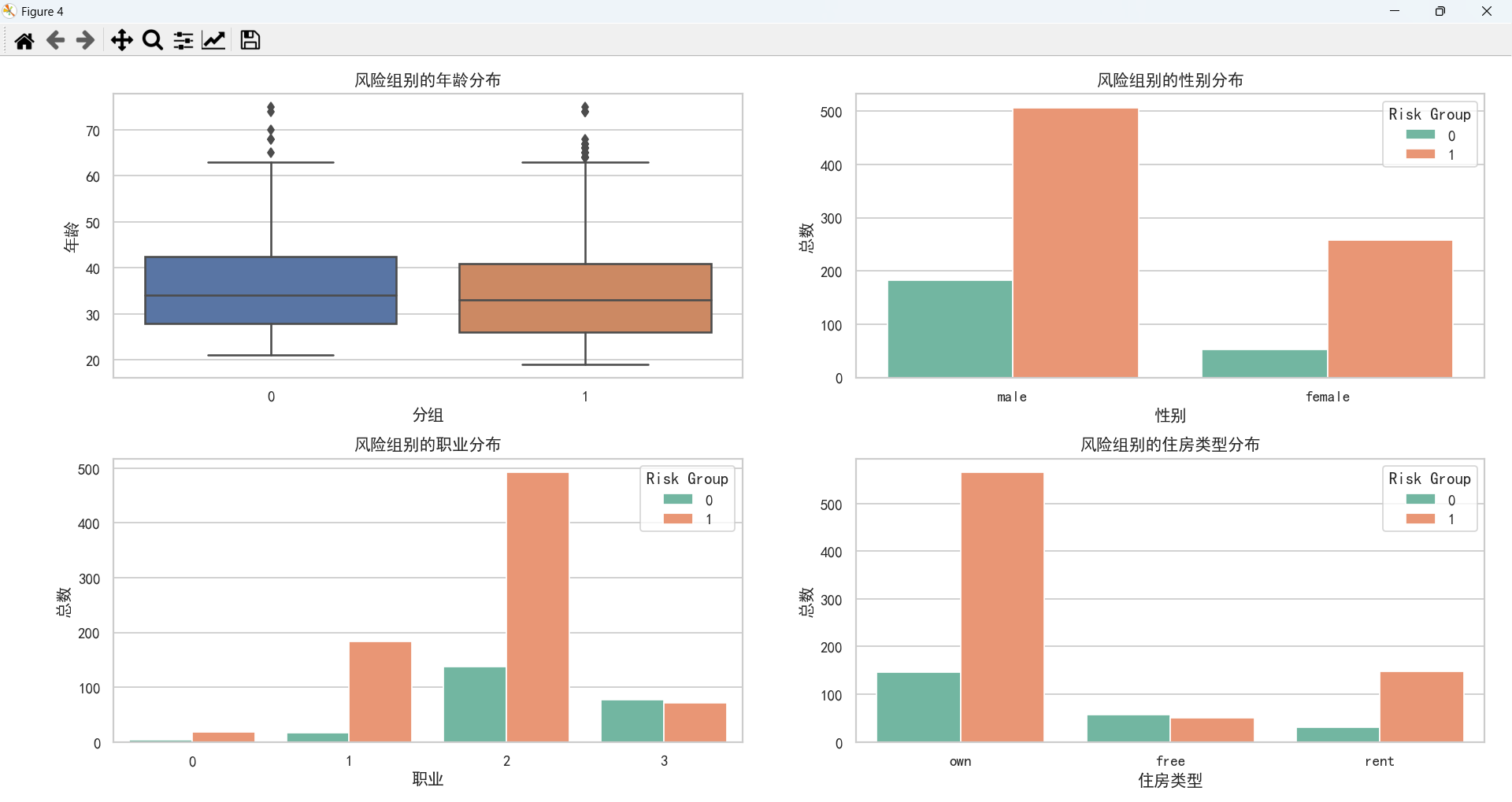
通过上图可以得到如下结论:
- 客户年龄主要集中在较年轻的年龄段,可能表明年轻人更倾向于申请贷款。
- 男性客户数量高于女性客户数量。
- 工作位于2级的客户数量最多,0级的客户数量最少,可能是因为0级无技能且非常驻,银行不予贷款。
- 自有房产客户数量>租房客户数量>免租赁客户数量,这里免租赁客户指的是那些居住在无需支付租金的住所的人,比如住在政府提供的免费住宿或者亲戚朋友家里。
客户经济情况分析
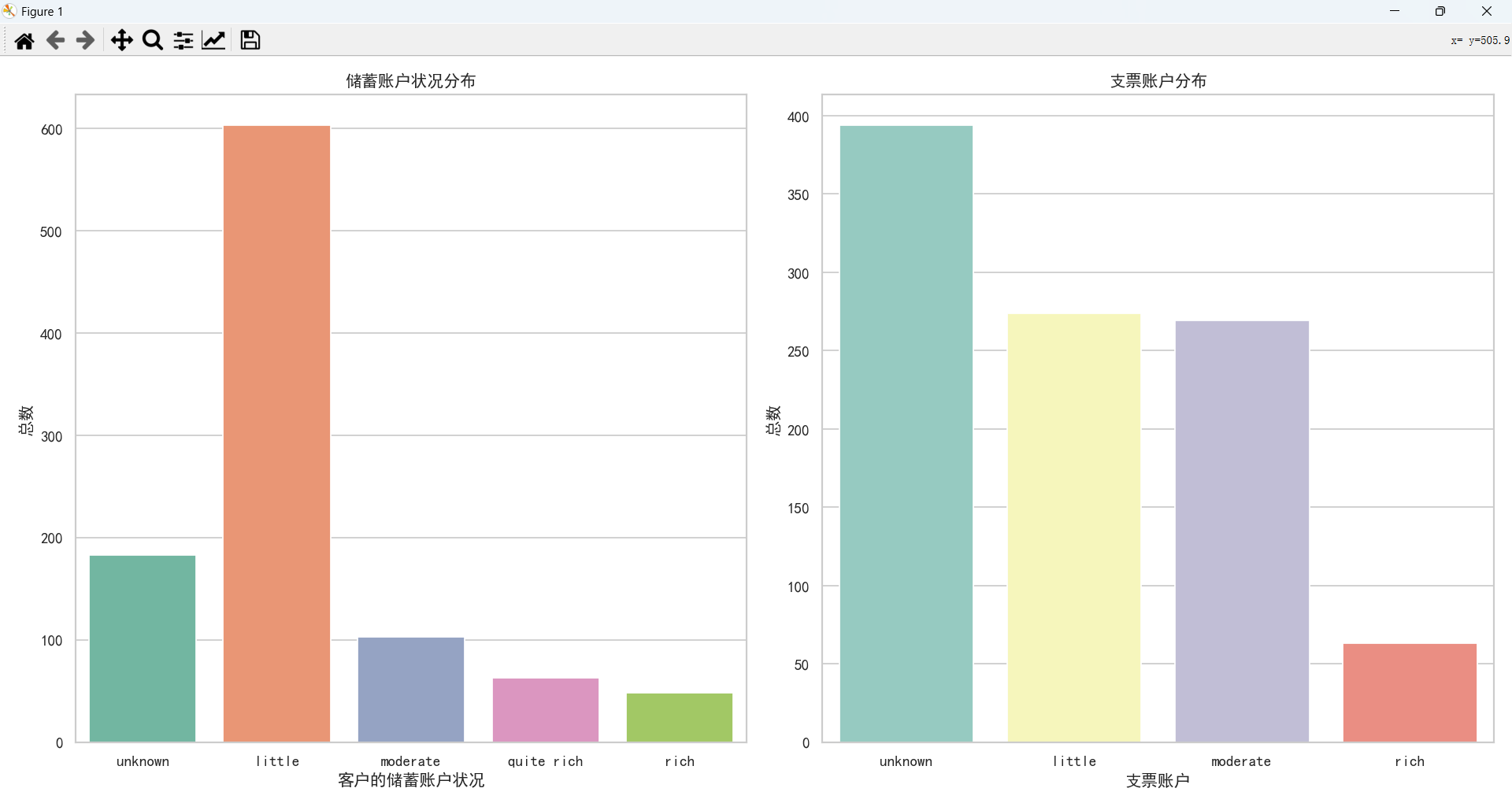
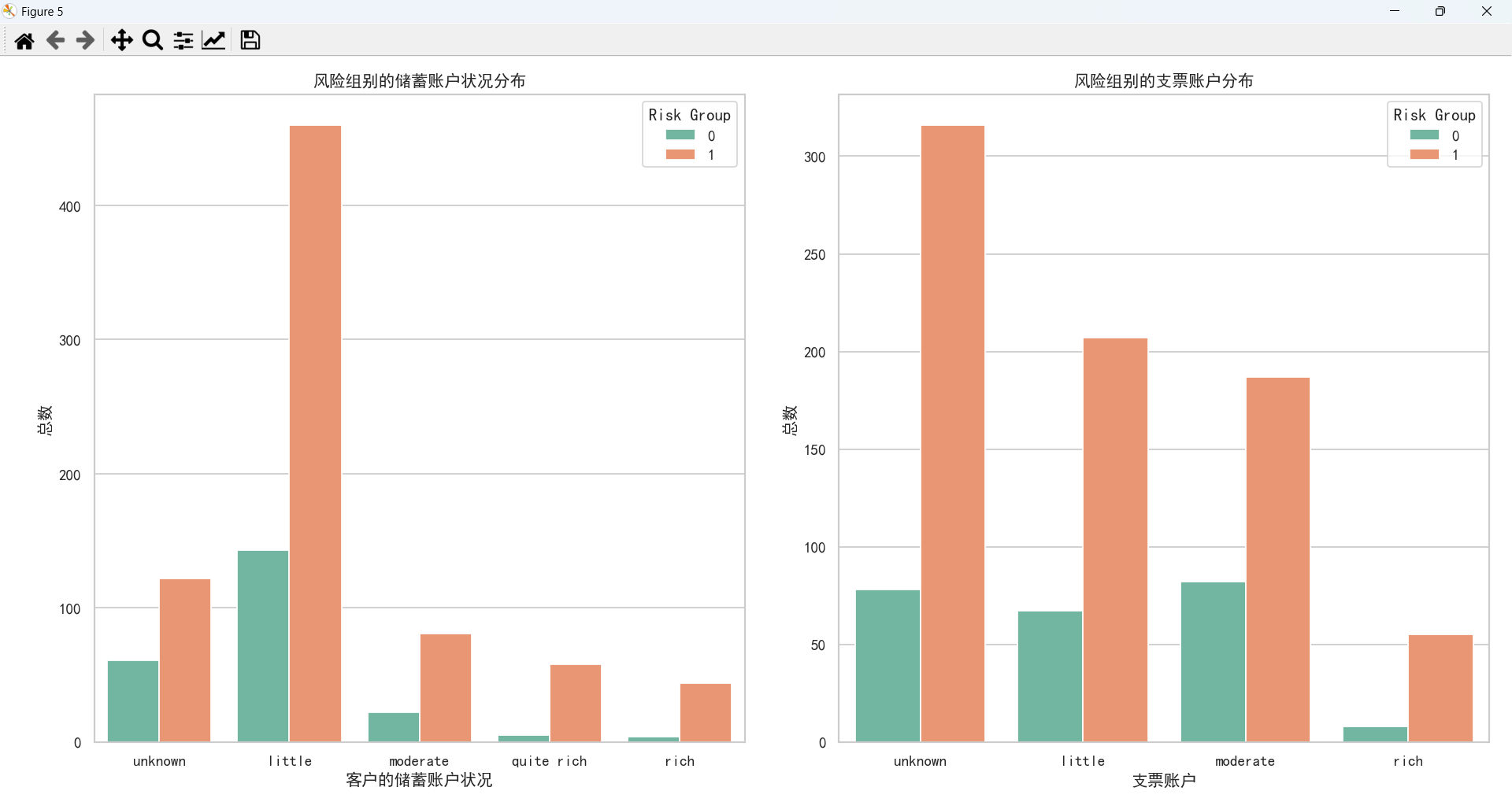
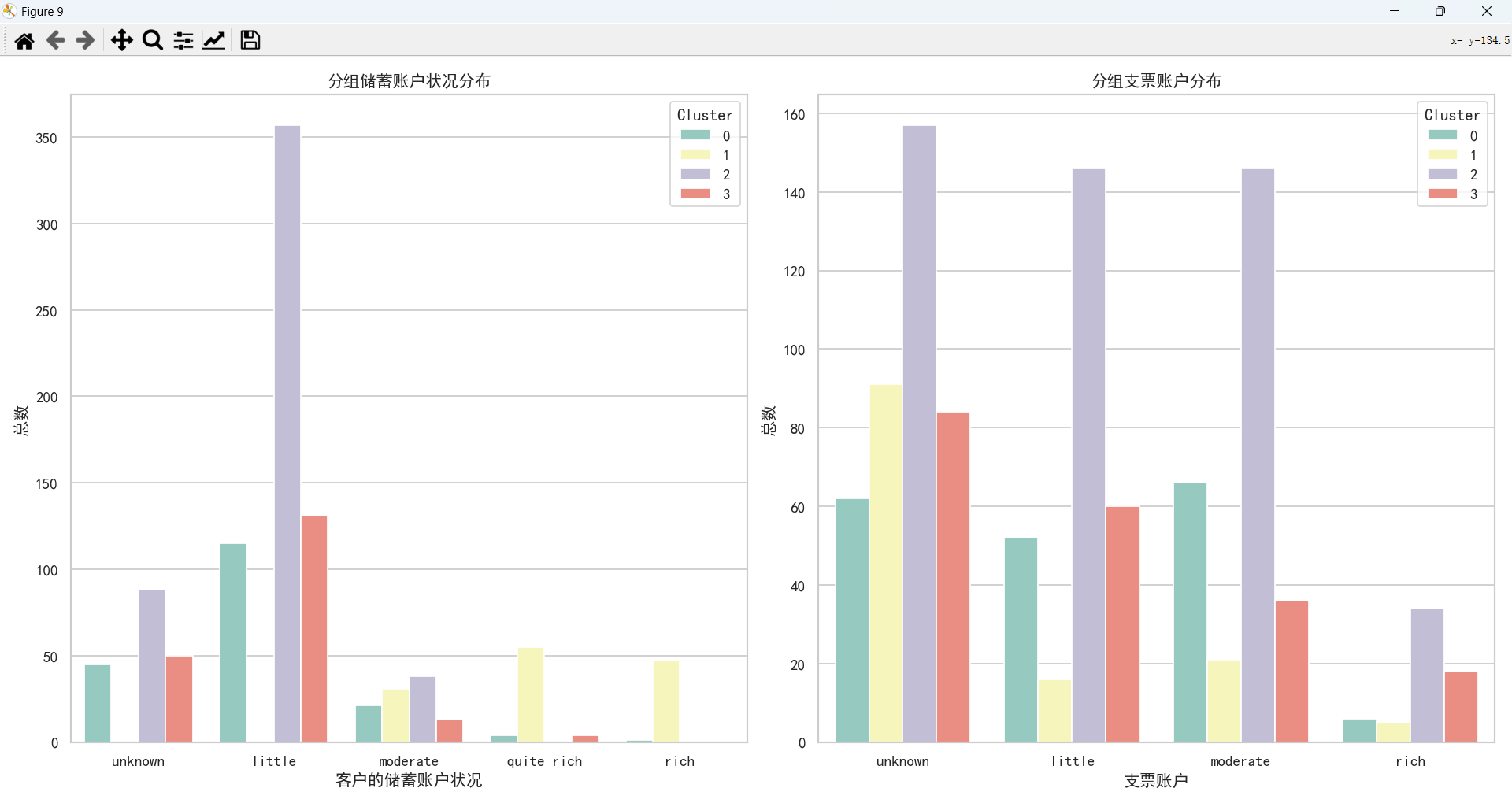
通过上图,可以得知:
- 越有钱的客户越不容易选择贷款。
- 储蓄账户状况为少量的客户,贷款人数最多。
- 支票账户状况为未知、少量、中等贷款人数比较多,尤其是位置的客户是最多的,表明放款的时候,支票账户可能不是一个主要的考虑因素,才会导致未知数据占多数。
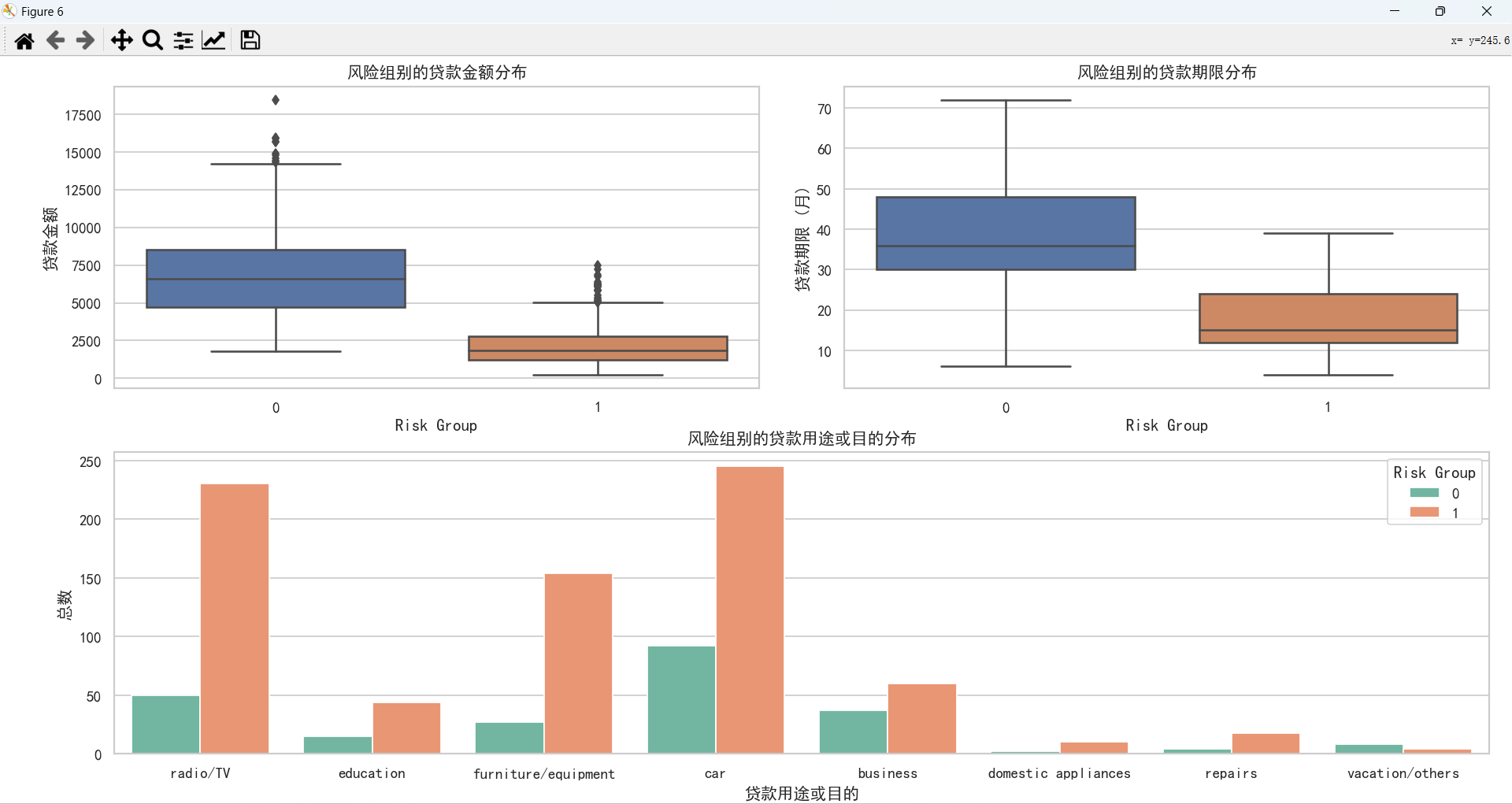
客户贷款情况分析
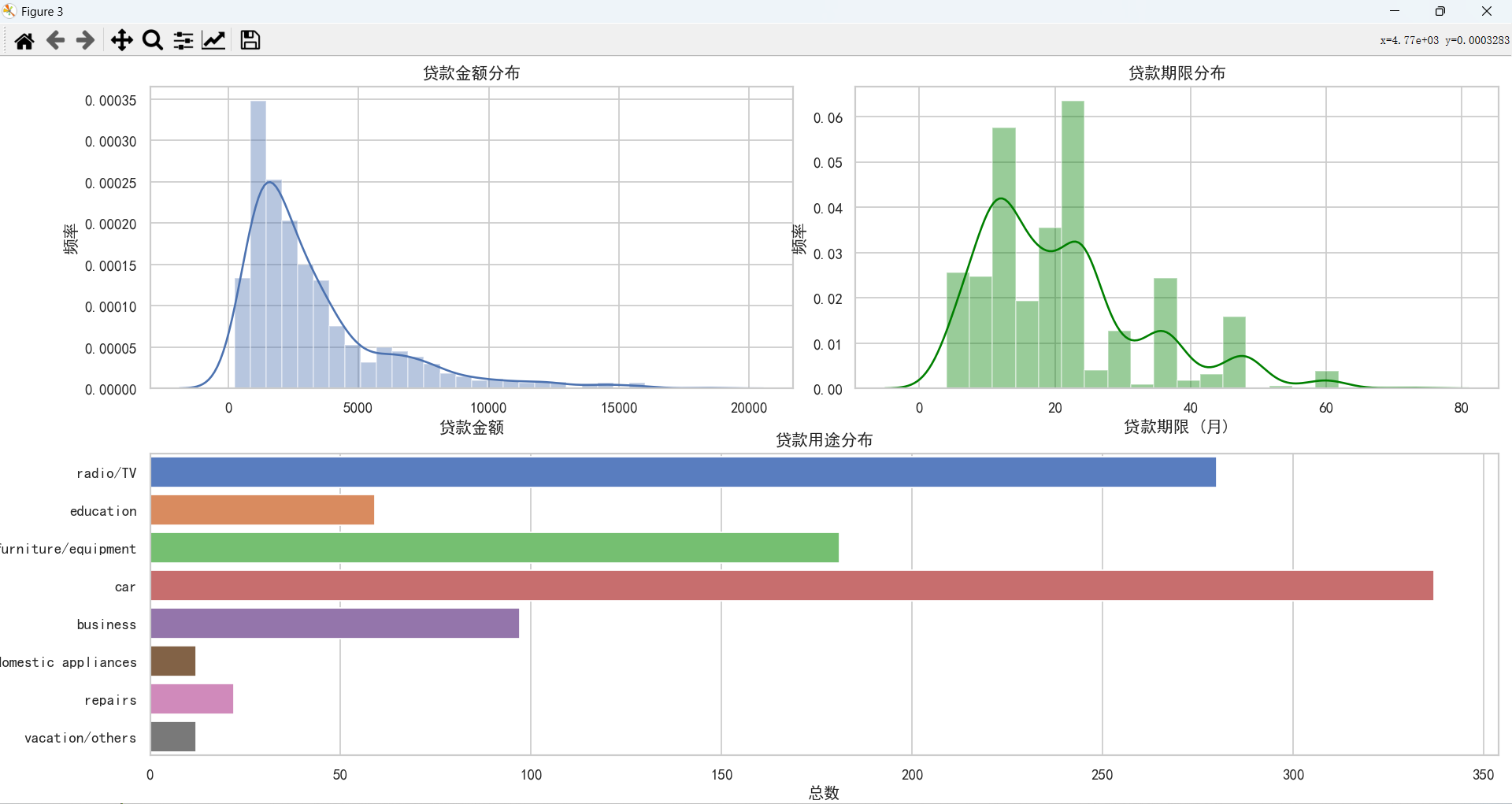
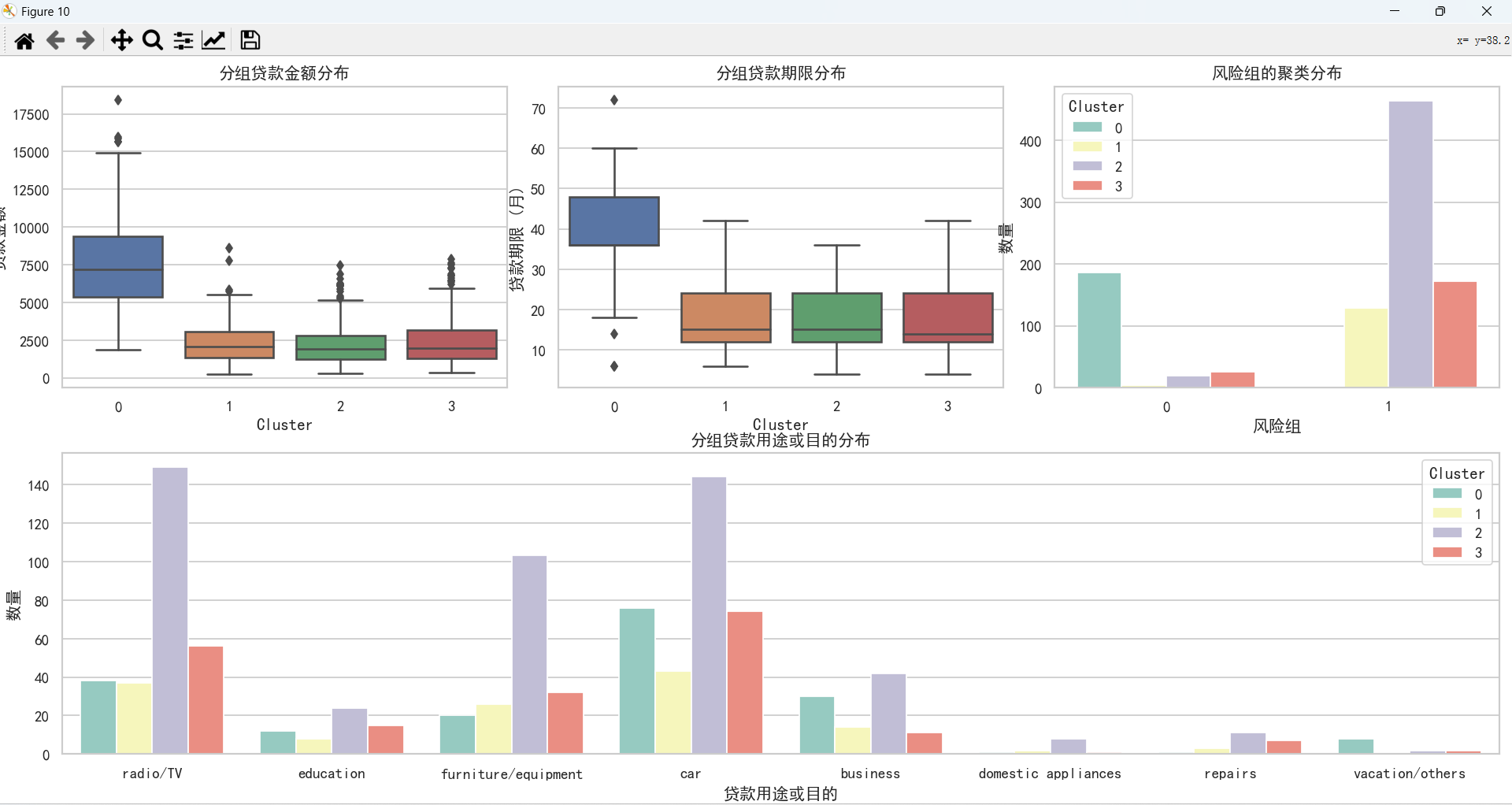
通过上图,可以得知:
- 客户贷款主要倾向于申请中低额度的贷款,贷款期限也主要选择中短期。
- 客户贷款用途主要用于购买车、收音机/电视、家具/设备。
客户贷款风险评估分析
数据预处理
# 因为需要进行聚类,所以需要对数据进行初步处理,这里对数值型数据,进行标准化,对分类变量处理为有序变量。
# 选择特征
features = ['年龄', '性别', '职业', '住房类型', '客户的储蓄账户状况', '支票账户', '贷款金额', '贷款期限']
new_data = data[features].copy()
# 对类别型特征进行有序编码
new_data['性别'] = new_data['性别'].map({
'female': 0,
'male': 1})
new_data['住房类型'] = new_data['住房类型'].map({
'free': 0,
'rent': 1,
'own': 2})
new_data['客户的储蓄账户状况'] = new_data['客户的储蓄账户状况'].map({
'unknown': 0,
'little': 1,
'moderate': 2,
'quite rich': 3,
'rich': 4})
new_data['支票账户'] = new_data['支票账户'].map({
'unknown': 0,
'little': 1,
'moderate': 2,
'rich': 3})
# 标准化数值型特征
scaler = StandardScaler()
num_features = ['年龄', '贷款金额', '贷款期限']
new_data[num_features] = scaler.fit_transform(new_data[num_features])
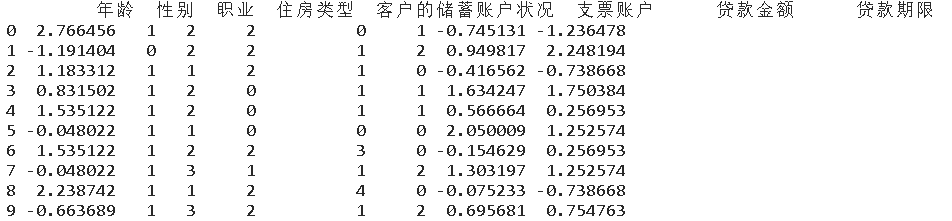
new_data.head(10)
划分高风险客户和低风险客户
# 模型选择:使用KMeans进行聚类
kmeans = KMeans(n_clusters=2, random_state=15)
clusters = kmeans.fit_predict(new_data)
# 将聚类结果添加到数据中
data['Risk Group'] = clusters
data.head(10)

两类客户之间对比
通过三类不同情况的分析,可以初步判断,0为高风险人群,1为低风险人群,原因如下:
- 类型1不仅借款金额远小于类型0,并且借款周期也远小于类型0,表明类型0的客户还款负担更重。
- 类型0虽然资金更加充足(储蓄账户状况、支票账户状况),但是通过贷款用途可以看到,主要用于商业和购买车子(占比更大),可以初步判断类型1中,有一些商人,从职业等级也能看出来,大部分在2和3,这一类人群,虽然有钱,但是开销也大,因此风险比类型1高。
- 因此,可以认为类型1属于低风险用户,类型0属于高风险用户,因为没有违约数据,这里只能通过聚类来简单划分一下。
基本情况对比
经济情况对比
贷款情况对比
用户画像分析
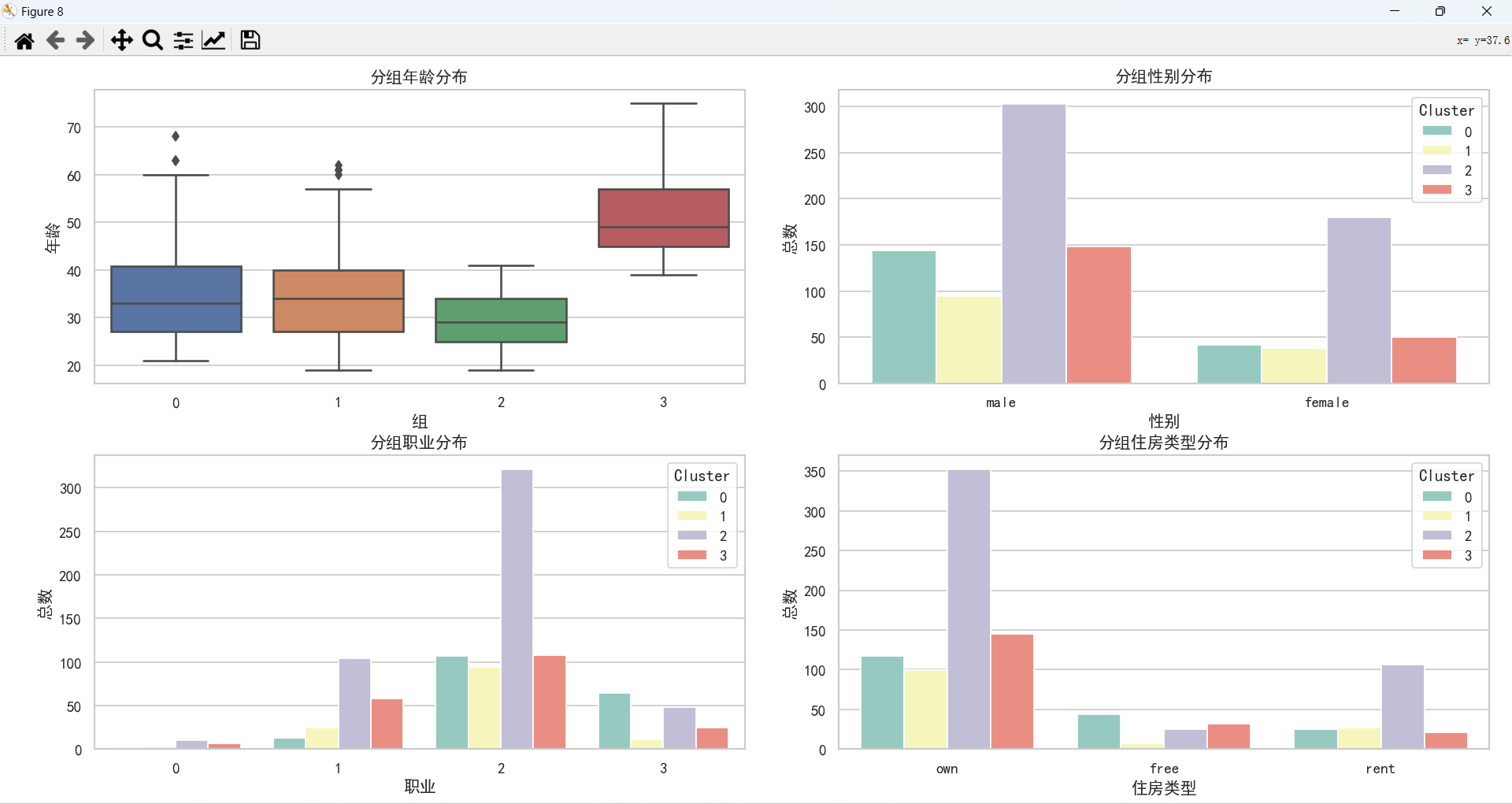
- 类型0(中高等额度需求,倾向于中长期贷款的高职业人群):
**用户画像:**年龄主要在20-40岁之间,职业主要在2-3级,这一类人是住免租赁或者租房的占比远高于其他三类,储蓄账户状况主要集中在未知和少量,支票账户也是如此,主要集中在未知、少量和适中,贷款金额和贷款周期远超其他三类,贷款主要用于购车,根据风险评估,这类客户全部为高风险。
**建议:**银行和金融机构可以为这个群体提供中期汽车贷款产品,并且可以通过金融教育来提升他们的储蓄和投资能力。
- 类别1(较高储蓄能力,倾向于短期贷款的人群):
用户画像:年龄分布比较均匀,与类型0相近,职业主要在2级,免租赁的占比较小,储蓄账户状况远超其他三类客户,贷款金额少,周期短,贷款主要用于购买设备,根据风险评估,这类客户全部为低风险。
建议:银行和金融机构可以为这个群体提供短期信用产品,同时考虑他们较高的储蓄能力,可以推广储蓄和投资相关产品。
- 类型2(短期贷款,储蓄能力有限的年轻化人群):
用户画像:平均年龄在30岁以下,最大年龄不超过45岁,比其他三类都更年轻,职业主要集中在2级,但是其他等级都有存在,租房占比高于其他三类,蓄账户状况主要集中在未知和少量,支票账户主要集中在未知、少量和适中,这类客户的资金情况与类型0类似,贷款情况与类型1类似,风险评估绝大多数为低风险。
建议:鉴于他们是信用初建者和年轻消费者,银行和金融机构可以提供小额信用卡产品和财务规划服务。
- 类型3(短期贷款的高龄客户):
用户画像:大龄客户,职业集中在1-2级,大部分有自己的房子,少部分是免租赁,蓄账户状况主要集中在未知和少量,支票账户每个等级均有占比,贷款情况与类型1和类型2类似,也是贷款金额少,周期短,同样的风险评估大多数是低风险。
建议:针对这类客户,银行和金融机构可以提供针对成熟消费者的产品和服务,如退休规划和健康保险,同时关注其稳定的信贷需求。
确定聚类数
# 使用肘部法则来确定最佳聚类数
inertia = []
silhouette_scores = []
k_range = range(2, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=10).fit(new_data)
inertia.append(kmeans.inertia_)
silhouette_scores.append(silhouette_score(new_data, kmeans.labels_))
这里并没有将风险评估的情况放到聚类数据中,这样可以通过原始数据更好的确定聚类数与聚类情况,并且可以根据聚类结果判断风险评估是否准确。

通过上图,可以得知:
- 左图为肘部法则图,通过此图可以看到,在4和5的时候,曲线下降速率明显下降。
- 右图为轮廓系数图,在2时,轮廓系数最高,在4时也不错。
- 结合两个图,我们选择4作为聚类数,此时肘部法则图下降速率有明显下降,且是轮廓系数图中第二高的点。
建立k均值聚类模型
# 执行K-均值聚类,选择4个聚类
kmeans_final = KMeans(n_clusters=4, random_state=15)
kmeans_final.fit(new_data)
# 获取聚类标签
cluster_labels = kmeans_final.labels_
# 将聚类标签添加到原始数据中以进行分析
data['Cluster'] = cluster_labels
四类客户之间对比
经济情况对比
贷款情况对比
随机森林模型
通过构建用户画像后,可以认为客户贷款风险评估得到的结果是比较正确的,因此可以建立随机森林模型来预测客户是否存在高风险,以及探究哪个特征是划分风险的重要因素。
数据处理
x = new_data
y = data['Risk Group']
#采用分层抽样来保证训练集和测试集中目标值与整体数据集的分布相似
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=10, stratify=y) #37分
#分离少数类和多数类
x_minority = x_train[y_train == 0]
y_minority = y_train[y_train == 0]
x_majority = x_train[y_train == 1]
y_majority = y_train[y_train == 1]
x_minority_resampled = resample(x_minority, replace=True, n_samples=len(x_majority), random_state=15)
y_minority_resampled = resample(y_minority, replace=True, n_samples=len(y_majority), random_state=15)
new_x_train = pd.concat([x_majority, x_minority_resampled])
new_y_train = pd.concat([y_majority, y_minority_resampled])
is_in_train = x_train.apply(lambda row: row.isin(new_x_train).all(), axis=1)
duplicates_in_test = x_train[is_in_train]
print(f"测试集中包含训练集的行数: {duplicates_in_test.shape[0]}")

建立模型
rf_clf = RandomForestClassifier(random_state=15)
rf_clf.fit(new_x_train, new_y_train)
模型评估
y_pred_rf = rf_clf.predict(x_test)
class_report_rf = classification_report(y_test, y_pred_rf)
print(class_report_rf)
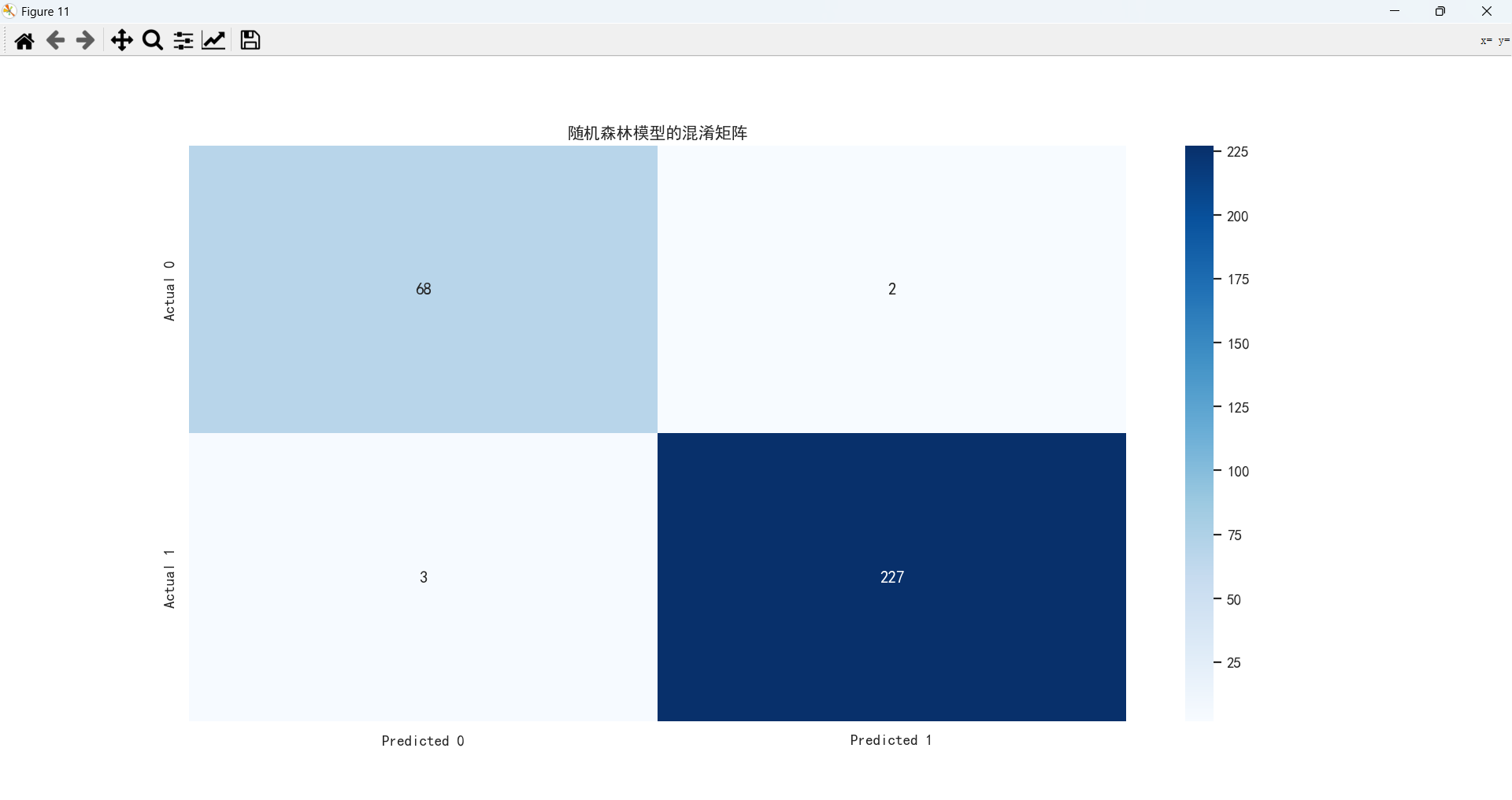
随机森林模型的混淆矩阵
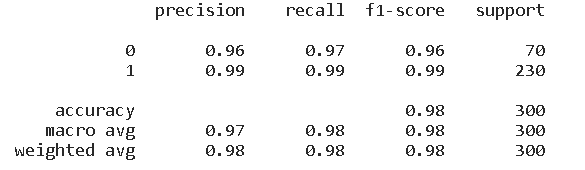
模型评分如下:
- 精确度: 对于类别0,精确度为0.92,对于类别1,精确度为0.99。
- 召回率: 对于类别0,召回率为0.97,对于类别1,召回率为0.97。
- F1得分: 对于类别0,F1得分为0.94,对于类别1,F1得分为0.98。
- 准确率: 0.97。
这是相当高的评价,可惜的就是数据中并没有包含客户贷款风险性这个特征,这个特征是通过聚类划分出来的,可能与实际有偏差,我们进一步探究哪个因素是划分的重要依据。
模型重要特征度
#模型重要特征度
rf_feature_importance = rf_clf.feature_importances_
feature_names = new_x_train.columns
rf_feature_df = pd.DataFrame({
'Feature': feature_names,
'Importance': rf_feature_importance
})
sorted_rf_feature_df = rf_feature_df.sort_values(by='Importance', ascending=False).head() #筛选出前五的重要特征

可以看出来,聚类划分高风险和低风险主要取决于贷款金额和贷款期限。
结论
本项目通过可视化分析对数据进行初步探索,并利用聚类分析将客户分为不同的风险群体,由于数据集中缺乏直接的客户贷款风险标签,我们无法直接评估风险分类的准确性,因此,再次采用聚类分析(不考虑客户贷款风险特征),将数据分为四个类别,分别描述如下:
- 类0:中高等额度需求和中长期贷款倾向的高职业人群,被认为是高风险群体。
- 类1:具有较高储蓄能力和短期贷款倾向的客户,属于低风险群体。
- 类2:年轻群体,倾向于短期贷款且储蓄能力有限,为低风险群体。
- 类3:高龄客户,偏好短期贷款,也是低风险群体。
可以发现,分类结果与实际相符,可以构建随机森林模型来识别风险分类的关键因素。分析结果显示,贷款金额和贷款期限是划分风险的主要依据。虽然无法准确评估模型的精度,但该模型仍可作为初步风险评估的有效工具,从而提高风险识别的效率。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Redis 极速上手
- 基于Java的校车管理系统
- Express安装与基础使用
- 70、C++ - 仓库目录结构介绍
- 拼多多ID取商品详情API:电商行业的核心价值与实时数据获取策略
- Qt 6之四:基础概念讲解
- 推荐一个答题工具:题主小程序(附上我的几个题库HCIP/VMware)
- 【每日一题】按分隔符拆分字符串
- 第38节: Vue3 鼠标按钮修改器
- SpringIOC之support模块ContextTypeMatchClassLoader