什么是残差矢量量化?
一、说明
????????基于残差矢量量化的神经音频压缩方法正在重塑现代音频编解码器的格局。在本指南中,了解 RVQ 背后的基本思想以及它如何增强神经压缩。
????????数据压缩在当今的数字世界中发挥着关键作用,促进信息的高效存储和传输。由于当今超过 80% 的互联网流量来自音频和视频流,因此开发更高效的数据压缩可以产生相当大的影响 - 降低成本并显着改善网络的整体能源和碳足迹。
????????传统的压缩算法一直致力于减少数据序列中的冗余(无论是图像、视频还是音频),同时大幅减小文件大小,但代价是丢失一些原始信息。MP3 编码算法极大地改变了我们存储和共享音乐数据的方式,这是一个著名的例子。
????????神经压缩技术作为一种新方法正在迅速兴起,它利用神经网络来表示、压缩和重建数据,有可能实现高压缩率和几乎为零的感知信息损失。

????????当与重建的放大和超分辨率技术相结合时,神经压缩方法可以实现近乎无损的功能(来源)。
????????特别是在音频领域,基于残差矢量量化的神经音频编解码器取代了传统的手工制作的管道。最先进的人工智能模型,如 Google 的SoundStream和Meta AI 的EnCodec,已经能够熟练地在广泛的比特率范围内编码音频信号,这标志着可学习编解码器向前迈出了重要一步。
????????在这篇博文中,我们将概述神经压缩和残差矢量量化背后的主要思想。
二、神经压缩
神经压缩旨在将各种数据类型(无论是像素形式(图像)、波形(音频)还是帧序列(视频))转换为更紧凑的表示形式,例如向量。
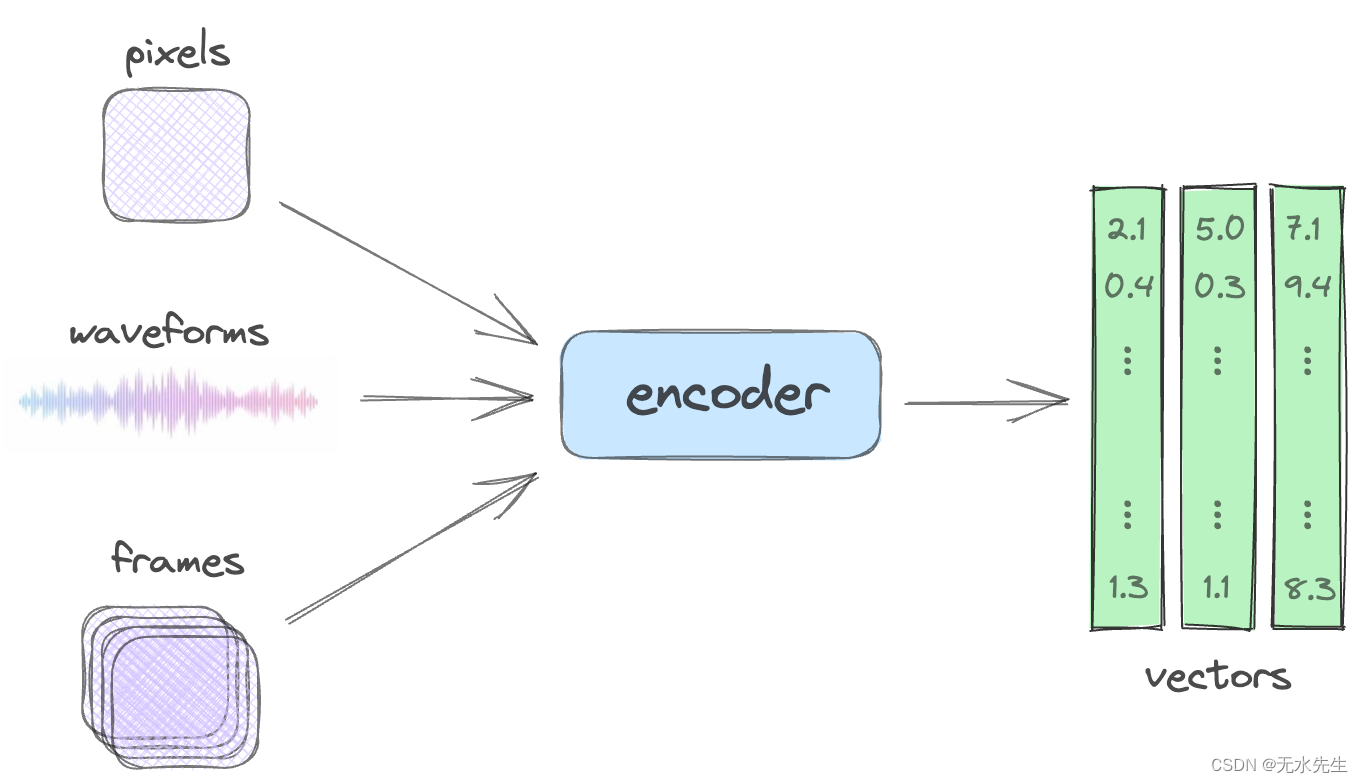
像素、波形和帧通过神经压缩映射到矢量。
????????关键是,这种转换不仅仅是简单地减小大小:它产生数据的表示,其中模式被自动识别、存储,然后用于重建。这种表示称为嵌入,广泛用于从语言模型到图像生成器的深度学习中。
????????例如,在图像压缩的背景下,神经压缩不是记录每个像素值,而是学习识别关键特征或视觉模式。与自动编码器一样,学习到的特征随后用于高精度地重建图像。类似地,波形可以转换为矢量格式并解码以重新生成声音。
????????关于神经压缩的学术讨论强调了其无损或接近无损压缩能力的潜力,即以最小的质量下降来压缩和解压缩数据的能力。事实上,当这些模型与迭代去噪和扩散相结合以进行放大或超分辨率技术时,它们可以以高度忠实于原始数据的方式重新创建数据。

使用基于扩散的恢复模型去模糊图像(来源)。
????????鉴于人类视觉和听觉系统往往比其他细节更容易注意到某些细节,这种方法更加重视和强调知觉损失。此外,该技术允许基于相同的矢量表示将内容自适应转换为不同的质量(分辨率、比特率或帧速率)。
????????在下一节中,我们将了解如何应用这些一般思想来使用神经音频编解码器压缩音频数据。最后,我们讨论了一个缺失的关键组件,残差矢量量化,以实现高压缩率。
三、神经音频编解码器和 RVQ
????????本质上,音频编解码器将录制的声音(数字音频信号)转换为给定的内容格式。目标是保持声音的原始品质,同时减小文件大小和比特率。最先进的神经音频压缩(或神经音频编解码器)采用深度神经网络来实现相同的目标。
? ? ? ? 基于自动编码器的简单方法没有帮助,因为音频信号具有非常高的信息密度并且需要正确表示高维向量。因此,需要采用量化技术来降低这些向量的维数。现在让我们概述一下量化的工作原理。
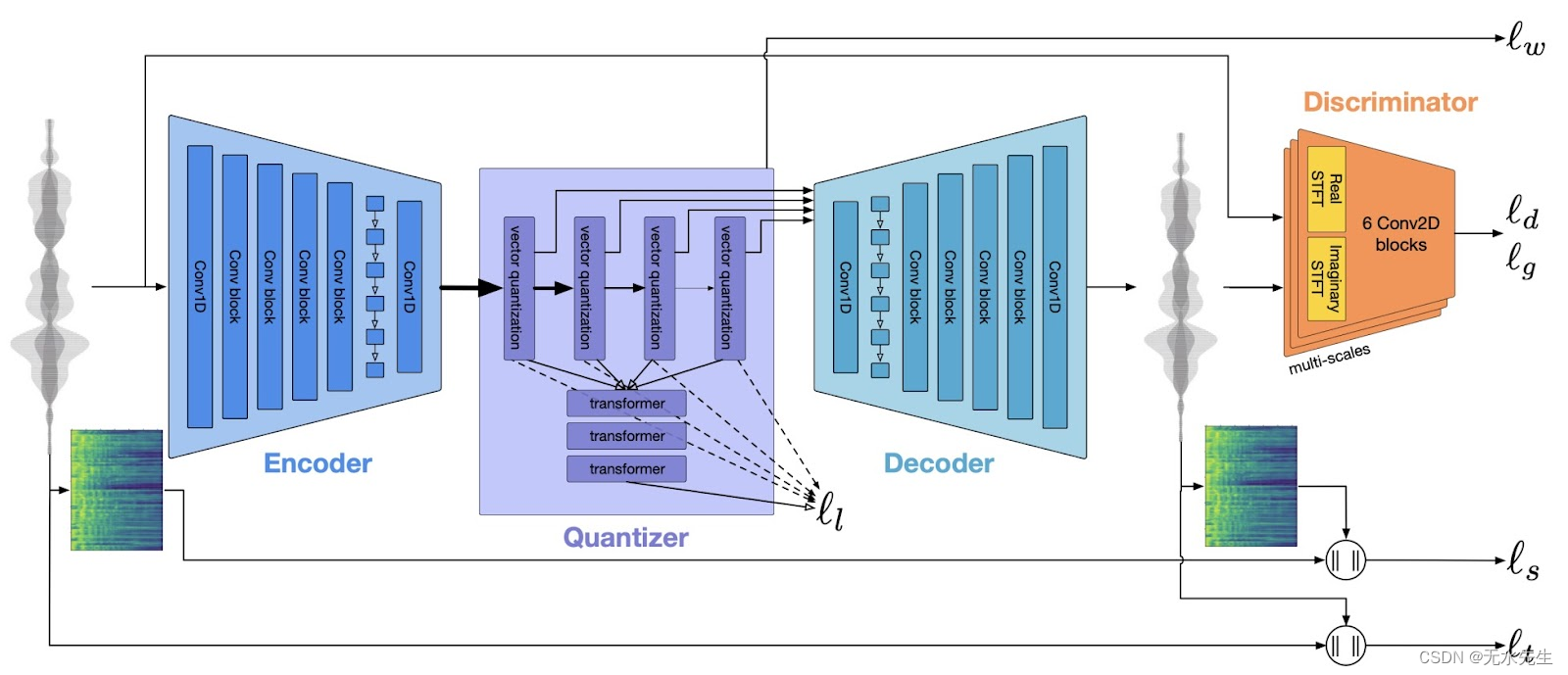
EnCodec 架构(来源)。
????????上图描绘了 EnCodec 架构,它反映了 SoundStream 的架构。其核心是一种基于端到端神经网络的方法。它由编码器、量化器和解码器组成,全部同时训练。
????????以下是管道运行方式的分步概述:
- 编码器将每个固定长度的样本(仅几毫秒的音频波形)转换为预先确定的固定维度的向量。
- 然后,量化器通过称为残差矢量量化的过程来压缩该编码矢量,该过程源自数字信号处理。
- 最后,解码器获取该压缩信号并将其重建为音频流。然后使用鉴别器组件将此重建的音频与原始音频进行比较。鉴别器测量两者之间的数值差异,称为鉴别器/生成器损失。
- 除了鉴别器损失之外,该模型还计算其他类型的损失。这些损失包括将重建的波形和梅尔谱图与原始波形和梅尔谱图进行比较,并评估承诺损失以稳定编码器的输出。最终目标是确保音频输出密切反映初始输入。
????????数据压缩的关键发生在量化器级别。下图说明了这个想法:
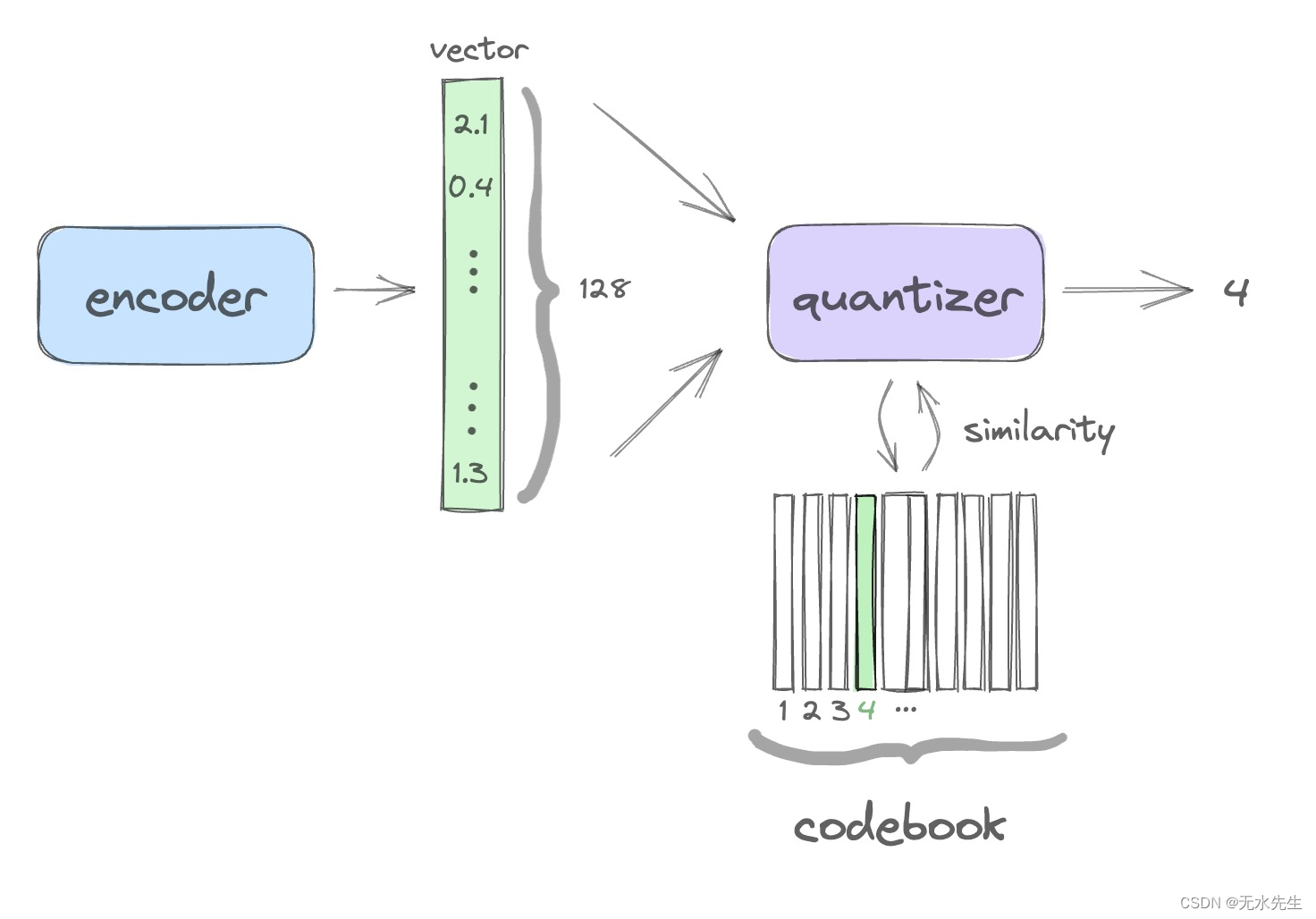
????????该图概述了单个量化步骤的逻辑,该步骤将 128 维向量减少为单个数字(码本中的索引),从而压缩信息。
????????考虑编码器将音频样本转换为 128 维向量。
- 第一量化器层具有包含固定数量的相同维度的可学习向量的码本表。
- 将输入向量与码本中的向量进行比较,并提取最相似向量的索引。
- 这是压缩阶段:我们刚刚用一个数字(密码本中的相应索引)替换了 128 个数字的向量。
????????实际上,单个量化器层需要非常大(实际上是指数级大)的码本来准确表示压缩数据。
????????残差矢量量化 (RVQ)提供了一个优雅的解决方案。RVQ 可以通过使用级联码本为这些高维向量提供逐渐更精细的近似。
????????这个想法很简单:主码本提供输入向量的一阶量化。然后使用辅助码本进一步量化残差或数据向量与其量化表示之间的差异。
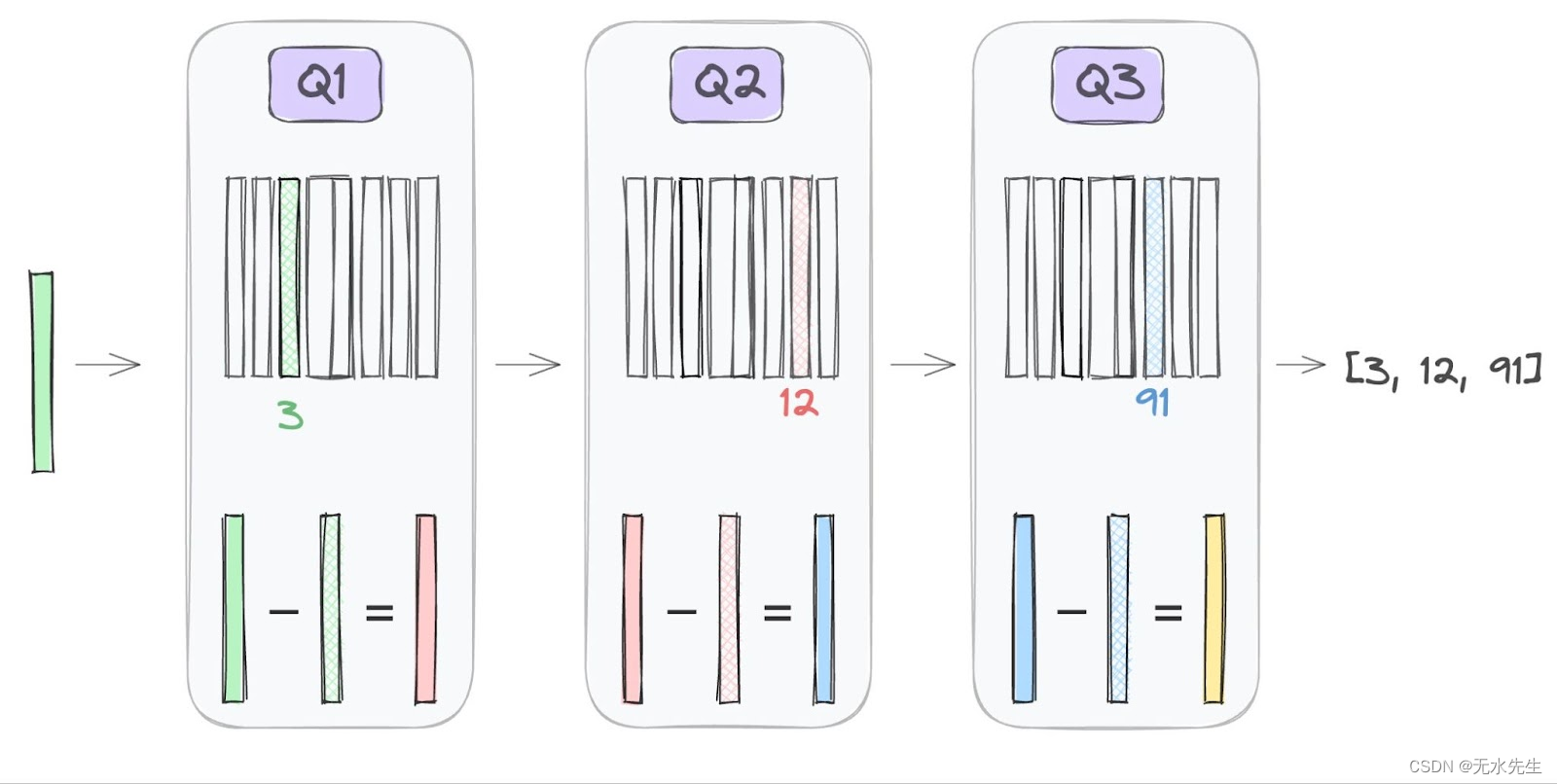
????????RVQ 将量化过程分解为多个层,每一层都处理前一层的残余误差。这允许系统缩放以在不同的比特率上运行(通过缩放层数)。?
????????这种分层方法仍在继续,每个阶段都专注于前一阶段的残差,如上图所示。因此,RVQ 不是尝试直接使用单个庞大的码本量化高维向量,而是解决了这个问题,在显着降低计算成本的情况下实现了高精度。
四、进一步阅读
????????要在 Pytorch 中试验 RVQ,您可以使用lucidrains的优秀开源VQ 存储库。
????????我们推荐R. Kumar 等人最近发表的论文《采用改进的 RVQGAN 的高保真音频压缩》 。(以及其中的文献)以了解神经音频压缩的最新进展。作者介绍了一种高保真“通用”神经音频压缩算法,可以用单个通用模型压缩所有音频域(语音、环境、音乐等),使其适用于所有音频的生成建模。提供开源代码和模型权重(以及演示页面)。
五、最后的话
????????基于残差矢量量化的神经压缩方法正在彻底改变音频(并且可能很快还会改变视频)编解码器,提供近乎无损的压缩功能,同时减少计算开销。RVQ 等量化技术对于文本转语音和文本转音乐生成器已变得至关重要。
????????更广泛地说,神经压缩的创新不仅意味着技术的进步,而且意味着迈向更高效、更可持续的数字生态系统的飞跃。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 人工智能的未来:机遇与挑战
- 定时任务 crontab (centos)+定时查看top的数据并按日期输出到指定文件
- day07 四数相加Ⅱ 赎金信 三数之和 四数之和
- ConcurrentHashMap和HashMap的区别
- 【LeetCode:530. 二叉搜索树的最小绝对差 | 二叉搜索树】
- java学习面向对象编程练习项目----电影信息系统管理
- 01.微服务架构优缺点、服务拆分和远程调用
- LeetCode刷题记录:(2)环形链表
- Go工程大坑,空切片和nil切片
- 完成实验十的ko-ngxugan