大模型增量学习 (1)
动机
1.知识继承
尽管在探索各种预训练技术和模型架构方面做出了巨大的努力,研究人员发现,简单地扩大模型容量、数据大小和训练时间可以显著提升模型性能,然而更多的模型参数也意味着更昂贵的计算资源、训练成本。现有的 PLM 通常是从零开始单独训练的,而忽略了许多已训练的可用模型。
问题:如何利用已有的 PLM 辅助训练更大的 PLM?
考虑到人类可以利用前人总结的知识来学习新任务;同样我们可以让大模型复用(继承)已有小模型中的隐式知识,从而加速大模型的训练。为减少预训练计算消耗,我们提出知识继承框架,充分利用现有小模型消耗的算力"。
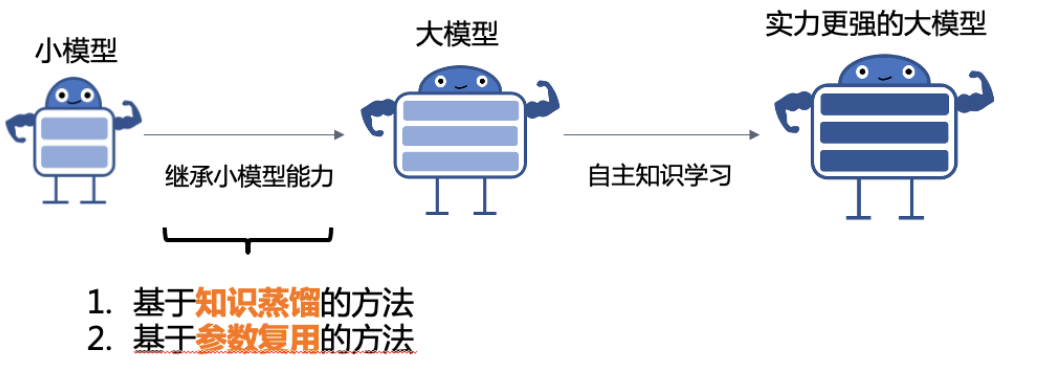
2.模型训练难度,能力增强不要出现退化;对能力分块训练,不同部分不同增量模型,底模共用
增量学习的几种方法
基于知识蒸馏
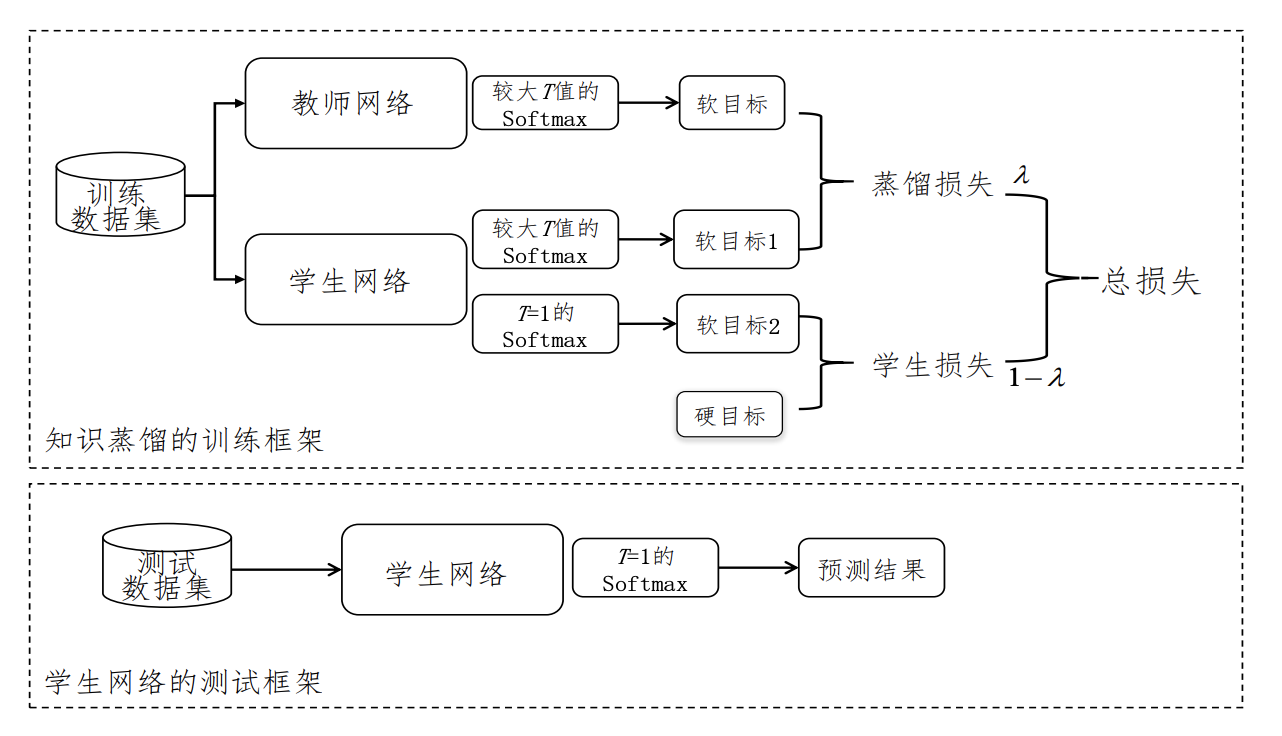
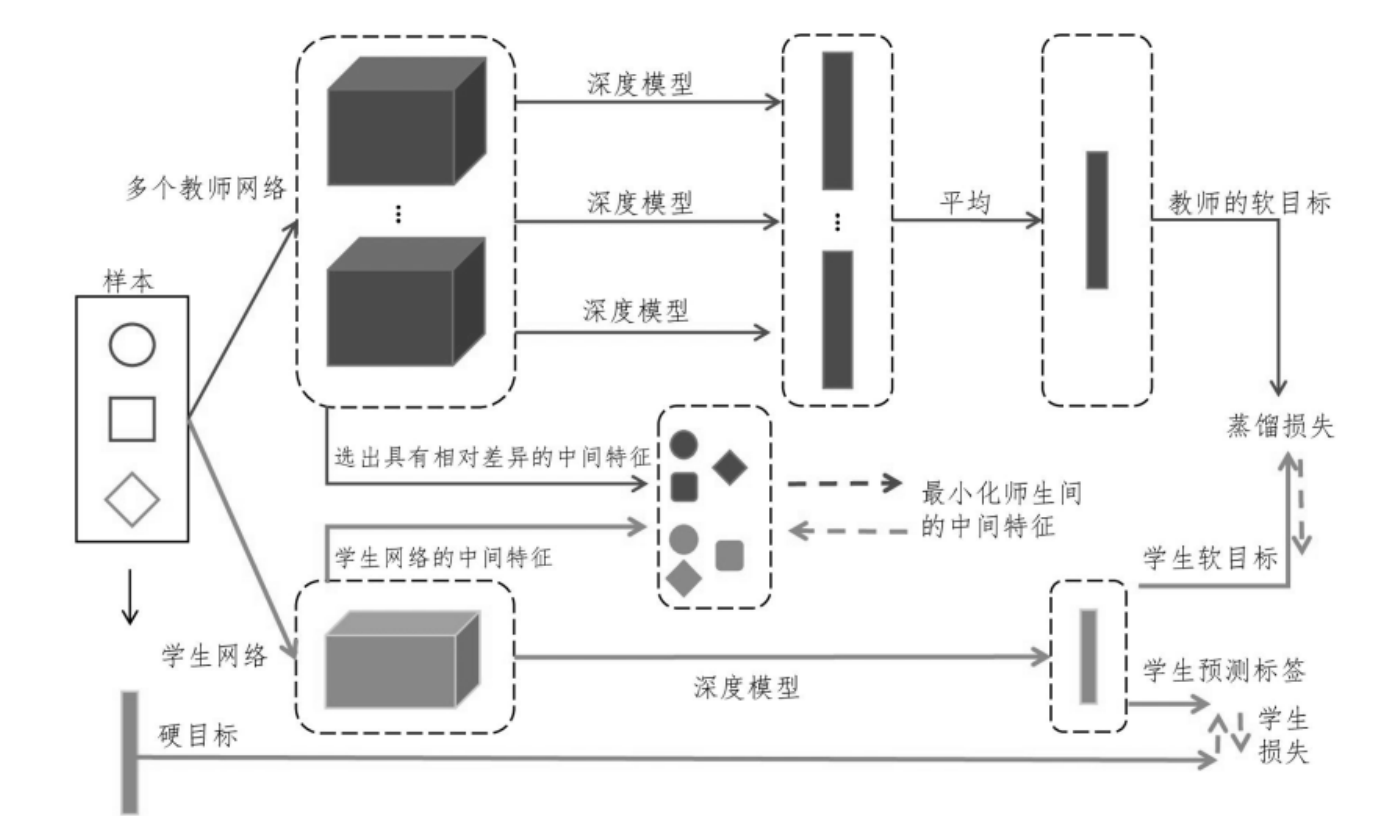
提出在大模型预训练初期,让现有小模型作为大模型的“老师”,将小模型的隐式知识“反向蒸馏”给大模型从而复用现有小模型的能力,减少大模型预训练计算消耗。
考虑到人类可以利用前辈总结的知识来学习新任务,使得学习过程可以变得高效;同样,继承现有 PLMs 中分布的隐含知识是值得的。在这个意义上,可以在预训练过程中提取一个已经存在的小 PLM 中总结的知识,以有效地学习更大的 PLMs。我们将上述过程称为知识遗传(KI)。这种直觉与计算机视觉领域的反向 KD(Yuan et al., 2020)相似。他们指出,一个精致的学生模型仍然可以从一个对特定下游任务有劣势的教师那里受益。
然而,反向 KD 在监督下游任务中的成功并不能保证其在大规模自监督预训练的场景下的可行性。要回答以下研究问题:
(RQ1)从一个已经训练过的 PLM 中提取知识是否能够有益于从头开始训练大型 PLMs?
(RQ2)考虑到人类能够从一代代传下知识,KI 是否可以在一系列不断增长的 PLMs 中顺序地执行?
(RQ3)随着越来越多的 PLMs 以不同的预训练设置(模型架构、训练数据、训练策略等)出现,不同的设置会如何影响 KI 的性能?
(RQ4)除了从头开始训练一个大型 PLM,当将一个已经训练过的大型 PLM 适应到一个新的领域时,较小的领域教师如何能够有益于这样的过程?
具体实现:
基于知识蒸馏的知识继承框架,利用小模型
M
S
M_S
MS?来训练大模型
M
L
M_L
ML?
L
(
D
L
;
M
S
)
=
∑
(
x
i
,
y
i
)
∈
D
L
(
1
?
α
)
L
S
E
L
F
(
x
i
,
y
i
)
?
自主学习
+
α
L
K
I
(
X
i
;
M
S
)
?
反向蒸馏
=
∑
(
x
i
,
y
i
)
∈
D
L
(
1
?
α
)
H
(
y
i
,
p
m
L
(
x
i
;
1
)
)
+
α
r
2
K
L
(
p
M
s
(
x
i
;
τ
)
∣
∣
p
M
L
(
x
i
;
τ
)
)
)
.
L(D_L;M_S) = \sum_{(x_i,y_i) \in D_L}\underbrace{(1-\alpha)L_{SELF}(x_i,y_i)}_{自主学习}+\underbrace{\alpha L_{KI}(X_i;M_S)}_{反向蒸馏} \\ =\sum_{(x_i,y_i) \in D_L}(1-\alpha)H(y_i,p_{m_L}(x_i;1))+\alpha r^2KL(p_{M_s}(x_i;\tau)||p_{M_L}(x_i;\tau))).
L(DL?;MS?)=∑(xi?,yi?)∈DL??自主学习
(1?α)LSELF?(xi?,yi?)??+反向蒸馏
αLKI?(Xi?;MS?)??=∑(xi?,yi?)∈DL??(1?α)H(yi?,pmL??(xi?;1))+αr2KL(pMs??(xi?;τ)∣∣pML??(xi?;τ))).
知识继承系数
α
t
\alpha_t
αt?的动态调整(当学生超越老师,停止向老师“学习”)
α
t
=
m
a
x
(
1
?
α
T
×
t
T
,
0
)
\alpha_t = max(1-\alpha_T \times \frac{t}{T},0)
αt?=max(1?αT?×Tt?,0)
框架利用先前训练过的 PLMs 来训练更大的模型。进行了充分的实证研究来证明其可行性。展示了 KI 可以很好地支持一系列 PLMs 的知识转移,这些 PLMs 的大小正在增长。分析了教师模型的各种预训练设置可能会影响 KI 的性能,结果揭示了如何选择最适合 KI 的教师 PLM。扩展了 KI,并展示了,在领域适应过程中,一个已经训练过的大型 PLM 可以从较小的领域教师那里受益。
在未来探索以下方向:(1)KI 的效率,即,给定有限的计算预算和预训练语料库,如何更有效地从教师模型中吸收知识。可能的解决方案包括去噪教师模型的预测和利用教师的更多信息。如何选择 KI 的最具代表性的数据点也是一个有趣的话题;(2)KI 在不同设置下的有效性,即,如果教师和学生在不同的词汇表、语言、预训练目标和模态上进行预训练,KI 如何应用。
参考:清华《 Knowledge Inheritance for Pre-trained Language Models》论文
其实现在大模型训练利用chatgpt来做训练数据准备也可以归属于知识蒸馏范畴。
基于参数复用
1)对于参数初始化,首先通过复制和堆叠现有较小PLM的参数,将先前的函数保持训练扩展到PLMs,称之为函数保持初始化(FPI)。FPI确保初始化的大型模型几乎与小型模型具有相同的行为,以便大型模型在后续优化中有一个良好的起点。发现,将上层的权重复制到当前层可以进一步加速大型模型的收敛,称之为高级知识初始化(AKI)。尽管AKI在某种程度上违反了函数保持的原则,在实验证明中显示的良好起点,导致更快的收敛速度并实现更高的训练效率。(2)其次,进一步采用了两阶段训练策略,以加速大型模型的训练过程。

为了证方法的优越性,对两个代表性的PLMs(BERT和GPT)进行了大量实验证明,这两个模型具有不同的源模型大小。结果表明:(1)与从头学习和渐进堆叠方法(例如StackBERT(Gong等人,2019)和MSLT(Yang等人,2020))相比,我们的方法在预训练中可以节省大量计算;(2)我们的方法是模型无关的,可以应用于广泛的基于Transformer的PLMs。一个典型的例子是,使用半大小的BERTBASE的小预训练模型进行初始化时,bert2BERT节省了原始BERTBASE预训练的45%计算成本。
总的来说:
(1)通过重用小模型的训练参数来初始化大模型,探索了一种高效预训练的新方向;
(2)成功地在BERT上扩展了保持功能的方法(Chen等人,2016),并进一步提出了高级知识初始化,可以有效地将训练过的小模型的知识传递给大模型并提高预训练效率;
(3)所提出的方法优于其他训练方法,并在BERTBASE上实现了45%的计算减少;
(4)我们的方法是通用的,对BERT和GPT模型都有效,并有望成为预训练超大规模语言模型的能源高效解决方案。
横向模型增长:
Function Preserving Initailzation(FPI),通过对小模型参数矩阵的扩展,生成适配大模型的参数矩阵。
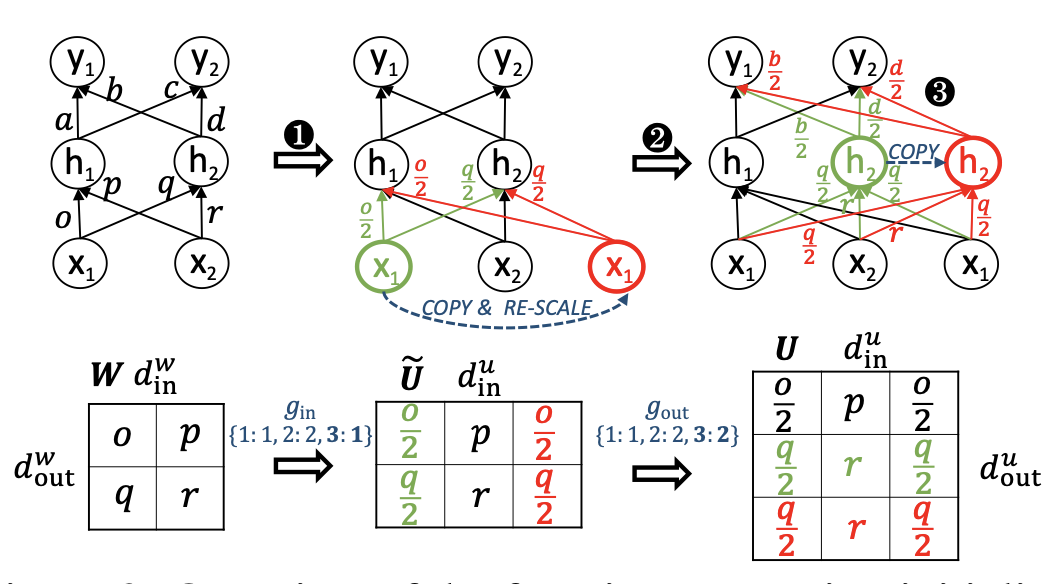
功能保持初始化(FPI)的概述。给定相同的输入{x1, x2},FPI确保初始化的目标模型具有与源模型相同的输出{y1, y2}。第一步和第二步分别是根据映射函数gin和gout扩展参数矩阵的输入维度和输出维度。在我们将矩阵W扩展为U之后,我们再次对上层参数矩阵进行输入维度扩展,以确保输出{y1, y2}与原始输出相同。从神经元的角度来看,FPI复制相应的输入和输出神经元以扩展神经网络。
Advabced Knowledge Initialization(AKI),在进行参数扩展是不仅考虑当前层的参数,还考虑更高层的参数对当前层进行扩展
为了进一步提高预训练目标模型的收敛速度,提出了高级知识初始化(AKI),它基于源模型中同一层和上一层的参数进行新矩阵的扩展。这一 intuitions 基于先前的研究发现(Jawahar等人,2019;Clark等人,2019),相邻的Transformer层具有相似的功能,这确保不会破坏当前层参数中包含的知识。此外,来自相邻层的知识可以打破FPI中出现的对称性(Chen等人,2016),这已经被证明是有益的。我们在图4中给出了一个说明性的例子,并将AKI表示为:
U
=
E
X
P
N
(
W
l
,
W
l
+
1
;
g
i
n
,
g
o
u
t
)
.
U = EXPN(W_l, W_{l+1}; g_{in}, g_{out}).
U=EXPN(Wl?,Wl+1?;gin?,gout?).
具体而言,首先对W_{l|l+1}进行输入维度扩展。这里以W_l为例:
C
g
i
n
(
i
)
=
I
(
g
i
n
(
i
)
=
g
i
n
(
i
′
)
)
∑
i
′
=
1
d
w
i
n
.
C_{g_{in(i)}} = I(g_{in(i)} = g_{in(i')}) \sum_{i' = 1}^{d_{w_{in}}}.
Cgin(i)??=I(gin(i)?=gin(i′)?)∑i′=1dwin???.
然后,将扩展后的Ue_l直接复制为新矩阵的顶部,并将从Ue_{l+1}中采样的参数放置在新矩阵的底部。
将上层信息聚合到新矩阵中:
(1)它打破了FPI对称性,这阻碍了模型的收敛(Chen等人,2016);例如,FPI使得同一层中的注意力模式重复,这是多余的,并被称为对称性;
(2)上层信息可以被用作类似但高层次的知识,以指导模型更快地收敛。
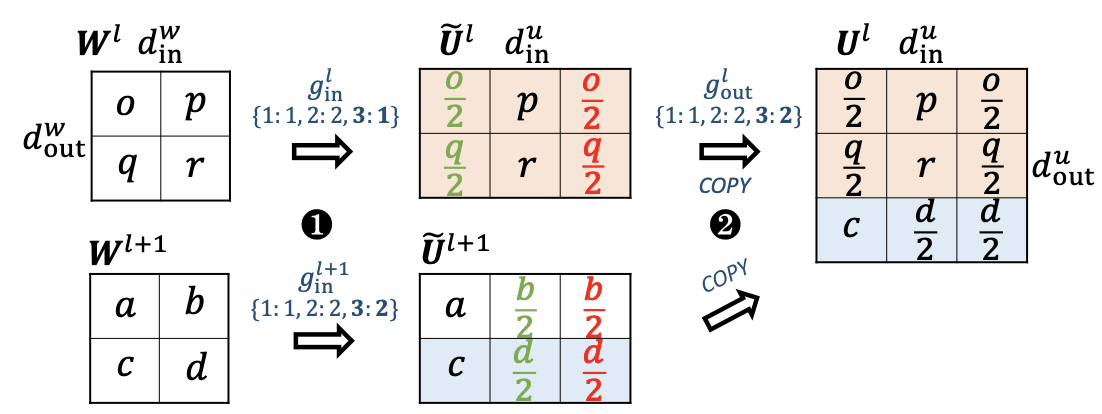
AKI概述。首先,在当前层和上层的矩阵上都进行输入维度扩展。然后,它使用当前层的扩展矩阵作为新矩阵的顶部,并将上层扩展矩阵的行作为新矩阵的底部
上面的策略是不只是可以对一个小模型扩展到大模型,可以并行的把多个小模型扩展成一个大模型。实现并不复杂,就是把多个小模型横向的排开,然后用FPI、AKI策略把多个小模型参数复用到大模型参数。
纵向模型增长:
类似stackingBert纵向的叠加模型参数,实现模型参数扩展。这部分通常是在横向扩展模型基础上,对前面很想扩展的层参数,纵向的叠加。但是其实也可以把多个小模型用FPI、AKI策略的扩展,然后把扩展参数模型做纵向的叠加。
MOE多专家模型
Mixture of Experts (MoE) 是一种机器学习技术,它将问题空间划分为多个均匀区域,每个区域都使用一个专家网络(学习器)。与集成技术不同,MoE通常只运行一个或少数几个专家模型,而不是将所有模型的结果结合起来2。
MoE的工作原理如下:
- 子任务和专家:MoE将预测建模任务分解为子任务,对每个子任务训练一个专家模型。例如,我们可以根据问题的一些领域知识将输入特征空间划分为子空间。然后,可以在每个问题的子空间上训练一个模型,这个模型实际上是该特定子问题的专家。
- 门控模型:开发一个门控模型,该模型学习基于要预测的输入信任哪个专家,并结合预测1。门控网络负责选择稀疏的专家组合来处理每个输入。
- 预测组合:给定一个输入,MoE通过根据权重以某种方式组合 f 1 ( x ) , . . . , f n ( x ) f_1(x), ..., f_n(x) f1?(x),...,fn?(x)来产生一个单一的组合输出。这里的 f 1 , . . . , f n f_1, ..., f_n f1?,...,fn? 是专家,每个都接受相同的输入 x,并产生输出 f 1 ( x ) , . . . , f n ( x ) f_1(x), ..., f_n(x) f1?(x),...,fn?(x)。权重为 w ( x ) 1 , . . . , w ( x ) n w(x)1, ..., w(x)n w(x)1,...,w(x)n。
专家和权重函数都通过最小化某种形式的损失函数进行训练,通常通过梯度下降。在选择专家的具体形式、权重函数和损失函数时有很大的自由度。
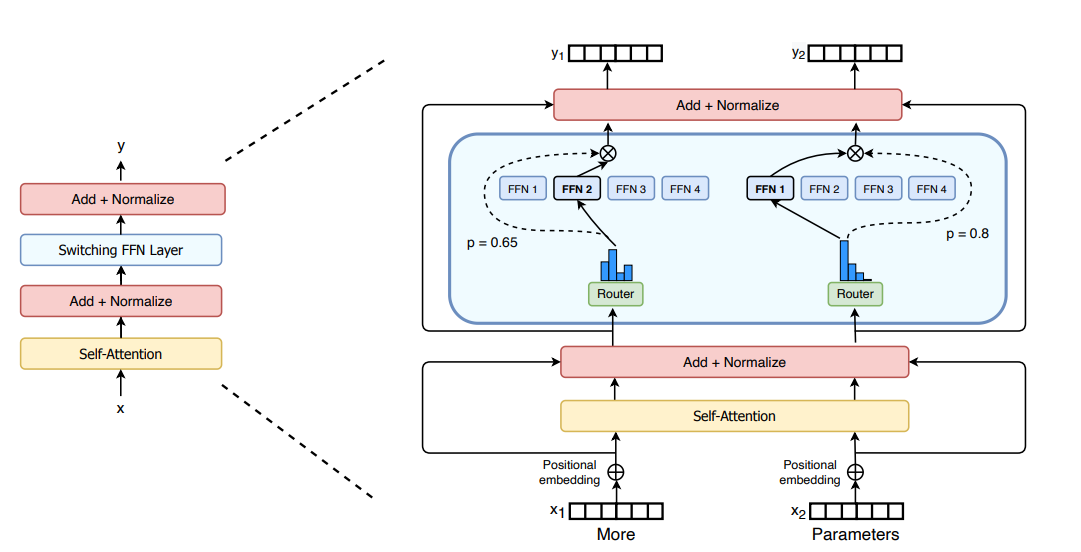
- 使用稀疏 MoE 层代替密集前馈网络 (FFN) 层。MoE 层有一定数量的“专家”(例如 8 个),其中每个专家都是一个神经网络。在实践中,专家是 FFN,但它们也可以是更复杂的网络,甚至是 MoE 本身,从而导致分层 MoE!
- 门网络或路由器,用于确定将哪些令牌发送给哪个专家。例如,在上图中,token为“More”被发送给第二个EA,token为“Parameters”被发送到第一个网络。可以将令牌发送给多个专家。在使用 MoE 时,如何将令牌路由给专家是重大决策之一 - 路由器由学习的参数组成,并与网络的其余部分同时进行预训练。
尽管与密集模型相比,MoE 提供了高效预训练和更快推理等优势,但它们也面临着挑战:
- MoE 可以显着提高计算效率的预训练,但在微调过程中难以泛化,导致过度拟合。
- 推理:虽然 MoE 可能有很多参数,但在推理过程中只使用其中的一些参数。与具有相同数量参数的密集模型相比,这会导致推理速度更快。然而,所有参数都需要加载到RAM中,因此对内存的要求很高。例如,给定像 Mixtral 8x7B 这样的 MoE,需要有足够的 VRAM 来保存密集的 47B 参数模型。为什么是 47B 参数而不是 8 x 7B = 56B?这是因为在 MoE 模型中,只有 FFN 层被视为单独的专家,其余模型参数是共享的。同时,假设每个令牌仅使用两名专家,推理速度 (FLOP) 就像使用 12B 模型(而不是 14B 模型),因为它计算 2x7B 矩阵乘法,但共享一些层(更多很快就会谈到这一点)。
训练和微调不稳定的问题,平衡损失可能会导致不稳定问题。例如,引入 dropout 可以提高稳定性,但会导致模型质量下降。另一方面,添加更多乘法组件可以提高质量,但会降低稳定性。ST-MoE 中引入的路由器 z 损失通过惩罚进入门控网络的大型对数,在不降低质量的情况下显着提高了训练稳定性。由于这种损失会促使值的绝对幅度变小,因此舍入误差会减小,这对于门控等指数函数可能会产生相当大的影响。
密集模型和稀疏模型之间的过拟合动力学有很大不同。稀疏模型更容易过度拟合,因此我们可以在专家内部探索更高的正则化(例如,我们可以对密集层进行一次丢失率,对稀疏层进行另一种更高的丢失率)。一个决策问题是是否使用辅助损耗进行微调。ST-MoE的作者尝试关闭辅助损失,即使高达11%的代币被丢弃,质量也没有受到显着影响。令牌删除可能是一种正则化形式,有助于防止过度拟合。
Switch Transformers 观察到,在固定的预训练困惑度下,稀疏模型在下游任务中的表现比密集模型更差,尤其是在 SuperGLUE 等推理密集型任务上。另一方面,对于知识密集型任务(如 TriviaQA),稀疏模型的表现不成比例地好。作者还观察到,帮助微调的专家数量较少。另一个证实泛化问题的观察结果是,该模型在较小的任务中表现较差,但在较大的任务中表现良好。
Mixture-of-Experts (MoE) 是一种神经网络架构设计,可以在不增加推理成本的情况下为大型语言模型 (LLMs) 添加可学习的参数1。MoE模型的训练和微调可以通过以下三种实验设置进行::
- Single task fine-tuning 单任务微调 ,直接对单个下游任务进行微调,而不进行指令调整
- Multi-task instruction-tuning 多任务指令调优 ,进行指令调整后,对下游任务进行少样本或零样本泛化
- Multi-task instruction-tuning followed by single-task fine-tuning多任务指令调优,然后是单任务微调,在进行指令调整的同时,对单个下游任务进行进一步的微调。
MoE 可能比密集模型从指令调优中受益更多。MoE 从更多的任务中受益更多。 与前面建议关闭辅助损耗函数的讨论不同,损耗实际上可以防止过拟合。
MoE模型的优点是,它们可以利用指令调整技术更好地从指令中受益。然而,缺点是,在没有指令调整的情况下,MoE模型的性能可能不如密集模型1。
此外,微调和检索增强生成(RAG)并不是对立的技术,而是可以结合使用以利用每种方法的优点。微调有助于使通用语言模型在特定任务上表现良好,使其更具任务特性,而RAG专注于通过检索机制将LLM连接到外部知识源2。结合RAG和微调在LLM项目中提供了强大的协同作用,可以显著提高模型性能和可靠性。微调允许通过使用特定领域和纠错数据对模型进行微调,以纠正模型可能持续犯的错误。其他优点包括学习所需的生成音调和更优雅地处理边缘情况。然而,微调模型在训练期间成为静态数据快照,可能会在动态数据场景中迅速过时。RAG在动态数据环境中表现优秀,它持续查询外部源,确保信息保持最新,而无需频繁地重新训练模型。
混合增量学习
DARE增量
整体思路就是:不同任务数据集sft出不同的功能增量层,把sft中不变的层去除,变化的参数可以认为是这个功能任务的激活参数;当多个功能任务下就会出现多个功能层,把这些功能层做带权重策略的融合,模型能够同时具备base model+不同功能任务sft的能力。这样就可以解决掉lora方法做sft,多个模型融合出现遗忘能力的问题。同时也可以让模型的训练更容易,泛化力更强。
对于语言模型(LM)而言,有监督式微调(SFT)是一种被广泛采用的策略。SFT 在预训练基模型的基础上,通过微调其参数来获得激发了特定能力的微调模型。显而易见,SFT 带来的效果体现在了模型在 SFT 前后的参数变化中,可以称之为 delta 参数。
阿里团队的研究者们首先证实 SFT 后的 LMs(无论是基于编码器还是基于解码器的)倾向于学习到大量冗余的 delta 参数。研究者们借鉴 Dropout 的思路提出了 DARE(Drop And REscale)来显著降低 delta 参数的冗余性。在将 DARE 应用于拥有 700 亿参数的 LMs 后,可以在维持模型性能的前提下去除多达 99% 的 delta 参数。同时,LMs 拥有的参数越多,它就能容忍越大的。
一种用于消除delta参数冗余性的简单方法
研究者们提出的 DARE 方法非常简单,仅由两部分组成:丢弃和重新缩放,其工作流程如下图所示。 表示预训练基模型的参数, 代表在预训练模型的基础上针对任务 进行 得到的模型参数。给定 delta 参数 , DARE 首先根据丢弃率 对 进行随机丟弃 (将它们的值重置为零),然后将剩余的参数乘以 1 /(1-p) ,计算过程如下:

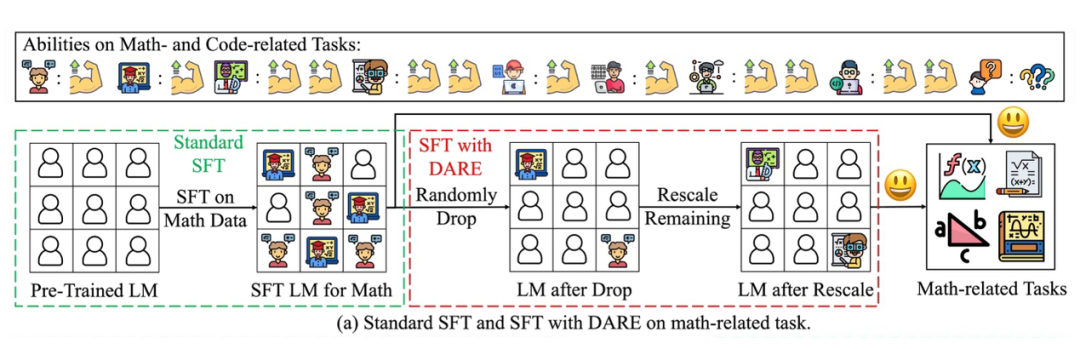
最后,研究者们将
σ
t
^
\hat{\sigma^t}
σt^和
θ
P
R
E
\theta_{PRE}
θPRE?相加来得到用于推理的参数,即
θ
D
A
R
E
t
=
σ
^
t
+
θ
P
R
E
\theta^t_{DARE}=\hat{\sigma}^t+\theta_{PRE}
θDAREt?=σ^t+θPRE?。研究者们指出重新缩放操作在 DARE 中是极其重要的,它能够保持模型输出的期望大致不变。后续的实验也展示了该操作的有效性。
使用DARE进行模型合并
研究模型合并方法的一个难点在于:对原始的模型参数进行简单的加权平均等运算会产生参数冲突,导致合并得到的模型效果比融合前的模型差。研究者们认为 DARE 具备的大幅降低参数冗余性的能力能天然地克服这一问题,并将 DARE 作为一个通用的预处理技术来有效地合并多个 LMs。
研究者们首先使用 DARE 来消除每个模型中的冗余 delta 参数以缓解多个模型之间的参数冲突,而后基于现有的模型合并方法整合降低了冗余性的 delta 参数(见图 3)。DARE 能应用于任何现有的模型合并方法,以 Task Arithmetic 方法来举例,DARE 的应用过程可以写为如下公式:

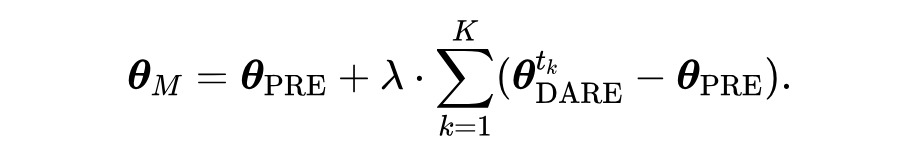

pretrain+增量控制参数+adapter层参数控制
这部分是属于个人的一些思考和可能思路的畅想。这个要解决的是个什么问题呢。其实就是如何让模型同时具备世界模型能力,并且可以增量的补强模型能力而不出现遗忘能力退化。有点类似于乐高的意思,就是有个基座层和功能插件,功能插件可以通过sft或者增量小模型训练,这个功能插件是可以和大模型无损失的对接的。
有了解过stylegan的同学应该就会知道,这个模型是如何分出了几个控制变量。每部分是可以单独去影响图片质量的某一部份的,比如眼睛还是眼睛;换句话说就是这个模型里面的参数是出现功能分化的;某一些向量embbeding就是控制模型里面某些参数产生制定的功能能力。当然stylegan是有自己问题的:泛化力不够,对于没有见过的特征无法处理,训练需要数据比较高;模型表征能力不够,训练人脸模型就只能hi人脸,如果要表征东西多了就要多个模型。
那么我们有没可能保留大模型的泛化力,同时又能保留stylegan的部分参数可控性。个人觉得是可以的:
1.pretrain模型作为世界模型,保留泛化力和表征力
2.在pretrain模型之上加一层类似stylegan的参数控制层,这一层相当于是复杂设备控制面板,把pretrain的各种参数收到更小维度的控制矩阵
3.在控制矩阵层上接入转换矩阵层,矩阵之上加入adapter层用sft的方式来增量训练模型不同指令能力;相当于是基于控制矩阵的语法利用sft数据做了编码,生成了一个小的控制程序模块你可以理解成是plm控制模块
4.有多个sft的控制模块后如果application需要用到多个模块,可以直接把这个模块插上(相当于是对控制矩阵层的转换矩阵作为转接头把几个模块加上)需要甚至可以用application层的例子吧多个sft层组合一起做application层sft
小结
文章回顾了如何把一个训练过的模型能力传递给另一个大模型的几种技术:知识蒸馏、参数复用。然后介绍了如何让大模型可以增量的扩展自己的能力,介绍了MOE experts方法,还介绍了一些自己的想法。
文章详细的介绍了知识蒸馏的方法,如何设计网络结构,需要注意的4个问题点。同时也介绍了参数复用的两大方法,横向扩展和纵向扩展,还介绍了如果有个小模型如何做参数复用。
在MOE部分介绍了如何实现多专家模式,把FFN层如何用稀疏的moe层表示。以及MOE的过拟合问题如何在预训练和微调时候控制。MOE带来了扩展模型能力的可能,但是也增加了训练的成本和难度。
在“pretrain+增量控制参数+adapter层参数控制”部分介绍了我的一些思考。大模型现在的sft方式其实面对的是单模型alighment的问题,只是通过alighment能够带来能力增量增强的副作用。但是如果训练技巧不够好或者模型训练过于成熟sft很可能会在增强了某部分能力消弱另一半能力。那么有没可能同时保持模型泛化力有模块化增量增加其他能力,不影响其它能力。我提出的想法是用某块组合方式来实现:
1.pretrain保持泛化性
2.把pretrain模型参数用更小可控参数矩阵层转换控制
3.在可控参数矩阵层之上增加adapter层,
这样相当于是pretrain是一个很复杂通用机器,通过控制矩阵引出基础控制算子,然后在通过adapter层作为控制算子编程层,用ssft数据任务调教控制编程层来实现能力增量更新。
这样就进呢个保持大模型强大的泛化能力和表征力,又能保证模型可增量增强能力不影响其它能力遗忘丢失。
参考:
https://aclanthology.org/2022.acl-long.151.pdf
https://aclanthology.org/2022.naacl-main.288.pdf
moe expters:
https://arxiv.org/pdf/2309.05444.pdf
https://arxiv.org/pdf/2208.02813.pdf
https://huggingface.co/blog/moe
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CSS新手入门笔记整理:CSS3动画
- 高速视频采集卡设计方案:620-基于PCIe的高速视频采集卡
- 【基于Python的二手车数据可视化平台的设计与实现】
- 大模型时代下AIGC新浪潮
- 【第1期】SpringSecurity基于角色和权限的细粒度接口权限控制
- Spring Boot实现数据加密脱敏:注解 + 反射 + AOP
- 用Minikube 搭建一个单机k8s玩玩
- 快速上手 vue.js <二>
- Python实现力扣经典面试题——移除元素
- linux查看已使用内存