transformer详解
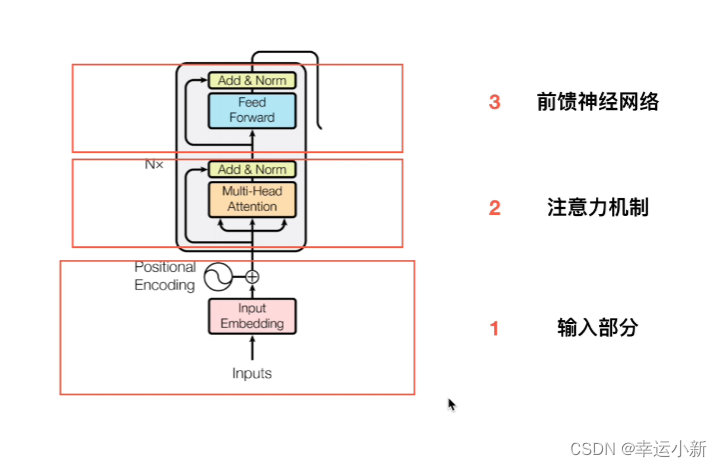
1.从全局角度概括transformer

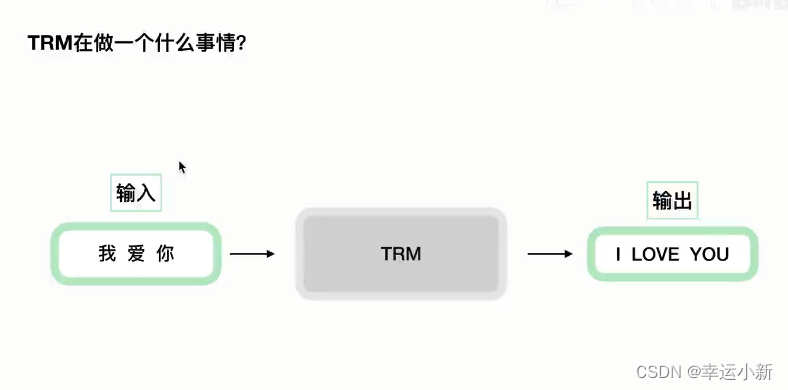
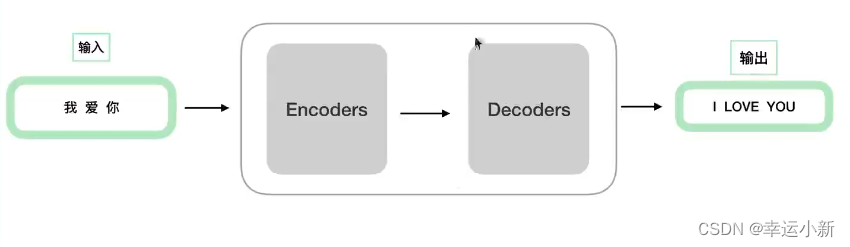
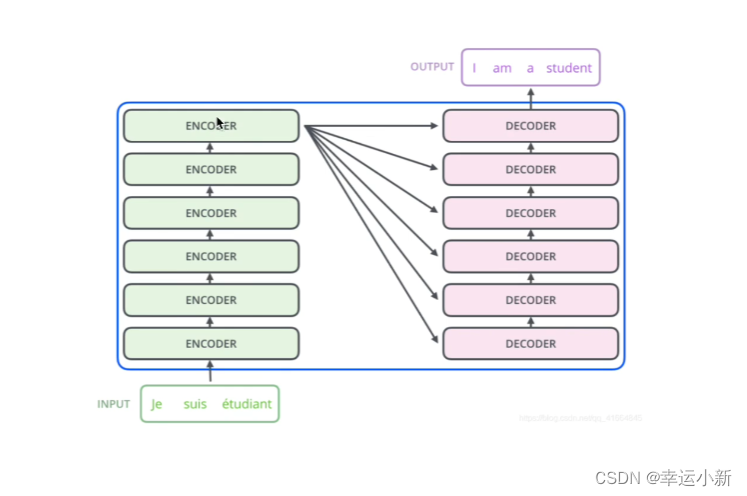
一个典型的编码器-解码器的结构,类似于sequence-to-sequence
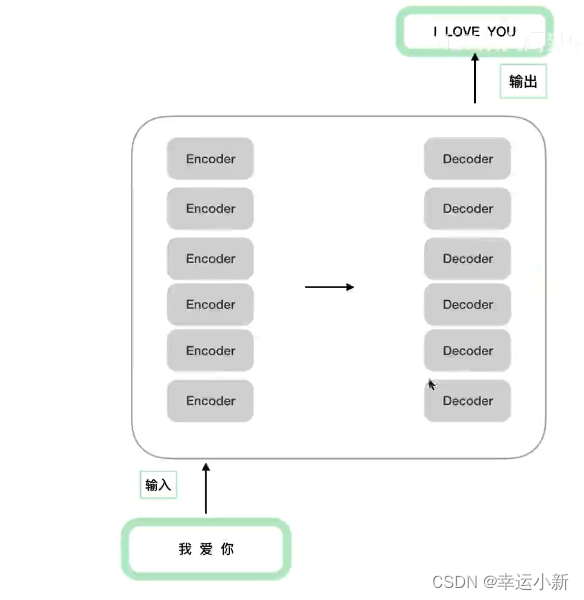
这6(可以自己定)个encode,decode在结构上是完全相同的,但是参数不是完全相同的
训练的时候,不是训练了一个encode,然后copy 6次,而是6个encode多在训练
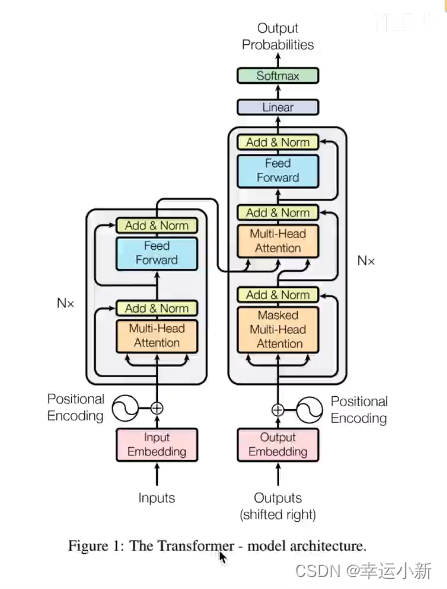
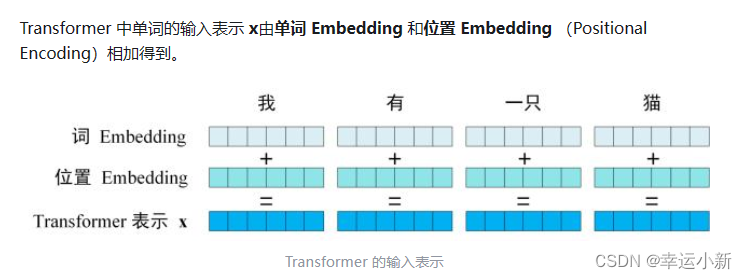
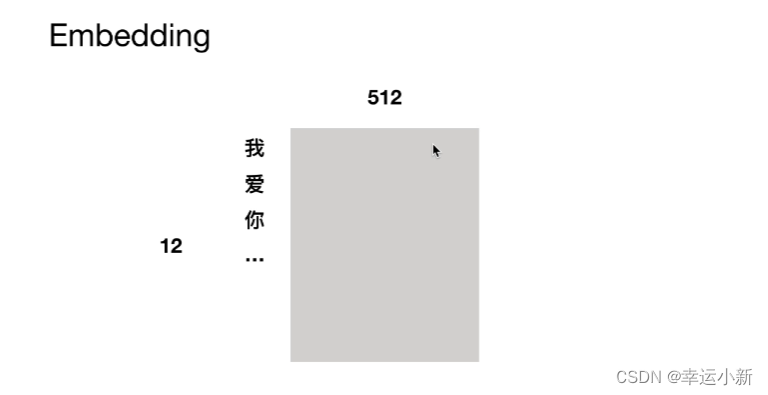
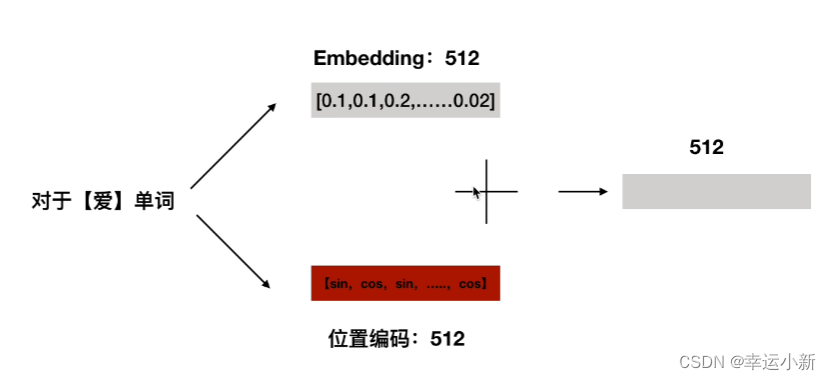
2.位置编码详细解读

RNN是共享一套参数
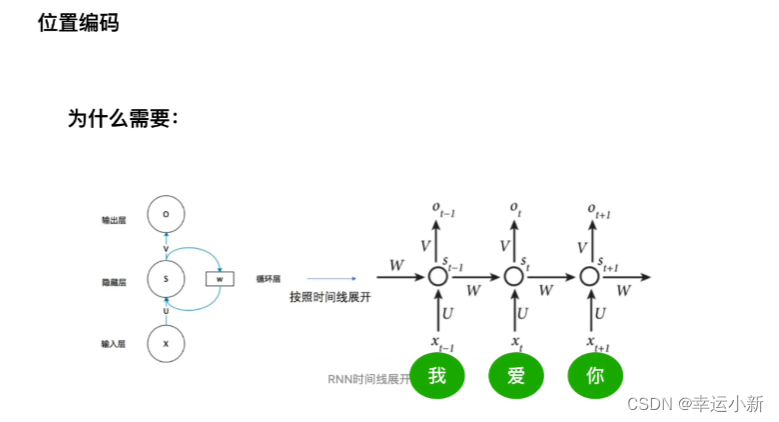
transformer是并行处理的,不同于RNN(先处理’我’,再处理‘爱’…),这样做增快了速度,但忽略了单词之间的先后关系
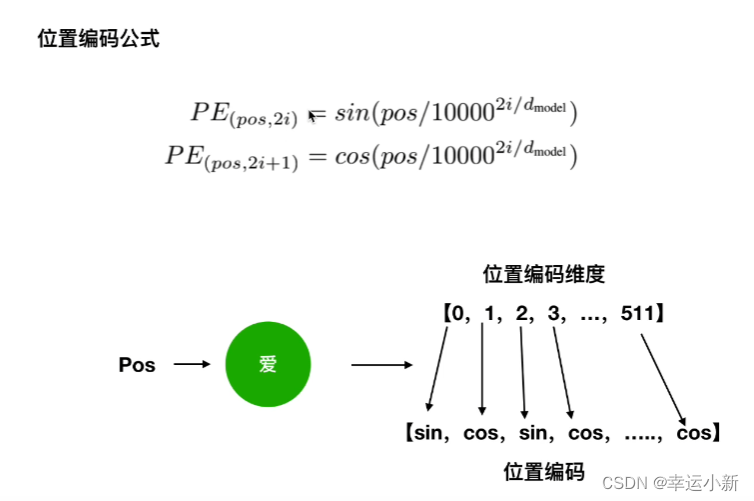
这里的2i表示偶数,2i+1表示奇数


正余弦函数对于同一个位置,同一个pos,不同的向量,使用不同的sin或者cos,体现出的是绝对位置信息
根据公式(2)三角函数的性质,我们可以推导出(3)
以第一行为例,对于‘我爱你’,pos+k代表‘你’,pos代表‘我’,k代表‘爱’
也就是说‘我爱你’中的‘你’可以被pos(‘我’),k(‘爱’)两者线性组合起来,这种组合意味着绝对位置向量中蕴含了相对位置信息
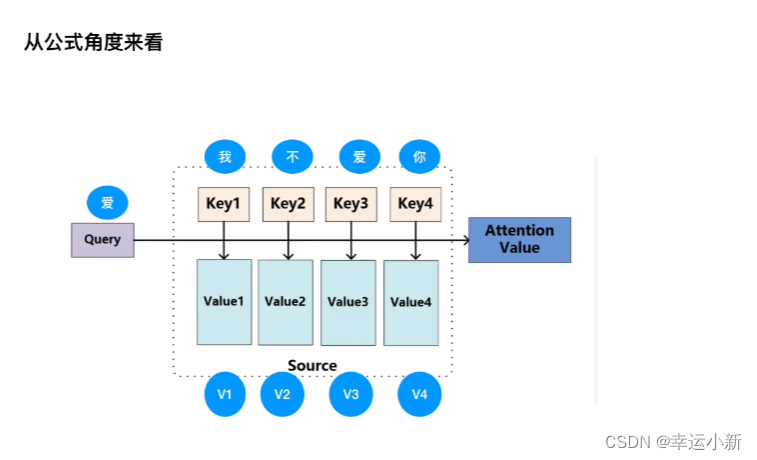
3.注意力机制

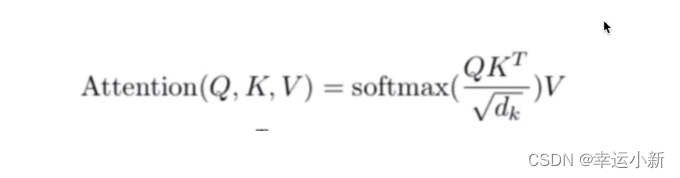
做softmax归一化,归一化后得到一个相似度向量,再乘V,得到一个加权的和

Q代表婴儿对应的某种向量
左上,左下,右上,右下分别代表Key1,Key2,Key3,Key4的某种向量
V1,V2,V3,V4也是左上,左下,右上,右下对应的某种值向量value
首先是婴儿和左上,左下,右上,右下分别做点乘得到某个值
(为什么要点乘?在相似度计算的时候有是三种方式,分别为点乘,MLP,cos相似性。其中点乘是一个向量在另一个向量上投影的长度,是一个标量,可以反映两个向量之间的相似度,也就是说两个向量越相似,点乘结果越大)
判断婴儿和左上,左下,右上,右下四个区域,哪个点乘的结果最大,结果越大,距离越靠近,越相似,我越关注
比如与左上,左下,右上,右下点乘后分别为0.7 ,0.1 ,0.1 ,0.1 ,
就与左上最相似,然后将0.7 ,0.1 ,0.1 ,0.1 ,再与V矩阵相乘,得到的就是attention value,就是一个加权和
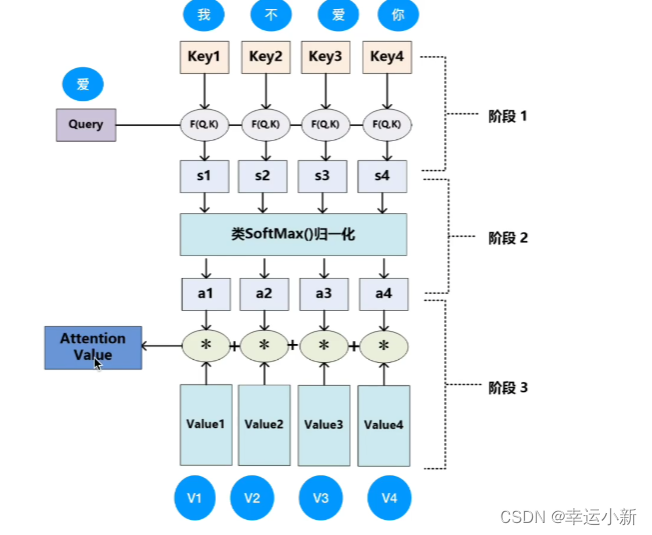
下面在讲解一下NLP中的例子
S1,S2,S3,S4就是点乘后的值,
然后softmax得到相似度a1,a2,a3,a4(相加=1)
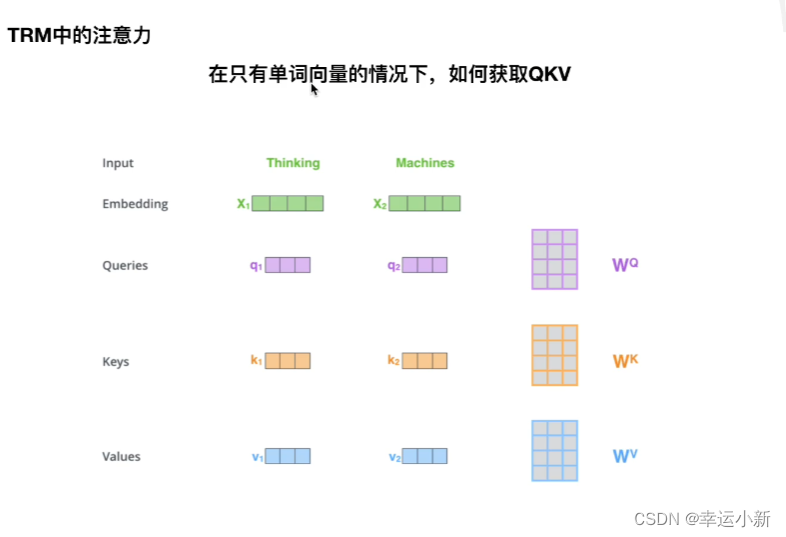
X1 * W^Q = q1
X1 * W^K = k1
X1 * W^V = v1
X2 * W^Q = q2
X2 * W^K = k2
X2 * W^V = v2
接下来我们就要做attention value

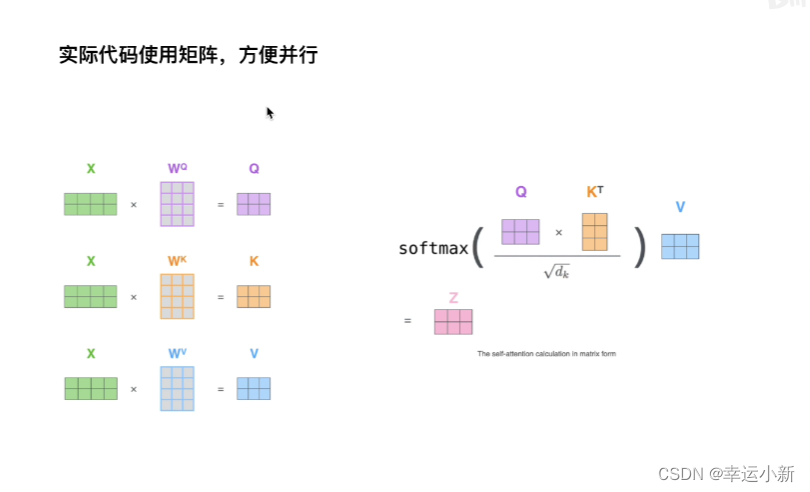
还有要注意多头
这里我们只用了一套参数,但实际上我们是用了多套参数

在不同的参数中的得到不同的Z
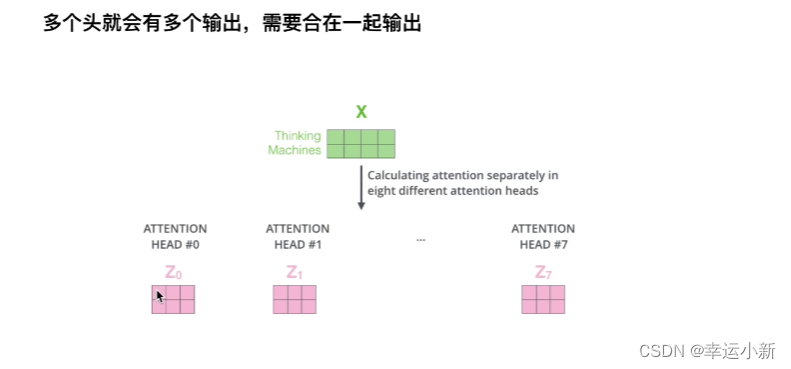
最后我们要将多个头合在一起进行输出,然后再乘以一个矩阵,就得到多头注意力机制的输出
4.残差连接
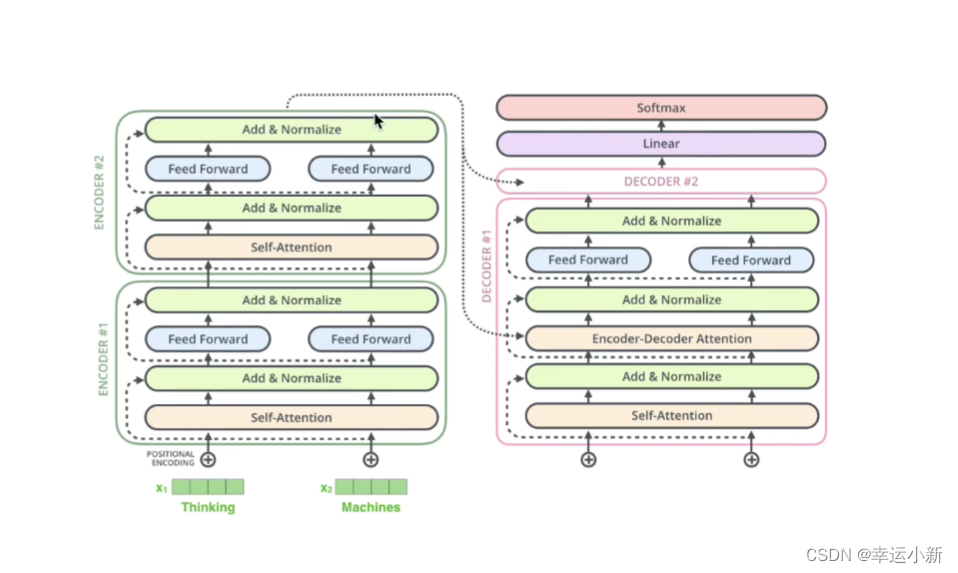
Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
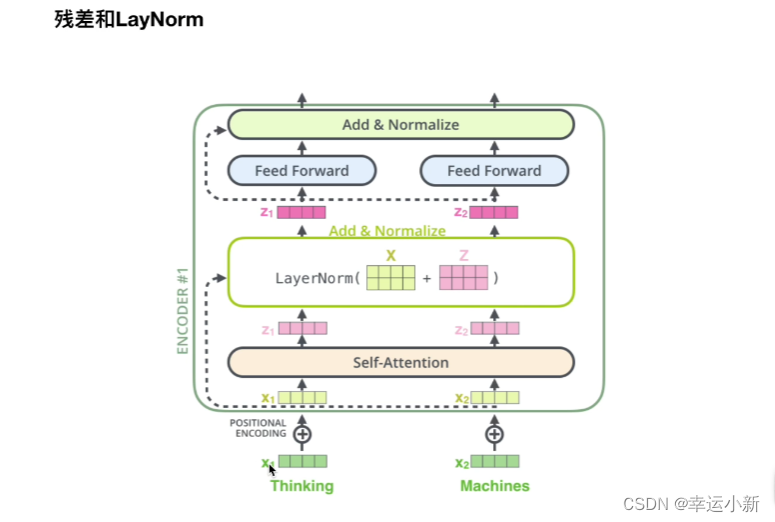
X + Z是一个残差的结果,再经过Layer Normalization
这里的Z表示其中的f(x)
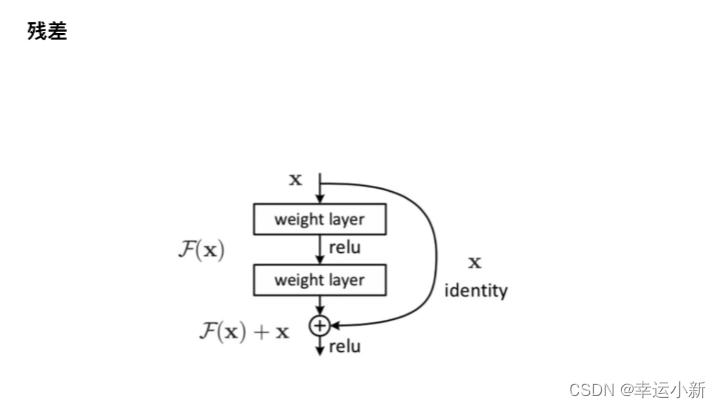

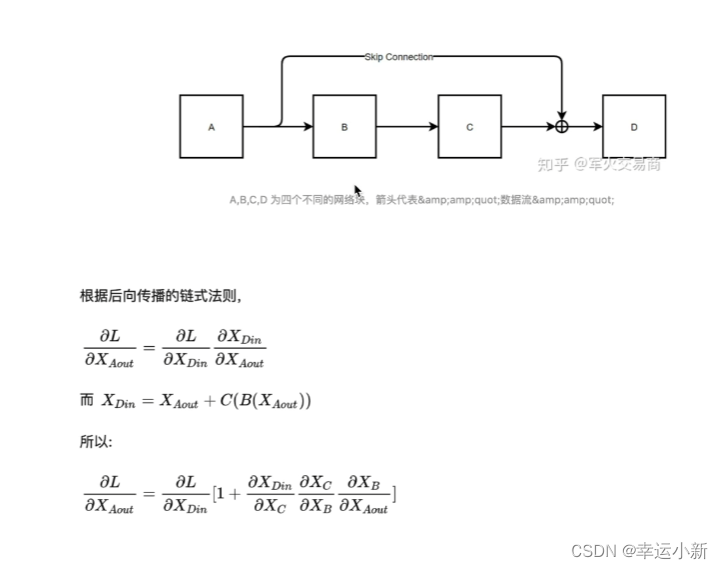

残差就是缓解了梯度消失,可以将NLP模型往深了做

5.Batch Normal

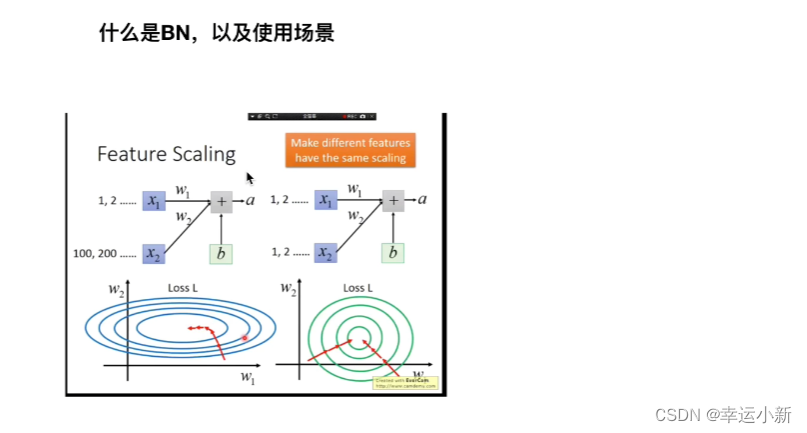
特征缩放
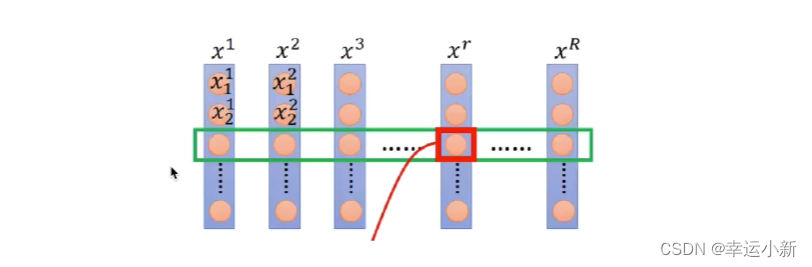
X1,X2,X3…表示班级里面的人,每一行代表他们的一个特征,身高体重…


比如一个班有50个人,我们选10个人的身高作为batch_size,去预测其他40个人的身高
如果选的人太少,效果不好

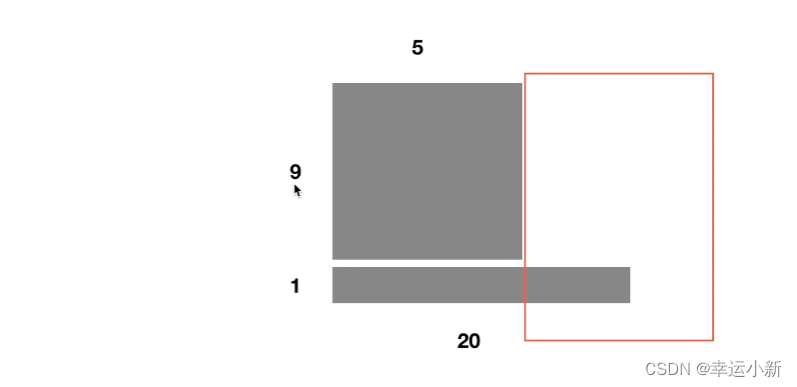
现在有一堆样本,batch_size为10
有9个长度为5,还有一个长度为20
这样我们在输入时前5个单词的均值和方差可以算出来
但第6个单词到第20个单词我们的均值和方差没法算
6.layer normal

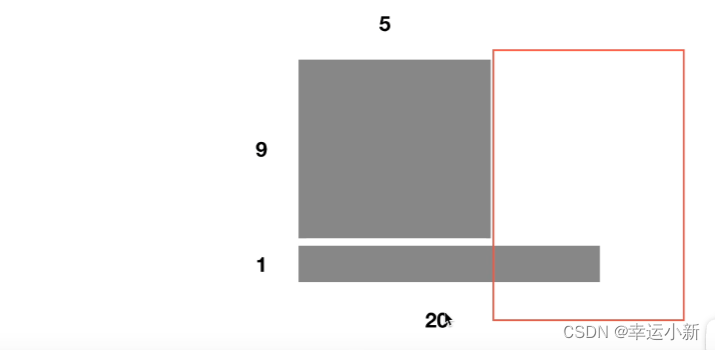
比如最后一个句子是20个单词,LN就是对这个20个单词去做缩放,去做他的均值和方差(横过来的)
BN就是分别对第一个单词做均值和方差,第二个单词做均值和方差…

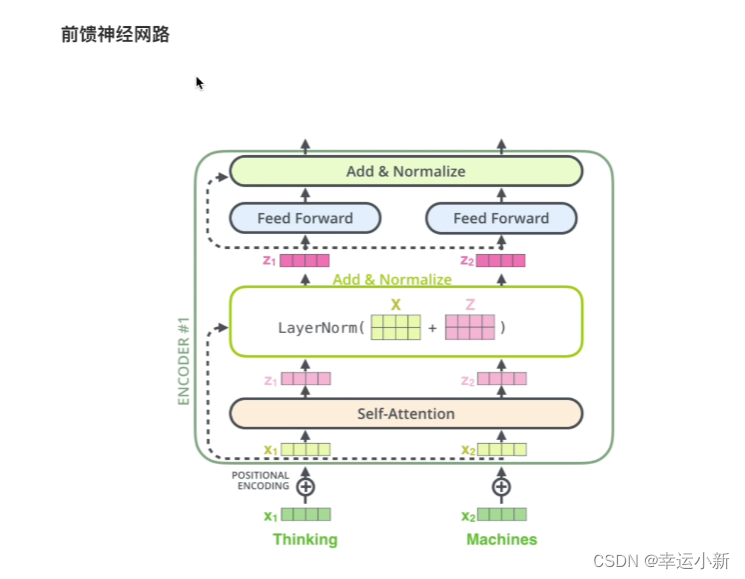
feed forward是一个两层的全连接
7.decode
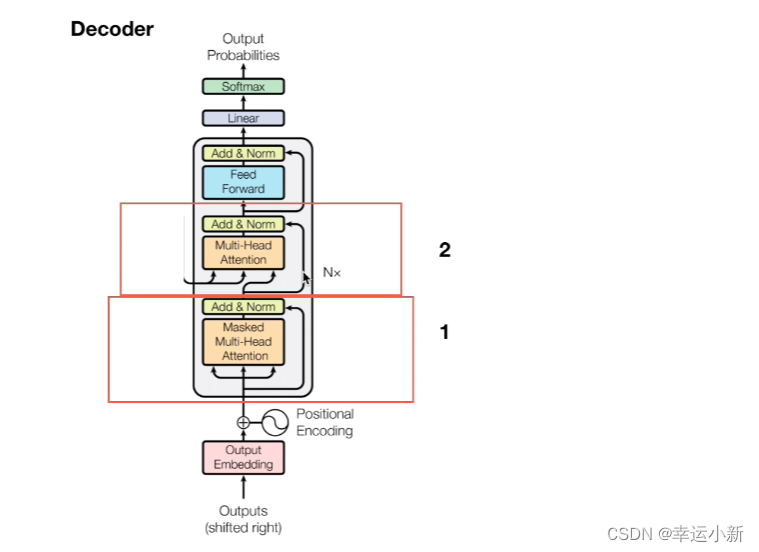
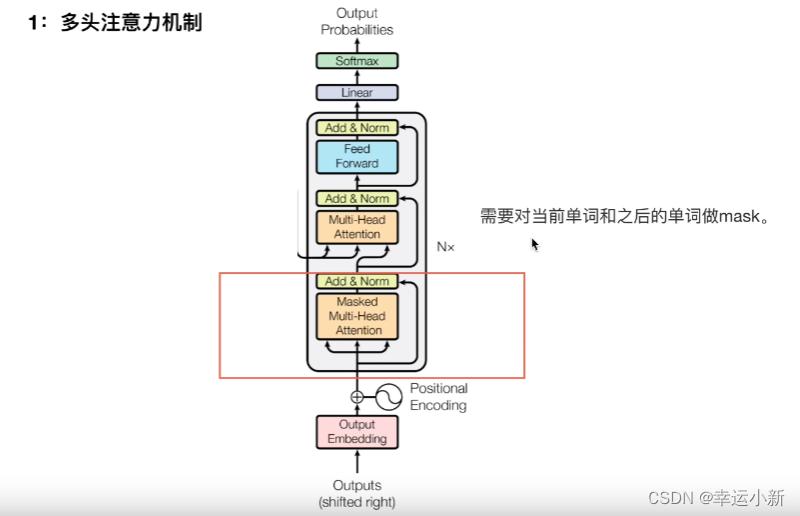
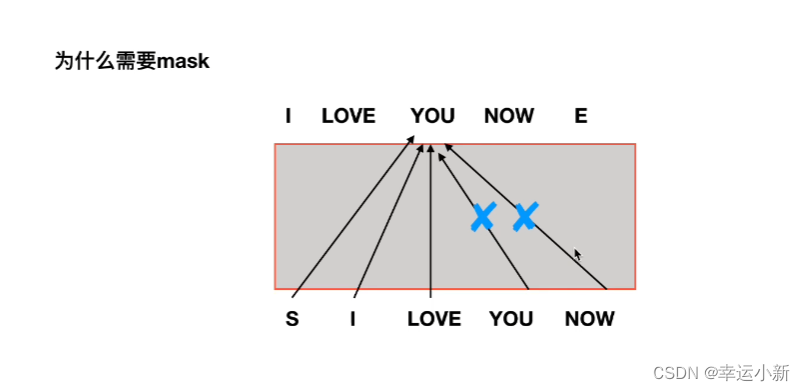
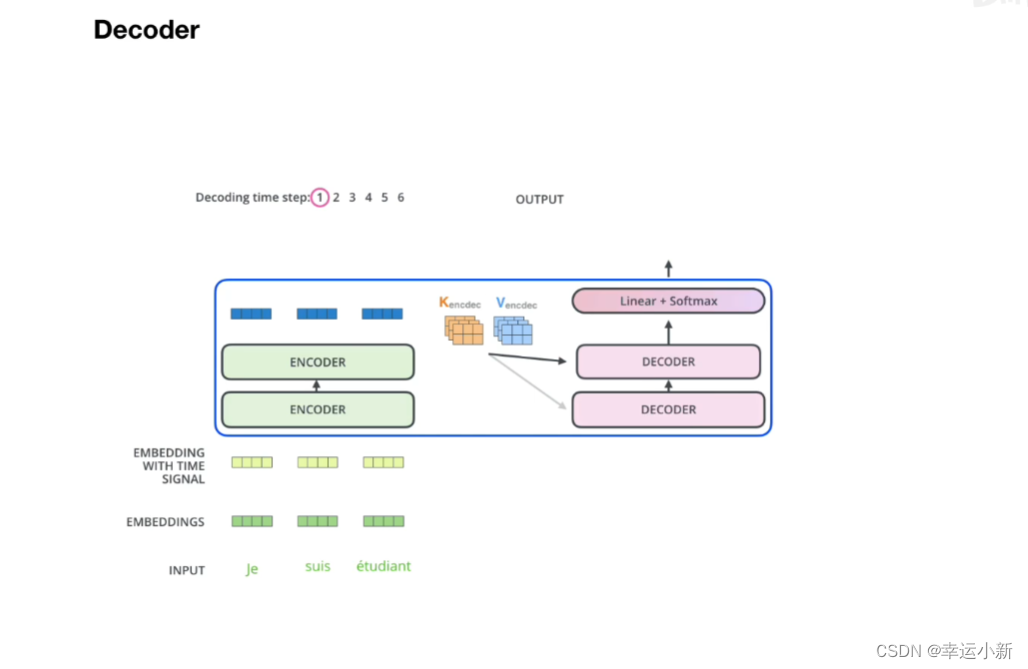
所有encode的输出生成某种值,和每一个
encode中生成K,V矩阵,decode中生成Q矩阵
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【DWJ_1703225514】基于Sklearn航空公司服务质量分析
- 云卷云舒:基于业务逻辑关联度实现数据预加载
- redis复习笔记01(小滴课堂)
- 多维护健康:新生儿补充多维注意事项
- 记录 Docker 外部访问的基本操作
- 传统跨境电商是否应转型独立站?
- 关于Redis的缓存问题的说明和解决方案
- rocky linux 8.8 安装 fail2ban 提示 No module named ‘fail2ban‘
- 【算法每日一练]-图论(保姆级教程篇14 )#会议(模板题) #医院设置 #虫洞 #无序字母对 #旅行计划 #最优贸易
- 基于SSM的企业员工管理系统