P4学习(二) 阅读《P4: Programming Protocol-Independent Packet Processors》论文
论文链接
注:本文所有内容和图片均来自于该论文,只用作学习记录使用
P4 的出现背景与三个目的
OpenFlow 1.0 提供了12个首部字段
到OF1.4 增长到41个首部字段
①增加了规范的复杂性
②新首部的灵活性仍然没变
P4的三个主要目标是:
-
现场可重配置(Reconfigurability in the field):程序员应该能够在网络设备部署后改变其处理数据包的方式。
-
协议独立性(Protocol independence):网络设备(如交换机)不应与任何特定的网络协议绑定。
-
目标独立性(Target independence):P4设计的程序应能够在各种硬件和软件平台上运行,而不受特定目标平台的限制。
P4实现方法
介绍
相较于不停地扩展首部字段长度,为了避免规范的首部字段泛滥现象。
P4被提出用于解析数据包和匹配报头字段

图一 P4与现有API的关系
新的“OpenFlow 2.0”API被配置用于灵活的机制来解析数据包和匹配报头字段
抽象转发模型
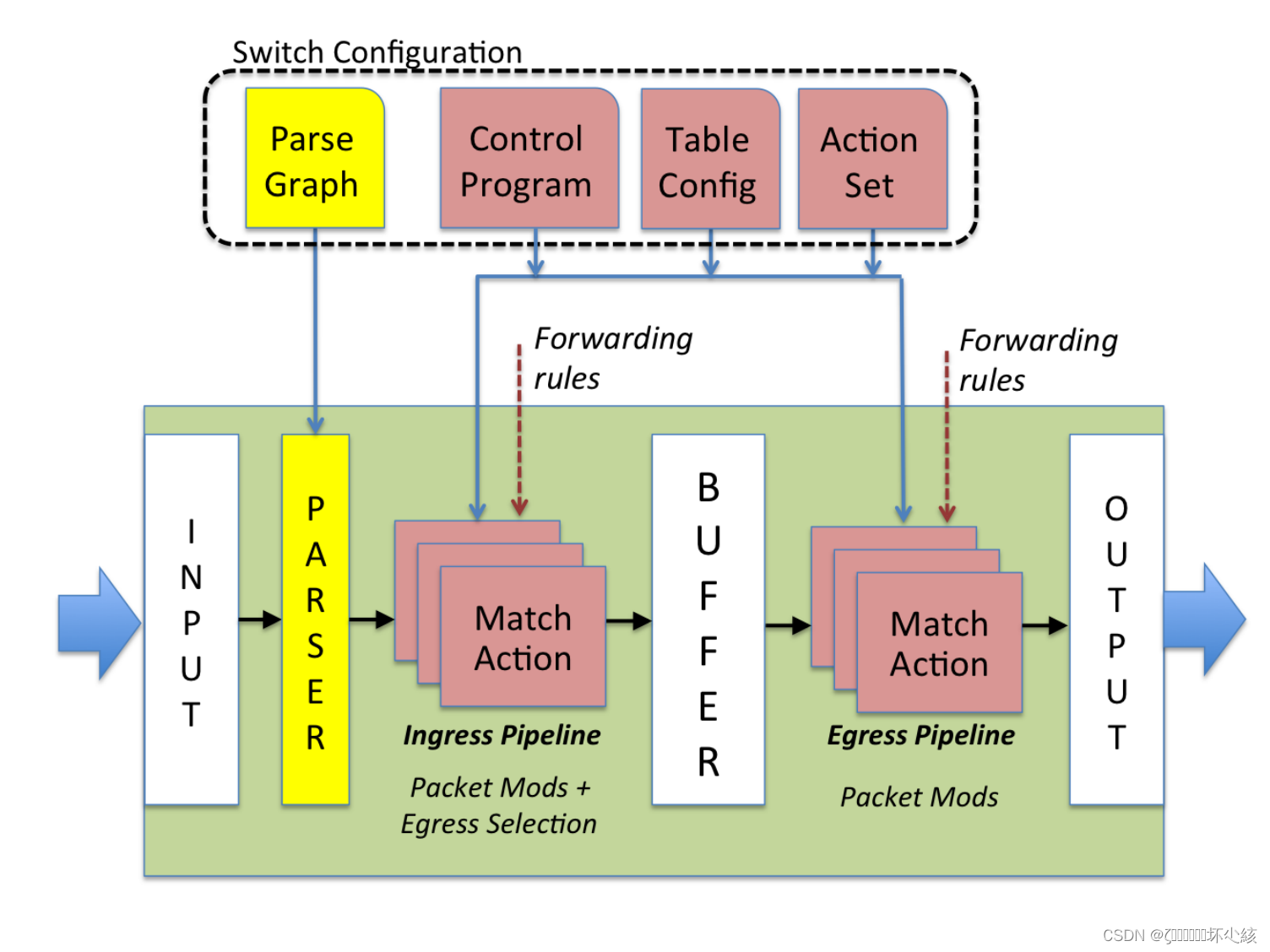 转发模型由两种操作控制:
转发模型由两种操作控制:配置和填充。
配置操作编程解析器,设置匹配+动作阶段的顺序,并且配置每个阶段如何处理头字段。填充操作,在匹配+动作表中添加(删除)流表项,这个表在配置操作进行时,就配置好。填充确定在任何给定时间应用到数据包的策略。
为了本文的目的,我们假定配置和填充是处于两个不同的阶段。交换机在配置阶段不需要处理数据包,但是,我们仍然希望,在重配、升级的时间里,仍然可以进行数据包处理。
首先是解析器对到来的数据包进行处理。数据包数据部分假定为分别缓存,并且不能够进行匹配。解析器从头部识别、解析出字段,并且因此定义交换机支持的协议。模型未对协议头的含义进行假定,仅仅是解析的表示(解析到的东西)定义了匹配+动作的集合。
接下来,解析出来的头字段通过匹配+动作表,匹配+动作表被分在进入和出去两部分之间,两者可能修改数据包头,进入的匹配+动作决定了出去的端口,以及决定了数据包放置的队列。基于进入口处理,数据包可能被转发、复制(组播或者控制平面)、丢弃,或者触发流控制。出口匹配+动作对每一个数据包头实例进行修改。动作表可以与流关联,以追踪帧到帧的数据状态。
数据包在多个阶段之间可以携带额外的信息(数据包处理时产生),我们将这些信息称之为元数据,可以类似数据包头字段那样被识别。元数据例子比如,进入端口、传输目的、和队列,时间戳可以用于数据包调度,有些数据(比如虚拟网标识符)在表与表之间传输是不会改变的。
排队原则的处理与现在的OpenFlow协议一样:一个动作映射一个数据包到一个队列,这个队列配置为接收特殊服务规则。服务规则作为交换机配置的一部分。通过添加动作原语可以允许程序员实现新的或者现存的拥塞控制协议。
总结
该模型的工作流程包括以下几个关键步骤:
-
可编程解析器:数据包首先通过一个可编程解析器。与OpenFlow假设的固定解析器不同,P4的模型支持可编程解析器,这允许定义新的报头格式,从而增加处理不同类型数据包的灵活性。
-
匹配+动作阶段:经过解析器处理后,数据包进入多个匹配+动作阶段。这些阶段可以是串行的、并行的,或者两者的结合。在OpenFlow模型中,这些阶段通常是串行的,但P4模型提供了更大的灵活性,允许这些阶段以不同的方式组织。
-
动作的执行:在匹配+动作阶段,根据数据包的特定内容执行一系列动作。这些动作是由交换机支持的协议独立的基元组成的,这意味着在定义数据包处理行为时,不依赖于任何特定的网络协议。
这个抽象模型概括了不同转发设备(例如以太网交换机、负载均衡器、路由器)如何处理数据包,并且可以应用于不同的技术(例如固定功能交换机ASIC、网络处理器NPU、可配置交换机、软件交换机、FPGA。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!