【进程间通信】
什么是进程通信
进程通信( InterProcess Communication,IPC)就是指进程之间的信息的传播和交换。
进程是分配系统资源的单位,包括内存地址空间,为了保证安全,一个进程不能直接访问另一个进程的地址空间,如下图。因此各进程拥有的内存地址空间相互独立。
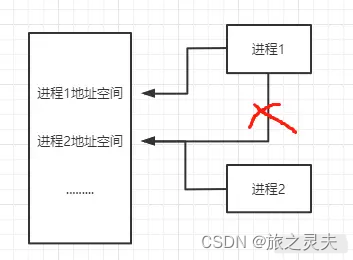
但是进程之间的信息交换又是必须实现的。为了保证进程间的安全通道,操作系统提供了一些方法。
那么不同进程之间存在着什么双方都可以访问的介质呢?进程的用户空间是互相独立的,一般而言是不能互相访问的,唯一的例外是共享内存区。但是,系统空间却是“公共场所”,所以内核显然可以提供这样的条件。除此以外,那就是双方都可以访问的外设了。在这个意义上,两个进程当然也可以通过磁盘上的普通文件交换信息,或者通过“注册表”或其它数据库中的某些表项和记录交换信息。广义上这也是进程间通信的手段,但是一般都不把这算作“进程间通信”。因为那些通信手段的效率太低了,而人们对进程间通信的要求是要有一定的实时性。
进程间通信的目的
和常见的通信一样,进程间的通信也主要是为了处理以下几种情况:
数据传输:一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几兆字节之间。
共享数据:多个进程想要操作共享数据,一个进程对共享数据的修改,别的进程应该立刻看到。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
资源共享:多个进程之间共享同样的资源。为了做到这一点,需要内核提供锁和同步机制。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程通过与内核及其它进程之间的互相通信来协调它们的行为。如Linux支持多种进程间通信机制,信号和管道是其中的两种。除此之外,Linux还支持System V的进程间通信机制。
常见的7种通信方式
进程间通信是同一台处理机或不同处理机的多个进程间传送数据或消息的一些技术或方法,主要的方式有:
1、管道(pipe)
管道是 UNIX 系统IPC最古老的形式,管道可以分为pipe(无名管道)和fifo(命名管道)两种,它们之间除了建立、打开、删除的方式不同外,其他的地方几乎是一样的,都是通过内核缓冲区实现数据传输。
各位如果学过 Linux 命令,那对管道肯定不陌生,Linux 管道使用竖线 | 连接多个命令,这被称为管道符。
$ command1 | command2以上这行代码就组成了一个管道,它的功能是将前一个命令(command1)的输出,作为后一个命令(command2)的输入,从这个功能描述中,我们可以看出管道中的数据只能单向流动,也就是半双工通信,如果想实现相互通信(全双工通信),我们需要创建两个管道才行。
管道的实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据:管道一端的进程顺序地将进程数据写入缓冲区,另一端的进程则顺序地读取数据,该缓冲区可以看做一个循环队列,读和写的位置都是自动增加的,一个数据只能被读一次,读出以后再缓冲区都不复存在了。当缓冲区读空或者写满时,有一定的规则控制相应的读进程或写进程是否进入等待队列,当空的缓冲区有新数据写入或慢的缓冲区有数据读出时,就唤醒等待队列中的进程继续读写。

通常管道指的就是无名管道。用于相关进程之间的通信,例如父进程和子进程,它通过pipe()系统调用来创建并打开,当最后一个使用它的进程关闭对他的引用时,pipe将自动撤销。它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
管道是一种半双工的通信方式,数据只能在一个方向上流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
在 Linux 的实际编码中,是通过 pipe 函数来创建匿名管道的,若创建成功则返回 0,创建失败就返回 -1:
int pipe (int fd[2]);该函数拥有一个存储空间为 2 的文件描述符数组:
- fd[0] 指向管道的读端,fd[1] 指向管道的写端
- fd[1] 的输出是 fd[0] 的输入
管道进程通信步骤:
(1)、父进程创建管道,得到两个?件描述符指向管道的两端

(2)、父进程fork出子进程,?进程也有两个?件描述符指向同?管道。

(3)、父进程关闭fd[0],子进程关闭fd[1],即?进程关闭管道读端,?进程关闭管道写端(因为管道只支持单向通信)。?进程可以往管道?写,?进程可以从管道?读,管道是?环形队列实现的,数据从写端流?从读端流出,这样就实现了进程间通信。

看完上面这些讲述,我们来理解下管道的本质是什么:对于管道两端的进程而言,管道就是一个文件(这也就是为啥管道也被称为共享文件机制的原因了),但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在于内存中。
简单来说,管道的本质就是内核在内存中开辟了一个缓冲区,这个缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区的操作。
管道出现的四种特殊情况:
1.写端关闭,读端不关闭;
那么管道中剩余的数据都被读取后,再次read会返回0,就像读到文件末尾一样。
2.写端不关闭,但是也不写数据,读端不关闭;
此时管道中剩余的数据都被读取之后再次read会被阻塞,直到管道中有数据可读了才重新读取数据并返回;
3.读端关闭,写端不关闭;
此时该进程会收到信号SIGPIPE,通常会导致进程异常终止。
4.读端不关闭,但是也不读取数据,写端不关闭;
此时当写端被写满之后再次write会阻塞,直到管道中有空位置了才会写入数据并重新返回。
使用管道的缺点:
1.两个进程通过一个管道只能实现单向通信,如果想双向通信必须再重新创建一个管道或者使用sockpair才可以解决这类问题;
2.只能用于具有亲缘关系的进程间通信,例如父子,兄弟进程。
一个简单的关于管道的例子:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int _pipe[2]={0,0};
int ret=pipe(_pipe); //创建管道
if(ret == -1)
{
perror("create pipe error");
return 1;
}
printf("_pipe[0] is %d,_pipe[1] is %d\n",_pipe[0],_pipe[1]);
pid_t id=fork(); //父进程fork子进程
if(id < 0)
{
perror("fork error");
return 2;
}
else if(id == 0) //child,写
{
printf("child writing\n");
close(_pipe[0]);
int count=5;
const char *msg="i am from XATU";
while(count--)
{
write(_pipe[1],msg,strlen(msg));
sleep(1);
}
close(_pipe[1]);
exit(1);
}
else //father,读
{
printf("father reading\n");
close(_pipe[1]);
char msg[1024];
int count=5;
while(count--)
{
ssize_t s=read(_pipe[0],msg,sizeof(msg)-1);
if(s > 0)
{
msg[s]='\0';
printf("client# %s\n",msg);
}
else
{
perror("read error");
exit(1);
}
}
if(waitpid(id,0,NULL) != -1)
{
printf("wait success\n");
}
}
return 0;
}
2、命名管道(named pipe)
命名管道FIFO又叫有名管道,和无名管道的主要区别在于,命名管道有一个名字,命名管道的名字对应于一个磁盘索引节点,但没有数据块,有了这个文件名,任何进程有相应的权限都可以对它进行访问。
而无名管道却不同,进程只能访问自己或祖先创建的管道,而不能访任意访问已经存在的管道——因为没有名字。命名管道的出现正好解决了这个问题。FIFO不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存储文件系统中。命名管道是一个设备文件,因此即使进程与创建FIFO的进程不存在亲缘关系,只要可以访问该路径,就能够通过FIFO相互通信。
只是拥有一个名字和相应的访问权限,通过mknode()系统调用或者mkfifo()函数来建立的。一旦建立,任何进程都可以通过文件名将其打开和进行读写,而不局限于父子进程,当然前提是进程对FIFO有适当的访问权。当不再被进程使用时,FIFO在内存中释放,但磁盘节点仍然存在。
可以使用open()函数通过文件名可以打开已经创建的命名管道,而无名管道不能由open来打开。当一个命名管道不再被任何进程打开时,它没有消失,还可以再次被打开,就像打开一个磁盘文件一样。
可以用删除普通文件的方法将其删除,实际删除的事磁盘上对应的节点信息。
命名管道也是半双工的通信方式,命名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int mknod(const char *pathname, mode_t mode, dev_t dev);
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);返回值:都是成功返回0,失败返回-1;
path为创建的命名管道的全路径名;
mod为创建的命名管道的模式,指明其存取权限;
dev为设备值,该值取决于文件创建的种类,它只在创建设备文件时才会用到;
mkfifo函数的作用:在文件系统中创建一个文件,该文件用于提供FIFO功能,即命名管道。
命名管道的特点:
1.命名管道是一个存在于硬盘上的文件,而管道是存在于内存中的特殊文件。所以当使用命名管道的时候必须先open将其打开。
2.命名管道可以用于任何两个进程之间的通信,不管这两个进程是不是父子进程,也不管这两个进程之间有没有关系。
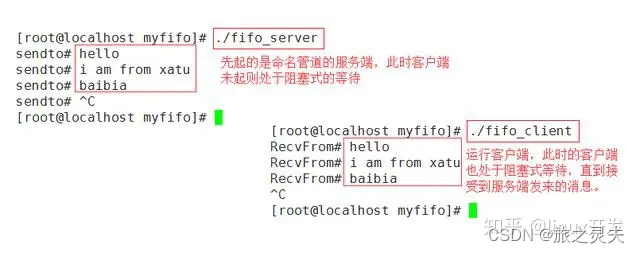
一个简单的关于命名管道的例子:
代码实现如下:
server.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
void testserver()
{
int namepipe=mkfifo("myfifo",S_IFIFO|0666); //创建一个存取权限为0666的命名管道
if(namepipe == -1)
{
perror("mkfifo error");
exit(1);
}
int fd=open("./myfifo",O_RDWR); //打开该命名管道
if(fd == -1){
perror("open error");
exit(2);
}
char buf[1024];
while(1)
{
printf("sendto# ");
fflush(stdout);
ssize_t s=read(0,buf,sizeof(buf)-1); //从标准输入获取消息
if(s > 0)
{
buf[s-1]='\0'; //过滤掉从标准输入中获取的换行
if(write(fd,buf,s) == -1)
{ //把该消息写入到命名管道中
perror("write error");
exit(3);
}
}
}
close(fd);
}
int main()
{
testserver();
return 0;
}client.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
void testclient()
{
int fd=open("./myfifo",O_RDWR);
if(fd == -1)
{
perror("open error");
exit(1);
}
char buf[1024];
while(1)
{
ssize_t s=read(fd,buf,sizeof(buf)-1);
if(s > 0)
{
printf("client# %s\n",buf);
}
else
{ //读失败或者是读取到字符结尾
perror("read error");
exit(2);
}
}
close(fd);
}
int main()
{
testclient();
return 0;
}
3、信号(signal)
信号是一种比较复杂的通信方式,是在软件层次上对中断机制的一种模拟,它是一种异步通信方式(也是进程通信中唯一一个异步的通信方式),也是比较复杂的通信方式,用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上可以说是一致的。
信号可以直接进行用户空间进程和内核进程之间的交互,内核进程也可以利用它来通知用户空间进程发生了哪些系统事件。
如果该进程当前并未处于执行态,则该信号就由内核保存起来,直到该进程恢复执行再传递给它。如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消时才被传递给进程。
用户进程对信号的响应方式主要有三种:
1、忽略信号:就是对信号不做任何处理,但是有两个信号不能忽略:SIGKILL及SIGSTOP。
2、捕捉信号:定义信号处理函数,当信号发生时,执行相应的处理函数。
3、执行缺省操作:Linux对每种信号都规定了默认操作
常用信号有以下几种:
1、SIGHUP:终止信号,该信号在用户终端连接结束时发出,通常是在终端的控制进程结束时,通知同一会话内的各个作业与控制端不再关联;
2、SIGINT:终止信号,该信号在用户输入intr字符,通常是ctrl+c时发出,终端驱动程序发出此信号并送到前台进程中的每一个进程;
3、SIGQUIT:终止信号,该信号和SIGINT信号类似,但是由quit字符,通常是ctrl+\来控制;
4、SIGALRM:闹钟信号,该信号当一个定时器到时的时候发出,收到此信号后定时结束,结束进程;
5、SIGCHLD:忽略信号,子进程状态改变,父进程会收到这个信号
6、SIGKILL:杀死信号,该信号用来立即结束程序的运行,并且不能被阻塞、处理和忽略;
7、SIGFPE:终止信号,该信号在发生比较 严重的算术运算错误时发出;
8、SIGILL:终止信号,该信号在一个进程企图执行一条非法指令时发出,比如可执行文件出现错误堆栈溢出时等等;
信号使用主要有以下几个步骤:
1、在目的进程中安装信号,需要提供一个信号处理函数。
2、信号被某个进程产生。
3、操作系统响应信号,在目的进程中被注册。(信号在目的进程中被注册,操作系统将添加信号到目的进程的PCB的未决信号数据结构中)
4、信号在进程中注销,进程在执行信号处理函数之前,首先要把信号在进程中注销。
5、信号生命终止,保护上下文,进程捕获信号,即执行信号处理函数。
4、消息队列(message queue)
消息队列,就是一个消息的链表,是一系列保存在内核中消息的列表,存放在内核中并由消息队列标识符标识。消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。可以通过发送消息来避免命名管道的同步和阻塞问题。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。
消息队列也克服了管道通信方式中信号量有限的缺点,具有写权限的进程可以按照一定的规则向消息队列中添加新信息;对消息队列有读权限的进程则可以从消息队列中读取信息。
消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
可以把消息看做一个记录,具有特定的格式以及特定的优先级。对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息,对消息队列有读权限的进程可以从消息队列中读取消息。
进程间通过消息队列通信,主要是:创建或打开消息队列,添加消息,读取消息和控制消息队列。
可以使用msgget函数来创建和访问一个消息队列。
int msgctl(int msgid, int command, struct msgid_ds *buf);上面的参数command是将要采取的动作,它可以取3个值:
IPC_STAT:把msgid_ds结构中的数据设置为消息队列的当前关联值,即用消息队列的当前关联值覆盖msgid_ds的值。
IPC_SET:如果进程有足够的权限,就把消息队列的当前关联值设置为msgid_ds结构中给出的值
IPC_RMID:删除消息队列
buf是指向msgid_ds结构的指针,它指向消息队列模式和访问权限的结构。msgid_ds结构至少包括以下成员:
struct msgid_ds { uid_t shm_perm.uid; uid_t shm_perm.gid; mode_t shm_perm.mode; };成功时返回0,失败时返回-1。
5、共享内存(shared memory)
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。共享内存可以说这是最有用的进程间通信方式。
共享内存允许两个或多个进程共享一个给定的存储区,这一段存储区可以被两个或两个以上的进程映射至自身的地址空间中,一个进程写入共享内存的信息,可以被其他使用这个共享内存的进程,通过一个简单的内存读取错做读出,从而实现了进程间的通信。。这种方式需要依靠某种同步操作,如互斥锁和信号量等。其原理可以简单的如下图表示:

采用共享内存进行通信的一个主要好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝,对于像管道和消息队里等通信方式,则需要再内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次:一次从输入文件到共享内存区,另一次从共享内存到输出文件。
一般而言,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时在重新建立共享内存区域;而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件,因此,采用共享内存的通信方式效率非常高。
但是,共享内存也并不完美,共享内存并未提供同步机制,也就是说,在一个服务进程结束对共享内存的写操作之前,并没有自动机制可以阻止另一个进程开始对它进行读取。这明显还达不到我们想要的,我们不单是在两进程间交互数据,还想实现多个进程对共享内存的同步访问,这也正是使用共享内存的窍门所在。
所以,我们通常会用信号量来实现对共享内存同步访问控制。
6、信号量(semaphore)
信号量本质上是一个计数器,它和管道有所不同,它不以传送数据为主要目的,主要作为进程之间及同一种进程的不同线程之间的同步和互斥手段,它常作为一种锁机制,可以用来控制多个进程对共享资源的访问,防止某进程正在访问共享资源时,其他进程也访问该资源,使得资源在一个时刻只有一个进程独享。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
可以这样理解,信号量就相当于是一个计数器。当有进程对它所管理的资源进行请求时,进程先要读取信号量的值:大于0,资源可以请求;等于0,资源不可以用,这时进程会进入睡眠状态直至资源可用。
当一个进程不再使用资源时,信号量+1(对应的操作称为V操作),反之当有进程使用资源时,信号量-1(对应的操作为P操作)。对信号量的值操作均为原子操作。
为什仫要使用信号量?
为了防止出现因多个程序同时访问一个共享资源而引发的一系列问题,我们需要一种方法,它可以通过生成并使用令牌来授权,在任一时刻只能有一个执行线程访问代码的临界区域。
什仫是临界区?什仫是临界资源?
临界资源:一次只允许一个进程使用的资源。
临界区:访问临界资源的程序代码片段。
信号量的工作原理
由于信号量只能进行两种操作等待和发送信号,即P(sv)和V(sv),它们之间的关系如下:
1、P(sv):如果sv的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行
2、V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1.
因为信号量属于临界资源,为了保护临界资源,信号量进行PV操作时都为原子操作。
举个例子,就是两个进程共享信号量sv,一旦其中一个进程执行了P(sv)操作,它将得到信号量,并可以进入临界区,使sv减1。而第二个进程将被阻止进入临界区,因为当它试图执行P(sv)时,sv为0,它会被挂起以等待第一个进程离开临界区域并执行V(sv)释放信号量,这时第二个进程就可以恢复执行了。
7、套接字(socket)
说到socket我们通常想到网络编程。socket即套接字,它是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
前面说到的进程间的通信,所通信的进程都是在同一台计算机上的,套接字socket也是一种进程间通信机制,与其他通信机制不同的是,使用socket进行通信的进程可以是同一台计算机的进程,也是可以是通过网络连接起来的不同计算机上的进程,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
套接字的特性由3个属性确定,它们分别是:域、类型和协议。
1、域
它指定套接字通信中使用的网络介质,最常见的套接字域是AF_INET,它指的是Internet网络。当客户使用套接字进行跨网络的连接时,它就需要用到服务器计算机的IP地址和端口来指定一台联网机器上的某个特定服务,所以在使用socket作为通信的终点,服务器应用程序必须在开始通信之前绑定一个端口,服务器在指定的端口等待客户的连接。另一个域AF_UNIX表示UNIX文件系统,它就是文件输入/输出,而它的地址就是文件名。
2、类型
因特网提供了两种通信机制:流(stream)和数据报(datagram),因而套接字的类型也就分为流套接字和数据报套接字。进程使用流套接字进行通信。
流套接字由类型SOCK_STREAM指定,它们是在AF_INET域中通过TCP/IP连接实现,同时也是AF_UNIX中常用的套接字类型。流套接字提供的是一个有序、可靠、双向字节流的连接,因此发送的数据可以确保不会丢失、重复或乱序到达,而且它还有一定的出错后重新发送的机制。
与流套接字相对的是由类型SOCK_DGRAM指定的数据报套接字,它不需要建立连接和维持一个连接,它们在AF_INET中通常是通过UDP/IP协议实现的。它对可以发送的数据的长度有限制,数据报作为一个单独的网络消息被传输,它可能会丢失、复制或错乱到达,UDP不是一个可靠的协议,但是它的速度比较高,因为它需要总是要建立和维持一个连接。
3、协议
只要底层的传输机制允许不止一个协议来提供要求的套接字类型,我们就可以为套接字选择一个特定的协议。通常只需要使用默认值。
基于流套接字的客户/服务器的工作流程:
首先服务器应用程序用系统调用socket来创建一个套接字,它是系统分配给该服务器进程的类似文件描述符的资源,它不能与其他的进程共享。
接下来,服务器进程会给套接字起个名字,使用系统调用bind来给套接字命名。然后服务器进程就开始等待客户连接到这个套接字。
然后,系统调用listen来创建一个队列并将其用于存放来自客户的进入连接。
最后,服务器通过系统调用accept来接受客户的连接。它会创建一个与原有的命名套接不同的新套接字,这个套接字只用于与这个特定客户端进行通信,而命名套接字(即原先的套接字)则被保留下来继续处理来自其他客户的连接。
基于socket的客户端比服务器端简单,同样,客户应用程序首先调用socket来创建一个未命名的套接字,然后将服务器的命名套接字作为一个地址来调用connect与服务器建立连接。
一旦连接建立,就可以像使用底层的文件描述符那样用套接字来实现双向数据的通信。
参考文章:
进程间通信的7种方式 - 掘金 (juejin.cn)
一文搞懂六大进程通信机制原理(全网最详细) - 知乎 (zhihu.com)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年G3锅炉水处理证模拟考试题库及G3锅炉水处理理论考试试题
- 【Proteus仿真】【51单片机】贪吃蛇游戏-LCD12864
- MacOS安装Miniforge、Tensorflow、Jupyter Lab等(2024年最新)
- R语言生物群落(生态)数据统计分析与绘图实践技术
- 【ARM 嵌入式 编译系列 2.5 -- GCC 编译参数学习 --specs=nano.specs选项 】
- UFW 要点:常见防火墙规则和命令
- 零售业一个逆天新模式,背后这个技术太厉害!
- Spring对事物的支持
- 基于SpringBoot的企业OA管理系统
- 18-冠-6,分子式C12H24O6,分子量264.32,应用:金属离子分离