通用大模型研究重点之二:Model Structure
发布时间:2024年01月24日
AttentionRNN(2014年)

十年前,上面的这篇文章算是为自然语言领域的RNN和Attention奠定了基础,BiRNN1997年,RNN encoder-decoder2014年分别为该论文奠定了基础,在这篇论文中详细阐述了通过软注意力解决对齐问题,也就是硬注意力和软注意力的一个区别,主要作用在隐含层得分问题上的基础研究。大佬之所以是大佬是能对一个现象级问题进行抽象并建模分析,同时先通过定性后定量实现系统性研究,下图是当时大佬们在这项研究中的核心工作。
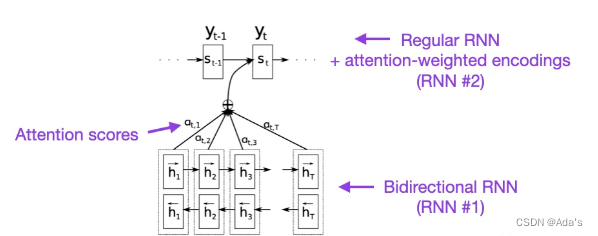
seq2seq(2014)

同样在自然语言处理领域,2014年谷歌提出了seq2seq这种序列化编解码结构,该结构在翻译领域开始迅速爆火。2015年attention正式被提出后,2017年seq2seq+attention进入融合阶段。在该阶段主要工作是通过编码输入序列获取语义信息的编码向量,在解码阶段通过解码得到输出序列,这种阶段还无法解决语义多维空间问题直到embedding方法出现才彻底解决。它的强大是输入和输出可以不一样,融合结果展示如下图。

Transformer(2017)

这篇论文出现,再次证明了大佬们的操作就是朴实无华,大道至简。一个好论文必先有个好名字,当时出现了一堆xxx is all u need。而这篇文章我个人理解最大贡献是通过编解码器思路用多头注意力实现位置时序信息和语义信息同时编码。这样输入的token不仅和它前后位置的内容相关同时关联了整个输入token内容语义,具体实现如下图。
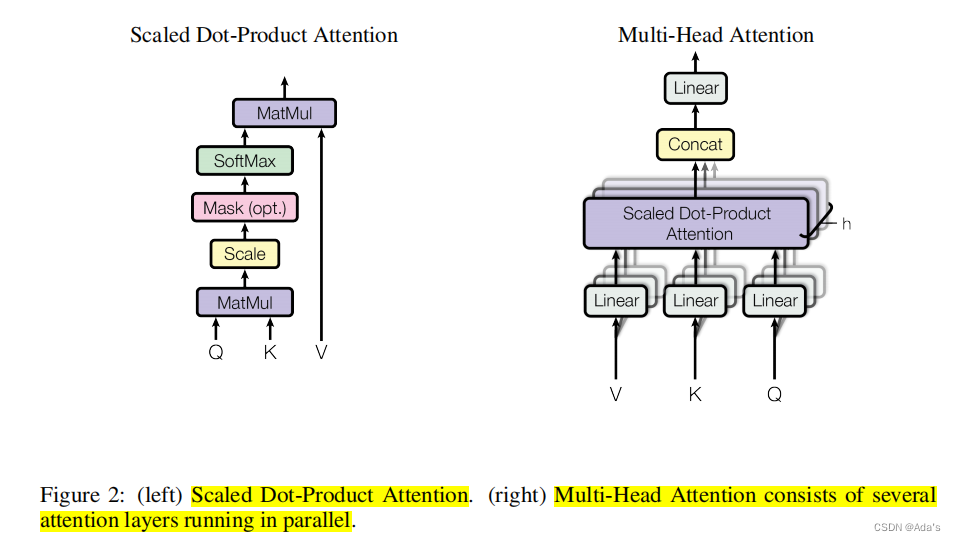
经过我读论文发现它的基线模型应该是ByteNet和ConvS2S。老外写东西就是这么坦率!

BERT
DERT
GPT
GLM
ViT
CLIP & BLIP
SAM
文章来源:https://blog.csdn.net/yunxinan/article/details/135770273
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 白学的小知识[css3轮播]
- java 版本企业招标投标管理系统源码+多个行业+tbms+及时准确+全程电子化
- 呼叫中心研究分析:到2027年市场规模预计将达4966亿美元
- Unity的Camera类——视觉掌控与深度解析(下)
- promise的then
- 设计模式-资源库模式
- etc文件夹下放的什么,有什么作用
- 在腾讯做了4年软件测试,让我见识到了真正的软件测试天花板
- Boost学习之深入理解asio库
- 前端秒杀商品详情显示实现