06.构建大型语言模型步骤
发布时间:2024年01月11日
在本章中,我们为理解LLMs奠定了基础。在本书的其余部分,我们将从头开始编写一个代码。我们将以 GPT 背后的基本思想为蓝图,分三个阶段解决这个问题,如图 1.9 所示。
图 1.9 本书中介绍的构建LLMs阶段包括实现LLM架构和数据准备过程、预训练以创建基础模型,以及微调基础模型以LLM成为个人助理或文本分类器。
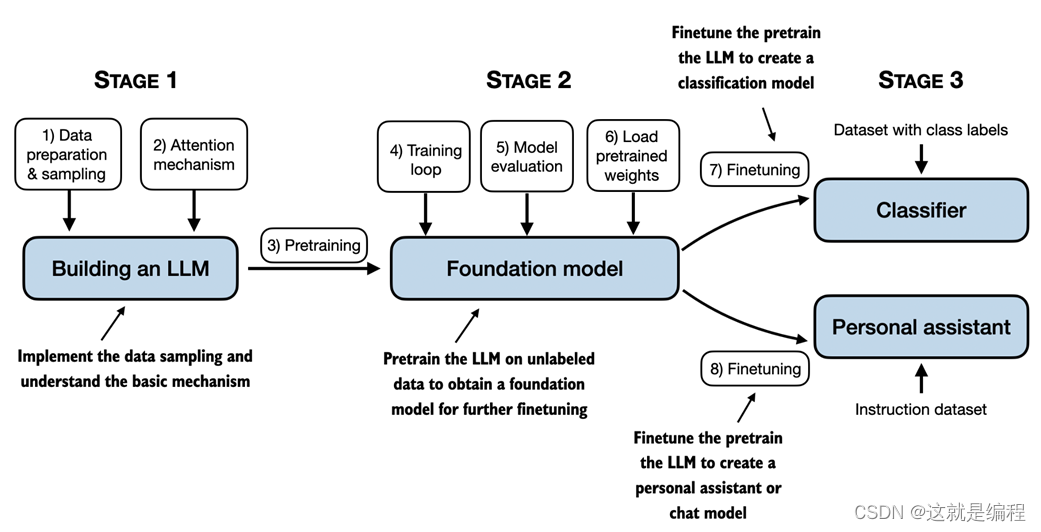
首先,我们将了解基本的数据预处理步骤,并编写每个 LLM.
接下来,在第 2 阶段,我们将学习如何编码和预训练能够生成新文本的类似 LLM GPT。我们还将介绍评估LLMs的基础知识,这对于开发有能力的 NLP 系统至关重要。
请注意,从头开始预训练大型LLM模型是一项艰巨的工作,需要数千到数百万美元的计算成本才能获得类似 GPT 的模型。因此,第 2 阶段的重点是使用小型数据集实施用于教育目的的培训。此外,本书还将提供用于加载公开可用的模型权重的代码示例。
最后,在第 3 阶段,我们将进行预训练LLM并对其进行微调,以遵循回答查询或对文本进行分类等指令——这是许多实际应用和研究中最常见的任务。
LLMs改变了自然语言处理领域,该领域以前依赖于明确的基于规则的系统和更简单的统计方法。LLMs引入了新的深度学习驱动方法,导致了理解、生成和翻译人类语言的进步。
- <
文章来源:https://blog.csdn.net/cq20110310/article/details/135505676
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Proxmox PVE 6.0 升级 6.4
- 《Python》在一行中按照“行下标列下标”(下标从0开始)的格式输出点的位置。如果鞍点不存在,则输出“NONE”
- SpringCloud+Eureka+Nacos使用和扩展
- 面试springcloud知识点
- 在Unity中使用EPPlus库NPOI库写入Excel数据
- 待解决:Unable to load tkdnd library.
- vue3+Element plus实现登录功能
- 平面灯阵中寻找最大正方形边界 - 华为机试真题题解
- K8S---kubectl replace
- win10 golang下载安装,及环境变量配置