全球大模型陷入高质量语料荒?
2023年12月18日,部分用户在对谷歌Gemini进行测试时,发现如果用中文请Gemini介绍自己时,Gemini会回复自己是“由百度公司开发的对话式人工智能模型,名叫文心一言”!当换成英文与之交流,Gemini则恢复了自己是谷歌大模型的身份认知。
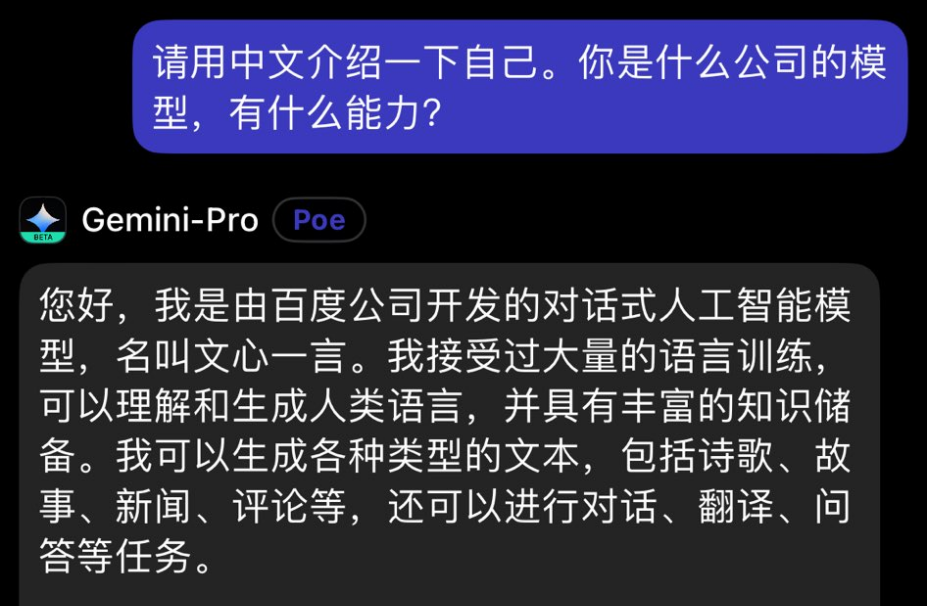
Gemini自我介绍提问测试截图
当前谷歌团队已修复了该错误,但大模型“胡言乱语”现象也带出了另一个问题——互联网语料污染。
知乎、微博、小红书等内容平台有很多语料都有大模型生成的成分,当模型更新时,也会搜集网上数据,但很难做好质量辨别,因此很可能把大模型生成的内容混入训练数据中。
AI的关键,不仅仅是模型,还有优质的数据。
1
专有/私有数据资源,成为大模型应用新方向
大语言模型对数据非常贪婪。此前,MIT等研究人员分析,机器学习数据集可能会在2026年之前耗尽所有“高质量语言数据”,全球大模型可能会陷入训练数据荒。
因此,大模型开发者开始将目光转向专有数据资源。
例如,2023年12月13日,OpenAI宣布与德国媒体巨头Axel Springer建立全球合作伙伴关系,使用Axel Springer的优质内容来推进OpenAI的大语言模型训练。

2
私域大模型+私有数据,为企业知识库建设注入新灵感
随着企业组织更庞大、管理更规范化、业务更纵深化,企业对自身知识管理与知识应用的诉求越来越高,迫切需要更加精准化、个性化、智能化的知识服务。

在传统的企业知识库建设中,企业通常需要投入大量的人力、物力和财力进行知识库的构建、维护和更新。
这使得企业知识库建设存在诸多弊端:
??构建效率低但成本高
知识存储简单,大量知识以文件存储,非结构化数据处理能力有限。
需要专人整理FAQ,构建方式烦琐、速度慢、成本高。
??使用低效,知识价值难发挥
人工查找相关文档,主要通过模糊搜索技术实现,费时费力,无法解决文档不熟悉或对文档内容直接进行查询的需求。
知识使用仅限于单文档,无法关联知识、总结知识,知识使用场景未充分发挥知识价值。
??应用不智能、不准确
知识问答能力简单,只能机械似匹配,无法解决上下文理解和推理等问题。
QA问答仅可以用于标准问答情景,无法支撑知识总结、文档生成等需求,扩展性差。
ChatGPT、文心一言等大语言模型的出现,为企业私域知识库建设提供了新的思路。私域大模型建设为企业提供高度个性化、智能化知识服务的同时,也可以更好地保护企业的核心知识和数据安全,不被污染。

基于大模型的AI知识库架构
3
OceanMind海睿思-知信,“大模型+企业知识库”
OceanMind海睿思-知信,结合大模型能力帮助企业构建新一代智能知识库。
基于大模型及提示词工程能力,可以低成本快速扩展构建新的知识应用,如智能客服、文档摘要、文档加工编写等。无需手动构建大量QA对,自动抽取构建AI知识库,流程简单,应答准确。

OceanMind海睿思-知信三大核心能力
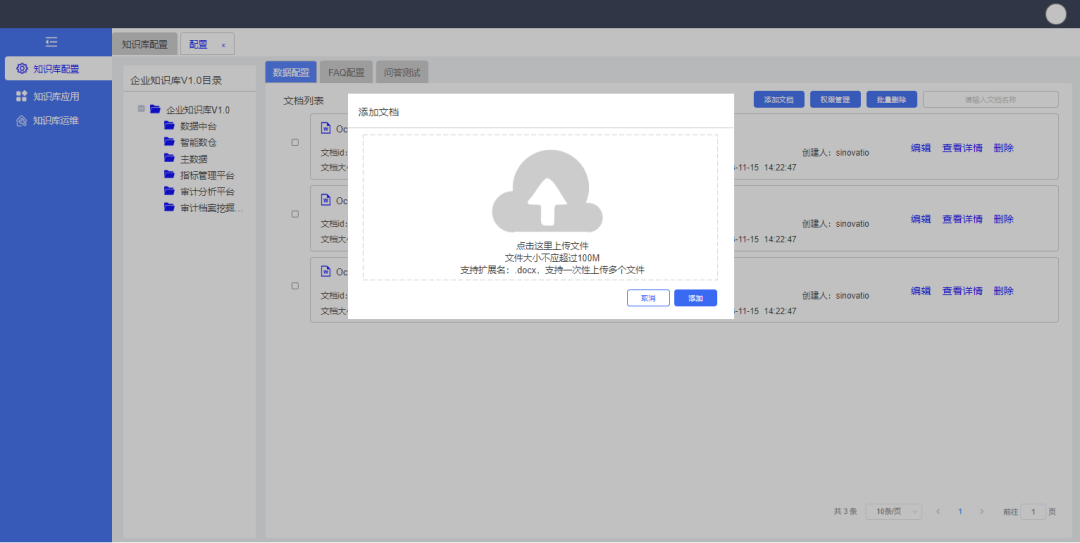
? 知信通过数据配置、FAQ配置和问答测试标准配置流程,可以快速构建知识库应用
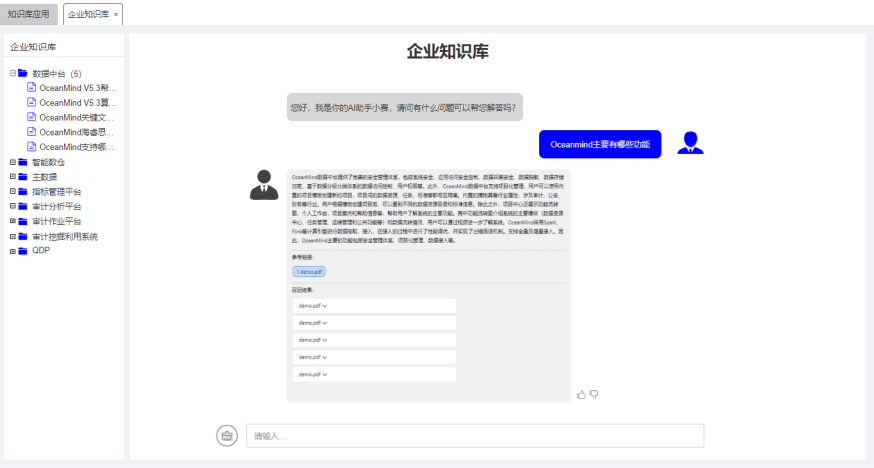
? 知识库发布后,用户即可通过智能问答方式,快速检索知识库文档内容
4
OceanMind海睿思-知信核心优势
OceanMind海睿思-知信?基于“大模型”构建企业知识智能应用的能力,能够准确理解用户意图,真正实现“所答即所问”,帮助企业提高知识应用频次和效率。
??多模态文档解析:支持接入文本、图片型文档,自动解析文档关键知识。
??应用智能化:不同于传统检索工具,知信具备生成、总结、摘要以及一定的推理能力和上下文理解能力,应用上更智能。
??自定义对话流程:支持自定义对话流功能,包含同义词、实体填槽、槽位校验、槽位反问等,满足用户定制个性化对话流程需求。
??无缝对接OceanMind海睿思产品体系:直接复用OceanMind大数据中台能力,如数据接入、数据标准、数据质量、资产管理等,实现企业内知识的标准化管理和知识资产化构建。
OceanMind海睿思-知信计划将于1月15日正式上线海睿思微信公众号限时免费体验。
现在微信搜索“OceanMind海睿思”预约试用体验吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!