正则表达式匹配文件或文件夹路径
发布时间:2024年01月19日
正则表达式
^(?:(?:[a-zA-Z]:|\.{1,2})?[\\/](?:[^\\?/*|<>:"]+[\\/])*)(?:(?:[^\\?/*|<>:"]+?)(?:\.[^.\\?/*|<>:"]+)?)?$
结构如下
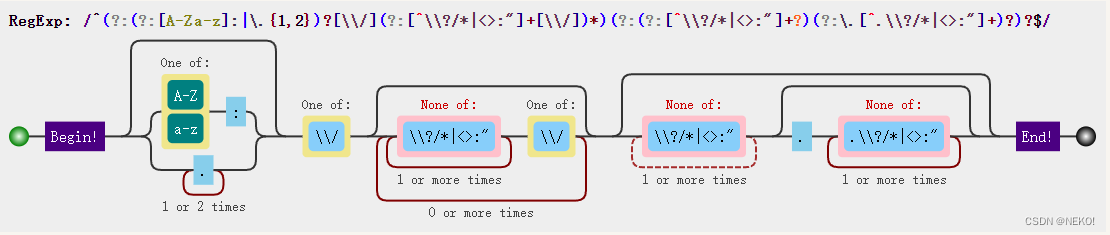
图片为菜鸟正则表达式可视化工具网页截图
可匹配的情况
- 正常Window带卷标的路径和类Unix不带卷标的路径,不区分正反斜线,如下所示
D:\Workspace\sample.txt
D:/Workspace/
D:\
/Workspace/sample.txt
/Workspace
注意无法匹配
D:请使用D:\
- 相对路径
.\Res\map\sample.bin
..\Res\map\
使用时注意事项
正则表达式本身在解析时会对反斜线做一次转义处理,这一次转义是独立于编程语言对反斜线的转义处理的,所以不能直接复制粘贴到代码里,需要做一些处理,简单理解就是正则表达式中每出现一个斜线,代码中就写两个,或者使用编程语言提供的原始字符串功能也可以。下面是一些使用案例:
// C++
// 额外转义
std::regex pattern("^(?:(?:[a-zA-Z]:|\\.{1,2})?[\\\\/](?:[^\\\\?/*|<>:\"]+[\\\\/])*)(?:(?:[^\\\\?/*|<>:\"]+?)(?:\\.[^.\\\\?/*|<>:\"]+)?)?$");
// 原始字符串
std::regex pattern(R"(^(?:(?:[a-zA-Z]:|\.{1,2})?[\\/](?:[^\\?/*|<>:"]+[\\/])*)(?:(?:[^\\?/*|<>:"]+?)(?:\.[^.\\?/*|<>:"]+)?)?$)");
# Python 原始字符串
pattern = r'^(?:(?:[a-zA-Z]:|\.{1,2})?[\\/](?:[^\\?/*|<>:"]+[\\/])*)(?:(?:[^\\?/*|<>:"]+?)(?:\.[^.\\?/*|<>:"]+)?)?$'
文章来源:https://blog.csdn.net/NEKOic/article/details/135700462
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 92. 反转链表 II
- Nginx之Openresty基本使用解读
- 【已更完:函数】【最新!黑马程序员Python自学课程笔记】课上笔记+案例源码+作业源码
- 数据分析的基本步骤
- Linux进程通信之命名管道
- 【Python_PySide2学习笔记(二十一)】输入对话框QInputDialog类的基本用法
- golang协程goroutine教程
- elasticsearch[七]:ES评分规则详解[查询评分规则、自定义评分规则]
- shell(49) : 多个服务器批量设置相互免密
- C++ Web框架Drogon初体验笔记