图像截屏公式识别——LaTeX-OCR安装与使用
一、简介
LaTeX-OCR 是一个开源的光学字符识别(OCR)软件,专为 LaTeX 文档提供支持。其主要目的是帮助用户将扫描的文档转换为 LaTeX 编辑器可以使用的可编辑文本,从而方便进行修改、编辑和排版。LaTeX广泛用于科技、数学、工程等领域的文档编写。而 OCR 技术则用于将图像中的文字转换为计算机可编辑的文本。LaTeX-OCR 的结合使得用户能够更方便地将扫描得到的文档内容转换为 LaTeX 格式,为文档的后续编辑和排版提供了便利。

-
高精度 OCR: LaTeX-OCR采用先进的OCR技术,能够高度准确地识别扫描文档中的字符,并以文本形式输出。这确保了转换后的文本质量,为后续编辑提供了可靠的基础。
-
支持 LaTeX 格式: 该软件专门为LaTeX文档设计,能够保留源文档中的LaTeX语法和格式。这意味着输出的文本与原始LaTeX文档一致,用户无需额外的格式调整。
-
多语言支持: LaTeX-OCR支持多种语言,包括英语、西班牙语、德语、法语等主流语言。这使得它适用于全球范围内的不同语言环境,提高了灵活性和实用性。
-
易于使用: 软件提供直观的用户界面,使用户能够轻松导入扫描文档、选择适当的设置,并以最少的步骤完成OCR过程。用户友好的设计有助于提高效率,降低使用门槛,使更多人能够受益于该工具。
二、环境安装
LaTeX-OCR可以从源码进行安装,也可以直接用pip来安装,源码地址:https://github.com/lukas-blecher/LaTeX-OCR,我这里直接使用pip进行安装,为了方便管理环境,这里使用conda创建虚拟环境。
1.环境安装
conda create -n latex python=3.10
activate latex
pip install "pix2tex[gui]"
2.启动与使用
latexocr
第一次启动的时候,它会去下载两个模型,可能会很慢,等等就可以,如果下载不下来,可以直接去官网下载后,放到指定的目录。

启动完成之后,出现UI交互界面,使用快捷键或者直接点击截屏识别:
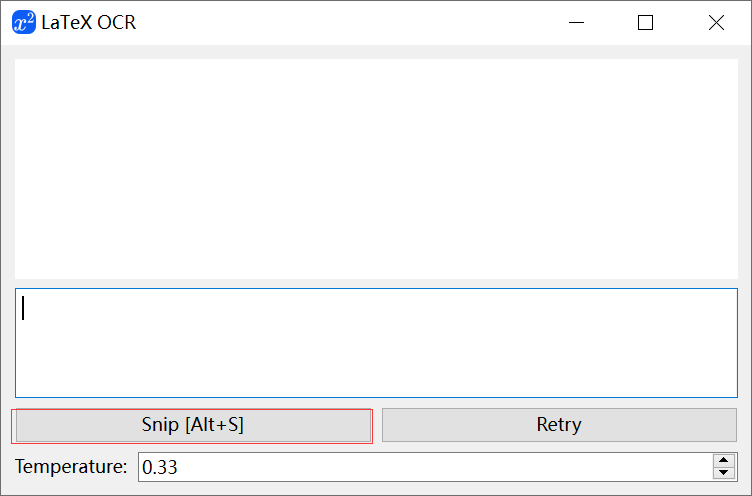
3.识别
识别一个复杂一点的公式,如果识别得不精准,可以自己手动调节Temperature值:

下面是生成的LaTeX 表示方法,把它复制到支持LaTeX 表示方法的编辑器就可以不用那么麻烦自己去输入各种符号了
L I = ? 1 N ∑ i = 1 N ∣ O g exp ? ( s i m ( z i I , z i T ) / τ ) ∑ j = 1 N exp ? ( s i m ( z i I , z j T ) / τ ) L_{I}=-\frac{1}{N}\sum_{i=1}^{N}|_{\mathrm{Og}}\frac{\exp(\mathrm{sim}(z_{i}^{I},z_{i}^{T})/\tau)}{\sum_{j=1}^{N}\exp(\mathrm{sim}(z_{i}^{I},z_{j}^{T})/\tau)} LI?=?N1?∑i=1N?∣Og?∑j=1N?exp(sim(ziI?,zjT?)/τ)exp(sim(ziI?,ziT?)/τ)?
4.代码调用
from PIL import Image
from pix2tex.cli import LatexOCR
img = Image.open('path/to/image.png')
model = LatexOCR()
print(model(img))
作者指出,该模型在较小分辨率的图像上表现最佳。为了提高其效果,添加了一个预处理步骤。在这一步中,另一个神经网络会预测输入图像的最佳分辨率。随后,定制图像会被自动调整大小,以更好地匹配训练数据的特征。这个方法旨在提升模型在真实场景中遇到的图像的性能。然而,需要注意的是,该模型可能不能在处理极大图像时达到最佳效果。因此,在拍摄图片之前,不建议进行过度放大。
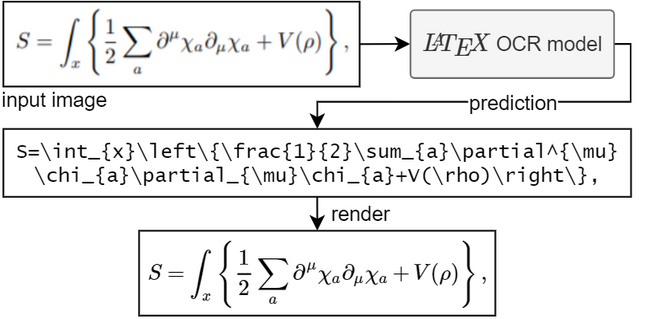
5.处理步骤
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- localhost与127.0.0.1的区别
- 【设计模式详解】探秘解释器模式,掌握解释器模式的艺术及其神奇力量【C++代码实现示例】
- PHP AES 加解密示例
- C语言使用了没定义的变量会有什么现象?
- 金蝶云星空其他出库单,审核中/审批流中可以选择序列号设置
- UE4 4.21使用编辑器蓝图EditorBlueprint方法
- Selenium-java 定位元素时切换iFrame时的方法
- 2024年软件测试基础知识总结
- 防止被坑!明理信息科技知识服务平台教你如何明智选择知识付费平台
- Windows 11 系统 安装MySQL