爬虫之牛刀小试(八):爬取微博评论
发布时间:2024年01月20日
今天爬取的是微博评论。
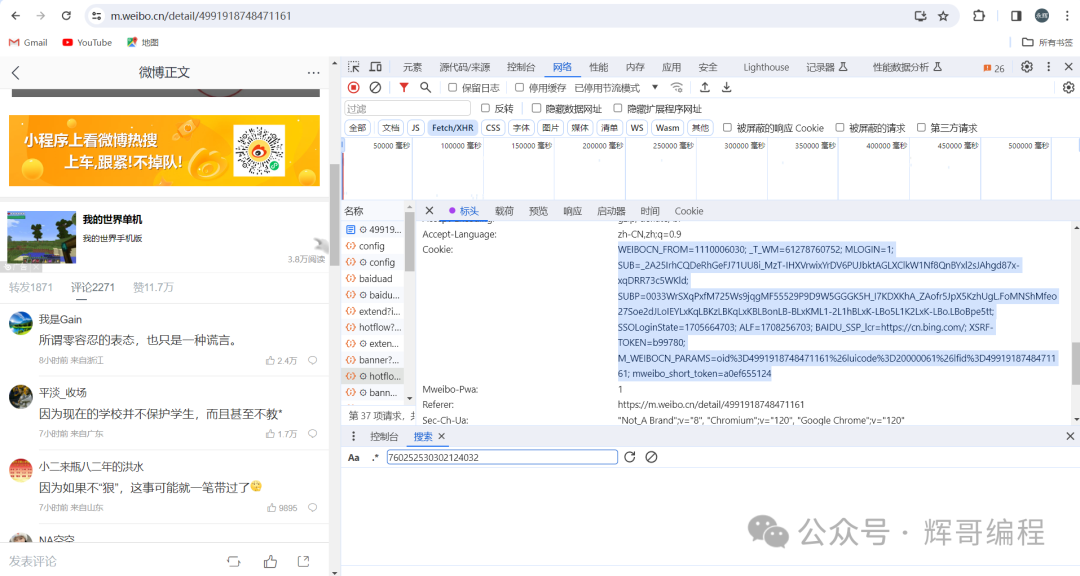
可以发现其特点是下一页评论的max_id在上一页中。

于是代码如下:
import requests
import json
import re
import time
headers = {
'User-Agent': '',
"Cookie": "",
"Referer": "https://m.weibo.cn/detail/4991918748471161"
}
url="https://m.weibo.cn/comments/hotflow?id=4991918748471161&mid=4991918748471161&max_id_type=0"
def get_page(url):
response = requests.get(url, headers=headers)
maxid=response.json()['data']["max_id"]
if response.status_code == 200:
return response, maxid
else:
print("请求失败")
def parse_page(datas):
for data in datas:
item=re.compile(r'<[^>]+>',re.S).sub('',data["text"])
print(item)
print("----------")
def get_url(max_id):
urls=[]
for i in range(1,14):
print("第"+str(i)+"页")
url="https://m.weibo.cn/comments/hotflow?id=4991918748471161&mid=4991918748471161&max_id="+str(max_id)
r=requests.get(url,headers=headers)
max_id=r.json()['data']["max_id"]
datas=r.json()['data']["data"]
parse_page(datas)
time.sleep(1)
print("第"+str(i)+"爬取完毕")
if __name__ == '__main__':
html,max_id = get_page(url)
get_url(max_id)
运行效果:
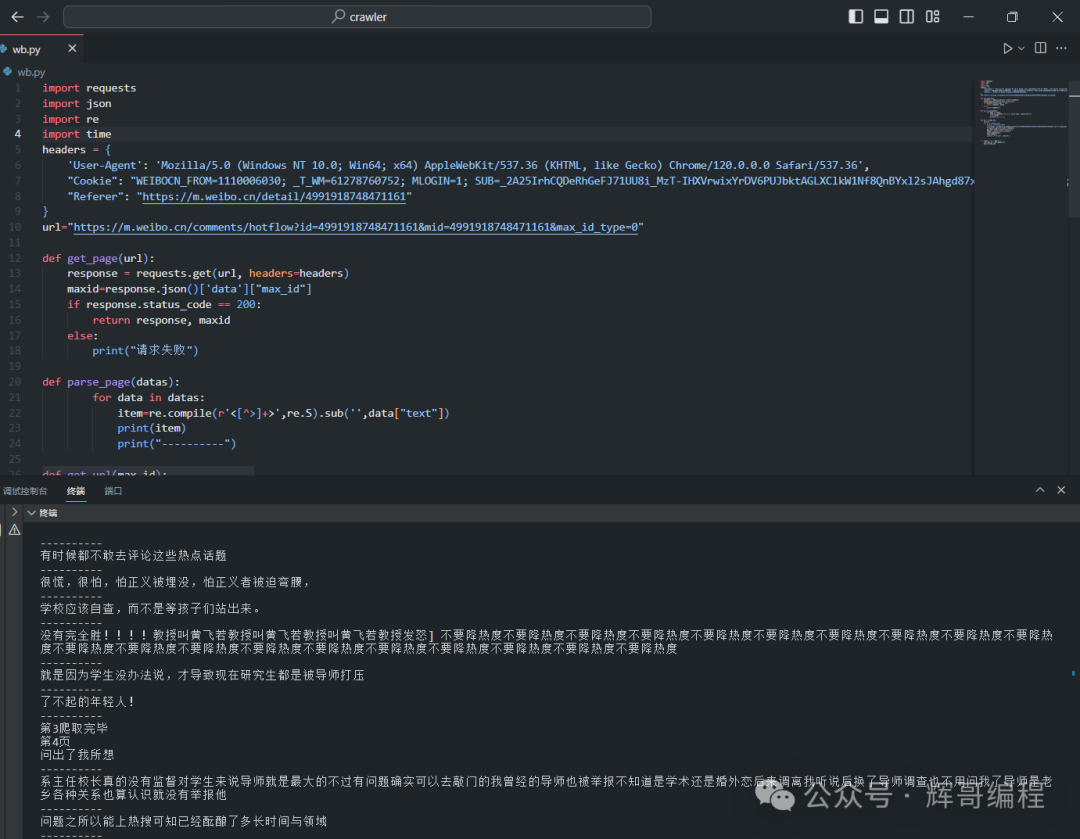
最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135709056
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!