Java基础 - 09 Set之linkedHashSet , CopyOnWriteArraySet
LinkedHashSet和CopyOnWriteArraySet都是Java集合框架提供的特殊集合类,他们在特定场景下有不同的用途和特点。
LinkedHashSet是Java集合框架中的一种实现类,它继承自HashSet并且保持插入顺序。它使用哈希表来存储元素,并使用链表来维护插入顺序。由于使用哈希表,LinkedHashSet提供了常数时间的复杂度(O(1))来执行插入、删除和查找操作。同时,由于使用链表来维护插入顺序,LinkedHashSet可以按照元素的插入顺序进行迭代。因此,LinkedHashSet适用于需要保持插入顺序并且需要高效的插入、删除和查找操作的场景。
CopyOnWriteArraySet是Java并发包中的一种线程安全的Set实现。它实现了Set接口,并且使用了CopyOnWriteArrayList作为内部数据结构。CopyOnWriteArraySet通过在每次修改时创建一个新的副本来实现线程安全性,因此在并发修改操作时不会出现ConcurrentModificationException异常。它适用于读操作频繁、写操作较少的场景,因为每次修改都会创建一个新的副本,可能会带来一定的内存开销。由于CopyOnWriteArraySet是无序的,它不会维护插入顺序。因此,如果需要保持元素的插入顺序,应该使用LinkedHashSet。
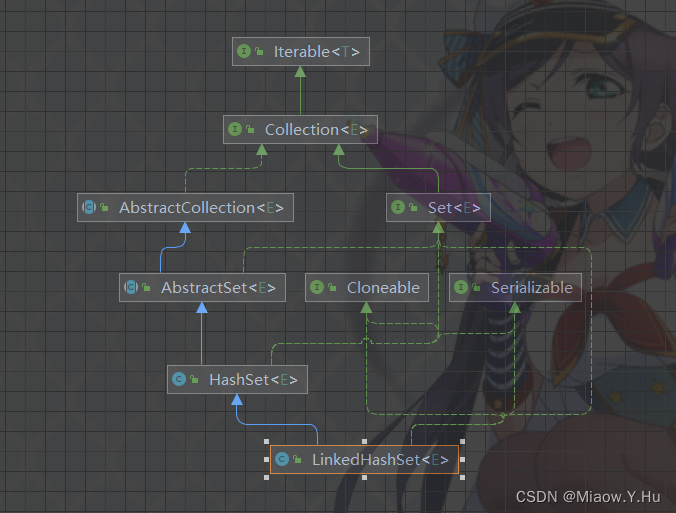
LinkedHashSet
LinkedHashSet是一个基于哈希表和链表实现的有序集合。它继承自HashSet,并且保留了元素插入的顺序。LinkedHashSet通过哈希表快速访问元素,同时使用链表维护元素的顺序。这使得LinkedHashSet在需要保持元素顺序的情况下更加适用。
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
// 添加元素
set.add("apple");
set.add("banana");
set.add("orange");
// 迭代元素,按照插入顺序输出
for (String fruit : set) {
System.out.println(fruit);
}
}
源码:
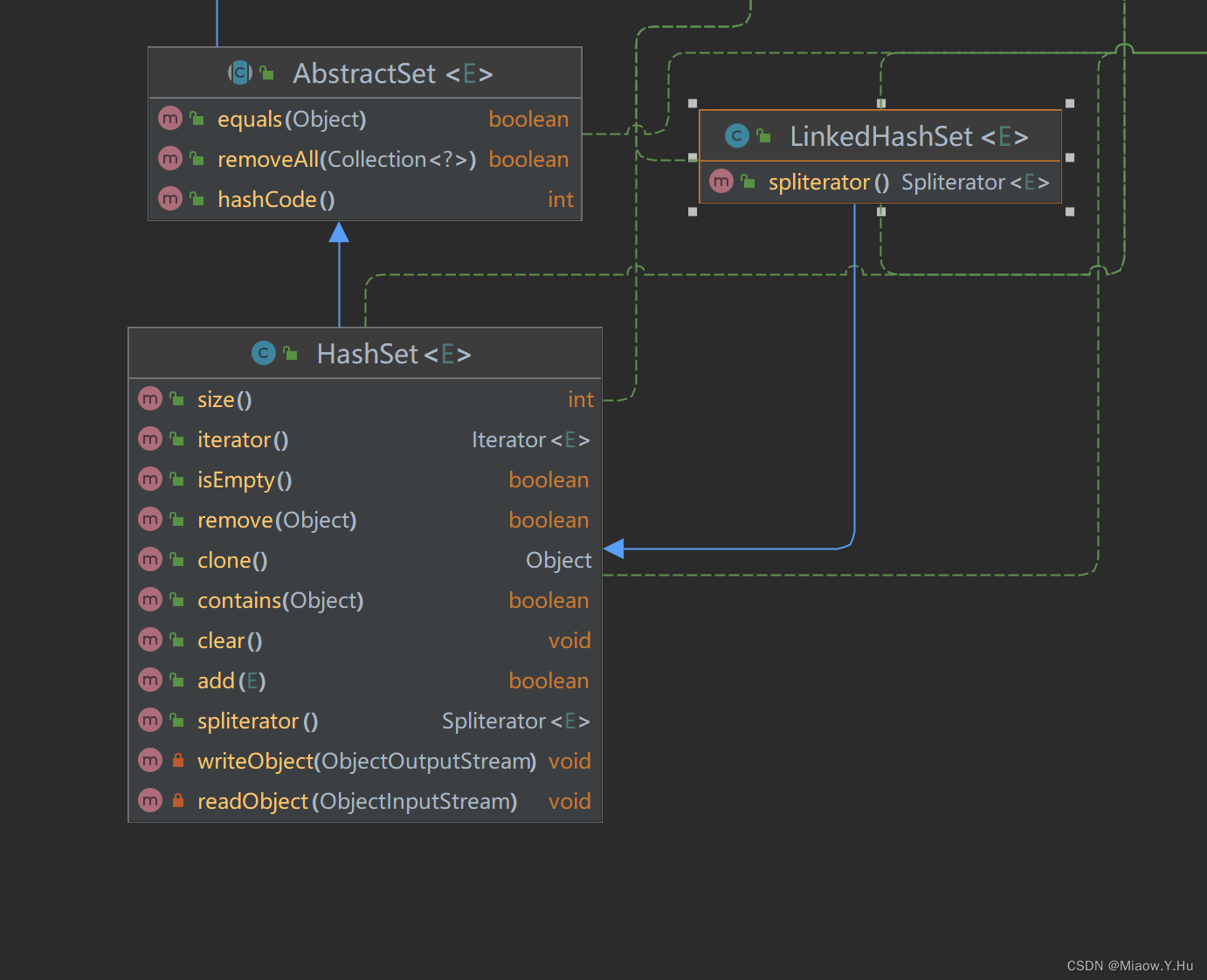
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
/**
* 构造一个带默认初始容量 (16) 和加载因子 (0.75) 的新空链接哈希 set。
*/
public LinkedHashSet() {
super(16, .75f, true);
}
/**
* 构造一个与指定 collection 中的元素相同的新链接哈希 set。
*/
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
/**
* 构造一个带指定初始容量和默认加载因子 (0.75) 的新空链接哈希 set。
*/
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
/**
* 构造一个带有指定初始容量和加载因子的新空链接哈希 set。
*/
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
}
以下是一些LinkedHashSet的特点和用途:
- LinkedHashSet保留了元素插入的顺序,因此可以按照插入顺序进行迭代。
- LinkedHashSet是线程不安全的,不适用于多线程环境。
- LinkedHashSet具有HashSet的高效查找特性,同时还可以保持元素的顺序。
- LinkedHashSet的插入、删除和查找操作具有常数时间复杂度。
CopyOnWriteArraySet
CopyOnWriteArraySet是一个线程安全的集合类,它实现了Set接口,并且内部使用了Copy-On-Write技术。Copy-On-Write是一种并发策略,它在写操作时创建并复制整个集合,这样读操作不会受到写操作的影响。因此,CopyOnWriteArraySet非常适合用于读多写少的场景。
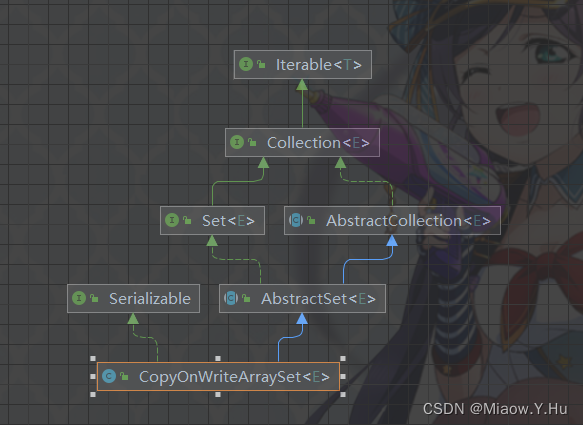
以下是一些CopyOnWriteArraySet的特点和用途:
- CopyOnWriteArraySet是线程安全的,适用于多线程环境。
- CopyOnWriteArraySet的迭代操作不需要加锁,并且不会抛出ConcurrentModificationException异常。
- CopyOnWriteArraySet的写操作会复制整个集合,因此在写操作频繁的情况下,性能可能较低。
- CopyOnWriteArraySet的读操作具有较低的性能开销。

内部方法介绍 add(E e): 向集合中添加指定元素。该方法会创建一个新的数组,并将指定元素添加到新数组中。remove(Object o): 从集合中移除指定元素。该方法会创建一个新的数组,并将除指定元素之外的所有元素添加到新数组中。contains(Object o): 判断集合中是否包含指定元素。该方法会遍历内部的数组,判断是否有相等的元素。isEmpty(): 判断集合是否为空。该方法会判断内部的数组是否为空。size(): 返回集合的大小,即元素的个数。该方法会返回内部数组的长度。iterator(): 返回一个迭代器**,用于遍历集合中的元素**。该方法返回的迭代器是通过拷贝内部数组创建的,因此不会受到集合修改的影响。toArray(): 将集合中的元素转换为数组,并返回该数组。该方法会创建一个新的数组,并将集合中的元素复制到新数组中。
两者直接的区别
CopyOnWriteArraySet
CopyOnWriteArraySet适用于读多写少的并发场景。它通过使用Copy-On-Write技术,在写操作时创建并复制整个集合,这样读操作不会受到写操作的影响。这使得CopyOnWriteArraySet在多线程环境下具有较好的安全性,读操作不需要加锁,并且不会抛出ConcurrentModificationException异常。因此,当需要在多线程环境下进行读操作较多的场景时,可以使用CopyOnWriteArraySet。
import java.util.concurrent.CopyOnWriteArraySet;
public class CopyOnWriteArraySetExample {
public static void main(String[] args) {
CopyOnWriteArraySet<String> set = new CopyOnWriteArraySet<>();
// 添加元素
set.add("apple");
set.add("banana");
set.add("cherry");
// 遍历元素
for (String element : set) {
System.out.println(element);
}
// 删除元素
set.remove("banana");
// 判断元素是否存在
boolean contains = set.contains("cherry");
System.out.println("Contains 'cherry': " + contains);
// 获取集合大小
int size = set.size();
System.out.println("Size: " + size);
}
}
LinkedHashSet
LinkedHashSet是HashSet的一个子类,它维护了一个双向链表来保持元素的插入顺序。LinkedHashSet适用于需要保持元素插入顺序的场景。它提供了HashSet的高性能查找和插入操作,并且使用链表来保持插入顺序。因此,当需要在保持插入顺序的同时进行高效的查找和插入操作时,可以使用LinkedHashSet。
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
// 添加元素
set.add("apple");
set.add("banana");
set.add("cherry");
// 遍历元素
for (String element : set) {
System.out.println(element);
}
// 删除元素
set.remove("banana");
// 判断元素是否存在
boolean contains = set.contains("cherry");
System.out.println("Contains 'cherry': " + contains);
// 获取集合大小
int size = set.size();
System.out.println("Size: " + size);
}
}
在多线程环境下,CopyOnWriteArraySet比LinkedHashSet具有更好的安全性。CopyOnWriteArraySet的读操作不需要加锁,并且不会抛出ConcurrentModificationException异常。而LinkedHashSet在多线程环境下需要使用外部同步机制来确保线程安全。例如,可以使用Collections.synchronizedSet()。
创建一个多线程环境下使用LinkedHashSet的示例
public class LinkedHashSetThreadSafetyExample {
public static void main(String[] args) {
Set<String> set = Collections.synchronizedSet(new LinkedHashSet<>());
// 创建多个线程来同时对set进行操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
set.add("Thread 1 - Element " + i);
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
set.add("Thread 2 - Element " + i);
}
});
// 启动线程
thread1.start();
thread2.start();
try {
// 等待线程执行完毕
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 输出set的元素数量
System.out.println("Set size: " + set.size());
}
}
在上述代码中,我们创建了一个多线程环境下使用LinkedHashSet的示例。首先,我们使用Collections.synchronizedSet()方法创建了一个线程安全的Set,即使用外部同步机制来确保线程安全。然后,我们创建了两个线程thread1和thread2,分别向set中添加1000个元素。最后,我们使用thread1.join()和thread2.join()方法等待两个线程执行完毕,然后输出set的元素数量。
使用CopyOnWriteArraySet类来实现多线程安全的Set。
import java.util.concurrent.CopyOnWriteArraySet;
public class CopyOnWriteArraySetThreadSafetyExample {
public static void main(String[] args) {
CopyOnWriteArraySet<String> set = new CopyOnWriteArraySet<>();
// 创建多个线程来同时对set进行操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
set.add("Thread 1 - Element " + i);
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
set.add("Thread 2 - Element " + i);
}
});
// 启动线程
thread1.start();
thread2.start();
try {
// 等待线程执行完毕
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 输出set的元素数量
System.out.println("Set size: " + set.size());
}
}
在上述代码中,我们使用CopyOnWriteArraySet类来实现多线程安全的Set。CopyOnWriteArraySet是一个线程安全的Set实现,通过在每次修改时创建一个新的副本来实现线程安全性。这意味着在并发修改操作时,不会发生ConcurrentModificationException异常。
我们创建了一个CopyOnWriteArraySet对象,然后创建了两个线程thread1和thread2,分别向set中添加1000个元素。最后,我们使用thread1.join()和thread2.join()方法等待两个线程执行完毕,然后输出set的元素数量。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 自然语言处理(NLP)
- 40岁以上的程序员创业适合做什么类型
- 数据安全保障的具体措施有哪些
- 亚马逊云科技Lightsail VPS:优化、安全与实战,一个都不能少
- 递归实现n的k次方
- 代码随想录训练营第二十天打卡|654.最大二叉树 617.合并二叉树 700.二叉搜索树中的搜索 98.验证二叉搜索树
- Linux文件隐藏属性及chattr和lsattr命令
- LeeCode 438.找到字符串中所有字母异位词.
- Python实现多元线性回归模型信用卡客户价值预测项目源码+数据+项目设计报告
- Kubernetes之Pod健康检查