[PyTorch][chapter 9][李宏毅深度学习][CNN]
前言:
? ? ? ? ? 卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。卷积神经网络的创始人是着名的计算机科学家Yann LeCun,目前在Facebook工作,他是第一个通过卷积神经网络在MNIST数据集上解决手写数字问题的人.
? ? ? ?CNN 除了在图像分类,还有一些其它有趣的创意方案:
? ? ? ? 语音识别,风格迁移,DeepDream,围棋游戏方面的应用场景。
目录:
- ? ? 卷积神经神经网络架构
- ? ? 卷积层
- ? ?池化层
- ? ?Flatten?
- ? ?全连接层
- ? ?梯度更新常用方案
- ? ?卷积层
- ? ?基于CNN的创意应用
- ? ?PyTorch? 模型搭建
一? 卷积神经网络的架构
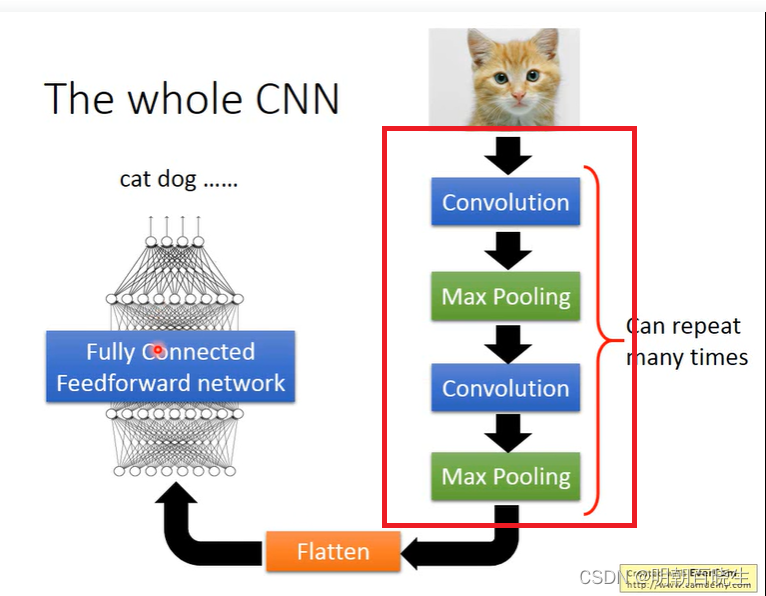
?卷积神经网络主要由五个部分组成:
| Input layer | 输入层 |
| ?CONV layer | 卷积层: 多个反复叠加 |
| Pooling layer | 池化层 :? 多个反复叠加 |
| Flatten? | ?张量展平 |
| FC layer | 全连接层 |
CNN 相对FC 网络主要引入了下面三个思想:
1.1: 局部采样
? ? ? A neuron does not have to see the whole image to?
? ? ? discover the pattern
? ? 采样输入图像的时候,不需要查看整个图像.
? ? 比如:一个神经元要实现识别鸟嘴功能,只需要每次采样局部图样处理

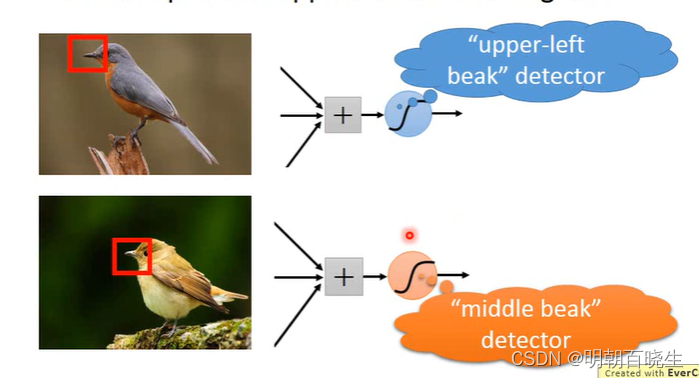
1.2: 权值共享
? ? ? ?the same pattern appear in different regions
? ? ? 针对不同的采样区域使用同一个卷积核
? ? ?例: 如下图,鸟嘴在不同的位置,每次采样不同的位置的图片时候,我们使用同一组卷积核
提取其鸟嘴特征。
? ?
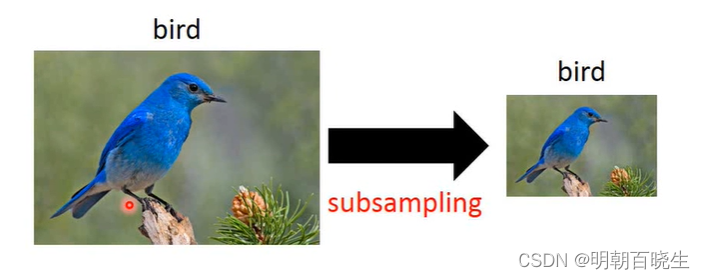
1.3? 池化思想?
? ? subsampling the pixels will not change the object
? ? 降采样图像不会改变图片形状,降低了计算量
? ?
二? 卷积层(Convolution)
? ?2.1 原理?:
? ? ? ? ?通过循环移动卷积核矩阵Filter, 提取图像的特征。
卷积核是通过训练学习出来的,有很多个.不同的卷积核可以
提取不同的图像纹理特征.?经过卷积后得到图像的称为feature map
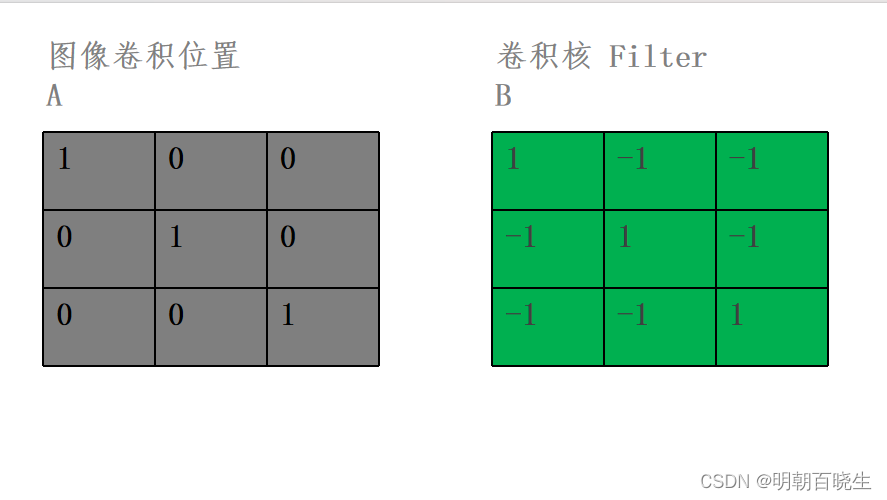
? ? ?2.2例子:
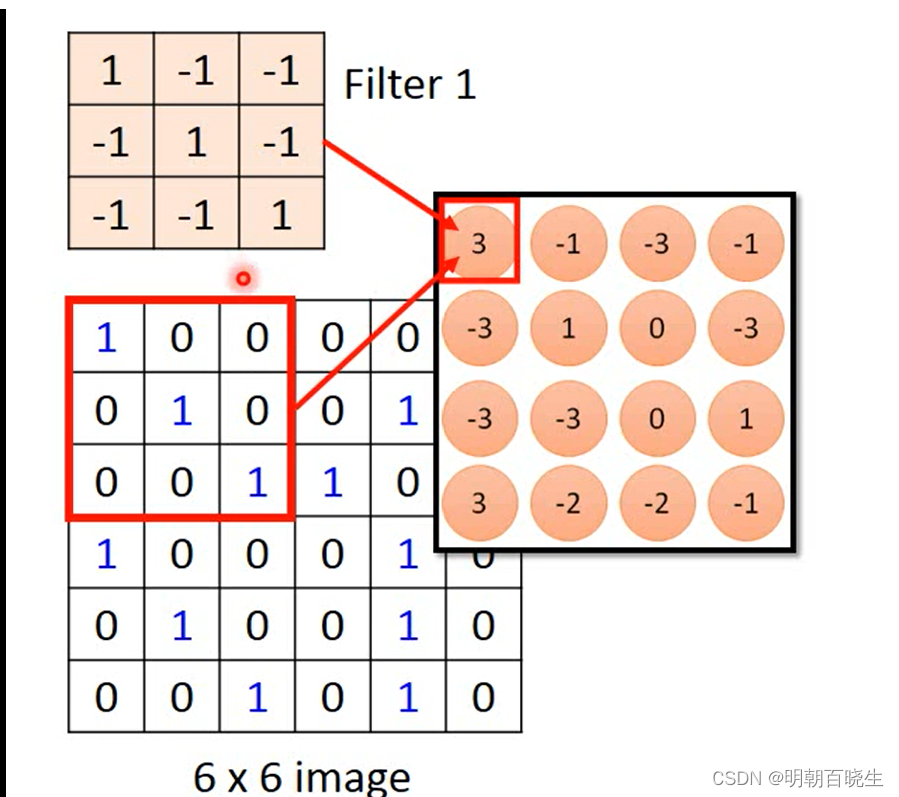
? 通过滑动移动卷积核,跟对应图像位置的矩阵 做 点积,求和.
?
?k: kernel_size 卷积核大小
? p:? padding? 填充
?H: 原图像的宽或者高
? s: stride 滑动步长
? 通过卷积后得到的新的尺寸为:
? ?
可以通过pytorch API? 直接计算
# -*- coding: utf-8 -*- """ Created on Sun Dec 31 17:04:34 2023 @author: cxf """ import torch import torch.nn as nn def CNN(): conv_layer = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride =1, padding=0, bias=False) print("\n default conv kernel:", conv_layer.weight.shape) conv_layer.weight = torch.nn.parameter.Parameter(torch.tensor([[[[1,-1,-1], [-1,1,-1], [-1,-1,1]] ]]).float(), requires_grad=True) print("\n weidht",conv_layer.weight.shape) image = torch.tensor( [[[1,0,0,0,0,1], [0,1,0,0,1,0], [0,0,1,1,0,0], [1,0,0,0,1,0], [0,1,0,0,1,0], [0,0,1,0,1,0]]] ,dtype= torch.float ) feature = conv_layer(image) print("\n res",feature) CNN()- in_channels 是指输入特征图的通道数,数据类型为 int
- out_channels 是输出特征图的通道数,数据类型为 int,
- kernel_size 是卷积核的大小,数据类型为 int 或 tuple
- stride 滑动的步长,数据类型为 int 或 tuple,默认是 1,在。
- padding 为补零的方式,注意当 padding 为’valid’或’same’时,stride 必须为 1。
三 池化(Max-Pooling)
? ? 3.1 原理
? ? ? 我们得到feature map 后对里面的元素进行分组,每一组取最大值.
那反向传播算法的时候,如何求微分呢
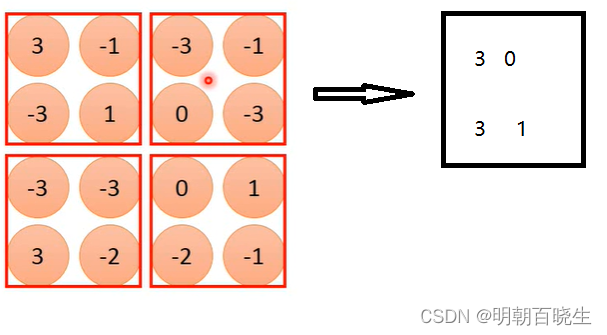
3.2? Max-pooling 微分原理:
? ? 以下面方案为例:

? ?3.1? 输入
? ? ? ? ? ?
? ? 3.2? ?神经元输入(每层):
? ? ? ? ? ? ??
? ? ? ? ? ? ?
? ? ? ? ? ??
? ? ? ? ? ??
? ? ? ? ? ??
? ? ? ? ?
3.3? 分组(Max-pooling)
? ? ? ? ?每层中
? ? ? ? ? ? ??分为一组
? ? ? ? ? ? ??分为一组
3.4? 神经元输出?分组(Max-pooling)
? ? ? ? ?
? ? ? ? ?
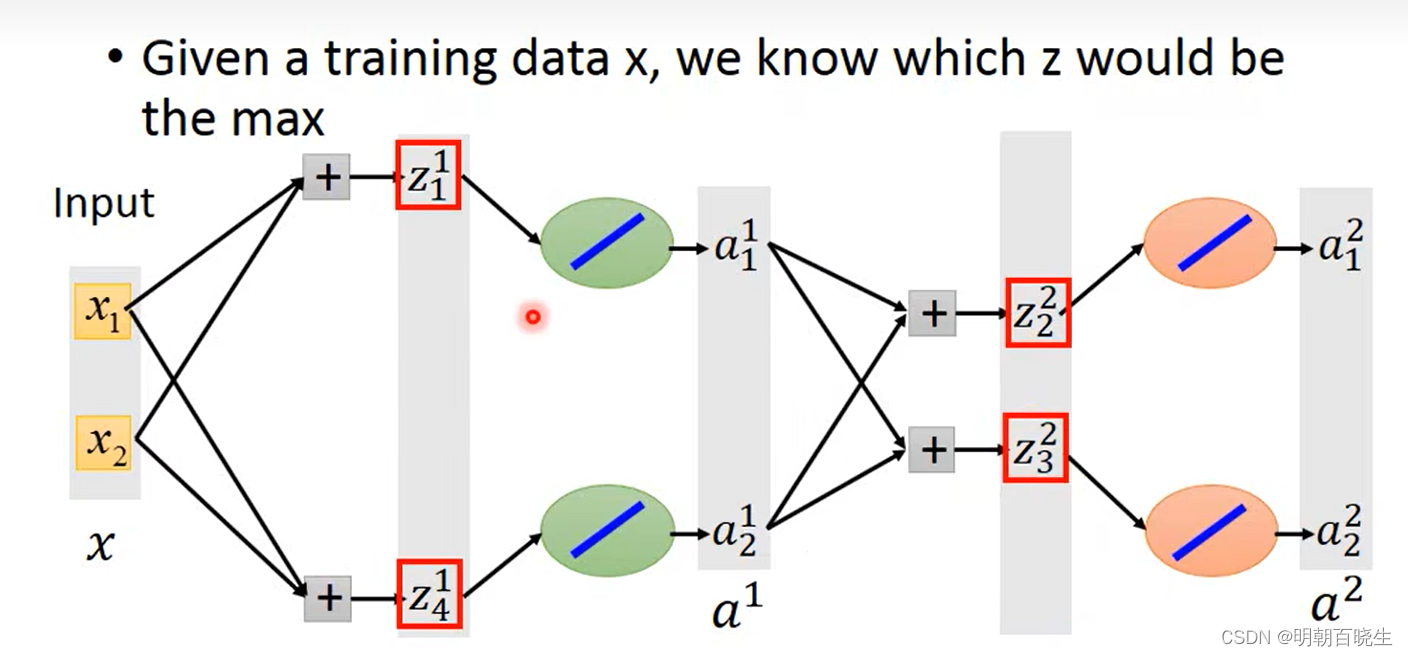
? 如下图,假设红色部分为最大值,在反向传播的时候只会更新
?对应的权重系数梯度,作用跟relu 一样.
当输入不同的时候,就会训练到不同的参数
?
四? Flatten
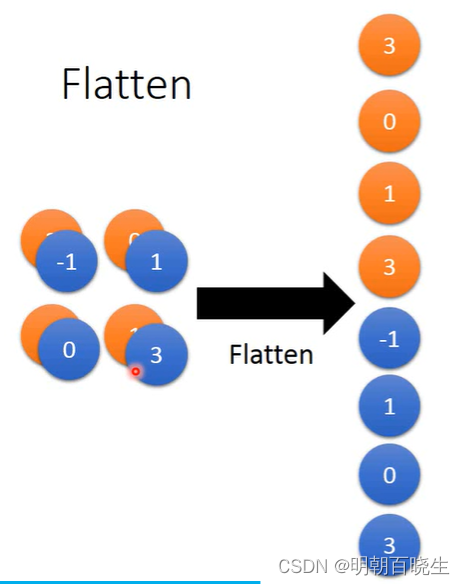
? 作用:
? 把经过多次 卷积,池化得到的特征图 进行拉直.
import torch
batch_size = 10
width = 5
height =5
a = torch.randn((batch_size,width,height))
b = torch.flatten(a, start_dim=1,end_dim=-1)
print(b.shape)? ?
?五? 全连接层
? ??全连接层,是每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
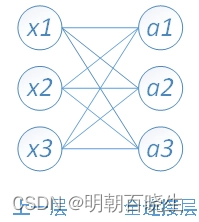
? 原理跟前面讲过的DNN是一样的
六 梯度更新常用方案
? ? ?6.1 Adagrad
? ? ? ? ?AdaGrad,全称Adaptive Gradient,又叫自适应梯度算法,是一种具有自适应学习率的梯度下降优化方法。
? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ?
优点
① 避免手动去调整学习率
② 他可以自动的为每个参数单独设置学习率,这样梯度较大的参数学习率较小,更新减慢,梯度较小的参数学习率较大,更新加速。在梯度图上可以解释为更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小)
缺点① 由于学习率分母中的?
?是历史梯度值平方的累加,因此随着迭代次数的增加,分母会越来越大,学习率衰减的速度会越来越快,学习率会越来越小甚至接近于0,因此AdaGrad迭代后期的学习率非常小,而非常容易出现梯度消失现象。
6.2 RMSProp
? ? ??RMSProp全称为Root Mean Square Propagation,是一种未发表的自适应学习率方法,由Geoff Hinton提出,是梯度下降优化算法的扩展
? ? ? ? ? ? ?
? ? ? ? ? ? ??
6.3 momentum
? ? ? 计算t时刻的梯度?
? ? ? ?
? ? ??
七? ?卷积核提取了什么特征
? ? 我们知道一个神经网络读入一张图片,通过多层网络,最后输出一个分类的结果,但是我们仅仅知道一个结果并不够,神经网络的一个挑战是要理解在每一层到底都发生了什么事。
? ? 1? 我们知道经过训练之后,每一层网络逐步提取越来越高级的图像特征,直到最后一层将这些特征比较做出分类的结果。比如前面几层也许在寻找边缘和拐角的特征,中间几层分析整体的轮廓特征,这样不断的增加层数就可以发展出越来越多的复杂特征,最后几层将这些特征要素组合起来形成完整的解释,这样到最后网络就会对非常复杂的东西,比如房子,小猫等图片有了反应。
? ? ?2? 为了理解神经网络是如何学习的,我们必须要理解特征是如何被提取和识别的,如果我们分析一些特定层的输出,我们可以发现当它识别到了一些特定的模式,它就会将这些特征显著地增强,而且层数越高,识别的模式就越复杂。当我们分析这些神经元的时候,我们输入很多图片,然后去理解这些神经元到底检测出了什么特征是不现实的,因为很多特征人眼是很难识别的。一个更好的办法是将神经网络颠倒一下,不是输入一些图片去测试神经元提取的特征,而是我们选出一些神经元,看它能够模拟出最可能的图片是什么,将这些信息反向传回网络,每个神经元将会显示出它想增强的模式或者特征。
? 常用方案如下:
?
? 7.1? 看卷积核
? ? ?可以直接查看第一层卷积核的参数,以图片的形式显示出来.如下图AlexNet
可以看到不同的卷积核在提取不同的特征.
? ?1? 使用浅层的神经网络将获得浅层的特征(边缘,圆形,颜色),如下图ResNet50?

? 2 使用高层的神经网络将获得深层的特征,如下图

7.2? 可以把卷积核提取的特征图片直接放在神经元里面,聚类.

7.3:ak响应
? ?假设经过卷积核处理后得到一张feature map
?对该feature map 里面相加求和得到 。
? 我们输入不同的图片得到不同的,求其最大值
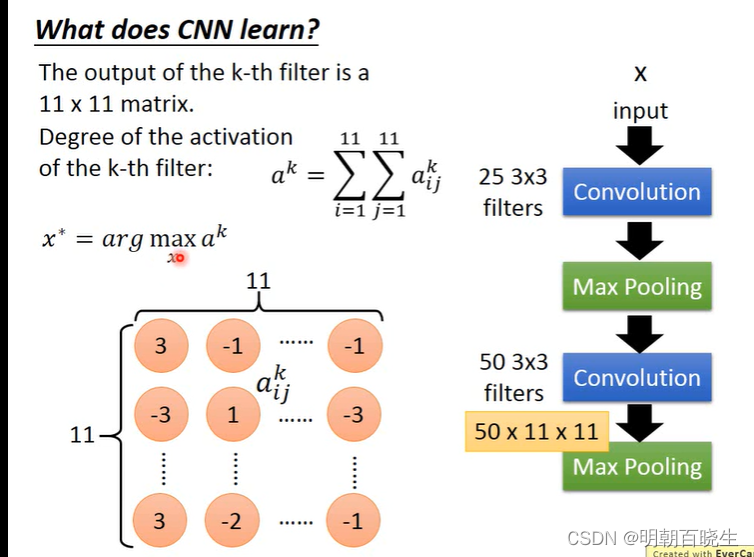
通过下面实验可以看到不同的filter 可以侦测不同的纹理特征


? ?
八? 基于CNN 的创意模型??
8 .1 Deep Dream
? ? ? 2015年Google发布了一个很有意思的东西,叫做Deep Dream使用了梯度上升算法,通过随机生成的噪声或者提供的图片生成一张怪异的图片,输入图requires_grad = True,
? ? ? 损失函数跟一般的神经网络不同
? ?图像在选定层上面的输出响应,要使得这些响应最大化.
? ?loss_component = torch.nn.MSELoss(reduction='mean')(layer_activation, torch.zeros_like(layer_activation))
? ? ? ? losses.append(loss_component)? ? loss = torch.mean(torch.stack(losses))
? ? loss.backward()

具体可以参考:?deep_dream_static_image 函数
GIt hub 参考代码:
GitHub - gordicaleksa/pytorch-deepdream: PyTorch implementation of DeepDream algorithm (Mordvintsev et al.). Additionally I've included playground.py to help you better understand basic concepts behind the algo.?GitHub - hjptriplebee/deep_dream_tensorflow: An implement of google deep dream with tensorflow
8.2 Deep Style
? ? ? ? ? ? ?Style Transfer是CNN的一個應用,在2015年 Gatys 等人發表的?A Neural Algorithm of Artistic Style中,採用了VGG的模型來對原圖(original image)及風格圖(style image)提取特徵,來實施將一張照片轉換成另一張圖的風格或是畫風,來生成一張新的圖片,讓它同時擁有原圖(original image)的內容以及風格圖(style image)的風格。

步骤: VGG 去掉后面的全连接部分
- 生成目标图片:先将内容图和风格图输入"喂给"VGG,然后生成目标内容图和目标风格图(仅一次输入),用作后面Loss的计算。
- 初始化合成图片:这里内容图上添加白噪声的方式来初始化合成图,我们将白噪声图片"喂给"VGG,就得到了合成图片。
- 载入预训练模型:Content信息捕捉,得到content loss,Style信息捕捉,得到style loss
- 计算总Loss值:这里我们分别采用内容损失+风格损失得出总的loss,两者配置一定权值
- 优化函数:这里优化函数采用AdamOptimizer
- 训练模型
详细参考:?https://www.cnblogs.com/yifanrensheng/p/12547660.html
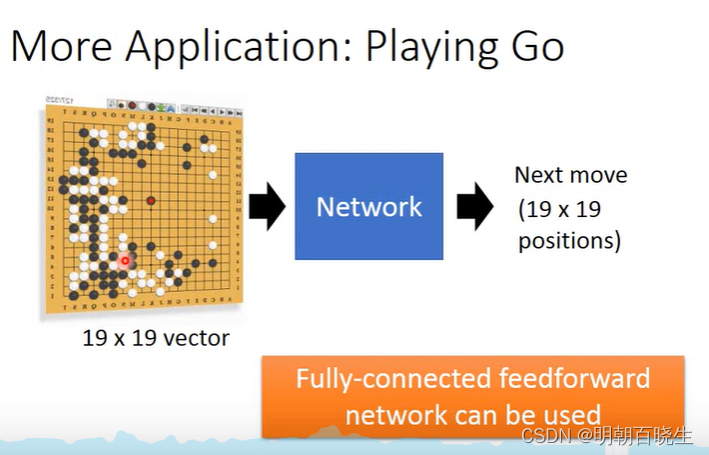
8.3 围棋

8.4 语音辨识

? ? 语音做傅里叶变换后,横向为时间,纵向为频率.
可以进行语音文字识别处理.
?
九? LeNet5 手写数字简单模型搭建?


# -*- coding: utf-8 -*-
"""
Created on Tue Jan 2 16:59:55 2024
@author: chengxf2
"""
import torch
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
#特征提取
self.layer1 =nn.Sequential(
nn.Conv2d(in_channels = 1, out_channels =6, kernel_size=5, stride=1 ,padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride =2),
nn.Conv2d(in_channels = 6, out_channels =16, kernel_size=5, stride=1 ,padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride =2)
)
# fully layer
self.layer2 =self.classifier = nn.Sequential(
# FC1层,输入为5*5*16=400,输出数为指定的参数值
nn.Linear(in_features=400, out_features=120),
nn.ReLU(),
# FC2 层
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
# FC3 层
nn.Linear(in_features=84, out_features=10)
)
def forward(self, x):
#前向传播
x = self.layer1(x)
print("\n 卷积 池化后输出 ",x.shape)
x = torch.flatten(x,1)
print("\n flatten 后输出 ",x.shape)
out = self.layer2(x)
return out
if __name__ == "__main__":
model = LeNet()
image = torch.rand((1,1,32,32))
out = model(image)
https://www.cnblogs.com/yifanrensheng/p/12547660.html
9.1 Deep Dream:计算机生成梦幻图像 - csmhwu
10: Convolutional Neural Network_哔哩哔哩_bilibili
LeNet5—论文及源码阅读_lenet5论文-CSDN博客
谷歌Deep Dream解析(附源代码,可以直接运行)-CSDN博客
【Neural Style Transfer】Deep Photo Style Transfer(含代码详解)-CSDN博客
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue2和Vue3的区别
- 如何处理uni-app中的跨平台差异
- centos用yum安装mysql详细教程
- 【生产者消费者模型的 Java 实现】
- 5G NTN:通信新天地,卫星通信的奇妙探索
- 是时候将javax替换为Jakarta了
- R语言【base】——sprintf():接受格式化文本和变量值来搭建字符型向量。
- RT-Thread: ulog 日志 讲解和使用
- 解决PP材质粘合问题用PP专用UV胶水
- WEB 3D技术 three.js rotation元素旋转控制