统计学-R语言-5.3
发布时间:2024年01月18日
前言
本篇文章即为概率与分布的最后一篇文章。
分位数
分位数函数是累积分布函数的反函数。
p-分位数是具有这样性质的一个值:小于或等于它的概率为p。
根据定义,中位数即50%分位数。
分位数通常用于置信区间的计算,以及与设计试验有关的势函数的计算。
下面给出一个置信区间计算的简单例子:如果𝜎= 12,测量了n=5个观测值,得到均值,通过相关的分位数得到𝜇的一个置信度为95%的置信区间:
xbar=83
sigma=12
n=5
sem=sigma/sqrt(n) #标准误
sem
[1] 5.366563
xbar+sem*qnorm(0.025)
[1] 72.48173
xbar+sem*qnorm(0.975)
[1] 93.51827
qnorm():输入的是小于或等于这个分位数的概率为p,区间为0—1,输出的是z-score(分位数)

由于标准正态分布的对称性,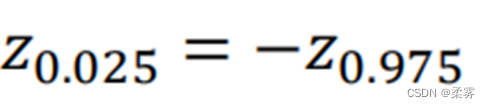
通常把置信度为95%的置的置信区间写成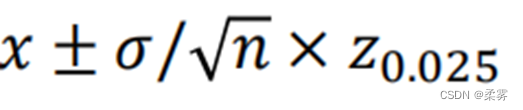
统计量的标准误
统计量的抽样分布的标准差,简称标准误差
衡量统计量的离散程度
在参数估计与假设检验中,用于衡量样本统计量估计总体参数的精确程度
样本均值和样本比例的标准误分别为
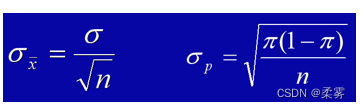
当计算标准误时涉及的总体参数未知时,用样本统计量代替计算的标准误,称为估计的标准误(在统计软件中得到的都是估计标准误)
以样本均值为例:当总体标准差?未知时,可用样本标准差s代替,则在重复抽样条件下,样本均值的估计标准误为
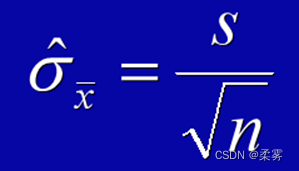
标准误与前面讲的标准差是两个不同的概念。标准差是根据原始观测值计算,反映一组原始数据的离散程度。而标准误是根据样本统计量计算的,反映统计量的离散程度的。
总结

文章来源:https://blog.csdn.net/2301_77225918/article/details/135658627
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- GitHub Copilot 与 OpenAI ChatGPT 的区别及应用领域比较
- 识别pdf标题并重命名pdf
- AI:119-DySnakeConv技术在图像分割中的优化应用:以分割检测头为例
- Note: A Woman Doctor Lina
- “华为杯“第十四届中国研究生数学建模竞赛-A题:无人机在抢险救灾中的优化运用(续)
- 使用Mecury人型机器人搭建VR遥操作控制平台!
- 鸿蒙OS应用开发之文本时钟
- grep的 -e和-E的区别
- 算法基础之整数划分
- 分享两个概念:非受检异常和受检异常