亚信科技AntDB数据库——深入了解AntDB-M元数据锁的实现(二)
5.5 防止低优先级锁饥饿
AntDB-M按照优先级将锁又分了两类,用于解决低优先级锁饥饿问题。
? ?●独占型(hog):?X, SNRW, SNW; 具有较强的不兼容性,优先级高,容易霸占锁,造成其他低优先级锁一直处于等待状态。
? ?●暗弱型(piglet):?SW; 优先级仅高于SRO。
这两种类型锁会分别进行加锁计数。当授予hog类型锁时,如果等待队列中有非hog类型,则计数加1。当授予piglet类型锁时,如果等待队列中有SRO,则计数加1。针对计数是否超过阀值(max_write_lock_count)制定了四种优先级矩阵。在加锁授权检测时,如果两种类型中有任一达到统计阀值,则切换到对应的优先级矩阵,重新检测是否可以授权,此时优先级进行了反转,会提升低优先级锁优先获取锁。当前等待队列里低优先级锁处理完毕后,会重置对应的hog,piglet计数器,并反转优先级。
5.6 死锁检测
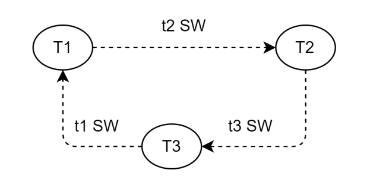
图1-死锁等待
每个线程在进入锁等待前,都会先进行死锁检测,避免陷入死锁等待。在检测前,会先将自己获取到的unobtrusive锁进行物化,即将锁放入锁的授予列表中,以便死锁检测能区分锁的归属线程。然后设置自己上下文等待ticket,每个进入等待的线程都有自己的等待ticket,用于死锁检测。
AntDB-M使用等待图算法进行死锁检测,每个锁对象下的waiting队列中的每个ticket都存在自己的不兼容锁,即正在等待的锁,所有锁对象下的waiting队列中的ticket根据等待关系,构成了一个等待图。先对当前线程的等待的锁对象下的所有ticket进行广度优先检测,即对当前ticket节点的所有边进行检测,在没有发现死锁时,再进入每个ticket上下文的等待ticket对应的锁对象进行深度检测。
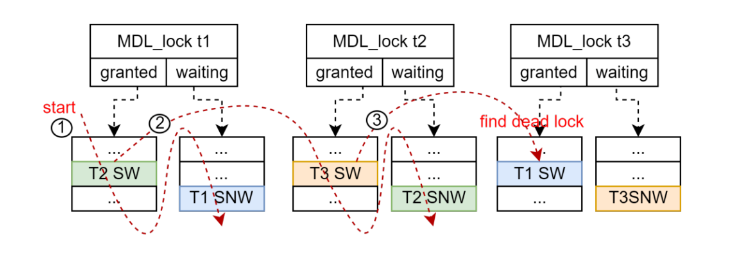
图2-死锁检测
检测开始时记住此次检测的起始上下文,即当前线程的上下文。当在广度、深度遍历过程中,发现等待路径上再次出现起始上下文,说明出现了循环等待,即死锁。如果检测深度(即检测上下文个数)超过阀值(32),也认为出现了死锁。
5.7 死锁驱逐
当发现死锁时,在整个检测路径上包括自己会有2到多个ticket,对于这些ticket,会选其中死锁权重最低的设置状态为驱逐,即唤醒该线程结束等待,将自己从锁对象的等待队列中移除。权重分为3级:DDL锁 > 用户级锁 > DML锁。在出现死锁时,更倾向于让DML事务回滚,让DDL语句继续执行。权重相同时,更倾向于后进入等待队列的事务回滚。在设置了驱逐状态后,并不能保证剩余的锁间没有死锁,会重新进行一次死锁检测,直到没有发现死锁,或者将自己设为驱逐状态为止。对每个上下文进行检测时,对其加读锁,避免上下文的等待对象被重置。
对每个锁对象进行检测时,对其加读锁,避免已授权、等待队列被更新。通过读锁保障数据安全的同时,又保障了多线程间的并发操作。
5.8 锁等待及通知
每个线程的锁上下文都有一个条件变量来进行锁等待。线程在没有获取锁的授权时,会将自己的ticket添加到锁对象的等待队列,并进入等待状态。等待队列的锁授予检测有3个时机:
1)加锁申请阶段,hog,piglet类型锁申请个数超过阀值。
2)当有线程释放元数据锁。
3)元数据锁降级。
时机触发时,会遍历该锁对象的等待列表,检测到可以授予时,设置线程等待状态为授予锁,通知该线程,并将ticket从等待队列移到授予队列。
总结??
AntDB-M通过多层次、多粒度、多优先级提供了灵活丰富的元数据锁功能,适用于各种业务场景。将加锁路径区分快速、慢速路径,提高绝大部分业务场景的加锁效率。通过优先级反转,避免低优先级饥饿。高效的广度优先死锁检测技术,避免了死锁的发生。如果检测到了死锁,会优先驱逐DML操作,保障成本更高的DDL操作,相同操作会优先驱逐等待时间更短的操作,保持公平性。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,服务国内24个省市自治区的数亿用户,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行超十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!