【计算机网络】TCP原理 | 可靠性机制分析(三)
个人主页:兜里有颗棉花糖
欢迎 点赞👍 收藏? 留言? 加关注💓本文由 兜里有颗棉花糖 原创
收录于专栏【网络编程】【Java系列】
本专栏旨在分享学习网络编程、计算机网络的一点学习心得,欢迎大家在评论区交流讨论💌
??一、滑动窗口原理
滑动窗口可以保证在TCP可靠性传输的前提下,数据传输的效率不会太低。我们知道UDP协议是不支持可靠性传输的,所以UDP传输数据的效率是要高于TCP的;而TCP的滑动窗口机制则可以缩小UDP和TCP传输效率之间的差距。
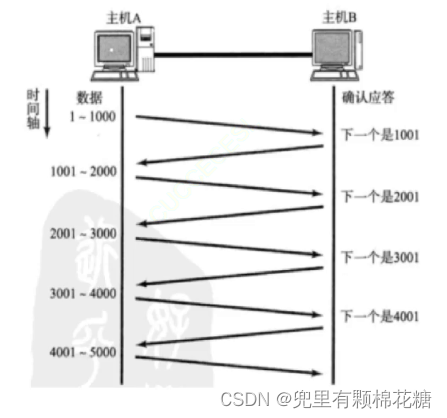
我们先来看看如果TCP如果不使用滑动窗口机制的时候是怎样进行数据传输的,如下图:
上面的传输虽然能够数据传输的可靠性,但其实主机A的大部分时间都消耗在等待ACK确认应答上了,所以数据传输的效率并不高。而滑动窗口机制就可以缩短主机A等待ACK的等待时间,如下图(使用滑动窗口机制):
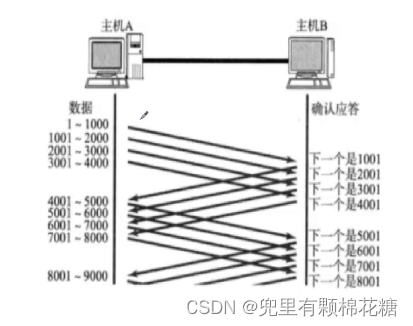
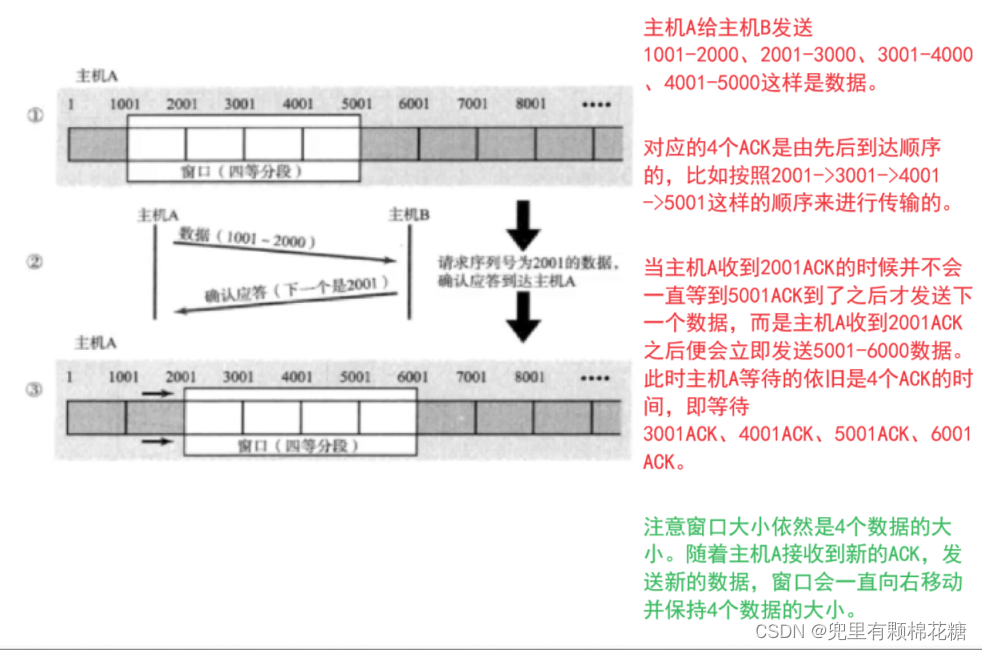
如上图:滑动窗口机制允许发送方在发送数据时能够同时发送多个数据包,而无需等待确认,同时我们把一次能够发送数据的多少称之为窗口。
当然了,窗口越大,数据传输的效率就越高,但是窗口大小是不能无限大的,否则接收方或者中间过程的网络设备是无法在一定时间内处理如此庞大的数据的。
滑动窗口如何解决丢包问题
滑动窗口机制在TCP协议中起到了提高数据传输效率的作用,那如果数据传输过程中丢包了又该怎么办呢?这里的丢包问题分为两种情况:一定情况是要传输的数据丢失了;另外一种情况就是ACK丢失。接下来我们来分析滑动窗口下的超时重传过程。
- 情况一:ACK丢失
我们先来分析较为简单的一种情况,即滑动窗口机制下,如果发送了ACK丢失,此时我们不需要对该情况作出任何处理。
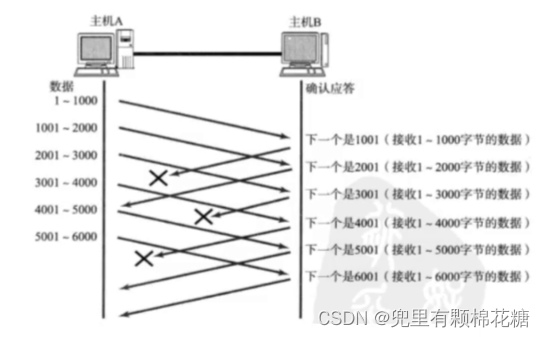
请看上图:上图中ACK1001(注意1001是一个确认序号哈,不要和ACK进行混淆,这里只是为了表述所以才写到一起)丢失了,但是ACK2001并没有丢失,确认序号2001的意思就是2000之前的所有数据(包括2000)都已经接收到了,所以即使ACK1001丢失,主机A在接收到ACK2001之后也是可以确定1000之前的数据包括1000(准确来收是2000之前的数据)都已经接收到了。
ACK3001和ACK4001也是一个道理。
如果所有的ACK全部丢失的话,这就相当于重大的网络故障了,另当别论即可;否则如果只是丢失一部分的ACK的话,对于TCP可靠传输是没有任何影响的。
- 情况二:数据包丢失
现在我们来看第二种情况,即数据包丢失:数据包如果丢失的话是一定要进行数据重传的。接下来我们对数据包什么时候重传以及怎样对数据包进行重传来进行分析。
上图中数据1001-2000并没有传输到主机B(即数据发生了丢失);接下来主机A发送了数据2001-3000,传输成功之后我们发现主机B返回的确认序号却是1001;接下来数据3001-7000传输成功之后返回的ACK确认序号依旧是1001,意思就是主机B在向主机A索要1001-2000的数据。换言之主机B只要没有接收到1001-2000的数据的话,那么主机B就会一直向主机A索要1001-2000之间的数据,具体做法是主机B一直返回确认序号是1001的ACK;与此同时当主机A连续收到了多个确认序号是1001的ACK之后,就会向主机B发送1001-2000的数据。
当重传的1001-2000的数据到达主机B之后,主机B返回的确认序号就是7001。
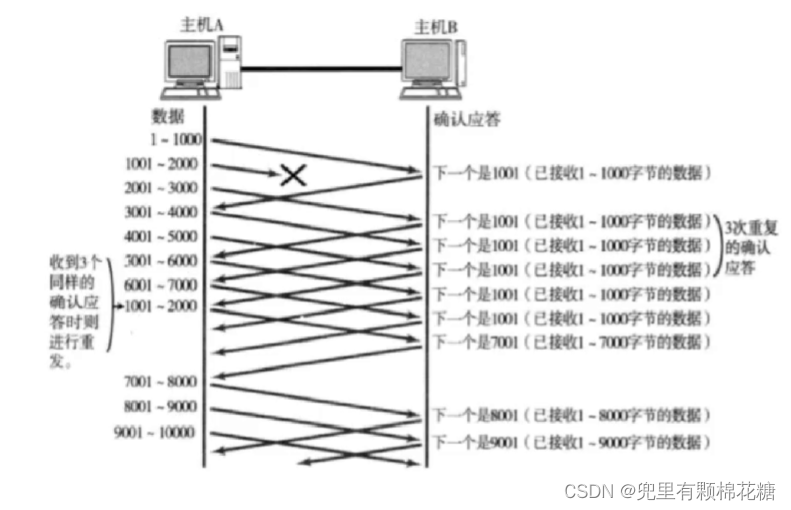
我们站在缓冲区的角度来进行分析:接收方主机B有一个缓冲区用来接收主机A发送的数据,如下图所示:
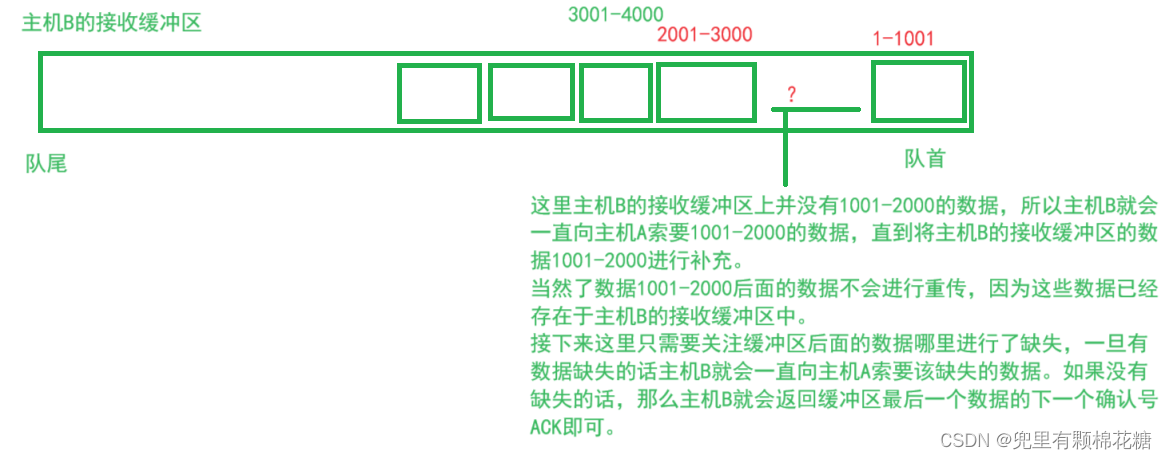
这里使用最小的成本来完成丢失数据的重新传输(并没有重传其它的数据),我们可以把它叫做快速重传哈,其实这个快速重传本质上依旧是超时重传,只不过是将把超时重传结合滑动窗口进行了一个变形的操作。
这里要说明以下,有时TCP协议并不会涉及到滑动窗口的机制,即并不会使用快速重传:当网络通信涉及到大规模数据传输的时候,会使用滑动窗口快速重传的机制;当网络通信涉及到的数据很少的时候,此时就是使用超时重传机制。TCP会根据具体的场景来决策到底是使用超时重传还是快速重传。
??二、滑动窗口——流量控制
我们已经知道滑动窗口中的窗口大小并不是越大越好,因为如果窗口如果太大,即传输大量的数据,此时接收方可能无法对这些数据进行处理,同时也可能导致数据传输的中间链路也无法对这些数据进行处理,进而导致丢包问题,此时我们就需要对这些丢失的数据进行重传。窗口太大的话并没有提高传输数据的效率反而会降低数据传输的效率。流量控制就是针对窗口太大导致接收方无法处理大量数据的一种策略。
发送方发送数据接收方对数据进行处理,这其实是一个生产者消费者模型,如下图:
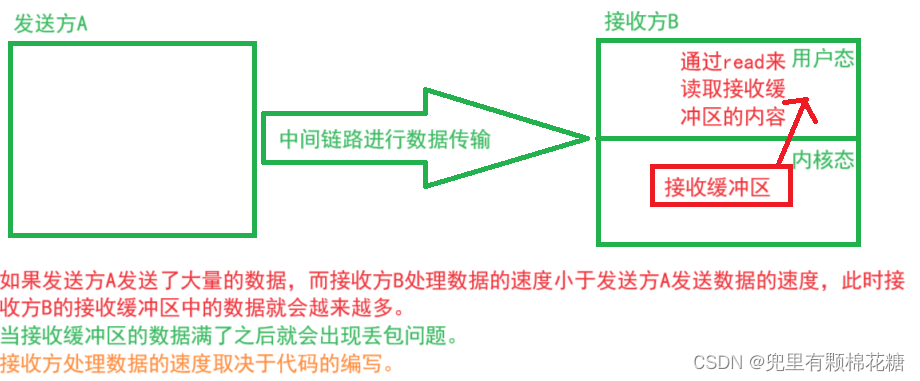
现在来解释什么是流量控制:流量控制就是根据接收方处理数据的能力来先至发送方窗口的大小。
那如何来衡量接收方处理数据的能力呢:可以通过接收方的接收缓冲区的剩余空间大小来衡量接收方处理数据的能力。如果剩余空间越大则说明应用程序处理数据的速度就越快。所以干脆我们直接把接收缓冲区剩余空间大小通过ACK报文反馈给发送方来作为发送方下一次发送数据、窗口大小的依据。
TCP报文结构中的16为窗口大小就是专门针对ACK报文而设定的,16位窗口大小就表示当前接收方缓冲区剩余容量的大小,把这个数字作为ACK报文之后反馈给发送方来作为发送方下一次发送数据大小的依据。TCP中的16位窗口大小字段的取值范围是0-65535,其中0表示接收方暂时不能接收数据,1-65535表示接收方可以接收的数据大小,每个单位代表一个字节。在TCP的标准实现中,默认窗口大小为64KB(即65535个字节)。但是这并不意味着16位窗口大小最大就是64kb。因为TCP报文选项中有一个选项窗口大小拓展因子。实际的16位窗口大小是16位窗口大小<<拓展因子,此时能够表示的窗口大小就非常大了。
下图是流量控制具体的工作过程,请看:
此时主机A虽然不会发送数据,但是由于主机A不知道主机B的接收缓冲区什么时候可以腾出空闲空间,所以主机A会周期性的向主机B发送窗口探测来触发ACK以获得主机B接收缓冲区的具体情况。
一旦发现主机B的接收缓冲区中有空闲内存后,主机A就会继续向主机B发送新的数据。
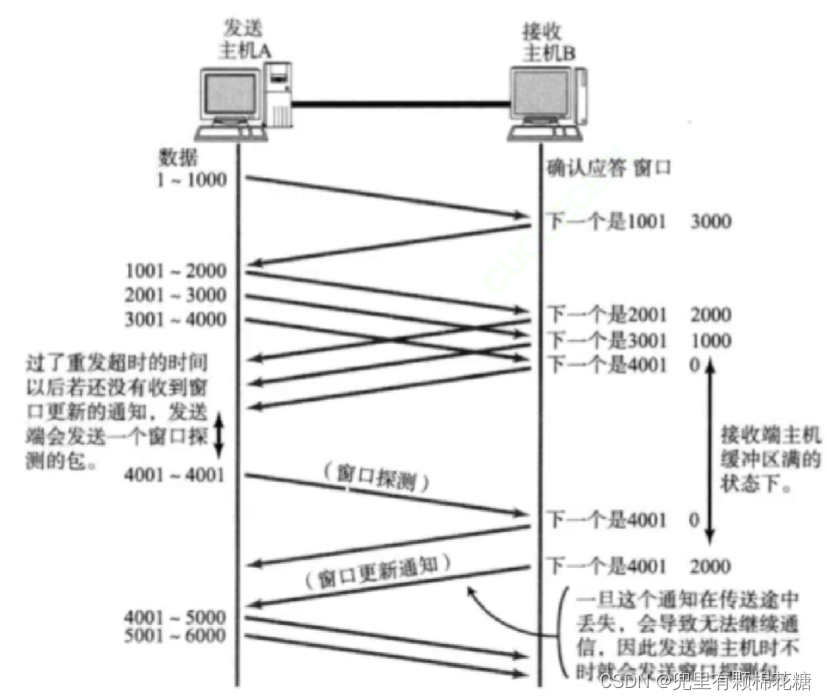
综上,流量控制简单来说就是接收方可以根据发送方窗口大小来反向限制发送方传输数据的速度。
??三、滑动窗口——拥塞控制
主机A向主机B发送数据的过程中,中间会经过一系列的交换机和路由器,所以数据传输的效率不仅仅取决于主机A、主机B,还取决于中间链路传输数据的速度。如果中间链路的某个环节传输数据的速度很慢,此时发送方即主机A的发送数据的速度不应该超过给环节传输数据的阈值。
那我们应该如何衡量链路中间某个环节转发数据的能力呢?
我们对中间链路环节的转发能力并没有很好的方式去进行量化,所以只能通过实践的方式来衡量中间链路环节的转发能力:
使用一个较小的窗口进行传输,如果传输通畅的话就将窗口调大。
使用一个较大的窗口进行传输,如果传输异常的话就将窗口调小。
简单来说就是通畅调大,异常调小。
下面我们来看TCP中拥塞控制是如何进行展开的:
第一步:
慢启动
刚开始进行通信的时候先使用一个很小的窗口试试水。为什么一上来不使用很大的窗口呢,因为如果遇到网络拥堵的话,刚刚进行网络通信时使用较大的窗口(意味着数据量的庞大)就会给网络带宽带来极大的负担。
第二步:指数增长
这里补充一个概念,即拥塞窗口:在拥塞窗口机制下使用的窗口大小。TCP发送方根据拥塞窗口的大小,确定可以发送的数据量。
指数增长就是在网络通畅的过程中,拥塞窗口的大小呈指数级别(*2)的增长(由于指数增长速度极快,所以对这里做出了一定的限制,请看第三步)。
第三步:线性增长
指数增长下当拥塞窗口大小达到一个阈值后就会从指数增长转换为线性增长(+n)。注意这里的指数增长和线性增长是根据数据传输的轮次来进行的。比如说,现在给定窗口大小是1000,那么传输了1000数据之后,本轮数据的传输就结束了,当接收方接收到ACK之后,继续发送数据就进入到了下一轮数据的传输,此时窗口大小就发生了变化,究竟是*2还是+n要根据具体情况具体分析。当线性增长增长到一定程度之后,发送方发送数据的速度就会非常快,当快的网络的极限的时候就可能出现丢包。
第四步:拥塞窗口回归小窗口
当窗口大小在增长过程中如果出现丢包则认为网络出现拥堵了,此时就会把窗口大小调整到小窗口(即最开始的慢窗口),继续回到指数增长和线性增长的过程。当然此时也会根据出现丢包的拥塞窗口的大小来调整阈值(这个阈值指的是指数增长到线程增长的阈值)。
下面是拥塞过程的详细展开图:
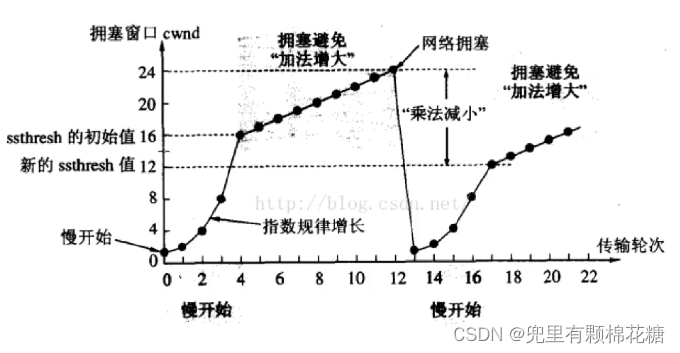
综上,拥塞控制即拥塞窗口的大小不断发送变化调整从而适应复杂多变的网络环境。当然这样做的一个弊端就是会带来数据传输上性能的损失,比如每次丢包后会重新回到慢开始使得数据传输会大打折扣。所以拥塞控制就出现了很多优化的版本(尽可能地把小窗口的传输时间缩短)。还有一点就是我们关注的是拥塞控制的这样一个策略而不是这里的参数,因为参数都是可以进行调整的。
??四、总结
发送方实际窗口=min(流量控制窗口,拥塞窗口):这是因为在网络中,发送方的发送速率应该受到接收方的接收速率限制(由流量控制窗口确定),同时也应该受到网络的拥塞程度限制(由拥塞窗口确定)。换句话来说我们不仅仅要考虑到接收方的处理能力,同时也要考虑到中间链路的处理能力。
滑动窗口在保证数据传输可靠性的前提下一定程度上提高了数据传输的效率,同时拥塞控制和流量控制共同限制了滑动窗口机制,我们也可以说拥塞控制和流量控制也是保证TCP可靠性的一种机制。
本文到这里就结束了,希望友友们可以支持一下一键三连哈。嗯,就到这里吧,再见啦!!!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!