可狱可囚的爬虫系列课程 10:在网站中寻找 API 接口
上一篇文章我们讲述了爬虫中一个比较重要的知识点,如何从 API 接口中获取数据,本篇文章我们继续讲述,如何在网站中寻找 API 接口,我们以“今日头条”网站 https://www.toutiao.com/ 为例。

如上图所示,如果要获取页面新闻数据,可能大部分同学的想法就是直接 Requests 结合 BeautifulSoup4 库进行数据的爬取,但是我们不妨先来找找看有没有 API 接口能够让我们更快速的得到数据。所以在未来大家写爬虫时,可以先试试能否找到 API 接口,再来决定要不要使用 BeautifulSoup4 库。
一、抓包工具的使用
1. 文件的监听
我们在要爬取的页面上打开开发者工具,如下图所示,按照箭头顺序先切换到 Network 选项卡,再点击 Fetch/XHR,然后重新刷新下页面,就能看到红色椭圆框中监听到很多的资源文件。

这里使用的 Network 选项卡就是开发者工具自带的监听功能,监听网页在加载过程中涉及的一些相关数据文件,另外网页加载过程涉及很多文件,像 JS 文件、CSS 文件、Font 文件、图像文件、音视频文件等,大家先简单理解我们切换到的 Fetch/XHR 就是找 API 接口文件的位置。但是这些文件中有可能存在我们需要的 API 数据接口,有些网站的数据接口做的很隐蔽,正常手段不一定找得到,需要结合更高级的抓包工具(Wireshark、Charles 等)才有可能找到,这里我们暂时先来讲解一般的 API 接口寻找方式,后续再单独说明抓包工具的使用。
2. API 接口的判断
如何判断哪个资源文件是我们想要的数据接口呢?最简单的方法是一个个的点开看,不过这样太麻烦,我们结合一些提示性的信息给这些资源文件排个序,最高效的寻找 API 接口。
首先观察这样几个字段:Name、Status、Size、Time。

- Name:文件名,我们依旧是遵循见名知义的原则,通过文件名猜测文件中包含的数据;
- Status:状态码,我们需要的是状态码为200 或者 304 的文件;
- Size:文件大小,数据量大的文件,文件大小都相对较大;
- Time:加载时间,数据量大的文件加载速度相对慢一些。
我们结合这四个字段的特征,给监听到的文件做筛选和排序,择优选取文件查看。例如,我大胆猜测 Name 列名为 hot-board...的文件为头条热榜所涉及数据。
3. 查看文件
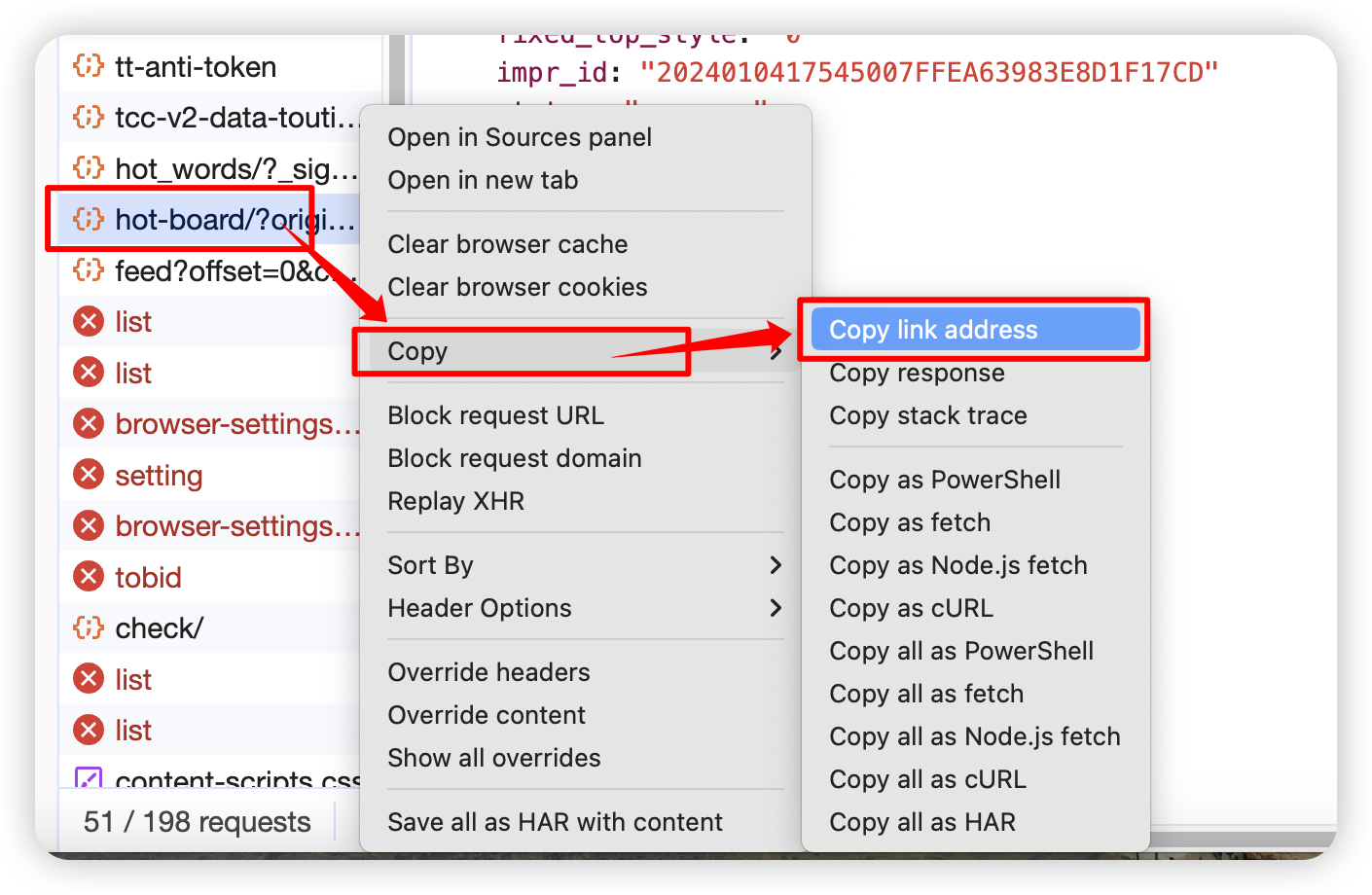
有了猜测目标以后,我们可以点击此文件的文件名位置,在弹出来的窗口切换到 Preview 预览选项卡,发现加载出来的数据和我们所猜测的一致,确实为头条热榜所示数据,这就证明 API 接口找对了,此时便可以从此文件上右键,复制其在线地址,用爬虫来抓取其中的数据。当然前面说了,有些 API 接口比较隐蔽,如果找不到就暂且选择老方法进行数据的爬取。

二、代码编写
1. API 接口请求
import requests
API_URL = 'https://www.toutiao.com/hot-event/hot-board/?origin=toutiao_pc&_signature=_02B4Z6wo00f01TIgxfQAAIDCpvae--DE-40yBMFAAC9V19pn3J.1AFd.u3TRK0tR1rbObxwJ7qLFJCGXBd0Z35J32hVZFJbsVx4puKKLsSDQInjDwZpK4c6DlvBFgCuz3EkKw6APt9jwKbeG36'
Headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=API_URL, headers=Headers)
result = response.text if response.status_code == 200 else '状态码异常'
print(result)
结果如下:

API 接口中数据是以 JSON 格式传输的,但是经过爬虫以后拿出来的结果就变成了 Python 的字符串,如上图所示,看起来像字典,但是整体结果是字符串。有同学问了,不是 JSON 吗,怎么又成了字典?你说巧不巧,JSON 格式的数据呀与 Python 的字典很像,所以 Python 提供了将字符串类型的 JSON 数据转为字典的方法,就是使用 Python 的内置 JSON 库。
2. JSON 库的使用
我们这里使用 JSON 库中的 loads 方法将字符串类型的 JSON 数据转为字典,同时仔细观察结果,通过字典的键将我们所需要的新闻准确无误的筛选出来。
import json
NewsInfo = json.loads(result)
for news_dict in NewsInfo['data']:
newsTitle = news_dict['Title']
print(newsTitle)
结果如下:

3. 完整代码
import requests
import json
API_URL = 'https://www.toutiao.com/hot-event/hot-board/?origin=toutiao_pc&_signature=_02B4Z6wo00f01TIgxfQAAIDCpvae--DE-40yBMFAAC9V19pn3J.1AFd.u3TRK0tR1rbObxwJ7qLFJCGXBd0Z35J32hVZFJbsVx4puKKLsSDQInjDwZpK4c6DlvBFgCuz3EkKw6APt9jwKbeG36'
Headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=API_URL, headers=Headers)
result = response.text if response.status_code == 200 else '状态码异常'
NewsInfo = json.loads(result)
for news_dict in NewsInfo['data']:
newsTitle = news_dict['Title']
print(newsTitle)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java与前端:风云变幻的技术之路
- Unity之组件的生命周期
- 基于Spring Cloud + Spring Boot的企业电子招标采购系统源码
- C++ Qt开发:SqlTableModel映射组件应用
- python在线电影院选择购票售票系统设计与实现(django框架)
- nginx查看连接数的几种方法
- Linux系统中,激活conda envs之后,用户名和路径都消失了,如何添加回来
- 优秘智能:开创AI人工智能未来,共筑智能生活之梦
- openGauss数据库考试
- 解决Android AAPT: error: resource android:attr/lStar not found. 问题