大模型第三节课程笔记
发布时间:2024年01月08日
- 大模型开发范式
优点:具有强大语言理解,指令跟随,和语言生成的能力,具有强大的知识储备和一定的逻辑推理能力,进而能作为基座模型,支持多元应用。
不足:大模型的知识时效性受限,大模型于特定的时间点训练;专业能力有限,如何打造垂域大模型;定制化成本高
两种核心的大模型开发范式

RAG:检索增强生成(核心思想:为大模型外挂知识库,用户的提问首先从知识库中匹配回答问题的相关文档,然后将提问和相关文档一起交给大模型,从而生成回答,进而提高大模型的知识储备),但缺点是受基座模型影响较大,基座模型的能力绝大部分限制了RAG模型的能力天花板;此外,将相关文档和问题一起传给大模型,占用了大量的模型上下文,也因此,对上下文跨度较大的综合性问题表现不佳。
Finetune: 延续传统自然语言处理算法的模型微调(核心思想:在一个新的较小的数据集上,进行轻量级的训练微调,从而提高模型在新数据集上的能力)核心优势是可个性化微调,且知识覆盖面广,finetune范式的应用将在个性化数据上微调,因此可以充分拟合个性化数据,尤其对于非可见知识,如回答风格,回答效果非常好;同时,由于fintune范式的应用是一个新的个性化大模型,其仍然具有大模型的广阔知识域,因此可回答的知识覆盖面广,但是新的数据集上训练成本高昂且数据无法实时更新。
RAG范式的进一步深入
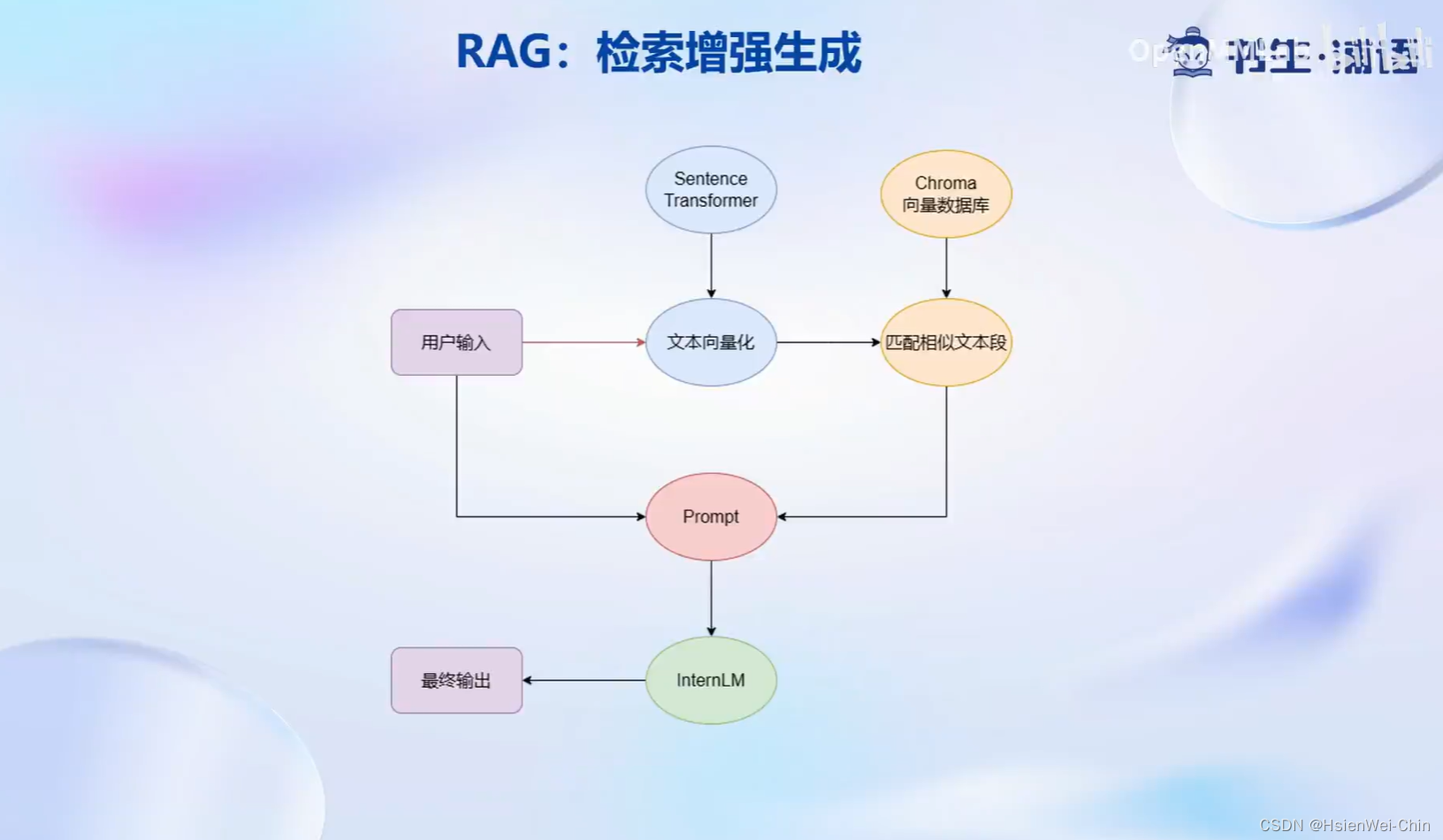
对于每一个用户输入,首先将基于向量模型sentence transformer,将输入文本转化为向量,并在向量数据库中匹配相似的文本段,在这里我们认为与问题相似的文本段,大概率包含了问题的答案,然后会将用户的输入和检索到的相似文本段一起嵌入到模型的prompt中,传递给interlm,然后得到输出。
-
LangChain

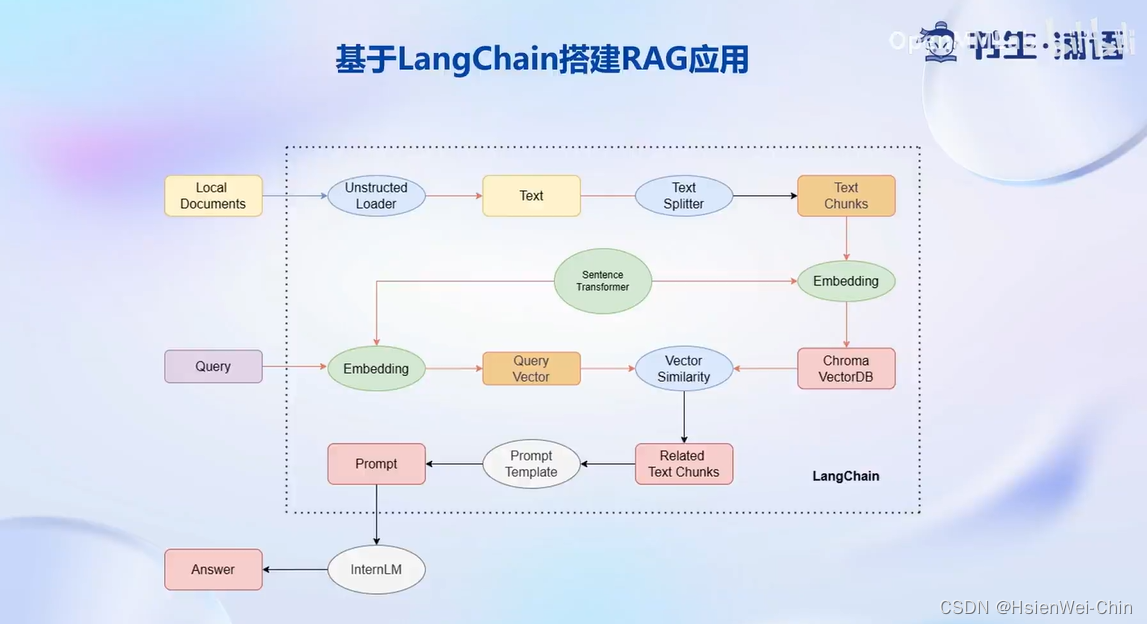
基于langchain搭建RAG应用:首先对于本地的文档形式存在的个人知识库,会使用UnstructedLoader组件加载本地文档,该组件将不同格式的本地文档,统一成纯文本格式;然后通过textsplittler组件,对提取出来的纯文本进行分割成chunks;再通过开源词向量模型Sentence Transformer将文本段转换为向量格式,存储到基于Chroma的向量数据库中;对于用户的每一个输入query,会首先通过Sentence Transformer将输入转换为同维度的向量,通过在向量数据库中进行相似度的匹配,找到和用户输入相关的文本段,将相关的文本段嵌入到已经写好的prompt template中,再交给interLM进行回答。 -
构建向量数据库

-
搭建知识库助手

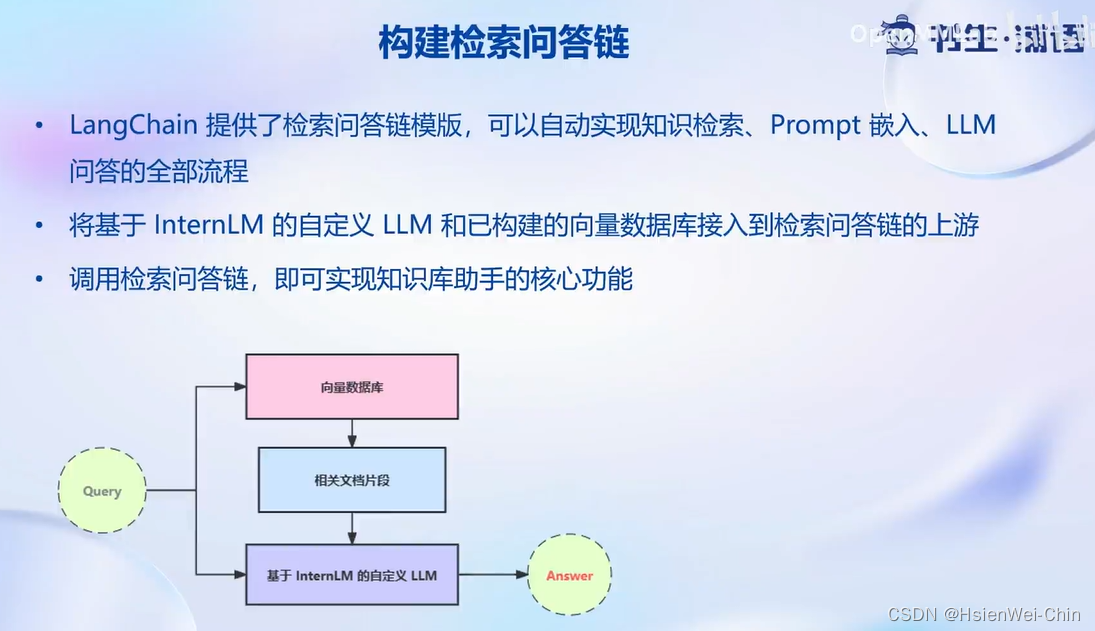

从检索方面的优化点:1)基于语义而不是基于字符长度进行chunk的切分,从而保证每一个chunk的语义完整性;2)…
从prompt的方面优化:不断优化从而不断激发模型的潜在能力
文章来源:https://blog.csdn.net/jinxianwei1999/article/details/135462990
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 路飞项目--02
- Qt/QML编程之路:设计模式(31)
- 如何在 Xftp 中使用自定义编辑器
- 数据结构学习 Leetcode322 零钱兑换
- 二进制、位运算和掩码运算,小白鼠测试示例
- 16.Linux基本使用和程序部署
- 文件归类软件,文件归类整理
- Java---Collection讲解(一)
- 基于Java+Swing大鱼吃小鱼(期末95分以上)
- AutoSAR(基础入门篇)4.3-Autosar_BSW的Communication功能