基于Python的房价预测可视化分析系统-论文、源码、开题报告
?博主介绍:👉全网个人号和企业号粉丝40W+,每年辅导几千名大学生较好的完成毕业设计,专注计算机软件领域的项目研发,不断的进行新技术的项目实战👈
??热门专栏推荐订阅?? 订阅收藏起来,防止下次找不到🔎上千套Python实战项目持续更新中~
有需求的各位可以先收藏起来,还有大家在毕设选题,开题报告有疑惑的都可以找我,给你参考意见,需要开题模板的可以私信留言告诉我??文末获取源码联系??? ? ? ????一定要先收藏??
?
4?系统设计
4.1?系统架构设计
本系统使用B/S模块进行开发,包括服务器和客户端。浏览器客户端主要通过浏览器进行访问系统,查看房屋数据的数据信息,而服务器端通过爬虫来爬取房屋数据的数据,然后存入数据库。从框架层次上本系统确定包括数据层、业务层和表现层。可以更好的管理系统的代码结构,各自负责不同的任务,实现代码的整理,提高开发速度,更有利于后期的升级维护和协作开发。基于Python的房价预测系统如图4.1所示:
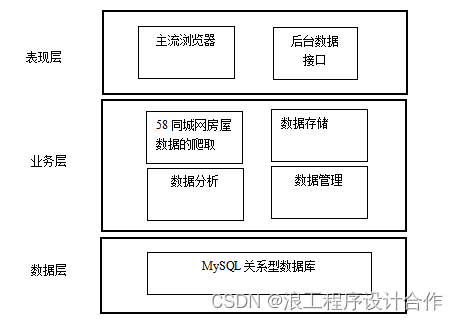
图4.1 ?系统框架模型图
表示层就是我们所见的系统界面,它是使用html、javascript以及Css和div视图页面。用户界面主要用于显示数据,收集客户输入的数据以及和用户相应的操作界面。表示层也可以通过一些框架进行实现,简化了界面设计的工作量,更有利于界面的风格统一和后期的修改。
数据访问层为系统提供基础的数据处理,实现数据库表的信息,增加信息、查询和删除等功能,数据访问层又可以分为实体层和数据库处理。数据访问层将处理后的数据返回给业务逻辑层,也可以接受业务逻辑层的数据,对数据进行数据保存,最终返回保存状态,给业务逻辑层进行判断。
业务逻辑层是所有系统的核心部分,在基于Python的房价预测系统中业务逻辑层是非常重要的层次,它是表示层和数据访问层的桥梁,实现系统的业务逻辑判断。
4.2?系统功能设计
4.2.1数据采集功能设计
在数据采集中,通过python进行爬虫设计,完成商品销售数据、价格数据的采集处理。数据采集主要包括了分析目标网站、目标网站的数据爬取、数据清洗处理、数据存储。其中,数据采集阶段的功能模块如图4.2所示。
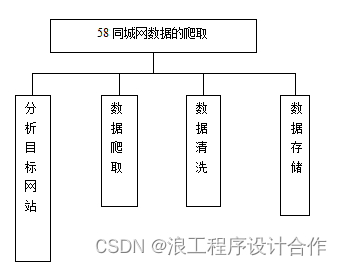
图4.2??数据采集功能模块图
本系统使用58同城网作为目标网站,先分析该网站的结构,然后对网页的数据进行爬取,在爬取过程中会遇到一些重复的商品销售数据,需要对数据进行清洗,通过数据处理获取到相对完整的房产价格,并把处理后的数据存储在对象中,通过循环对象来构造数据存储的插入语句,再进行数据存储,将数据保存在MySQL数据库中。
4.2.2数据管理功能设计
完成数据采集后,数据存储在MySQL中,基于Python的房价预测系统可以对爬取的数据进行管理,管理员登录数据库,可以查看每一条房产价格的内容以及爬取的目标网址,也可以对单条的房产价格进行删除。此外,管理还具有系统管理、用户管理等功能。前台用户具有注册登录,信息查看等功能,其中大屏数据包括房屋名称统计、价格趋势统计、房型统计、类型统计、区域统计。其中,基于Python的房价预测系统的数据管理功能模块如图4.3所示。
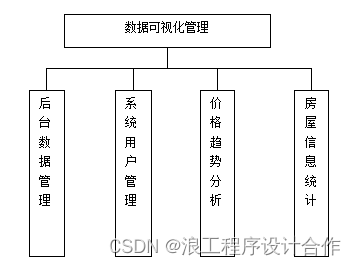
图4.3??数据管理功能模块图
在系统前台,所有的用户都可以通过浏览器访问基于Python的房价预测系统,查看所有大屏数据。在系统后台,管理员对数据进行管理。
其中普通用户功能如下:
(1)登录注册
(2)查看系统简介信息。
(3)查看房屋资讯信息。
(4)房产楼盘信息查看,包括楼盘名称、价格区间、开盘日期、地址、楼盘图片。
(5)房屋信息查看,包括房屋名称、户型、楼层、小区、面积、价格等。
(6)房产信息评论(查看其他会员的评论信息,登录后发布房产评论)。
(7)对各不同的房产数据进行点赞、踩、收藏。
(8)个人中心,修改个人信息,修改个人密码。查看个人收藏的房屋数据,移除收藏。
(9)信息反馈,发布反馈信息给管理员,给出系统建设意见和建议。
系统后台的管理员功能如下:
(1)管理所有爬取的数据信息:更新房产、房屋数据信息。包括爬取的网址、房产标题、图片、名称、标签、价格、开盘日期、交房日期、户型、地址。
(2)管理用户信息:用户信息的添加,删除。
(3)管理房屋类型信息:房屋类型信息的添加,删除。
(4)管理区域信息:区域信息的添加,删除。
(5)系统管理:管理系统轮播图广告信息,自定义图片内容。
(6)数据可视化大屏:通过大屏展示所有的房屋统计、价格趋势统计、热销户型统计、热销区域等。
(7)留言反馈管理,查看会员反馈的信息,及时处理。
(8)系统简介管理,修改系统简介信息。
4.3?系统流程设计
4.3.1爬虫流程设计
在爬虫工作前,先分析需要爬取的网站url地址,查看网页的html布局,并使用对应的关键字进行文章检索,本系统中用到的python类库主要包括requests、pymysql、beautifulSoup、json等。基于Python的房价预测系统爬虫采集流程如图4.4所示。
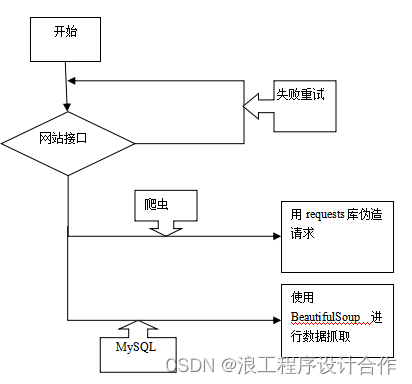
图4.4??系统爬虫采集流程图
先初始化url地址,然后获取当前页面的url列表,并将url放在待处理队列。在循环中,爬取列表数据,先通过request库构造请求头,模拟真实客户端的数据请求方法,避免目标网站防爬机制,然后使用beautifulSoup方法进行数据抓取。beautifulSoup可以从HTML网页中提取数据,减少抓取的工作量。beautifulSoup是python专门为爬取数据提供的一个基础类库,提供了HTML解析器,可以轻松的提取到页面中所有的文本记录。当爬取完数据后对数据进行判断,查看数据是否符合要求,最后将数据存储到数据库中。在存储的时候需要调用pymysql的方法,先连接数据库并指定字段的对应关系。存储完数据后,即完成了单次爬取的操作流程,接着继续下一条,直到结束所有的采集流程。
4.3.2数据可视化流程
本系统所采集的数据,主要包括房产价格的信息,内容涵盖房屋数据的标题、内容简介,爬取日期,目标网站的url地址,获取完数据后对数据进行可视化处理,通过python的管理系统进行数据展示,其中数据可视化处理流程如下图4.5所示。
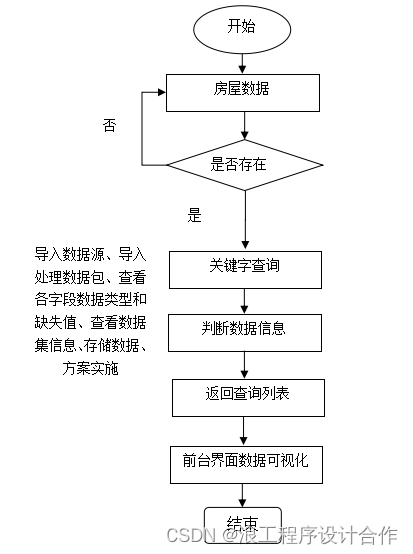
图4.5 数据可视化处理流程图
在房屋数据信息中,可以通过条件进行查询,输入条件后点击查询,先调用查询的业务逻辑方法。该方法先收集用户输入的条件记录,然后对条件信息进行判断,并将条件加入到查询的sql语句方法中。通过对应的条件来查询数据库中的记录,数据库操作层将查询的结果反馈到界面界面,对这些数据集合进行解析,并绑定到html页面进行显示。点击某一条记录的信息,通过ID值来进行传递,通过ID值获取到对应的详细记录,界面绑定了爬取记录的URL地址,点击地址可以跳转到目标网站。
4.4?数据库设计
本基于网络爬虫的基于Python的房价预测系统采用MYSQL数据库作为数据存储,下面介绍数据库中的各个表的详细信息。
表: 房屋数据信息表
| 字段 | 列名 | 类型 | 是否主键 | 是否空 | 说明 |
| 1 | Col_id | int(4) | NO | Null | 主键id |
| 2 | Col_title | nvarchar(500) | NO | Null | 标题 |
| 3 | Col_con | nvarchar(500) | NO | Null | 内容 |
| 4 | Col_url | nvarchar(500) | NO | Null | 目标url |
| 5 | Col_riqi | Datatime | NO | Null | 爬取日期 |
表: 管理员信息表
| 字段 | 列名 | 类型 | 是否主键 | 是否空 | 说明 |
| 1 | Col_username | nvarchar(500) | PK | No | 用户名 |
| 2 | Col_password | nvarchar(500) | NO | Null | 密码 |
表: 会员信息表
| 字段 | 列名 | 类型 | 是否主键 | 是否空 | 说明 |
| 1 | col_user_id | int(4) | 主键 | No | 无 |
| 2 | col_user_name | text(16) | Yes | 无 | |
| 3 | col_user_pw | text(16) | Yes | 无 | |
| 4 | col_user_type | int(4) | Yes | 无 | |
| 5 | col_user_realname | text(16) | Yes | 无 | |
| 6 | col_user_address | text(16) | Yes | 无 | |
| 7 | col_user_sex | text(16) | Yes | 无 | |
| 8 | col_user_tel | text(16) | Yes | 无 | |
| 9 | col_user_email | text(16) | Yes | 无 |
表: 价格信息表
| 字段 | 列名 | 类型 | 是否主键 | 是否空 | 说明 |
| 1 | Col_id | int(4) | PK | No | |
| 2 | Col_zhuid | nvarchar(40) | NO | Null | 主表id |
| 3 | Col_con | nvarchar(400) | NO | Null | 内容 |
| 4 | Col_jiage | int(4) | NO | Null | 价格 |
表: 浏览记录信息表
| 字段 | 列名 | 类型 | 是否主键 | 是否空 | 说明 |
| 1 | Col_id | int(4) | NO | Null | |
| 2 | Col_zhuid | nvarchar(40) | NO | Null | 主表id |
| 3 | Col_riqi | datetime | NO | Null | 日期 |
| 4 | Col_userid | int(4) | NO | Null | 浏览人 |
5?系统实现
5.1数据采集的实现
启动项目,运行爬虫程序,首先通过指定的URL进行过滤,然后将待抓取的URL放入抓取队列中。接着读取URL,解析DNS,下载网页内容,将文本内容通过BeautifulSoup进行存储。
其中爬取到的数据如5.1所示。
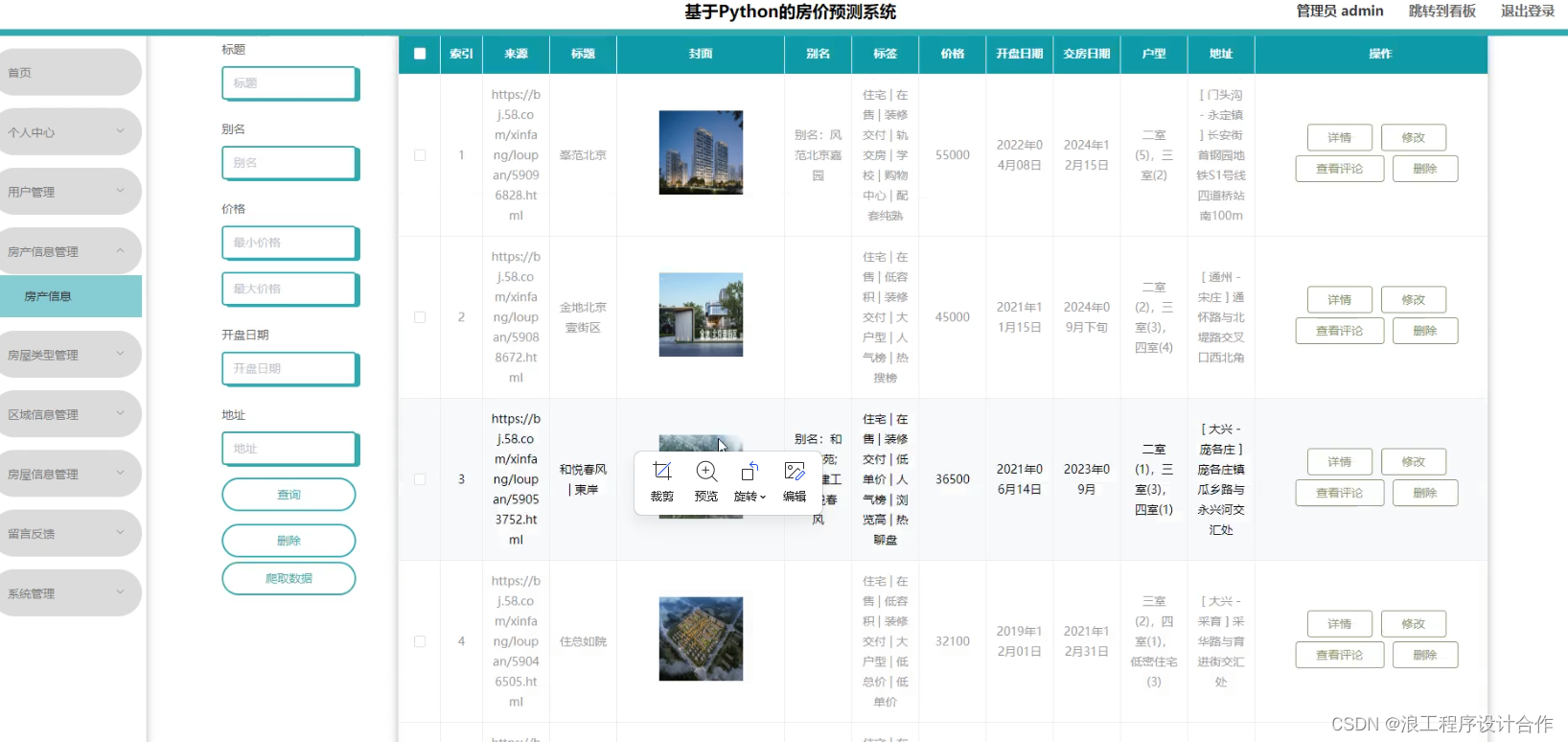
图5.1?采集的数据列表
分析HTML,获取对方文本,通过BeautifulSoup. find_all方法查找a链接下的信息,样式为post-item-title。于是得到代码:
soup.find_all("a", class_="post-item-title")
可以读取到所有a链接,并且样式名称为post-item-title的内容。该内容就是本系统需要的爬取内容,包括了房屋数据的标题、URL地址和内容。再通过for语句循环爬取到的对象结果,使用MySQL的cursor.execute方法进行数据保存,最后commit提交方法把数据插入到数据库。本爬虫用到的类库如下:
import requests
import json
from bs4 import BeautifulSoup
import re
import pymysql
5.2数据库操作的实现
在系统后台使用Django框架进行开发,首先在该后台项目中创建setting.py文件,文件中先需要导入MySQL类库包,然后使用install_as_MySQLdb方法,创建数据库,这时程序具备了访问数据库的功能。另外,在python安装目录中,需要安装pymysql的驱动,使用pip install?pymysql进行安装。
安装好MySQL驱动后,在setting.py文件中,需要配置数据库的链接名称和密码:
'default': {????'ENGINE': 'django.db.backends.mysql',//指定mysql数据库实例,也可以更换其它类型数据库????'NAME': fangchan,//指定基于Python的房价预测系统数据库名称????'USER': 'root',//数据库访问用户名????'PASSWORD': '123',//数据库访问密码????'HOST': '127.0.0.1',//数据库的主机IP地址,如果部署外网上,需要真实IP????'PORT': '3306',//数据库的端口号。}
???配置了数据库连接串,即可实现数据库的操作。
5.3系统首页的实现
前台使用VUE技术进行数据查询,在首页中,先建立和服务器端连接请求,然后发送方法调用,接收返回值。首页主要包括了用户注册登录、所有的房产价格信息、房屋信息、留言反馈。其中首页的界面如5.4所示。
??
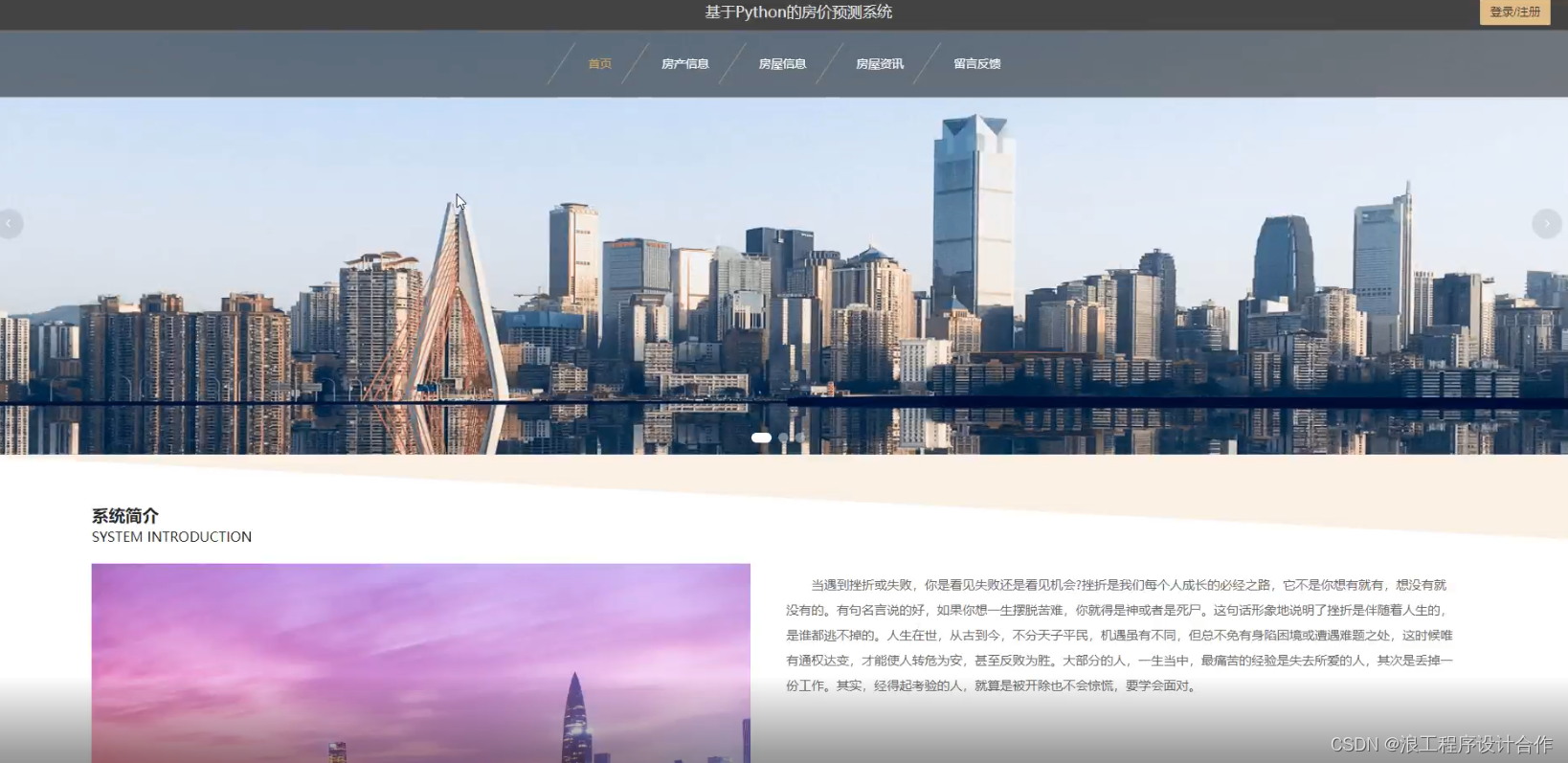
图5.4?系统首页界面
登录用户账号后才可使用系统所有功能。具体操作为用户点击登录账号,在账号栏输入用户账号,密码栏输入用户密码,随后输入正确的验证码后点击登录,方可进入用户系统功能模块,密码错误用户名错误和验证码错误都会导致无法登录。
5.4房价预测大屏显示
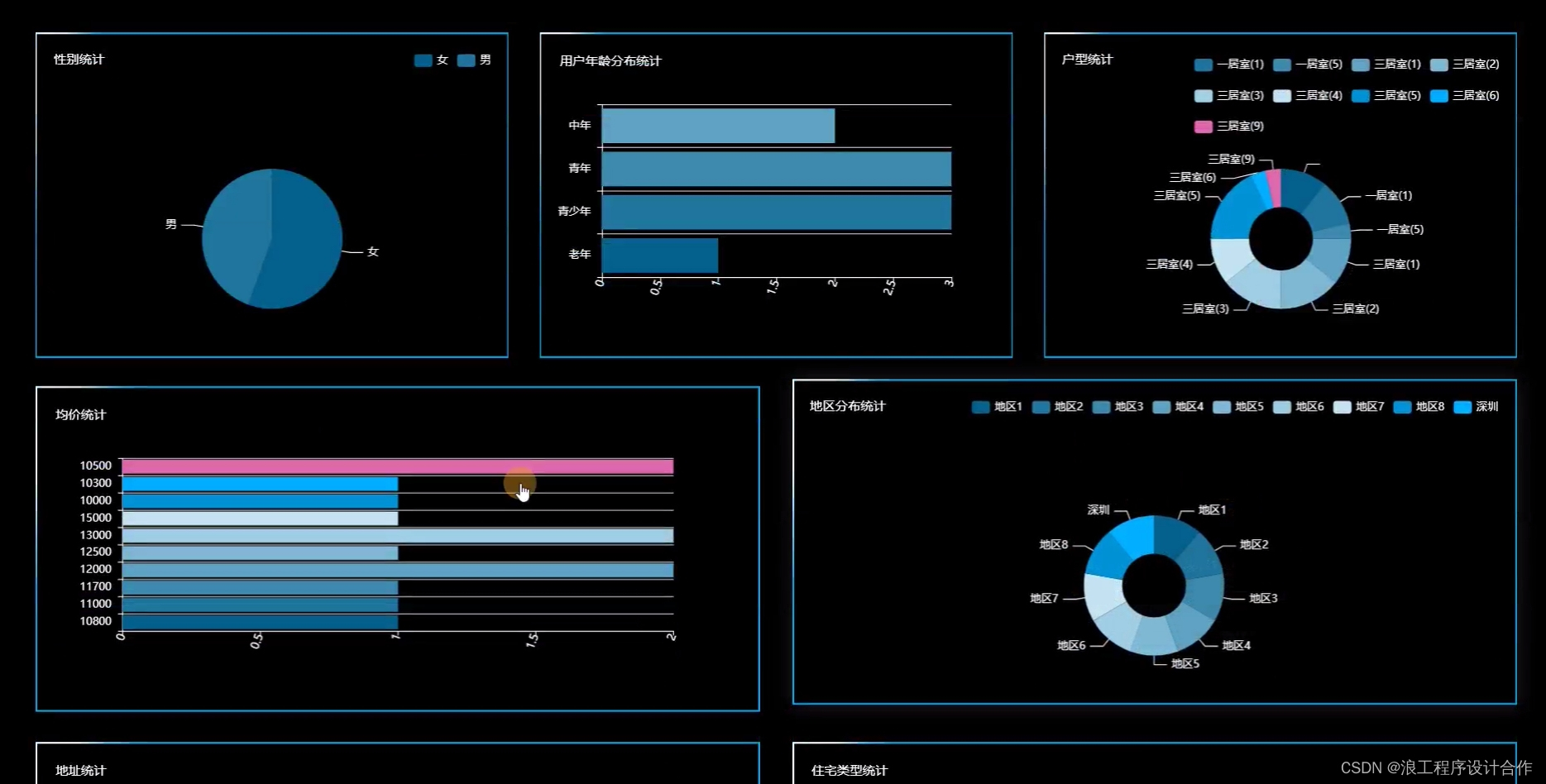
大屏板块信息包括了房屋名称统计、价格趋势统计、房型统计、类型统计、区域统计。最终显示的界面如5.5所示。
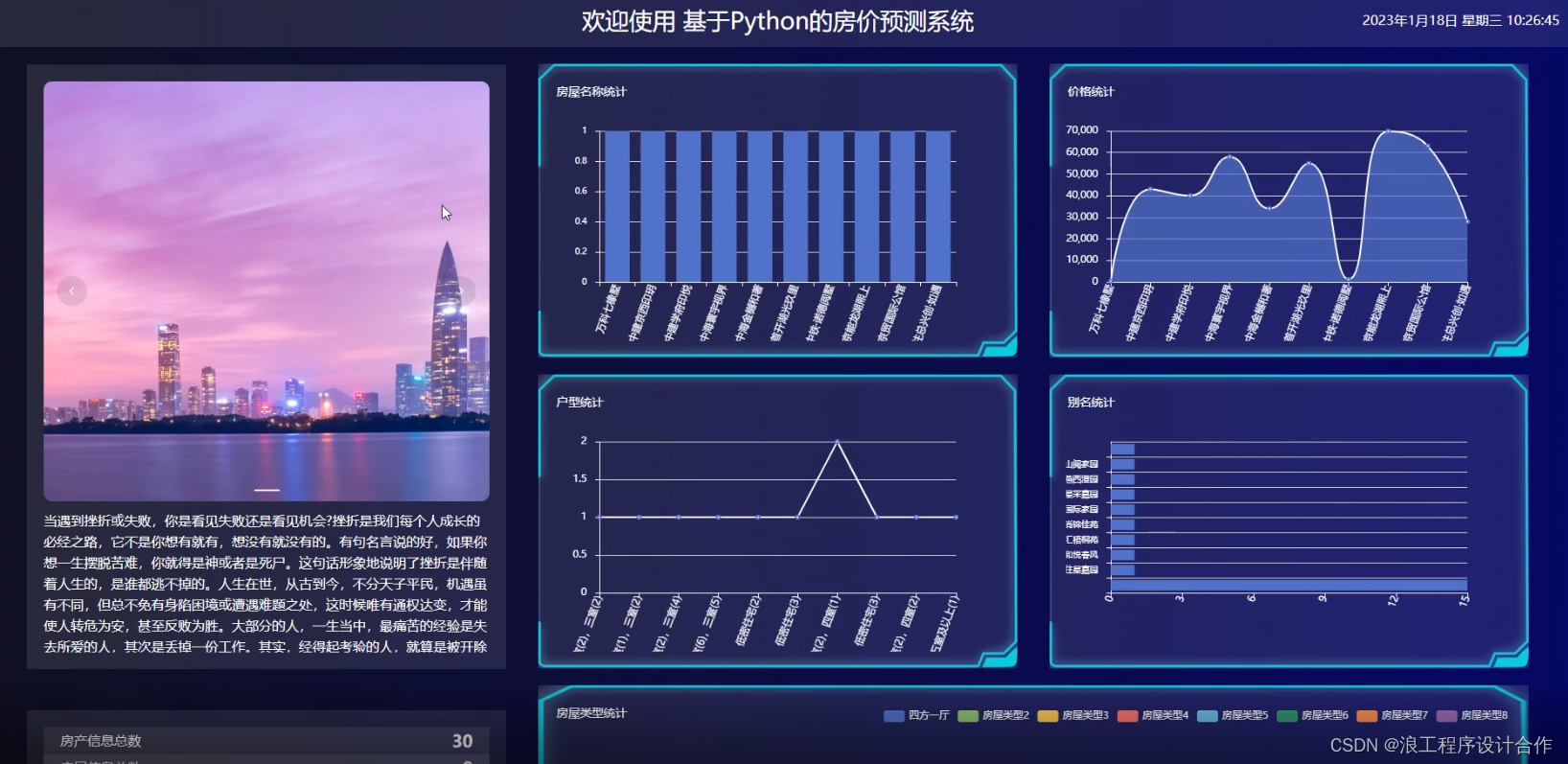
图5.5?房屋数据大屏查看
大屏数据展示使用DataV组件库,可以添加新组件库,开箱即用,通过读取数据库中对应数据库表的数据,设置宽高或配置简单的数据即可显示。
源码获取
大家点赞、收藏、关注?,让更多需要的同学看到
不同开发语言专栏推荐订阅:
👇下方有我的微信名片👇
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL运维篇(二)主从复制
- QCheckBox 选择框使用
- springboot 集成websocket
- 2024年热门网络安全运营工具/方案推荐
- 打破微软封印面向未来创建.NET Framework4.8工程
- Docker安装Elasticsearch,kibana,ik分词器
- gem5学习(14):将gem5扩展到ARM——Extending gem5 for ARM
- c++学习笔记-STL案例-机房预约系统5-学生模块
- 掌握高效创作的艺术:引领未来的AI文章生成器
- C++设计模式之状态模式