算法设计与分析(2):具体模型和下限
在本章中,我们将研究一些简单、具体的计算模型,每个模型都精确定义了什么算作一步,并试图为许多问题获得紧密的上限和下限。本章中研究的具体模型和问题包括:
- 找出数组中最大和第二大元素所需的比较次数
- 对数组排序所需的比较次数
- 确定图是否连通所需的图查询次数
在本章中,我们想要:
- 理解计算模型的概念,并举几个例子(比较模型,查询边模型)
- 理解在特定模型中下界的定义
- 看一些如何在特定模型中证明下界的示例,特别是对于排序和选择问题
1 术语:上界和下界
在本章中,我们将研究几个不同具体模型中多种问题的(最坏情况)上界和下界。每个模型将精确指定允许在输入上执行的操作以及它们的成本。每个模型将有一些花费一定数量的操作(如执行比较或交换一对元素),一些无开销的操作,以及一些完全不允许的操作。
定义:上界
对于某个问题和某个长度
n
n
n,上界
U
n
U_n
Un? 表示存在一个算法
A
A
A,对于每个长度为
n
n
n 的输入
x
x
x,
A
A
A 的成本最多为
U
n
U_n
Un?。
某个问题和某个长度 n n n 的下界是通过对那个 n n n 的上界取反来获得的。它说明某个上界是不可能的(对于那个值的 n n n)。如果我们采用上述陈述并对其取反,我们可以得到以下陈述。对于每一个算法 A A A,存在一个长度为 n n n 的输入 x x x,使得 A A A 在输入 x x x 上的成本超过 U n U_n Un?。重新表述:
定义:下界
对于某个问题和某个长度
n
n
n,下界
L
n
L_n
Ln? 表示对于任何算法
A
A
A,存在一个长度为
n
n
n 的输入
x
x
x,
A
A
A 在该输入上的成本至少为
L
n
L_n
Ln? 步。
这些是单个 n n n 值的定义。现在,如果 f ( n ) f(n) f(n) 对于每个 n ∈ N n∈\mathbb{N} n∈N 都是该问题的一个上界,则函数 f : N → R f:\mathbb{N}→\mathbb{R} f:N→R 是该问题的一个上界。并且,如果 g ( n ) g(n) g(n) 对于每个 n n n 都是该问题的一个下界,则函数 g ( ? ) g(·) g(?) 是该问题的一个下界。
使用这种术语的原因是,如果我们的目标是理解每个问题的“真实复杂度”,用任何算法可以实现的最佳最坏情况保证来衡量,那么 f ( n ) f(n) f(n) 的上界和 g ( n ) g(n) g(n) 的下界意味着真实复杂度介于 g ( n ) g(n) g(n) 和 f ( n ) f(n) f(n) 之间。
最后,算法的成本是什么?正如我们之前所说的,这取决于使用的特定计算模型。我们下面将考虑不同的模型,并展示每个模型都有自己的上界和下界。当编写程序时,通常使用规则来计算操作的成本(添加两个整数的成本为 1 1 1,复制长度为 l l l 的字符串的成本应约为 l l l 等)——我们使用某些成本模型对此进行精确表达。
研究诸如排序和选择等问题的一个自然模型是比较模型。
定义:比较模型
在比较模型中,输入由
n
n
n 个元素(通常以某种初始顺序)组成。算法可以以成本
1
1
1 比较两个元素(询问是否
a
i
<
a
j
a_i < a_j
ai?<aj??)。移动元素是免费的。不允许对元素执行其他操作(将它们用作索引、添加它们等)。
2 比较模型中的选择
2.1 查找 n n n 个元素中的最大值
在比较计算模型中,找到 n n n 个元素中的最大值需要和足够的比较次数是多少?
断言:比较模型中 select-max 的上界
n
?
1
n-1
n?1 次比较就足以找到
n
n
n 个元素中的最大值。
证明 只需从左到右扫描,跟踪到目前为止的最大元素。这最多需要 n ? 1 n-1 n?1 次比较。
现在,让我们试着找一个下界。一个简单的下界是,我们必须查看所有元素(否则没有查看的元素可能大于我们查看的所有元素)。但是查看所有 n n n 个元素可以用 n / 2 n/2 n/2 次比较来完成,所以这还不够紧凑。事实上,我们可以给出一个更好的下界:
断言:比较模型中 select-max 的下界
在最坏的情况下,找到
n
n
n 个元素中的最大值需要
n
?
1
n-1
n?1 次比较。
证明 假设某个算法 A \mathscr{A} A 使用少于 n ? 1 n-1 n?1 次比较就可以找到 n n n 个元素中的最大值。考虑 n n n 个不同元素的任意输入,并构建一个图,其中如果 A \mathscr{A} A 比较两个元素,我们就在它们之间连接一条边。如果进行的比较少于 n ? 1 n-1 n?1 次,那么这个图一定至少有两个连通分量。现在假设算法 A \mathscr{A} A 输出某个元素 u u u 作为最大值,其中 u u u 在某个分量 C 1 C_1 C1? 中。在这种情况下,选择一个不同的分量 C 2 C_2 C2?,并将一个很大的正数(例如 u u u 的值)添加到 C 2 C_2 C2? 中的每个元素。这个过程不会改变 A \mathscr{A} A 所做的任何比较结果,所以在这组新的元素上,算法 A \mathscr{A} A 仍然会输出 u u u。然而,现在 u u u 不是最大值,所以 A \mathscr{A} A 一定是错误的。
由于上界和下界相等,因此 n ? 1 n-1 n?1 的界是紧致的。
2.2 查找 n n n 个元素中的第二大值
找到 n n n 个元素中的第二大值需要(下界)和足够的(上界)比较次数是多少?同样,我们假设所有元素都是不同的。
断言:比较模型中 select-second-max 的下界
在最坏的情况下,找到
n
n
n 个元素中的第二大值需要
n
?
1
n-1
n?1 次比较。
证明 用于找到最大值的同一参数仍然成立。
现在,让我们着手找到一个上界。下面是一个简单的起点。
断言:比较模型中 select-second-max 的上界#1
2
n
?
3
2n-3
2n?3 次比较就足以找到
n
n
n 个元素中的第二大值。
证明 只需用 n ? 1 n-1 n?1 次比较找到最大值,然后用 n ? 2 n-2 n?2 次比较找到其余部分中的最大值,总共 2 n ? 3 2n-3 2n?3 次比较。
我们现在有一个间隙: n ? 1 n-1 n?1 与 2 n ? 3 2n-3 2n?3。这个间隙并不大:两者都是 Θ ( n ) Θ(n) Θ(n),但记住我们要找的是紧密的界限。那么,你认为哪一个更接近事实?事实证明,我们可以大大减少上界:
断言:比较模型中 select-second-max 的上界#2
n
+
lg
?
n
?
2
n+\lg n-2
n+lgn?2 次比较就足以找到
n
n
n 个元素中的第二大值。
证明 第一步,我们用
n
?
1
n-1
n?1 次比较以网球比赛或季后赛结构找到最大元素。也就是说,我们将元素分组成对,找到每对中的最大值,并对最大值进行递归。例如,
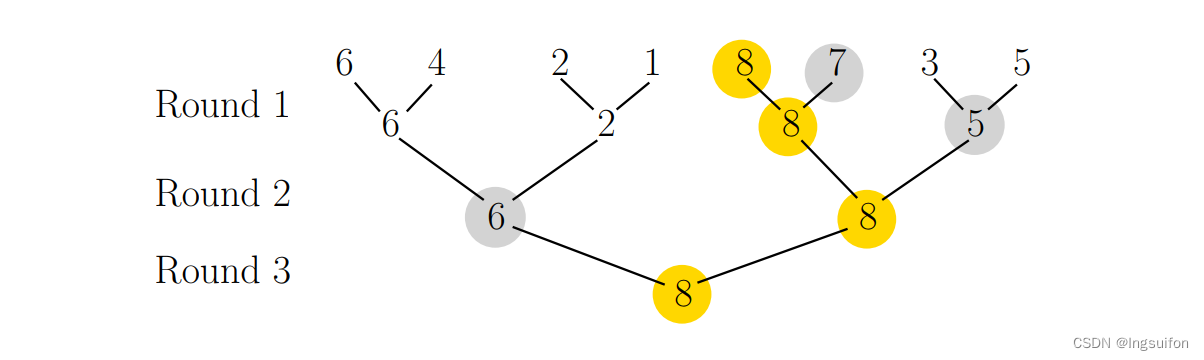
现在,仅根据到目前为止的比较,我们对第二大数字(即第二好的选手)的可能位置有哪些信息?答案是第二好的一定已经直接与最好的进行过比较并失败。这意味着第二大的数字只有
lg
?
n
\lg n
lgn 种可能性,因为最大的数总共进行了
lg
?
n
\lg n
lgn 次比较,这之中一定有一次是与第二大的数进行的比较,我们只需再次比较
lg
?
(
n
)
?
1
\lg (n)-1
lg(n)?1 就可以找到其中的最大值。
此时,我们有一个下界 n ? 1 n-1 n?1 和一个上界 n + lg ? ( n ) ? 2 n+\lg (n)-2 n+lg(n)?2,所以它们几乎紧致。事实证明,下界实际上可以改进到恰好满足上界。
3 比较模型中的排序
在比较模型中的排序问题中,输入是一个数组 a = [ a 1 , a 2 , . . . , a n ] a = [a_1,a_2,...,a_n] a=[a1?,a2?,...,an?],输出是一个输入的排列 π ( a ) = [ a π ( 1 ) , a π ( 2 ) , . . . , a π ( n ) ] π(a) = [a_{π(1)},a_{π(2)},...,a_{π(n)}] π(a)=[aπ(1)?,aπ(2)?,...,aπ(n)?],其中元素按递增顺序排列。我们通过展示以下比较排序的下界来开始这节内容。
定理1 比较模型中的排序下界
任何确定性比较排序算法在最坏情况下都必须执行至少
lg
?
(
n
!
)
\lg (n!)
lg(n!) 次比较来排序
n
n
n 个元素。具体来说,对于任何确定性比较排序算法
A
\mathscr{A}
A,对于所有
n
≥
2
n ≥ 2
n≥2,都存在一个大小为
n
n
n 的输入
I
I
I,使得
A
\mathscr{A}
A 进行至少
lg
?
(
n
!
)
=
Ω
(
n
log
?
n
)
\lg (n!) = Ω(n \log n)
lg(n!)=Ω(nlogn) 次比较来排序
I
I
I。
为了证明这个定理,我们不能假设排序算法一定会像快速排序那样选择枢轴,或者像归并排序那样分割输入——我们需要以某种方式分析任何可能存在的(基于比较的)算法。我们现在呈现这个证明,它使用了一个非常漂亮的信息论证明。(这个证明异常简短:值得仔细思考每一行和每一个断言。)
定理1的证明 首先,我们给出一个简单的一般性结论。假设你有一些问题,算法可能产生 M M M 种不同的输出:例如,对于通过比较进行的排序,其输出可以看作是输入的一个特定排列,输入的每个可能排列都是可能的,因此 M = n ! M = n! M=n!。此外,假设对于这些输出中的每一个,都存在某些输入,它是唯一正确的答案。这对排序来说是正确的。那么,我们有一个最坏情况下界 lg ? M \lg M lgM。原因是算法需要弄清楚这 M M M 个输出中的哪一个是正确的,而每个是/否问题的回答都可以以排除考虑中剩余可能性的一半的方式来回答。(为什么是一半?因为每次比较都有一个二进制输出,所以它将可能性集合分成两部分。这些部分中至少有一个包含至少一半的可能性。)因此,在最坏的情况下,找到正确答案至少需要 lg ? M = lg ? n ! \lg M = \lg n! lgM=lgn! 步。
上述论证通常称为“信息论”证明,因为我们本质上是在说,在我们能够正确决定需要产生的输出之前,我们需要至少 lg ? ( M ) = lg ? ( n ! ) \lg (M)= \lg (n!) lg(M)=lg(n!) 比特的有关输入的信息。
lg ? ( n ! ) \lg (n!) lg(n!) 看起来像什么?我们有: lg ? ( n ! ) = lg ? ( n ) + lg ? ( n ? 1 ) + lg ? ( n ? 2 ) + . . . + lg ? ( 1 ) < n lg ? ( n ) = O ( n log ? n ) \lg (n!) = \lg (n) + \lg (n-1) + \lg (n-2) + ... + \lg (1) < n\lg (n) = O(n\log n) lg(n!)=lg(n)+lg(n?1)+lg(n?2)+...+lg(1)<nlg(n)=O(nlogn) 和 lg ? ( n ! ) = lg ? ( n ) + lg ? ( n ? 1 ) + lg ? ( n ? 2 ) + . . . + lg ? ( 1 ) > ( n / 2 ) lg ? ( n / 2 ) = Ω ( n log ? n ) \lg (n!) = \lg (n) + \lg (n-1) + \lg (n-2) + ... + \lg (1)> (n/2)\lg (n/2) = Ω(n\log n) lg(n!)=lg(n)+lg(n?1)+lg(n?2)+...+lg(1)>(n/2)lg(n/2)=Ω(nlogn)。所以, lg ? ( n ! ) = Θ ( n log ? n ) \lg (n!) = Θ(n\log n) lg(n!)=Θ(nlogn)。
然而,我们要找紧密的界限,让我们更精确一点。特别是,我们可以利用
n
!
∈
[
(
n
/
e
)
n
,
n
n
]
n! ∈ [(n/e)^n, n^n]
n!∈[(n/e)n,nn] 的事实来得到:
n
lg
?
n
?
n
lg
?
e
<
lg
?
(
n
!
)
<
n
lg
?
n
n
lg
?
n
?
1.443
n
<
lg
?
(
n
!
)
<
n
lg
?
n
\begin{aligned} n \lg n - n \lg e < \lg (n!) < n \lg n\\ n \lg n - 1.443n < \lg (n!) < n \lg n \end{aligned}
nlgn?nlge<lg(n!)<nlgnnlgn?1.443n<lg(n!)<nlgn?
由于
1.433
n
1.433n
1.433n 是一个低阶项,有时人们会将这个事实写成:
lg
?
(
n
!
)
=
(
n
lg
?
n
)
(
1
?
o
(
1
)
)
\lg (n!) = (n \lg n)(1 - o(1))
lg(n!)=(nlgn)(1?o(1)),意思是随着
n
n
n 趋于无穷大,
lg
?
(
n
!
)
\lg (n!)
lg(n!) 与
n
lg
?
n
n \lg n
nlgn 之间的比率趋于
1
1
1。
这个下界有多紧致? 假设 n n n 是一个 2 2 2 的幂——让我们假设这适用于剩余内容。你能想到一个进行至多 n lg ? n n \lg n nlgn 次比较的算法,因此在首要项中是紧密的吗?实际上,有几种算法,包括:
二分插入排序 如果我们执行插入排序,使用二分搜索插入每个新元素,则进行的比较次数最多为 ∑ k = 2 n ? lg ? k ? ≤ n lg ? n \sum^n_{k=2}?\lg k?≤n \lg n ∑k=2n??lgk?≤nlgn。注意,插入排序在移动数组中的元素以腾出空间插入每个新元素方面花费很大,因此如果我们也计算移动成本,它的效率不是特别高,但它在比较次数方面表现不错。
归并排序 合并两个各有 n / 2 n/2 n/2 个元素的列表最多需要 n ? 1 n-1 n?1 次比较。因此,展开递归,我们得到 ( n ? 1 ) + 2 ( n / 2 ? 1 ) + 4 ( n / 4 ? 1 ) + . . . + n / 2 ( 2 ? 1 ) = n lg ? n ? ( n ? 1 ) < n lg ? n (n-1)+2(n/2-1)+4(n/4-1)+...+n/2(2-1)= n \lg n - (n-1) <n \lg n (n?1)+2(n/2?1)+4(n/4?1)+...+n/2(2?1)=nlgn?(n?1)<nlgn。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大神们都在用的5款AI写作软件
- 使用PHP自定义一个加密算法,实现编码配合加密,将自己姓名的明文加密一下
- 计算机网络复习2
- ssm/php/node/python智慧小区团购系统
- Python3.12 新版本之f-string的几个新特性
- Selenium登录网页时,不定时出现异常弹窗的四种解决方案
- CompletableFuture 详解(一):基本概念及用法
- LLM漫谈(一)| LLM可以取代数据分析师吗?
- 基础数据结构第九期 堆(数组+STL)
- VTK程序运行闪退解决方案