TensorRT 深入介绍
前言
一、tensorRT 做了那些优化
1、算子融合
常见的算子融合有以下操作:
- conv + bn + relu
- conv + relu
- conv + relu + max_pool
- conv + add + relu
- conv + add
2、量化
因为我们在训练的时候,参数的每次更新的幅度都是十分微小的。所以为了保证在训练时梯度反向传播计算的准确性,就需要精度比较高的数据类型,所以大多数框架是使用单精度FP32。但是在实际推理时是不需要进行反向传播的,所以可以适当降低数据精度,比如考虑降为半精度FP16或整型INT8的精度。
因为更低的数据精度将会占用更少的内存,同时也会让模型的体积更小,延时也更低,可以最大化提高模型的吞吐量,并且理论上不会造成太大的精度损失。
一般来说,FP16不会使模型的精度下降得太厉害,是一种比较安全的量化方式。与FP32相比,FP16的内存消耗仅为它的1/2,因此FP16是更适合在移动端进行模型推理的数据格式。相比FP32来说,占用内存减少了一半,同时也有相应的指令值,速度比FP32要快很多;
相对于FP16来说,INT8占用的内存又减少了一半。但是使用INT8的话,模型掉点的情况就会比较严重,所以这里就需要进行数据精度的校准。
整体来说,使用低精度进行推理的话,模型推理的加速效果还是比较明显的。对于普通大小的模型来说,可以起到三倍左右的加速效果;对于大模型来说,加速效果更明显,甚至可以提高到7倍以上。
3、内核自动调整
TensorRT会根据不同的显卡架构、核心数量、内核频率来进行特定的优化策略,最终寻找到最合适当前架构的计算方式,所以在1080TI上可以运行的TensorRT模型,而放到3090上就不一定可以正常执行,因为不同硬件之间的优化是无法共享的。此外,TensorRT实现了许多GPU算子,内核可以根据不同的batch size大以及模型的复杂度,来选择最优的算法。
4、动态张量显存
我们知道,显存的开辟和释放都是需要时间的。在TensorRT中,会通过调整一些策略来减少模型运行中,所需要的开辟和释放次数,最大限度地减少内存占用并有效地为张量对内存进行重用,从而可以减少推理的时间
5、多流执行
在TensorRT中,会使用CUDA的stream流技术。也就是使用可扩展的设计来并行处理多个输入流,来最大化实现并行操作。
二、如何在TensorRT运行我们训练好的模型
1、TensorRT 的运行流程
拿Pytorch训练好的pth模型来说,如果它要转为TensorRT可以运行的模型,就需要使用ONNX作为桥梁。也就是需要先转化为ONNX ,再由ONNX来构建TensorRT的引擎Engine ,最后才能够在TensorRT上运行。所以它的整体流程为:
- 使用PyTorch训练模型,生成**.pth文件**
- 将.pth文件转化成ONNX模型
- 在TensorRT中加载ONNX模型,并转化成TensorRT的Engine文件
- 在TensorRT中使用Engine文件进行推理
2、ONNX是什么
这里简单做个ONNX的简介,我们平常一般会在 Pytorch、Tensorflow、paddlepaddle上进行模型的开发与训练,但是这些框架其实并不相通,那么部署起来的话,Pytorch 的模型就只能部署在 Pytorch 框架上,而不能在 Tensorflow上运行。这时我们就想使用一个通用的结构,通过这个结构,可以适应 Pytorch 的模型,也可以适应 Caffe 的模型,以及其他框架的模型,甚至适合在手机、开发板这些环境上运行。
那么ONNX 就是起到了这个作用。我们可以使用任意一种深度学习的框架来训练网络,然后将模型的结构与参数都转换为一种通用的中间格式来表示,最后使这个中间结构来适应不同的推理引擎。这样我们在部署时,就不用考虑深度学习框架的限制了。我们不仅不用担心怎么适应各个复杂的框架,我们还可以通过这个中间表示来对网络结构进行优化,使模型在推理的过程中,大大提高运算效率。
3、Engine的构建流程
构建引擎时, TensorRT为所选平台和配置选择最优化的内核。从网络定义文件到构建引擎这个过程可能非常耗时,并且我们不应在每次推理时都重复这个操作,除非模型、平台或配置发生更改。
为了避免模型在每次推理时都要进行编译Engine的操作,所以在第一次构建完Engine后可以就对其进行持久化来保存在本地。
TensorRT上主要存在以下几个对象:
- builder:创建 config、network、Engine等其它对象的核心类。
- network:它是TensorRT的模型类,其它框架下训练完的模型在解析之后将被用于填充到 network中。
- config:用于配置builder
- ONNX Parser:用于解析ONNX文件的类,将ONNX 文件解析出来,并填充到TensorRT的 network 结构中去。
- Engine:是在特定 config 与硬件上编译出来的计算引擎,且只能应用于特定的 config 与硬件上,我们可以对其进行持久化到本地,以节约下次编译的时间。Engine集成了模型结构、模型参数与最优计算 kernel 的配置。同时,Engine是与硬件和 TensorRT的版本有着强绑定的,所以要求 Engine 的编译与执行的硬件与 TensorRT 版本要保持一致。
- context:进行inference推理的实际对象,由 Engine 创建,与 Engine 是一对多的关系。
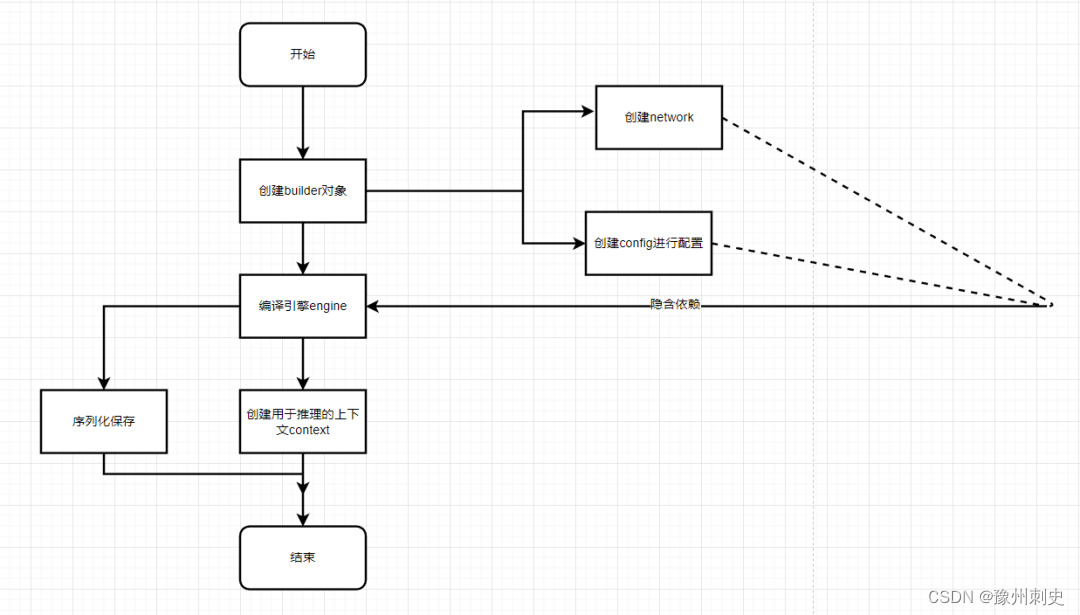
- 解析 network graph,注册计算层;
- 删除冗余的常量节点与冗余层;
- 进行模型融合的操作,最终构建成新的计算层;
- 在计算层中执行最优的kernel搜索;
- 打包成最终的 kernel 优化策略,构建 Engine引擎;
三、TensorRT的其他工具
1、 trtexec
我们可以使用官方提供的工具trtexec来进行模型转换,将ONNX 转为Engine 。在转换的过程中,可能需要等比较长的时间。除了构建Engine 之外,trtexec还可以用于指定大小的输入和输出、计算不同性能下的耗时、模型所支持的精度等。
我们可以在模型转换的时候来对网络进行测试。如:
- 使用Engine进行性能测试
./trtexec --loadEngine =mnist16.trt --batch=16
- 在 FP16 模式下,使用深度学习加速器NVIDIA DLA来运行 AlexNet 网络
./trtexec --deploy=data/AlexNet/AlexNet_N2.prototxt \ #指定caffe的网络模型文件
--output=prob \ #标记输出节点名称,可以多次指定
--useDLACore=1 \ #使用深度学习加速器
--fp16 \ #启用fp16模型,默认是不使用fp16的
--allowGPUFallback #启用DLA时,允许GPU回退不支持的层,默认值是禁用的
- 在 INT8 模式下在 DLA 上运行 AlexNet 网络
./trtexec --deploy=data/AlexNet/AlexNet_N2.prototxt \ #指定caffe的网络模型文件
--output=prob \ #标记输出节点名称,可以多次指定
--useDLACore=1 \ #使用深度学习加速器
--int8 \ #启用int8模型
--allowGPUFallback #启用DLA时,允许GPU回退不支持的层,默认值是禁用的
- 可以使用trtexec来测试模型并打印耗时,并将耗时结果写入json文件
./trtexec --deploy=data/AlexNet/AlexNet_N2.prototxt \ #指定caffe的网络模型文件,
--output=prob \ #标记输出节点名称,可以多次指定
--exportTimes=trace.json #将计时结果写入json文件,注意这里默认是禁用的
- 通过多流执行来调整吞吐量
./trtexec --loadEngine =g1.trt --batch=1 --streams=2
./trtexec --loadEngine =g1.trt --batch=1 --streams=3
./trtexec --loadEngine =g1.trt --batch=1 --streams=4
./trtexec --loadEngine =g2.trt --batch=2 --streams=2
2、polygraphy
使用polygraphy,可以查看ONNX 和Engine 的输出差异,我们主要是看从ONNX 转为Engine 后是否有精度损失。除此之外,还可以观察Engine 中的每层的输出。这个工具在调试的时候用的比较多。
3、ONNX GraphSurgeon
ONNX GraphSurgeon可以修改我们导出的ONNX 模型,主要是对ONNX模型进行优化,比如增加或者剪掉某些节点,修改名字或者维度。有点像 ONNX-simplifier。
4、Pytorch-Quantization
我们可以在Pytorch训练或者推理时来进行模拟量化,从而提升量化模型的精度和速度,并且量化训练后的模型,也是支持导出ONNX和Engine的。
参考链接
https://docs.nvidia.com/deeplearning/tensorrt/index.html
https://zhuanlan.zhihu.com/p/371239130
https://mp.weixin.qq.com/s?__biz=MzkyMDE2OTA3Mw==&mid=2247501201&idx=2&sn=778bf7ac2261d1b1e51bcfffca69fb72&chksm=c1947a8ff6e3f399c0614d2c91f6cd2b6749006991edb38827171066533cad9d95b3557d9ddc&cur_album_id=2405123118882357250&scene=189#wechat_redirect
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 婴儿洗衣机哪款性价比高?希亦、RUUFFY、觉飞全维度测评对比
- 质量图导向法解包裹之---计算边缘可靠性
- Linux介绍、安装、常见命令
- HCIP第一次练习 -- RIP复习实验
- 转义(escape)、校验与编码(encode)
- Spring(1)Spring从零到入门 - Spring特点,系统架构简介,两个核心概念IoC与DI(涉及管理第三方bean)
- 交叉熵损失(Cross Entropy Loss)学习笔记
- 商智C店H5性能优化实战
- Fusion360 服务器验证警告 解决方案
- React 中的 ref 和 refs:解锁更多可能性(上)