MySQL是如何保证数据不丢失的?
前言
上篇文章《InnoDB在SQL查询中的关键功能和优化策略》对InnoDB的查询操作和优化事项进行了说明。但是,MySQL作为一个存储数据的产品,怎么确保数据的持久性和不丢失才是最重要的,感兴趣的可以跟随本文一探究竟。
Buffer Pool 和 DML 的关系
InnoDB中的「Buffer Pool」除了在查询时起到提高效率作用,同样,在insert、update、delete这些DML操作时为了减少和磁盘的频繁交互,也会将这些更新先在Buffer Pool中缓存的数据页进行操作,随后将这些有更新的「脏页」刷到磁盘中。
这个时候就涉及到一个问题:如果MySQL服务宕机了,这些在内存中更新的数据会不会丢失?
答案是一定会存在丢失现象的,只不过MySQL做到了尽量不让数据丢失。接下来来看一下MySQL是怎么做的。
这里还是把结构图贴一下,方便下面介绍时看图理解。
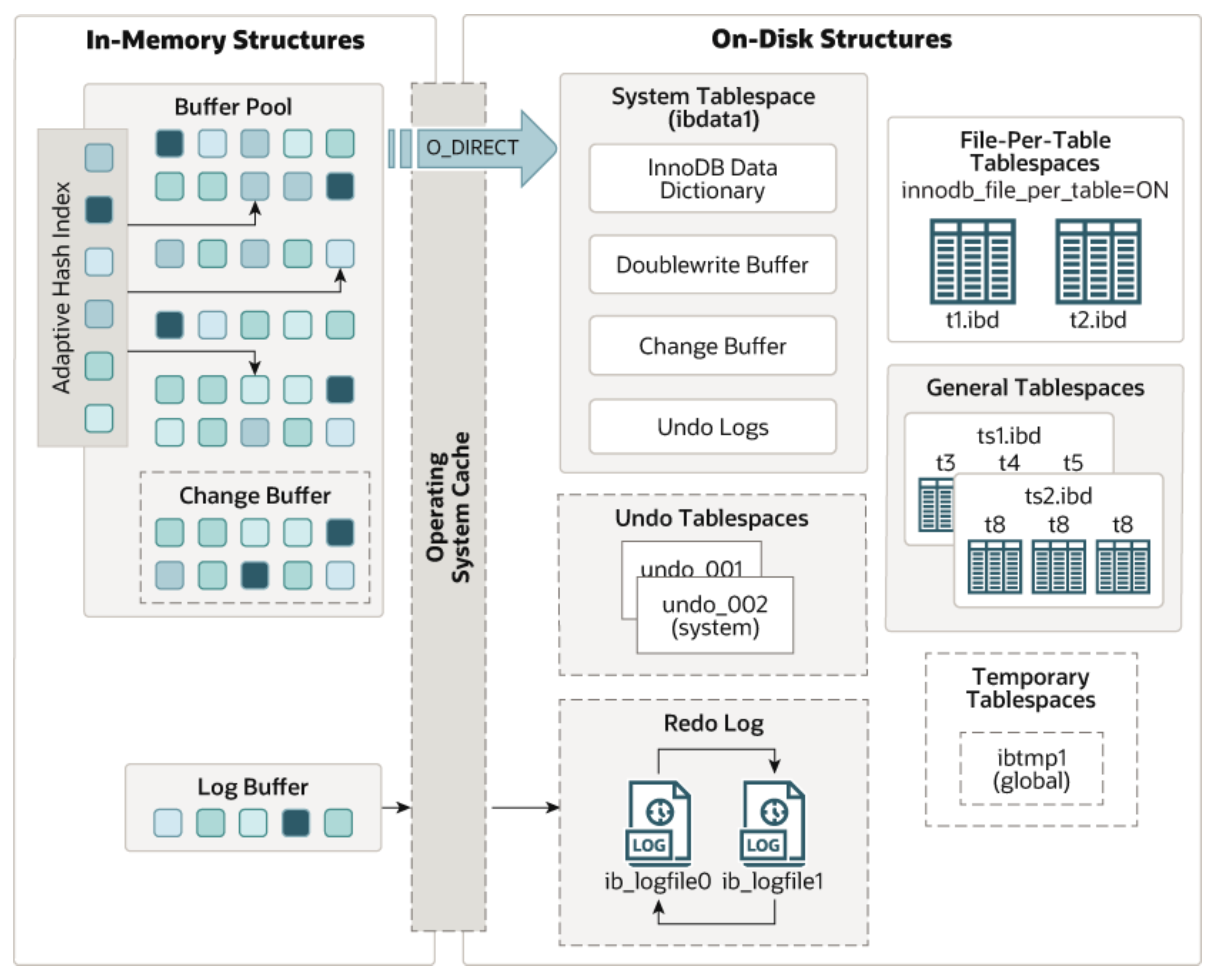
DML操作流程
加载数据页
通过上文可以知道,行记录是在数据页中,所以,当InnoDB接收到DML操作请求后,还是会去找「数据页」,查找的过程跟上文查询行记录流程是一样。这里说一下,insert的请求会根据主键索引去找数据页,update、delete根据查询条件去找数据页,总之「数据页」要加载到「Buffer Pool」之后才会进行下一步操作。
更新记录
定位到数据页后,insert操作就是往数据页中添加一行记录,delete是标记一下行记录的‘删除标记’,而update则是先删除再添加,这是因为存在可变长的字段类型,比如varchar,每次更新时,这种类型的数据占用内存是不固定的,所以先删除再添加。
这里的删除标记是行记录的字段,也就是除了业务字段数据,InnoDB默认为每行记录添加的字段,所以一个行记录大概如下图,这也是之前提到过的「行格式」。

找到数据页并且更新记录之后DML操作就算完成了,但是还没有落地到磁盘。
这个时候直接刷新到磁盘视为完成不可以吗?
数据持久化方案
可以是可以,但是如果每次的DML操作都要将一个16KB的数据页刷到磁盘,其效率是极低的,估计也就没有人用MySQL了。但是如果不刷新到磁盘,就会发生MySQL服务宕机数据会丢失现象。MySQL在这里的处理方案是:
- 等待合适的时机将批量的「脏页」异步刷新到磁盘。
- 先快速将更新的记录以日志的形式刷新到磁盘。
先看第一点,什么时候是合适的时机?
合适的时机刷盘
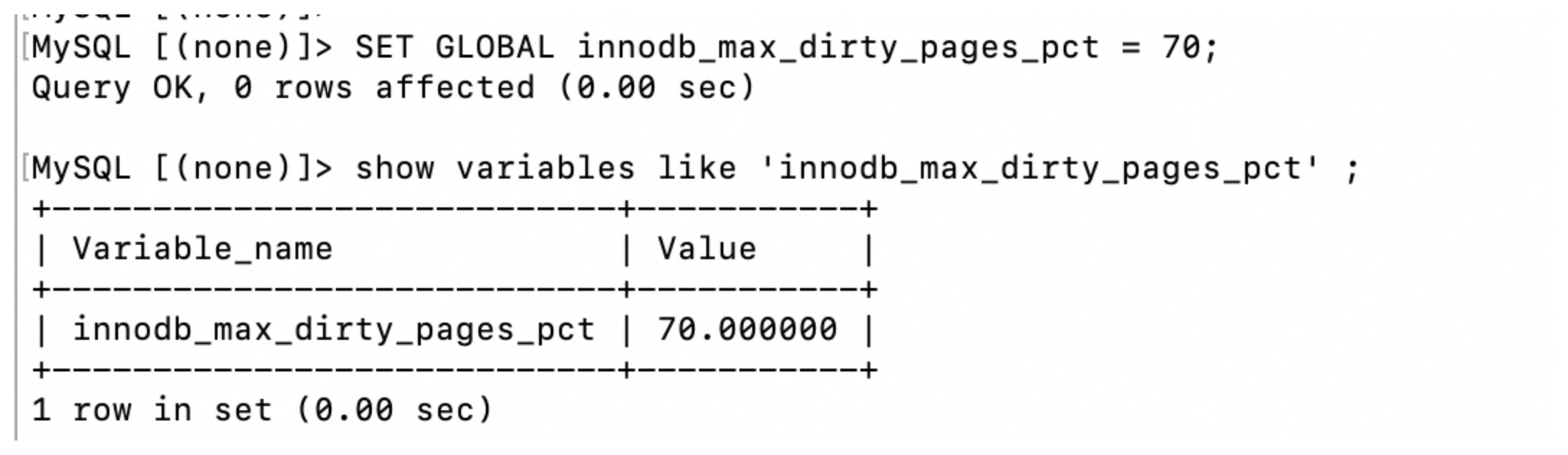
当「脏页」在「Buffer Pool」中达到某个阈值的时候,InnoDB会将这些脏页刷新到磁盘中。这个阈值可以通过 innodb_max_dirty_pages_pct 这个参数查看或设置,相关命令如下:
-- 查看脏页刷新阈值
show variables like 'innodb_max_dirty_pages_pct'
-- 在线设置脏页刷新阈值,当脏页在Buffer Pool占用70%的时候刷新
SET GLOBAL innodb_max_dirty_pages_pct = 70
当然,这个合适的时机只是为了减少与磁盘的交互,用来提高性能的,并不能确保数据不丢失。
双写机制
在刷新「脏页」这里还有一个非常重要的注意事项就是:因为InnoDB的页大小为16KB,而一般操作系统的页大小为4KB。意味着InnoDB将这些「脏页」向磁盘刷新时,在操作系统层面会被分成4个4KB的页,这样的话,如果其中有一页因为MySQL宕机或者其他异常导致没有成功刷新到磁盘,就会出现「页损坏现象」,数据也就不完整了。
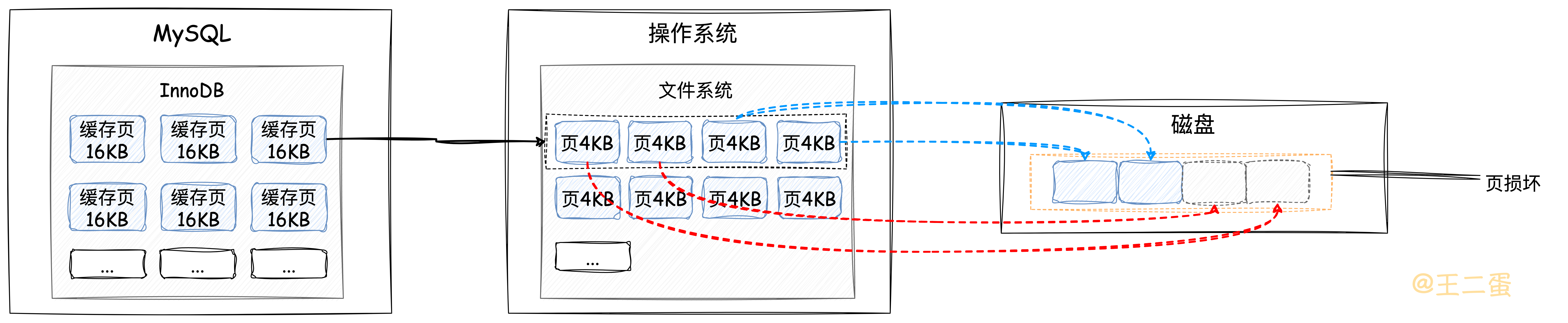
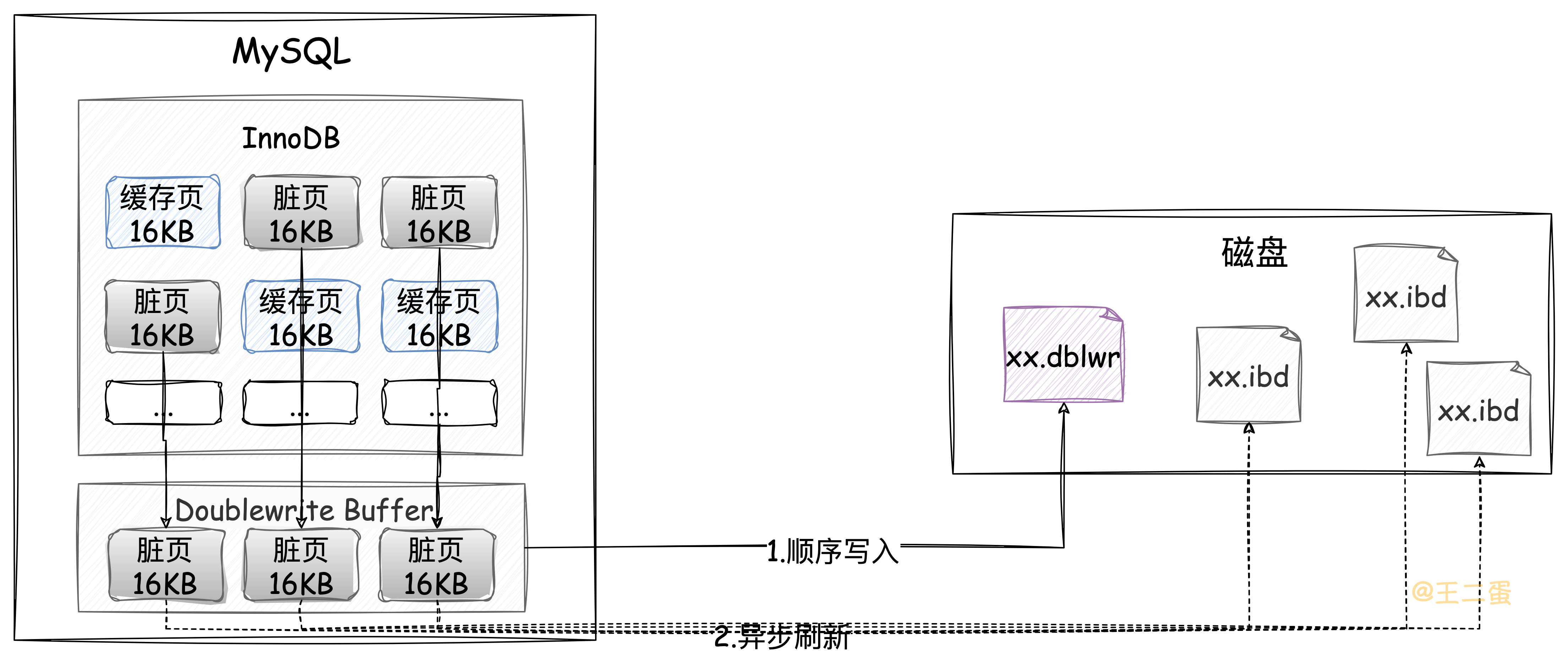
所以InnoDB在这里采用的双写机制,在将这些「脏页」刷新到磁盘之前先会往结构图中的「Doublewrite Buffer」中写入,随后再刷新到对应的表空间中,当出现故障时就可以通过双写缓冲区进行恢复。
向「Doublewrite Buffer」就不会发生「页损坏现象」?
「Doublewrite Buffer」的大小是独立且固定的,不是基于页的大小来划分的。所以不受操作系统中的页大小限制,也不会发生「页损坏现象」。并且先以顺序IO的方式向「Doublewrite Buffer」写入数据页,再以随机IO异步刷新到表空间这种方式还可以提高写入性能。
再看第二点,为什么以日志的形式先刷新到磁盘?
日志先行机制
在「Buffer Pool」中更新完数据页后,由于不会及时将这些「脏页」刷新到磁盘,为了避免数据丢失,会将本次的DML操作向「Log Buffer」中写一份并且刷新到磁盘中,相比16KB的数据页来说,这个数据量会小很多,而且写入日志文件时是追加操作,属于顺序IO,效率较高。如下图,哪种方式写入效率更高是显而易见的。
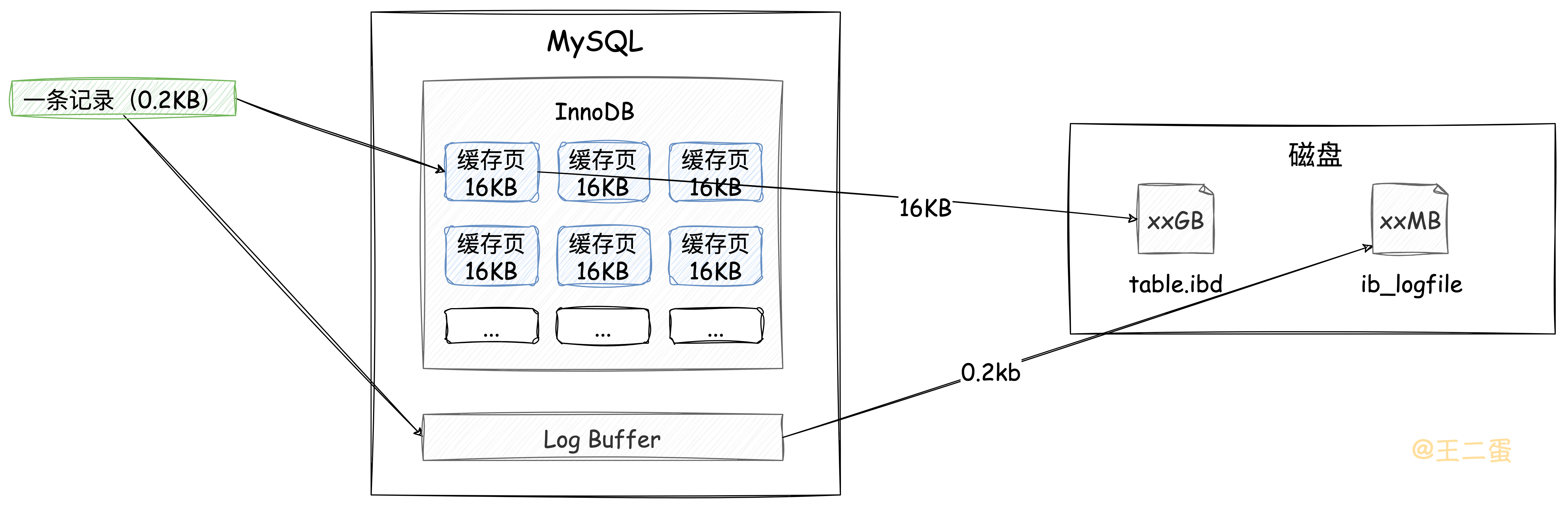
这里说的日志文件就是经常会听到的「Redo Log」,即使MySQL宕机了,通过磁盘的redolog,也可以在MySQL启动时尽可能的将数据恢复到宕机之前样子。当然,还有「Undo Log」,因为对本文重点没有直接影响,所以不对此展开说明。
这种日志先行(WAL)的机制也是MySQL用于提高效率和保障数据可靠的一种方式。
为什么是尽可能的恢复?
日志刷盘机制
因为「Log Buffer」中的日志数据什么时候向磁盘刷新则是由 innodb_flush_log_at_trx_commit 和 innodb_flush_log_at_timeout 这两个参数决定的。
innodb_flush_log_at_trx_commit默认为1,也就是每次事务提交后就会刷新到磁盘。- 当
innodb_flush_log_at_trx_commit设置为0时,则不会根据事务提交来刷新,而是根据innodb_flush_log_at_timeout设置的时间定时刷新,这个时间默认为1秒。 - 当
innodb_flush_log_at_trx_commit设置为2时,仅将日志写入操作系统中的缓存中,随后跟随根据innodb_flush_log_at_timeout定时刷新。
如果在MySQL服务宕机的时候,「Log Buffer」中的日志没有刷新到磁盘,这部分数据也是会丢失的,在重启后也不会恢复。所以如果不想丢失数据,在性能还可以的情况下,尽量将innodb_flush_log_at_trx_commit设置为1。
「redo log」是怎么恢复数据的?
Redo Log 恢复数据
首先,redo log会记录DML的操作类型、数据的表空间、数据页以及具体操作内容,以 insert into t1(1,'hi')为例,对应的redo log内容大概这样的

假如 innodb_flush_log_at_trx_commit 的值为1,那么当该DML操作事务提交后,就会将 redo log 刷新到磁盘。成功刷新到磁盘后,就可以视为数据被写入成功。
此时如果「脏页」还没刷新到磁盘便宕机,那么在下次MySQL启动时便去加载redo log,如果redo log存在数据则意味着需要恢复数据。这个时候就可以通过redo log中的内容重新构建「脏页」,从而恢复到宕机之前的状态。
怎么构建「脏页」呢?
其实在每次的redo log写入时都会记录一个「LSN(log sequence number)」,同时这个值在「数据页」中记录最后一次被修改的日志序列位置。MySQL在启动时通过LSN来对比 redo log 和数据页,如果数据页中的LSN小于 redo log 的LSN,则会将该数据页加载到「Buffer Pool」,然后根据 redo log 的内容构建出「脏页」,等待下次刷新到磁盘,数据也就恢复了。如下图
注意:这个恢复的过程重点在redo上,实际上还涉及到「Change Buffer」、「Undo Log」等操作,这里没有展开说明。
「Doublewrite Buffer」和「redo log」都是恢复数据的,不冲突吗?
不冲突,「Doublewrite Buffer」是对「页损坏现象」的整个数据页进行恢复,Redo Log只能对某次的DML操作进行恢复。
总结
InnoDB通过以上的操作可以尽可能的保证MySQL不丢失数据,最后再总结一下MySQL是如何保障数据不丢失的:
- 为了避免频繁与磁盘交互,每次DML操作先在「Buffer Pool」中的缓存页中执行,缓存页有更新之后便成为「脏页」,随后根据
innodb_max_dirty_pages_pct这个参数将「脏页」刷新到磁盘。 - 因为「脏页」在刷新到磁盘之前可能会存在MySQL宕机等异常行为导致数据丢失,所以MySQL采用日志先行(WAL)机制,将DML操作以日志的形式进行记录到「Redo Log」中,随后根据
innodb_flush_log_at_trx_commit和innodb_flush_log_at_timeout这两个参数将「Redo Log」刷新到磁盘,以便恢复。 - 在向磁盘刷新「脏页」时,为了避免发生「页损坏」现象,InnoDB采用双写机制,先将这些脏页顺序写入「Doublewrite Buffer」中,随后再将数据页异步刷新到各个表空间中,这种方式既能提高写入效率,又可以保障数据的完整性。
- 如果在「脏页」刷新到磁盘之前,MySQL宕机了,那么会在下次启动时通过 redo log 将脏页构建出来,做到数据恢复。
- 通过以上步骤,MySQL做到了尽可能的不丢失数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 8086CPU的寻址方式(7种)
- 欠拟合与过拟合
- Leetcode—54.螺旋矩阵【中等】
- RK3568平台 TinyAlsa集成第三方音频算法
- Buck电源设计常见的一些问题(一)半桥栅极驱动芯片共性失效问题
- 字符串乘方(求字符串中子串有几个)
- 创建一个矩形中有两个三角形
- simulink代码生成(四)——SCI发送模块(串口通信)
- 具有出色的数据速率、SI8642BA-AUR、SI8642BB-AS1R、SI8641BB-B-IUR、SI8635BD-B-ISR低功耗数字隔离器
- 在线文稿演示应用PPTist