【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
本文介绍了表的常见操作(比如union等、排序等以及insert)、group/over window 、 基于行的操作和时态表join操作等具体事例
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
一、maven依赖
本文maven依赖参考文章:【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表 中的依赖,为节省篇幅不再赘述。
二、表的union、unionall、intersect、intersectall、minus、minusall和in的操作
本示例的运行结果均在执行用例中,其中用例只能在批模式下工作,用例特意说明了,如果没说明的则意味着流批模式均可。
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Executable;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.tablesql.TestTableAPIJoinOperationDemo.Order;
import org.tablesql.TestTableAPIJoinOperationDemo.User;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.and;
import static org.apache.flink.table.api.Expressions.row;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIJoinOperationDemo2 {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private double balance;
private Long rowtime;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private long id;
private long user_id;
private double amount;
private Long rowtime;
}
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
final static List<Order> orderList = Arrays.asList(
new Order(1L, 1, 18, 1698742358391L),
new Order(2L, 2, 19, 1698742359396L),
new Order(3L, 1, 25, 1698742360407L),
new Order(4L, 3, 28, 1698742361409L),
new Order(5L, 1, 29, 1698742362424L),
new Order(6L, 4, 49, 1698742362424L)
);
// 创建输出表
final static String sinkSql = "CREATE TABLE sink_table (\n" +
" id BIGINT,\n" +
" user_id BIGINT,\n" +
" amount DOUBLE,\n" +
" rowtime BIGINT\n" +
") WITH (\n" +
" 'connector' = 'print'\n" +
")";
/**
*
* @throws Exception
*/
static void testUnionBySQL() throws Exception {
// TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
DataStream<Order> orderA = env.fromCollection(orderList);
DataStream<Order> orderB = env.fromCollection(orderList);
// 将DataStream数据转Table和View,然后查询
Table tableA = tenv.fromDataStream(orderA, $("id"), $("user_id"), $("amount"),$("rowtime"));
tenv.createTemporaryView("tableB", orderB, $("id"), $("user_id"), $("amount"),$("rowtime"));
// 查询:tableA中amount>2的和tableB中amount>1的数据最后合并
// select * from tableA where amount > 2
// union
// select * from tableB where amount > 1
String sql = "select * from " + tableA + " where amount > 2 union select * from tableB where amount > 1";
Table resultTable = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, Order>> resultDS = tenv.toRetractStream(resultTable, Order.class);// union使用toRetractStream
// String sql = "select * from " + tableA + " where amount > 2 union select * from tableB where amount > 1";
// 9> (true,TestTableAPIJoinOperationDemo2.Order(id=1, user_id=1, amount=18.0, rowtime=1698742358391))
// 8> (true,TestTableAPIJoinOperationDemo2.Order(id=2, user_id=2, amount=19.0, rowtime=1698742359396))
// 4> (true,TestTableAPIJoinOperationDemo2.Order(id=5, user_id=1, amount=29.0, rowtime=1698742362424))
// 8> (true,TestTableAPIJoinOperationDemo2.Order(id=4, user_id=3, amount=28.0, rowtime=1698742361409))
// 14> (true,TestTableAPIJoinOperationDemo2.Order(id=6, user_id=4, amount=49.0, rowtime=1698742362424))
// 6> (true,TestTableAPIJoinOperationDemo2.Order(id=3, user_id=1, amount=25.0, rowtime=1698742360407))
// toAppendStream → 将计算后的数据append到结果DataStream中去
// toRetractStream → 将计算后的新的数据在DataStream原数据的基础上更新true或是删除false
// 类似StructuredStreaming中的append/update/complete
// TODO 3.sink
resultDS.print();
// TODO 4.execute
env.execute();
}
/**
* 和 SQL UNION 子句类似。Union 两张表会删除重复记录。两张表必须具有相同的字段类型。
* 本示例仅仅使用同一个表来演示
* 该操作只能是在批处理模式下
*
* @throws Exception
*/
static void testUnion() throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
EnvironmentSettings env = EnvironmentSettings.newInstance().inBatchMode() .build();
TableEnvironment tenv = TableEnvironment.create(env);
Table ordersTable = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(3L, 1, 25, 1698742360407L),
row(4L, 3, 28, 1698742361409L),
row(5L, 1, 29, 1698742362424L),
row(6L, 4, 49, 1698742362424L)
));
Table left = ordersTable.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table unionResult = left.union(left);
tenv.createTemporaryView("order_union_t", unionResult);
Table result = tenv.sqlQuery("select * from order_union_t");
// 下面不能转换,只有流式表可以转成流
// 出现异常:The UNION operation on two unbounded tables is currently not supported.
// DataStream<Tuple2<Boolean, Order>> resultDS = tenv.toRetractStream(result, Order.class);
// resultDS.print();
//输出表
tenv.executeSql(sinkSql);
result.executeInsert("sink_table");
// +I[6, 4, 49.0, 1698742362424]
// +I[5, 1, 29.0, 1698742362424]
// +I[1, 1, 18.0, 1698742358391]
// +I[3, 1, 25.0, 1698742360407]
// +I[4, 3, 28.0, 1698742361409]
// +I[2, 2, 19.0, 1698742359396]
}
/**
* 和 SQL UNION ALL 子句类似。Union 两张表。 两张表必须具有相同的字段类型。
* 本示例仅仅使用同一个表来演示
*
* @throws Exception
*/
static void testUnionAll() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"),$("balance"),$("rowtime"));
Table left = usersTable.select($("id").as("userId"), $("name"), $("balance"),$("rowtime").as("u_rowtime"));
Table result = left.unionAll(left);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 14> (true,+I[5, alanchan, 29.0, 1698742362424])
// 8> (true,+I[4, alanchan, 28.0, 1698742361409])
// 5> (true,+I[1, alan, 18.0, 1698742358391])
// 10> (true,+I[1, alan, 18.0, 1698742358391])
// 11> (true,+I[2, alan, 19.0, 1698742359396])
// 6> (true,+I[2, alan, 19.0, 1698742359396])
// 7> (true,+I[3, alan, 25.0, 1698742360407])
// 13> (true,+I[4, alanchan, 28.0, 1698742361409])
// 12> (true,+I[3, alan, 25.0, 1698742360407])
// 9> (true,+I[5, alanchan, 29.0, 1698742362424])
env.execute();
}
/**
* 和 SQL INTERSECT 子句类似。Intersect 返回两个表中都存在的记录。
* 如果一条记录在一张或两张表中存在多次,则只返回一条记录,也就是说,结果表中不存在重复的记录。
* 两张表必须具有相同的字段类型。
* 该操作只能是在批处理模式下
*
* @throws Exception
*/
static void testIntersect() throws Exception {
EnvironmentSettings env = EnvironmentSettings.newInstance().inBatchMode() .build();
TableEnvironment tenv = TableEnvironment.create(env);
Table ordersTableA = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(6L, 4, 49, 1698742362424L)
));
Table ordersTableB = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(3L, 1, 25, 1698742360407L),
row(4L, 3, 28, 1698742361409L),
row(7L, 8, 4009, 1698782362424L)
));
Table left = ordersTableA.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table right = ordersTableB.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table intersectResult = left.intersect(right);
tenv.createTemporaryView("order_intersect_t", intersectResult);
Table result = tenv.sqlQuery("select * from order_intersect_t");
//输出表
tenv.executeSql(sinkSql);
result.executeInsert("sink_table");
// +I[1, 1, 18.0, 1698742358391]
}
/**
* 和 SQL INTERSECT ALL 子句类似。
* IntersectAll 返回两个表中都存在的记录。如果一条记录在两张表中出现多次,那么该记录返回的次数同该记录在两个表中都出现的次数一致,也就是说,结果表可能存在重复记录。
* 两张表必须具有相同的字段类型。
* 该操作只能是在批处理模式下
*
* @throws Exception
*/
static void testIntersectAll() throws Exception {
EnvironmentSettings env = EnvironmentSettings.newInstance().inBatchMode() .build();
TableEnvironment tenv = TableEnvironment.create(env);
Table ordersTableA = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(6L, 4, 49, 1698742362424L)
));
Table ordersTableB = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(3L, 1, 25, 1698742360407L),
row(4L, 3, 28, 1698742361409L),
row(7L, 8, 4009, 1698782362424L)
));
Table left = ordersTableA.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table right = ordersTableB.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table intersectResult = left.intersectAll(right);
tenv.createTemporaryView("order_intersect_t", intersectResult);
Table result = tenv.sqlQuery("select * from order_intersect_t");
//输出表
tenv.executeSql(sinkSql);
result.executeInsert("sink_table");
// +I[2, 2, 19.0, 1698742359396]
// +I[1, 1, 18.0, 1698742358391]
}
/**
* 和 SQL EXCEPT 子句类似。Minus 返回左表中存在且右表中不存在的记录。
* 左表中的重复记录只返回一次,换句话说,结果表中没有重复记录。
* 两张表必须具有相同的字段类型。
* 该操作只能是在批处理模式下
*
* @throws Exception
*/
static void testMinus() throws Exception {
EnvironmentSettings env = EnvironmentSettings.newInstance().inBatchMode() .build();
TableEnvironment tenv = TableEnvironment.create(env);
Table ordersTableA = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(6L, 4, 49, 1698742362424L)
));
Table ordersTableB = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(3L, 1, 25, 1698742360407L),
row(4L, 3, 28, 1698742361409L),
row(7L, 8, 4009, 1698782362424L)
));
Table left = ordersTableA.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table right = ordersTableB.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table intersectResult = left.minus(right);
tenv.createTemporaryView("order_intersect_t", intersectResult);
Table result = tenv.sqlQuery("select * from order_intersect_t");
//输出表
tenv.executeSql(sinkSql);
result.executeInsert("sink_table");
// +I[6, 4, 49.0, 1698742362424]
}
/**
* 和 SQL EXCEPT ALL 子句类似。
* MinusAll 返回右表中不存在的记录。在左表中出现 n 次且在右表中出现 m 次的记录,在结果表中出现 (n - m) 次,
* 例如,也就是说结果中删掉了在右表中存在重复记录的条数的记录。
* 两张表必须具有相同的字段类型。
* 该操作只能是在批处理模式下
*
* @throws Exception
*/
static void testMinusAll() throws Exception {
EnvironmentSettings env = EnvironmentSettings.newInstance().inBatchMode() .build();
TableEnvironment tenv = TableEnvironment.create(env);
Table ordersTableA = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(6L, 4, 49, 1698742362424L)
));
Table ordersTableB = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(3L, 1, 25, 1698742360407L),
row(4L, 3, 28, 1698742361409L),
row(7L, 8, 4009, 1698782362424L)
));
Table left = ordersTableA.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table right = ordersTableB.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table intersectResult = left.minus(right);
tenv.createTemporaryView("order_intersect_t", intersectResult);
Table result = tenv.sqlQuery("select * from order_intersect_t");
//输出表
tenv.executeSql(sinkSql);
result.executeInsert("sink_table");
// +I[6, 4, 49.0, 1698742362424]
}
/**
* 和 SQL IN 子句类似。如果表达式的值存在于给定表的子查询中,那么 In 子句返回 true。
* 子查询表必须由一列组成。
* 这个列必须与表达式具有相同的数据类型。
*
* @throws Exception
*/
static void testIn() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"),$("balance"),$("rowtime"));
DataStream<Order> orders = env.fromCollection(orderList);
Table ordersTable = tenv.fromDataStream(orders, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table left = usersTable.select($("id").as("userId"), $("name"), $("balance"),$("rowtime").as("u_rowtime"));
Table right = ordersTable.select($("user_id"));
Table result = left.select($("userId"), $("name"), $("balance"),$("u_rowtime")).where($("userId").in(right));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 3> (true,+I[4, alanchan, 28.0, 1698742361409])
// 12> (true,+I[1, alan, 18.0, 1698742358391])
// 15> (true,+I[3, alan, 25.0, 1698742360407])
// 12> (true,+I[2, alan, 19.0, 1698742359396])
env.execute();
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// testUnion();
// testUnionAll();
// testUnionBySQL();
// testIntersect();
// testIntersectAll() ;
// testMinus();
// testMinusAll();
testIn();
}
}
三、表的OrderBy, Offset 和 Fetch操作
在批处理模式下,也即有界情况下,order by 可以单独使用,排序也可以是任意字段,与一般数据库的排序结果一样。
在流模式下,也即无界的情况下,order by需要和fetch一起使用,排序字段需要有时间属性,与一般数据库的排序有点差异。
需要说明的是order by 和offset&fetch都可以在批处理模式和流模式下工作。
- Order By,和 SQL ORDER BY 子句类似。返回跨所有并行分区的全局有序记录。对于无界表,该操作需要对时间属性进行排序或进行后续的 fetch 操作。
- Offset & Fetch,和 SQL 的 OFFSET 和 FETCH 子句类似。Offset 操作根据偏移位置来限定(可能是已排序的)结果集。Fetch 操作将(可能已排序的)结果集限制为前 n 行。通常,这两个操作前面都有一个排序操作。对于无界表,offset 操作需要 fetch 操作。
具体结果见下面示例
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.row;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.tablesql.TestTableAPIJoinOperationDemo2.Order;
import org.tablesql.TestTableAPIJoinOperationDemo2.User;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIJoinOperationDemo3 {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private double balance;
private Long rowtime;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private long id;
private long user_id;
private double amount;
private Long rowtime;
}
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
final static List<Order> orderList = Arrays.asList(
new Order(1L, 1, 18, 1698742358391L),
new Order(2L, 2, 19, 1698742359396L),
new Order(3L, 1, 25, 1698742360407L),
new Order(4L, 3, 28, 1698742361409L),
new Order(5L, 1, 29, 1698742362424L),
new Order(6L, 4, 49, 1698742362424L)
);
// 创建输出表
final static String sinkSql = "CREATE TABLE sink_table (\n" +
" id BIGINT,\n" +
" user_id BIGINT,\n" +
" amount DOUBLE,\n" +
" rowtime BIGINT\n" +
") WITH (\n" +
" 'connector' = 'print'\n" +
")";
/**
* Order By
* 和 SQL ORDER BY 子句类似。返回跨所有并行分区的全局有序记录。
* 对于无界表,该操作需要对时间属性进行排序或进行后续的 fetch 操作。
* Sort on a non-time-attribute field is not supported.
*
* Offset & Fetch
* 和 SQL 的 OFFSET 和 FETCH 子句类似。
* Offset 操作根据偏移位置来限定(可能是已排序的)结果集。
* Fetch 操作将(可能已排序的)结果集限制为前 n 行。
* 通常,这两个操作前面都有一个排序操作。对于无界表,offset 操作需要 fetch 操作。
*
* @throws Exception
*/
static void testOrderByWithUnbounded() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
env.setParallelism(1);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
usersTable.printSchema();
// 从已排序的结果集中返回前3条记录
Table result = usersTable.orderBy($("rowtime").desc()).fetch(3);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
// resultDS.print();
// (true,+I[1, alan, 18.0, 2023-10-31T08:52:38.391])
// (true,+I[2, alan, 19.0, 2023-10-31T08:52:39.396])
// (true,+I[3, alan, 25.0, 2023-10-31T08:52:40.407])
// (false,-D[1, alan, 18.0, 2023-10-31T08:52:38.391])
// (true,+I[4, alanchan, 28.0, 2023-10-31T08:52:41.409])
// (false,-D[2, alan, 19.0, 2023-10-31T08:52:39.396])
// (true,+I[5, alanchan, 29.0, 2023-10-31T08:52:42.424])
// 从已排序的结果集中返回跳过2条记录之后的所有记录
Table result2 = usersTable.orderBy($("rowtime").desc()).offset(2).fetch(4);
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
result2DS.print();
// (true,+I[1, alan, 18.0, 2023-10-31T08:52:38.391])
// (false,-U[1, alan, 18.0, 2023-10-31T08:52:38.391])
// (true,+U[2, alan, 19.0, 2023-10-31T08:52:39.396])
// (true,+I[1, alan, 18.0, 2023-10-31T08:52:38.391])
// (false,-U[2, alan, 19.0, 2023-10-31T08:52:39.396])
// (true,+U[3, alan, 25.0, 2023-10-31T08:52:40.407])
// (false,-U[1, alan, 18.0, 2023-10-31T08:52:38.391])
// (true,+U[2, alan, 19.0, 2023-10-31T08:52:39.396])
// (true,+I[1, alan, 18.0, 2023-10-31T08:52:38.391])
env.execute();
}
/**
* 和 SQL ORDER BY 子句类似。返回跨所有并行分区的全局有序记录。
* 对于无界表,该操作需要对时间属性进行排序或进行后续的 fetch 操作。
* 这个和一般的查询数据库的结果比较类似
*
* @throws Exception
*/
static void testOrderByWithBounded() throws Exception {
EnvironmentSettings env = EnvironmentSettings.newInstance().inBatchMode() .build();
TableEnvironment tenv = TableEnvironment.create(env);
Table ordersTable = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.BIGINT()),
DataTypes.FIELD("user_id", DataTypes.BIGINT()),
DataTypes.FIELD("amount", DataTypes.BIGINT()),
DataTypes.FIELD("rowtime", DataTypes.BIGINT())
),
Arrays.asList(
row(1L, 1, 18, 1698742358391L),
row(2L, 2, 19, 1698742359396L),
row(3L, 1, 25, 1698742360407L),
row(4L, 3, 28, 1698742361409L),
row(5L, 1, 29, 1698742362424L),
row(6L, 4, 49, 1698742362424L)
));
Table left = ordersTable.select($("id"), $("user_id"),$("amount"),$("rowtime"));
Table orderByResult = left.orderBy($("amount").desc());
tenv.createTemporaryView("order_union_t", orderByResult);
Table result = tenv.sqlQuery("select * from order_union_t");
//输出表
tenv.executeSql(sinkSql);
// +I[6, 4, 49.0, 1698742362424]
// +I[5, 1, 29.0, 1698742362424]
// +I[4, 3, 28.0, 1698742361409]
// +I[3, 1, 25.0, 1698742360407]
// +I[2, 2, 19.0, 1698742359396]
// +I[1, 1, 18.0, 1698742358391]
result.executeInsert("sink_table");
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// testOrderByWithUnbounded();
testOrderByWithBounded();
}
}
四、表的insert操作
和 SQL 查询中的 INSERT INTO 子句类似,该方法执行对已注册的输出表的插入操作。 insertInto() 方法会将 INSERT INTO 转换为一个 TablePipeline。 该数据流可以用 TablePipeline.explain() 来解释,用 TablePipeline.execute() 来执行。
输出表必须已注册在 TableEnvironment中。此外,已注册表的 schema 必须与查询中的 schema 相匹配。
该示例仅仅展示一个方法,运行环境和其他的示例一致,并且本示例仅仅展示的是insert Into,也可以使用execute Insert方法,在其他示例中有展示其使用。
static void testInsert() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<Order> orderA = env.fromCollection(orderList);
DataStream<Order> orderB = env.fromCollection(
Arrays.asList(
new Order(10L, 1, 18, 1698742358391L),
new Order(16L, 4, 49, 1698742362424L)
)
);
Table tableA = tenv.fromDataStream(orderA, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table tableB = tenv.fromDataStream(orderB, $("id"), $("user_id"), $("amount"),$("rowtime"));
tenv.executeSql(sinkSql);
tableA.insertInto("sink_table").execute();
tableB.insertInto("sink_table").execute();
// +I[1, 1, 18.0, 1698742358391]
// +I[2, 2, 19.0, 1698742359396]
// +I[3, 1, 25.0, 1698742360407]
// +I[4, 3, 28.0, 1698742361409]
// +I[5, 1, 29.0, 1698742362424]
// +I[6, 4, 49.0, 1698742362424]
// +I[10, 1, 18.0, 1698742358391]
// +I[16, 4, 49.0, 1698742362424]
}
五、Group window
Group window 聚合根据时间或行计数间隔将行分为有限组,并为每个分组进行一次聚合函数计算。对于批处理表,窗口是按时间间隔对记录进行分组的便捷方式。
窗口是使用 window(GroupWindow w) 子句定义的,并且需要使用 as 子句来指定别名。为了按窗口对表进行分组,窗口别名的引用必须像常规分组属性一样在 groupBy(…) 子句中。
1、Tumble (Tumbling Windows)
滚动窗口将行分配给固定长度的非重叠连续窗口。例如,一个 5 分钟的滚动窗口以 5 分钟的间隔对行进行分组。滚动窗口可以定义在事件时间、处理时间或行数上。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
import static org.apache.flink.table.expressions.ApiExpressionUtils.unresolvedCall;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.BuiltInFunctionDefinitions;
import org.apache.flink.types.Row;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIOperationWithWindowDemo {
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int balance;
private Long rowtime;
}
static void testTumbleOver() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
//按属性、时间窗口分组后的互异(互不相同、去重)聚合
Table groupByWindowResult = usersTable
.window(Tumble
.over(lit(5).minutes())
.on($("rowtime"))
.as("w")
)
.groupBy($("name"), $("w"))
.select($("name"), $("balance").sum().distinct().as("sum_balance"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(groupByWindowResult, Row.class);
result2DS.print("result2DS:");
// result2DS::2> (true,+I[alan, 62])
// result2DS::16> (true,+I[alanchan, 57])
//使用分组窗口结合单个或者多个分组键对表进行分组和聚合。
Table result = usersTable
.window(Tumble.over(lit(5).minutes()).on($("rowtime")).as("w")) // 定义窗口
.groupBy($("name"), $("w")) // 按窗口和键分组
// 访问窗口属性并聚合
.select(
$("name"),
$("w").start(),
$("w").end(),
$("w").rowtime(),
$("balance").sum().as("sum(balance)")
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print("resultDS:");
// resultDS::2> (true,+I[alan, 2023-10-31T08:50, 2023-10-31T08:55, 2023-10-31T08:54:59.999, 62])
// resultDS::16> (true,+I[alanchan, 2023-10-31T08:50, 2023-10-31T08:55, 2023-10-31T08:54:59.999, 57])
env.execute();
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
testTumbleOver();
}
}
2、Slide (Sliding Windows)
滑动窗口具有固定大小并按指定的滑动间隔滑动。如果滑动间隔小于窗口大小,则滑动窗口重叠。因此,行可能分配给多个窗口。例如,15 分钟大小和 5 分钟滑动间隔的滑动窗口将每一行分配给 3 个不同的 15 分钟大小的窗口,以 5 分钟的间隔进行一次计算。滑动窗口可以定义在事件时间、处理时间或行数上。
static void testSlidingOver() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
Table result1 = usersTable
.window(
Slide.over(lit(10).minutes())
.every(lit(5).minutes())
.on($("rowtime"))
.as("w")
)
.groupBy($("name"),$("w"))
.select($("name"),$("balance").sum().as("sum(balance)"),$("w").start(),$("w").end(),$("w").rowtime())
;
DataStream<Tuple2<Boolean, Row>> result1DS = tenv.toRetractStream(result1, Row.class);
// result1DS.print("result1DS:");
// result1DS::16> (true,+I[alanchan, 57, 2023-10-31T08:45, 2023-10-31T08:55, 2023-10-31T08:54:59.999])
// result1DS::2> (true,+I[alan, 62, 2023-10-31T08:45, 2023-10-31T08:55, 2023-10-31T08:54:59.999])
// result1DS::16> (true,+I[alanchan, 57, 2023-10-31T08:50, 2023-10-31T09:00, 2023-10-31T08:59:59.999])
// result1DS::2> (true,+I[alan, 62, 2023-10-31T08:50, 2023-10-31T09:00, 2023-10-31T08:59:59.999])
// Sliding Processing-time window (assuming a processing-time attribute "proctime")
Table usersTable2 = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime().as("proctime"));
Table result2 = usersTable2
.window(Slide.over(lit(10).minutes())
.every(lit(5).minutes())
.on($("proctime"))
.as("w")
)
.groupBy($("name"),$("w"))
.select($("name"),$("balance").sum().as("sum(balance)"),$("w").start(),$("w").end(),$("w").proctime())
;
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
// result2DS.print("result2DS:");
// result2DS::2> (true,+I[alan, 62, 2023-10-31T08:45, 2023-10-31T08:55, 2023-11-03T02:17:19.345Z])
// result2DS::16> (true,+I[alanchan, 57, 2023-10-31T08:45, 2023-10-31T08:55, 2023-11-03T02:17:19.345Z])
// result2DS::16> (true,+I[alanchan, 57, 2023-10-31T08:50, 2023-10-31T09:00, 2023-11-03T02:17:19.348Z])
// result2DS::2> (true,+I[alan, 62, 2023-10-31T08:50, 2023-10-31T09:00, 2023-11-03T02:17:19.348Z])
//Sliding Row-count window (assuming a processing-time attribute "proctime")
Table usersTable3 = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime().as("proctime"));
Table result3 = usersTable3
.window(Slide.over(rowInterval(10L)).every(rowInterval(5L)).on($("proctime")).as("w"))
.groupBy($("name"),$("w"))
.select($("name"),$("balance").sum().as("sum(balance)"))
;
DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(result3, Row.class);
result3DS.print("result3DS:");
//Event-time grouping windows on row intervals are currently not supported.
env.execute();
}
3、Session (Session Windows)
static void testSessionOver() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
// Session Event-time Window
Table result1 = usersTable
.window(Session.withGap(lit(10).minutes()).on($("rowtime")).as("w"))
.groupBy($("name"),$("w"))
.select($("name"),$("balance").sum().as("sum(balance)"))
;
DataStream<Tuple2<Boolean, Row>> result1DS = tenv.toRetractStream(result1, Row.class);
result1DS.print("result1DS:");
// result1DS::16> (true,+I[alanchan, 57])
// result1DS::2> (true,+I[alan, 62])
// Session Processing-time Window (assuming a processing-time attribute "proctime")
Table usersTable2 = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime().as("proctime"));
Table result2 = usersTable2
.window(Session.withGap(lit(10).minutes()).on($("proctime")).as("w"))
.groupBy($("name"),$("w"))
.select($("name"),$("balance").sum().as("sum(balance)"))
;
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
result2DS.print("result2DS:");
// result2DS::2> (true,+I[alan, 62])
// result2DS::16> (true,+I[alanchan, 57])
env.execute();
}
六、Over Windows
Over window 聚合聚合来自在标准的 SQL(OVER 子句),可以在 SELECT 查询子句中定义。与在“GROUP BY”子句中指定的 group window 不同, over window 不会折叠行。相反,over window 聚合为每个输入行在其相邻行的范围内计算聚合。
Over windows 使用 window(w: OverWindow*) 子句(在 Python API 中使用 over_window(*OverWindow))定义,并通过 select() 方法中的别名引用。
Over Window 定义了计算聚合的行范围。Over Window 不是用户可以实现的接口。相反,Table API 提供了Over 类来配置 over window 的属性。可以在事件时间或处理时间以及指定为时间间隔或行计数的范围内定义 over window 。可以通过 Over 类(和其他类)上的方法来定义 over window。
1、Unbounded Over Windows
static void testOverWithUnbounded() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
// 所有的聚合必须定义在同一个窗口上,比如同一个分区、排序和范围内。目前只支持 PRECEDING 到当前行范围(无界或有界)的窗口。
// 尚不支持 FOLLOWING 范围的窗口。ORDER BY 操作必须指定一个单一的时间属性。
Table result = usersTable
// 定义窗口
.window(
Over
.partitionBy($("name"))
.orderBy($("rowtime"))
.preceding(unresolvedCall(BuiltInFunctionDefinitions.UNBOUNDED_RANGE))
.following(unresolvedCall(BuiltInFunctionDefinitions.CURRENT_RANGE))
.as("w"))
// 滑动聚合
.select(
$("id"),
$("balance").avg().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 2> (true,+I[1, 18, 18, 18])
// 16> (true,+I[4, 28, 28, 28])
// 2> (true,+I[2, 18, 19, 18])
// 16> (true,+I[5, 28, 29, 28])
// 2> (true,+I[3, 20, 25, 18])
//over window 上的互异(互不相同、去重)聚合
Table result2 = usersTable
.window(Over
.partitionBy($("name"))
.orderBy($("rowtime"))
.preceding(unresolvedCall(BuiltInFunctionDefinitions.UNBOUNDED_RANGE))
.as("w"))
.select(
$("name"), $("balance").avg().distinct().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(result2, Row.class);
result3DS.print();
// 16> (true,+I[alanchan, 28, 28, 28])
// 2> (true,+I[alan, 18, 18, 18])
// 2> (true,+I[alan, 18, 19, 18])
// 16> (true,+I[alanchan, 28, 29, 28])
// 2> (true,+I[alan, 20, 25, 18])
env.execute();
}
2、Bounded Over Windows
static void testOverWithBounded() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
// 有界的事件时间 over window(假定有一个叫“rowtime”的事件时间属性)
// .window(Over.partitionBy($("a")).orderBy($("rowtime")).preceding(lit(1).minutes()).as("w"));
Table result = usersTable
// 定义窗口
.window(
Over
.partitionBy($("name"))
.orderBy($("rowtime"))
.preceding(lit(1).minutes())
.as("w"))
// 滑动聚合
.select(
$("id"),
$("balance").avg().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
// resultDS.print();
// 2> (true,+I[1, 18, 18, 18])
// 16> (true,+I[4, 28, 28, 28])
// 2> (true,+I[2, 18, 19, 18])
// 16> (true,+I[5, 28, 29, 28])
// 2> (true,+I[3, 20, 25, 18])
// 有界的处理时间 over window(假定有一个叫“proctime”的处理时间属性)
// .window(Over.partitionBy($("a")).orderBy($("proctime")).preceding(lit(1).minutes()).as("w"));
Table usersTable2 = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
Table result2 = usersTable2
.window(Over.partitionBy($("name")).orderBy($("rowtime")).preceding(lit(1).minutes()).as("w"))
.select(
$("id"),
$("balance").avg().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
// result2DS.print();
// 16> (true,+I[4, 28, 28, 28])
// 2> (true,+I[1, 18, 18, 18])
// 2> (true,+I[2, 18, 19, 18])
// 16> (true,+I[5, 28, 29, 28])
// 2> (true,+I[3, 20, 25, 18])
// 有界的事件时间行数 over window(假定有一个叫“rowtime”的事件时间属性)
//.window(Over.partitionBy($("a")).orderBy($("rowtime")).preceding(rowInterval(10)).as("w"));
Table usersTable3 = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
Table result3 = usersTable3
.window(Over.partitionBy($("name")).orderBy($("rowtime")).preceding(rowInterval(10L)).as("w"))
// .window(Over.partitionBy($("name")).orderBy($("rowtime")).preceding(lit(1).minutes()).as("w"))
.select(
$("id"),
$("balance").avg().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(result3, Row.class);
result3DS.print("result3DS:");
// result3DS::16> (true,+I[4, 28, 28, 28])
// result3DS::2> (true,+I[1, 18, 18, 18])
// result3DS::16> (true,+I[5, 28, 29, 28])
// result3DS::2> (true,+I[2, 18, 19, 18])
// result3DS::2> (true,+I[3, 20, 25, 18])
// 有界的处理时间行数 over window(假定有一个叫“proctime”的处理时间属性)
// .window(Over.partitionBy($("a")).orderBy($("proctime")).preceding(rowInterval(10)).as("w"));
Table usersTable4 = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
Table result4 = usersTable4
.window(Over.partitionBy($("name")).orderBy($("rowtime")).preceding(rowInterval(10L)).as("w"))
// .window(Over.partitionBy($("name")).orderBy($("rowtime")).preceding(lit(1).minutes()).as("w"))
.select(
$("id"),
$("balance").avg().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> result4DS = tenv.toRetractStream(result4, Row.class);
result4DS.print("result4DS:");
// result4DS::16> (true,+I[4, 28, 28, 28])
// result4DS::16> (true,+I[5, 28, 29, 28])
// result4DS::2> (true,+I[1, 18, 18, 18])
// result4DS::2> (true,+I[2, 18, 19, 18])
// result4DS::2> (true,+I[3, 20, 25, 18])
env.execute();
}
七、Row-based操作
1、本示例的公共代码
本部分代码是本示例的公共代码,下面的具体操作示例均以一个方法进行展示,所需要进入的import均在公共代码部分中。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
import static org.apache.flink.table.api.Expressions.lit;
import static org.apache.flink.table.api.Expressions.row;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.AggregateFunction;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIOperationWithRowbasedDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int balance;
private Long rowtime;
}
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
public static class MyMapFunction extends ScalarFunction {
public Row eval(String a) {
return Row.of(a, "pre-" + a);
}
@Override
public TypeInformation<?> getResultType(Class<?>[] signature) {
return Types.ROW(Types.STRING, Types.STRING);
}
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// testMap();
// testFlatMap();
// testAggregate();
// testGroupWindowAggregate();
testFlatAggregate();
}
}
1、Map
public static class MyMapFunction extends ScalarFunction {
public Row eval(String a) {
return Row.of(a, "pre-" + a);
}
@Override
public TypeInformation<?> getResultType(Class<?>[] signature) {
return Types.ROW(Types.STRING, Types.STRING);
}
}
/**
* 使用用户定义的标量函数或内置标量函数执行 map 操作。如果输出类型是复合类型,则输出将被展平。
* @throws Exception
*/
static void testMap() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
ScalarFunction func = new MyMapFunction();
tenv.registerFunction("func", func);
// DataStream<String> users = env.fromCollection(Arrays.asList("alan", "alanchan", "alanchanchn"));
// Table usersTable = tenv.fromDataStream(users, $("name"));
DataStream<User> users = env.fromCollection(userList);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"), $("rowtime"));
Table result = usersTable.map(call("func", $("name")));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 2> (true,+I[alan, pre-alan])
// 4> (true,+I[alan, pre-alan])
// 6> (true,+I[alanchan, pre-alanchan])
// 5> (true,+I[alanchan, pre-alanchan])
// 3> (true,+I[alan, pre-alan])
env.execute();
}
2、FlatMap
public static class MyFlatMapFunction extends TableFunction<Row> {
public void eval(String str) {
if (str.contains("#")) {
String[] array = str.split("#");
for (int i = 0; i < array.length; ++i) {
collect(Row.of(array[i], array[i].length()));
}
}
}
@Override
public TypeInformation<Row> getResultType() {
return Types.ROW(Types.STRING, Types.INT);
}
}
/**
* 使用表函数执行 flatMap 操作。
*
* @author alanchan
*
*/
static void testFlatMap() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
TableFunction func = new MyFlatMapFunction();
tenv.registerFunction("func", func);
// DataStream<User> users = env.fromCollection(userList);
// Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"), $("rowtime"));
DataStream<String> users = env.fromCollection(Arrays.asList("alan#alanchan#alanchanchn", "alan_chan_chn#", "alan-chan-chn"));
Table usersTable = tenv.fromDataStream(users, $("name"));
Table result = usersTable.flatMap(call("func", $("name")));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 13> (true,+I[alan_chan_chn, 13])
// 10> (true,+I[alan, 4])
// 12> (true,+I[alanchanchn, 11])
// 11> (true,+I[alanchan, 8])
env.execute();
}
3、Aggregate
public static class MyMinMaxAcc {
public int min = 0;
public int max = 0;
}
public static class MyMinMax extends AggregateFunction<Row, MyMinMaxAcc> {
public void accumulate(MyMinMaxAcc acc, int value) {
if (value < acc.min) {
acc.min = value;
}
if (value > acc.max) {
acc.max = value;
}
}
@Override
public MyMinMaxAcc createAccumulator() {
return new MyMinMaxAcc();
}
public void resetAccumulator(MyMinMaxAcc acc) {
acc.min = 0;
acc.max = 0;
}
@Override
public Row getValue(MyMinMaxAcc acc) {
return Row.of(acc.min, acc.max);
}
@Override
public TypeInformation<Row> getResultType() {
return new RowTypeInfo(Types.INT, Types.INT);
}
}
/**
* 使用聚合函数来执行聚合操作。你必须使用 select 子句关闭 aggregate,并且 select 子句不支持聚合函数。如果输出类型是复合类型,则聚合的输出将被展平。
*
* @throws Exception
*/
static void testAggregate() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
AggregateFunction myAggFunc = new MyMinMax();
tenv.registerFunction("myAggFunc", myAggFunc);
Table ordersTable = tenv.fromValues(
DataTypes.ROW(
// DataTypes.FIELD("key", DataTypes.BIGINT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("balance", DataTypes.INT())
),
Arrays.asList(
row("alan", 16987423),
row("alan", 16396),
row("alanchan", 1690407),
row("alanchanchn", 16409),
row("alanchan", 162424),
row("alan", 164)
));
Table usersTable = ordersTable.select($("name"),$("balance"));
// Table usersTable = tenv.fromDataStream(users, $("key"),$("name"),$("age"));
Table result = usersTable
.groupBy($("name")).
aggregate(call("myAggFunc", $("balance")))
.select($("name"), $("f0"),$("f1"));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 2> (true,+I[alan, 0, 16987423])
// 16> (true,+I[alanchan, 0, 1690407])
// 16> (true,+I[alanchanchn, 0, 16409])
env.execute();
}
4、Group Window Aggregate
/**
* 在 group window 和可能的一个或多个分组键上对表进行分组和聚合。你必须使用 select 子句关闭 aggregate。并且 select 子句不支持“*“或聚合函数。
*
* @throws Exception
*/
static void testGroupWindowAggregate() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
AggregateFunction myAggFunc = new MyMinMax();
tenv.registerFunction("myAggFunc", myAggFunc);
List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L),
new User(5L, "alanchan", 29, 1698742362424L)
);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
Table result = usersTable
.window(Tumble.over(lit(5).minutes())
.on($("rowtime"))
.as("w")) // 定义窗口
.groupBy($("name"), $("w")) // 以键和窗口分组
.aggregate(call("myAggFunc", $("balance")))
.select($("name"), $("f0"), $("f1"), $("w").start(), $("w").end()); // 访问窗口属性与聚合结果
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 2> (true,+I[alan, 0, 25, 2023-10-31T08:50, 2023-10-31T08:55])
// 16> (true,+I[alanchan, 0, 29, 2023-10-31T08:50, 2023-10-31T08:55])
env.execute();
}
5、FlatAggregate
/**
* Top2 Accumulator。
*/
public static class Top2Accum {
public Integer first;
public Integer second;
}
/**
* 用户定义的聚合函数 top2。
*/
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void merge(Top2Accum acc, java.lang.Iterable<Top2Accum> iterable) {
for (Top2Accum otherAcc : iterable) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
public void emitValue(Top2Accum acc, Collector<Tuple2<Integer, Integer>> out) {
// 下发 value 与 rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
/**
* 和 GroupBy Aggregation 类似。使用运行中的表之后的聚合算子对分组键上的行进行分组,以按组聚合行。
* 和 AggregateFunction 的不同之处在于,TableAggregateFunction 的每个分组可能返回0或多条记录。
* 必须使用 select 子句关闭 flatAggregate。并且 select 子句不支持聚合函数。
*
* @throws Exception
*/
static void testFlatAggregate() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
env.setParallelism(1);
tenv.registerFunction("top2", new Top2());
Table ordersTable = tenv.fromValues(
DataTypes.ROW(
// DataTypes.FIELD("key", DataTypes.BIGINT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("balance", DataTypes.INT())
),
Arrays.asList(
row("alan", 16987423),
row("alan", 16396),
row("alanchan", 1690407),
row("alanchanchn", 16409),
row("alanchan", 162424),
row("alan", 164)
));
// Table orders = tenv.from("Orders");
Table result = ordersTable
.groupBy($("name"))
.flatAggregate(call("top2", $("balance")))
.select($("name"), $("f0").as("balance"), $("f1").as("rank"));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// (true,+I[alan, 16987423, 1])
// (false,-D[alan, 16987423, 1])
// (true,+I[alan, 16987423, 1])
// (true,+I[alan, 16396, 2])
// (true,+I[alanchan, 1690407, 1])
// (true,+I[alanchanchn, 16409, 1])
// (false,-D[alanchan, 1690407, 1])
// (true,+I[alanchan, 1690407, 1])
// (true,+I[alanchan, 162424, 2])
// (false,-D[alan, 16987423, 1])
// (false,-D[alan, 16396, 2])
// (true,+I[alan, 16987423, 1])
// (true,+I[alan, 16396, 2])
env.execute();
}
八、时态表的join-java版本
假设有一张订单表Orders和一张汇率表Rates,那么订单来自于不同的地区,所以支付的币种各不一样,那么假设需要统计每个订单在下单时候Yen币种对应的金额。
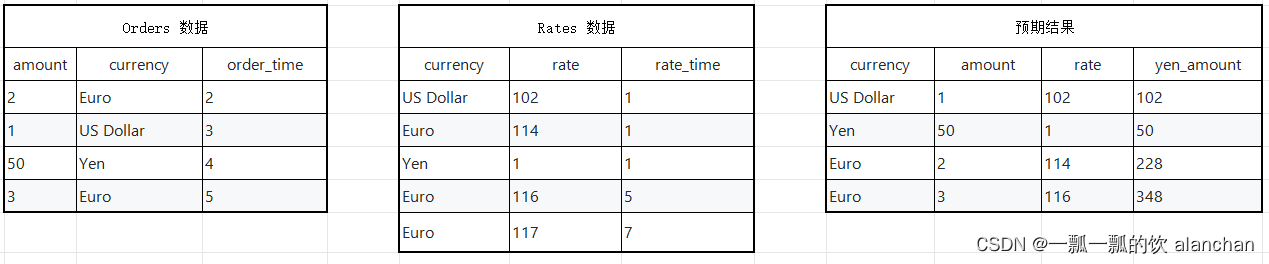
1、统计需求对应的SQL
SELECT o.currency, o.amount, r.rate
o.amount * r.rate AS yen_amount
FROM
Orders AS o,
LATERAL TABLE (Rates(o.rowtime)) AS r
WHERE r.currency = o.currency
2、Without connnector 实现代码
就是使用静态数据实现,其验证结果在代码中的注释部分。
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
import static org.apache.flink.table.api.Expressions.$;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
public class TestTemporalTableFunctionDemo {
// 维表
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Rate {
private String currency;
private Integer rate;
private Long rate_time;
}
// 事实表
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private Long total;
private String currency;
private Long order_time;
}
final static List<Rate> rateList = Arrays.asList(
new Rate("US Dollar", 102, 1L),
new Rate("Euro", 114, 1L),
new Rate("Yen", 1, 1L),
new Rate("Euro", 116, 5L),
new Rate("Euro", 119, 7L)
);
final static List<Order> orderList = Arrays.asList(
new Order(2L, "Euro", 2L),
new Order(1L, "US Dollar", 3L),
new Order(50L, "Yen", 4L),
new Order(3L, "Euro", 5L)
);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// order 实时流 事实表
DataStream<Order> orderDs = env.fromCollection(orderList)
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(10))
.withTimestampAssigner((order, rTimeStamp) -> order.getOrder_time()));
// rate 实时流 维度表
DataStream<Rate> rateDs = env.fromCollection(rateList)
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Rate>forBoundedOutOfOrderness(Duration.ofSeconds(10))
.withTimestampAssigner((rate, rTimeStamp) -> rate.getRate_time()));
// 转变为Table
Table orderTable = tenv.fromDataStream(orderDs, $("total"), $("currency"), $("order_time").rowtime());
Table rateTable = tenv.fromDataStream(rateDs, $("currency"), $("rate"), $("rate_time").rowtime());
tenv.createTemporaryView("alan_orderTable", orderTable);
tenv.createTemporaryView("alan_rateTable", rateTable);
// 定义一个TemporalTableFunction
TemporalTableFunction rateDim = rateTable.createTemporalTableFunction($("rate_time"), $("currency"));
// 注册表函数
// tenv.registerFunction("alan_rateDim", rateDim);
tenv.createTemporarySystemFunction("alan_rateDim", rateDim);
String sql = "select o.*,r.rate from alan_orderTable as o,Lateral table (alan_rateDim(o.order_time)) r where r.currency = o.currency ";
// 关联查询
Table result = tenv.sqlQuery(sql);
// 打印输出
DataStream resultDs = tenv.toAppendStream(result, Row.class);
resultDs.print();
// rate 流数据(维度表)
// rateList
// order 流数据
// orderList
// 控制台输出
// 2> +I[2, Euro, 1970-01-01T00:00:00.002, 114]
// 5> +I[50, Yen, 1970-01-01T00:00:00.004, 1]
// 16> +I[1, US Dollar, 1970-01-01T00:00:00.003, 102]
// 2> +I[3, Euro, 1970-01-01T00:00:00.005, 116]
env.execute();
}
}
3、With connnector 实现代码
本处使用的是kafka作为数据源来实现。其验证结果在代码中的注释部分。
1)、bean定义
package org.tablesql.join.bean;
import java.io.Serializable;
import lombok.Data;
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
@Data
public class CityInfo implements Serializable {
private Integer cityId;
private String cityName;
private Long ts;
}
package org.tablesql.join.bean;
import java.io.Serializable;
import lombok.Data;
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
@Data
public class UserInfo implements Serializable {
private String userName;
private Integer cityId;
private Long ts;
}
2)、序列化定义
package org.tablesql.join.bean;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
public class CityInfoSchema implements DeserializationSchema<CityInfo> {
@Override
public CityInfo deserialize(byte[] message) throws IOException {
String jsonStr = new String(message, StandardCharsets.UTF_8);
CityInfo data = JSON.parseObject(jsonStr, new TypeReference<CityInfo>() {});
return data;
}
@Override
public boolean isEndOfStream(CityInfo nextElement) {
return false;
}
@Override
public TypeInformation<CityInfo> getProducedType() {
return TypeInformation.of(new TypeHint<CityInfo>() {
});
}
}
package org.tablesql.join.bean;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
public class UserInfoSchema implements DeserializationSchema<UserInfo> {
@Override
public UserInfo deserialize(byte[] message) throws IOException {
String jsonStr = new String(message, StandardCharsets.UTF_8);
UserInfo data = JSON.parseObject(jsonStr, new TypeReference<UserInfo>() {});
return data;
}
@Override
public boolean isEndOfStream(UserInfo nextElement) {
return false;
}
@Override
public TypeInformation<UserInfo> getProducedType() {
return TypeInformation.of(new TypeHint<UserInfo>() {
});
}
}
3)、实现
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
package org.tablesql.join;
import static org.apache.flink.table.api.Expressions.$;
import java.time.Duration;
import java.util.Properties;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import org.tablesql.join.bean.CityInfo;
import org.tablesql.join.bean.CityInfoSchema;
import org.tablesql.join.bean.UserInfo;
import org.tablesql.join.bean.UserInfoSchema;
public class TestJoinDimByKafkaEventTimeDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Kafka的ip和要消费的topic,//Kafka设置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");
props.setProperty("group.id", "kafkatest");
// 读取用户信息Kafka
FlinkKafkaConsumer<UserInfo> userConsumer = new FlinkKafkaConsumer<UserInfo>("user", new UserInfoSchema(),props);
userConsumer.setStartFromEarliest();
userConsumer.assignTimestampsAndWatermarks(WatermarkStrategy
.<UserInfo>forBoundedOutOfOrderness(Duration.ofSeconds(0))
.withTimestampAssigner((user, rTimeStamp) -> user.getTs()) // 该句如果不加,则是默认为kafka的事件时间
);
// 读取城市维度信息Kafka
FlinkKafkaConsumer<CityInfo> cityConsumer = new FlinkKafkaConsumer<CityInfo>("city", new CityInfoSchema(), props);
cityConsumer.setStartFromEarliest();
cityConsumer.assignTimestampsAndWatermarks(WatermarkStrategy
.<CityInfo>forBoundedOutOfOrderness(Duration.ofSeconds(0))
.withTimestampAssigner((city, rTimeStamp) -> city.getTs()) // 该句如果不加,则是默认为kafka的事件时间
);
Table userTable = tableEnv.fromDataStream(env.addSource(userConsumer), $("userName"), $("cityId"), $("ts").rowtime());
Table cityTable = tableEnv.fromDataStream(env.addSource(cityConsumer), $("cityId"), $("cityName"),$("ts").rowtime());
tableEnv.createTemporaryView("userTable", userTable);
tableEnv.createTemporaryView("cityTable", cityTable);
// 定义一个TemporalTableFunction
TemporalTableFunction dimCity = cityTable.createTemporalTableFunction($("ts"), $("cityId"));
// 注册表函数
// tableEnv.registerFunction("dimCity", dimCity);
tableEnv.createTemporarySystemFunction("dimCity", dimCity);
Table u = tableEnv.sqlQuery("select * from userTable");
// u.printSchema();
tableEnv.toAppendStream(u, Row.class).print("user流接收到:");
Table c = tableEnv.sqlQuery("select * from cityTable");
// c.printSchema();
tableEnv.toAppendStream(c, Row.class).print("city流接收到:");
// 关联查询
Table result = tableEnv
.sqlQuery("select u.userName,u.cityId,d.cityName,u.ts " +
"from userTable as u " +
", Lateral table (dimCity(u.ts)) d " +
"where u.cityId=d.cityId");
// 打印输出
DataStream resultDs = tableEnv.toAppendStream(result, Row.class);
resultDs.print("\t关联输出:");
// 用户信息格式:
// {"userName":"user1","cityId":1,"ts":0}
// {"userName":"user1","cityId":1,"ts":1}
// {"userName":"user1","cityId":1,"ts":4}
// {"userName":"user1","cityId":1,"ts":5}
// {"userName":"user1","cityId":1,"ts":7}
// {"userName":"user1","cityId":1,"ts":9}
// {"userName":"user1","cityId":1,"ts":11}
// kafka-console-producer.sh --broker-list server1:9092 --topic user
// 城市维度格式:
// {"cityId":1,"cityName":"nanjing","ts":15}
// {"cityId":1,"cityName":"beijing","ts":1}
// {"cityId":1,"cityName":"shanghai","ts":5}
// {"cityId":1,"cityName":"shanghai","ts":7}
// {"cityId":1,"cityName":"wuhan","ts":10}
// kafka-console-producer.sh --broker-list server1:9092 --topic city
// 输出
// city流接收到::6> +I[1, beijing, 1970-01-01T00:00:00.001]
// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.004]
// city流接收到::6> +I[1, shanghai, 1970-01-01T00:00:00.005]
// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.005]
// city流接收到::6> +I[1, shanghai, 1970-01-01T00:00:00.007]
// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.007]
// city流接收到::6> +I[1, wuhan, 1970-01-01T00:00:00.010]
// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.009]
// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.011]
// 关联输出::12> +I[user1, 1, beijing, 1970-01-01T00:00:00.001]
// 关联输出::12> +I[user1, 1, beijing, 1970-01-01T00:00:00.004]
// 关联输出::12> +I[user1, 1, shanghai, 1970-01-01T00:00:00.005]
// 关联输出::12> +I[user1, 1, shanghai, 1970-01-01T00:00:00.007]
// 关联输出::12> +I[user1, 1, shanghai, 1970-01-01T00:00:00.009]
env.execute("joinDemo");
}
}
以上,本文介绍了表的常见操作(比如union等、排序等以及insert)、group/over window 、 基于行的操作和时态表join操作等具体事例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Stream流总结:从入门到精通
- Journal of King Saud University - Computer and Information Sciences投稿经验
- Python - 深夜数据结构与算法之 Disjoint-Set
- YOLOv5改进 | 主干篇 | 利用SENetV2改进网络结构 (全网首发改进)
- 赠人玫瑰,手有余香,分享5款让人爱不释手的软件
- 【C++ Primer Plus学习记录】?:运算符
- 一卡通水控电控开发踩过的坑
- ReactNative 常见问题及处理办法(加固混淆)
- Enter opening balance: $688
- 编程笔记 html5&css&js 009 HTML链接