mysql-实战案例 (超详细版)

?🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
?博客主页:小小恶斯法克的博客
🎈该系列文章专栏:重拾MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注!???
 ?
?
目录
?查询员工的姓名、年龄、职位、部门信息 (隐式内连接,需要消除笛卡尔积)
?查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接)
?查询拥有员工的部门ID、部门名称 (难点在于有一个部门是没有员工的)
?查询所有年龄大于40岁的员工, 及其归属的部门名称; 如果员工没有分配部门, 也需要展示出来(因为没有部门的也要展示,只能使用外连接,外连接大部分采用左外,因为右外也可以通过调换表顺序改为左外)
?查询所有员工的工资等级 (发现跟部门没有关系,而员工表中只有工资,没有等级,所以涉及新表salgrade)
?查询所有学生的选课情况, 展示出学生名称, 学号, 课程名称
🚀??????多表查询综合案例
数据环境准备:
create table salgrade(
grade int, --薪资等级
losal int, --这个等级的最低薪资
hisal int --这个等级的最高薪资
) comment '薪资等级表';
insert into salgrade values (1,0,3000);
insert into salgrade values (2,3001,5000);
insert into salgrade values (3,5001,8000);
insert into salgrade values (4,8001,10000);
insert into salgrade values (5,10001,15000);
insert into salgrade values (6,15001,20000);
insert into salgrade values (7,20001,25000);
insert into salgrade values (8,25001,30000);
在这个案例中,我们主要运用上面所讲解的多表查询的语法,完成以下的12个需求即可,而这里主要涉? 及到的表就三张:emp员工表、dept部门表、salgrade薪资等级表 。
?查询员工的姓名、年龄、职位、部门信息 (隐式内连接,需要消除笛卡尔积)
表 : empcp , dept
连接条件: empcp.dept_id = dept.id
这里再重复一下,如果给表起了别名你就必须要用别名去定义字段了
select e.name , e.age , e.job , d.name from empcp e , dept d where e.dept_id = d.id;?执行:
 ?
?
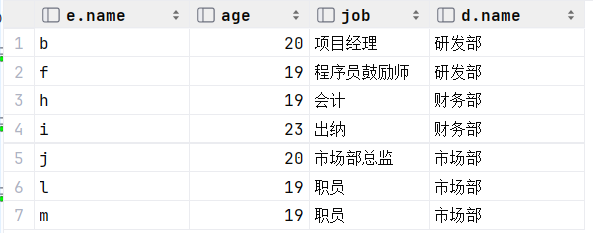
?查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接)
表 : empcp , dept
连接条件: empcp.dept_id = dept.id
在DQL语句中我们的查询条件在哪个关键字之后?是在where之后
select e.name , e.age , e.job , d.name from empcp e inner join dept d on e.dept_id =
d.id where e.age < 30;
执行:
 ?
?
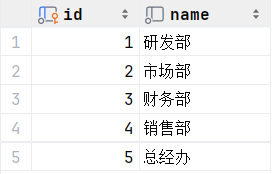
?查询拥有员工的部门ID、部门名称 (难点在于有一个部门是没有员工的)
表 : empcp , dept
连接条件: empcp.dept_id = dept.id
换个思路:我们要去查拥有员工的部门,其实就是查询部门表和员工表之间的交集,怎么去查询两个表之间的交集,其实就是用内连接
select? * from empcp e , dept d where e.dept_id = d.id ;
而我们只要返回部门id,和部门名称,所以把*改为d.id,d.name
?
发现重复,去重,用关键字distinct
select distinct d.id , d.name from empcp e , dept d where e.dept_id = d.id;执行:
 ?
?
?查询所有年龄大于40岁的员工, 及其归属的部门名称; 如果员工没有分配部门, 也需要展示出来(因为没有部门的也要展示,只能使用外连接,外连接大部分采用左外,因为右外也可以通过调换表顺序改为左外)
表 : empcp , dept
连接条件: empcp.dept_id = dept.id
select * from empcp e left join dept d on e.dept_id = d.id where e.age > 40;
然后把*换成员工表的所有字段e.*,和部门名称d.name,如下
select e.*, d.name from empcp e left join dept d on e.dept_id = d.id where e.age >
40 ;
执行:
 ?
?
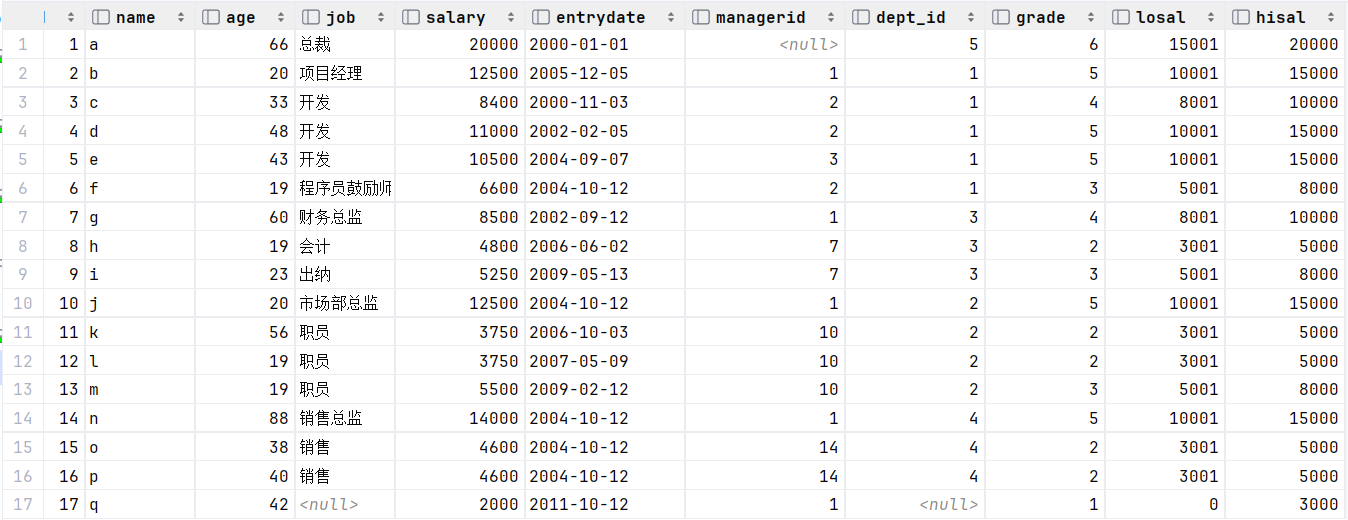
?查询所有员工的工资等级 (发现跟部门没有关系,而员工表中只有工资,没有等级,所以涉及新表salgrade)
表 : empcp , salgrade
连接条件 : empcp.salary >= salgrade.losal and empcp.salary <= salgrade.hisal
1.empcp表与salgrade表进行联合查询
2.empcp表与salgrade之间有没有外键关联?没有,如果要说empcp和salgrade之间没有外键关联,怎么产生关系呢?它们之间产生关系实际上通过一个字段salary产生关系,我们要去判断员工薪资等级,就要让这个薪资介于最小值与最大值之间,这就是连接条件
?
select *? from empcp e,salgrade s where e.salary >= s.losal and e.salary <= s.hisal ;
再改细节,*变为empcp表的全部字段e*,和salgrade表中的grade字段s.grade
-- 方式一
select e.* , s.grade , s.losal, s.hisal from empcp e , salgrade s where e.salary >= s.losal and e.salary <= s.hisal;
-- 方式二
select e.* , s.grade , s.losal, s.hisal from empcp e , salgrade s where e.salary between s.losal and s.hisal;
执行:
 ?
?
?查询 "研发部" 所有员工的信息及工资等级
表 : empcp , salgrade , dept
连接条件 : empcp.salary between salgrade.losal and salgrade.hisal , empcp.dept_id = dept.id
查询条件 : dept.name = '研发部'
梳理:
1.因为员工表中只有部门的id,而这里要根据部门的名词去查,所以这个里面涉及的表结构将会是三张表
2.那么可想而知,三张表我们连接连接的条件会有几个?2个
3.联查n张表,至少需要n-1个条件
4.我们去梳理连接条件的时候,不要一股脑的梳理三张表的条件,两个两个去梳理
5.首先empcp和salgrade的连接条件我们已经梳理过了,就是empcp.salary between salgrade.losal and salgrade.hisal
6.再梳理第二个条件empcp表和dept表它们什么条件,不就是empcp.dept_id = dept.id
代码思路:
1.select * from empcp e , dept d , salgrade s ; 这种我们称之为隐式内连接
2.连接的条件将在where之后编写?
3.select * from empcp e , dept d , salgrade s where e.dept_id = d.id;
4.如果是多个连接条件之间使用and进行连接
5.select * from empcp e , dept d , salgrade s where e.dept_id = d.id and e.salary between s.losal and s.hisal;
6为了让语法更加清晰,可以用括号完善一下
7.select * from empcp e , dept d , salgrade s where e.dept_id = d.id?and (e.salary between s.losal and s.hisal);
8.还有一个查询条件,记住如果说在连接查询中还有额外的查询条件,此时直接在where后继续跟着写就可以
9.select * from empcp e , dept d , salgrade s where e.dept_id = d.id?and (e.salary between s.losal and s.hisal) and d.name = '研发部';
10.最后将*改动,写为需要取的字段e.*员工信息,s.grade工资等级,如下:
select e.* , s.grade from empcp e , dept d , salgrade s where e.dept_id = d.id and (
e.salary between s.losal and s.hisal ) and d.name = '研发部';
我们可以格式化一下代码更清楚
--
select e.*, s.grade
from empcp e,
dept d,
salgrade s
where e.dept_id = d.id
and (
e.salary between s.losal and s.hisal)
and d.name = '研发部';
执行:
 ?
?
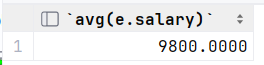
?查询 "研发部" 员工的平均工资
表 : empcp , dept
连接条件? : empcp.dept_id = dept.id
要求平均数的聚合函数是avg
select * from empcp e , dept d where e.dept_id = d.id ;?
还有一个查询条件 查询研发部 d.name = "研发部"
select * from empcp e , dept d where e.dept_id = d.id and d.name = "研发部"
基本的sql编写完了再对*进行优化,如下
select avg(e.salary) from empcp e, dept d where e.dept_id = d.id and d.name = '研发部';执行:
 ?
?
?查询工资比 "n"?高的员工信息。
思路:
拆解为两步
1.查询 "n" 的薪资
select salary from empcp where name = 'n';2.查询比她工资高的员工数据
select * from empcp where salary > ( select salary from empcp where name = 'n' ); --后面其实就是刚刚查出来的14000,这个14000就是上面那条语句查询返回的结果,所以我们要通过子查询来实现,把上面的语句放到下面,然后再加上括号
执行:
 ?
?
执行:
 ?
?
?查询比平均薪资高的员工信息
思路:
拆解为两步
1.查询员工的平均薪资
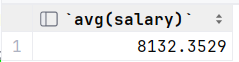
select avg(salary) from empcp;2.查询比平均薪资高的员工信息
select * from empcp where salary > ( select avg(salary) from empcp );
执行:
 ?
?
执行:
 ?
?
?查询低于本部门平均工资的员工信息
思路:
拆解为两步
1.查询指定部门平均薪资
比如查询1号部门的平均薪资
select * from emp e1 where e1.dept_id = 1
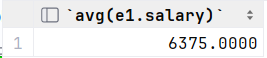
*改avg(e1.salary) 此时只能用别名e1
select avg(e1.salary) from empcp e1 where e1.dept_id = 1; select avg(e1.salary) from empcp e1 where e1.dept_id = 2;2.查询低于本部门平均工资的员工信息
思路:
1.首先查询出所有的员工数据
2.select * from empcp;
3.此时所有的员工数据都拿到了,在此基础上增加一个查询条件,salary<当前部门的平均薪资
4.当前部门的平均薪资,只需要把当前的部门薪资传递下来,也就是上面的那句sql语句
select * from empcp where salary < (select avg(e1.salary) from empcp e1 where e1.dept_id = 1);
5.但是里面写死的部门id我们要替换掉,比如当我们去判断第一行数据时,需要传递的部门id是5,去判断第二行数据时,需要传递的部门id是1
6.此时我们只需要把dept_id这个字段传进来即可,我们需要把empcp起一个别名e2
7.这里就应该是select * from empcp e2 where e2.salary < (select avg(e1.salary) from empcp e1 where e1.dept_id = 1);e2.salary < 当前部门的平均薪资,再把当前部门传进来
8.当前部门应该就是e2.dept_id,代码如下
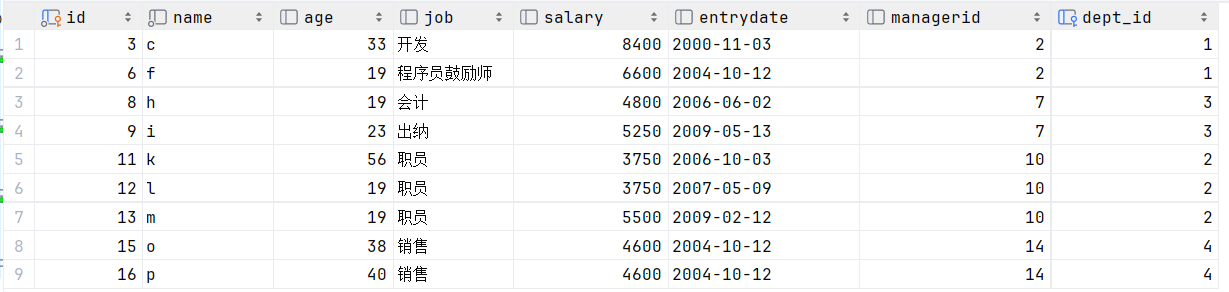
select * from empcp e2 where e2.salary < ( select avg(e1.salary) from empcp e1 where e1.dept_id = e2.dept_id );
执行:
 ?
?
执行:
 ?
?
为了验证查询到的字段,我们可以在*之后增加一个输出字段,?我们可以把子查询直接粘贴过来,这个不就是当前部门的平均薪资嘛,我们再取一个别名为”当前部门的平均薪资“
select e2.*, (select avg(e1.salary) from empcp e1 where e1.dept_id = e2.dept_id) '当前部门平均薪资'
from empcp e2
where e2.salary < (select avg(e1.salary) from empcp e1 where e1.dept_id = e2.dept_id);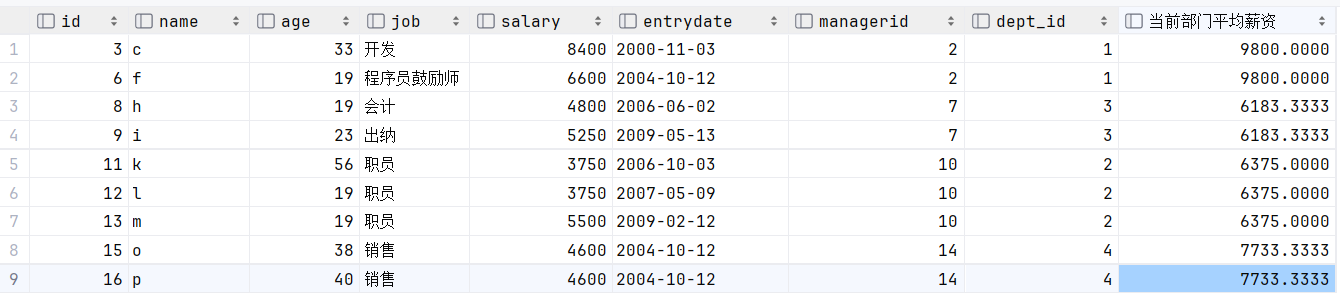 ?对比后发现,是正确的
?对比后发现,是正确的
?查询所有的部门信息, 并统计部门的员工人数
1.先查询所有部门信息
2.select id,name from dept;
3.此时查出了所有的部门id,以及部门的名称
4.接着考虑如何统计部门的员工数量
5.select count(*) from empcp where dept_id = 1;
6.这条语句是统计1号部门的员工数量
7.接下来需要考虑,在上面的语句下如何统计1号部门的员工数量,2号部门的员工数量
8.我再添加一个查询id,此时select id,name,id '人数'?from dept;
9.这个id本身不是查询人数,我想要后面的dept.id查询为人数,能不能根据id查询出人数呢?可以,就是这句,统计1号部门的员工数量select count(*) from empcp where dept_id = 1;
10.变为select id,name,(select count(*) from empcp where dept_id = id) '人数'?from dept;? 加上括号,变成一个子查询存在
11.这里面最需要注意的是标红的dept_id是empcp表的id,紫id是dept表的id
12.此时就要给表起对应的别名,给empcp起别名为e,给dept起名为d
13.select d.id, d.name,(select count(*) from empcp e where e.dept_id =d.id) '人数'?from dept? d;
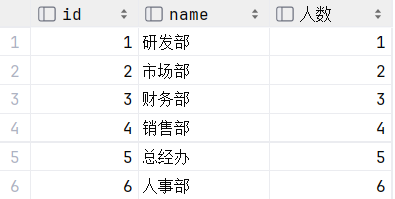
select d.id, d.name , ( select count(*) from empcp e where e.dept_id = d.id ) '人数' from dept d;执行:
 ?
?
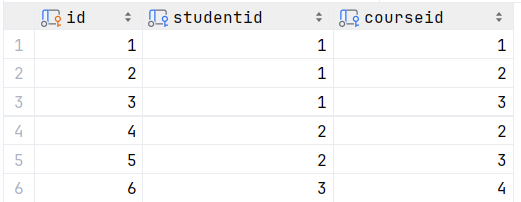
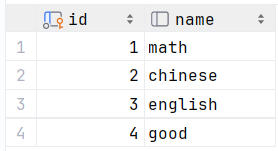
?查询所有学生的选课情况, 展示出学生名称, 学号, 课程名称
表 : student , course , student_course
连接条件: student.id = student_course.studentid , course.id = student_course.courseid
1.之前讲解表与表之间的关系时,特别说明了学生和课程的关系是多对多的关系,一个学生可以选择多个课程,一个课程也可以供多个学生选择,涉及的表有三张
2.这三张表会通过中间表student_course来维护它们之间的关系
3.三张表在消除笛卡尔积的时候需要3-1个关系
4.先梳理一下连接条件
5.student.id = student_course.studentid,course.id =?student_course.courseid
ps:第一张是student表,第二张是student_course表,第三张是course表
??
6.select * from student s,student_course sc,course c where s.id = sc.studentid and??c.id = sc.courseid ;
7.再对*优化
8.我们只需要展示学生的姓名, 学号,课程也就是s.name , s.no , c.name ,代码如下
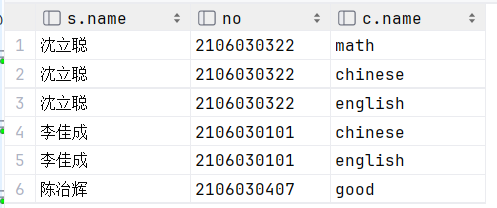
select s.name , s.no , c.name from student s , student_course sc , course c where
s.id = sc.studentid and sc.courseid = c.id ;
执行:
 ?
?
总结:本篇博客到这里就结束了,希望能帮到你,谢谢你这么好看还来看我
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- EOS链Ubuntu环境Install Prebuilt Binaries(安装预构建的二进制文件)的安装
- 软件测试概念及分类整理汇总
- ICC2:illegal dimension route
- 2-5基础算法-双指针/二分
- “华为杯” 第二十届中国研究生数学建模竞赛 数模之星、华为之夜与颁奖大会
- JavaScript二
- 【服务器数据恢复】服务器迁移数据时lun数据丢失的数据恢复案例
- JavaScript实现字符串首字母大写、翻转字符串、获取用户选定的文本
- linux下docker搭建mysql8
- 【css技巧】文本超出两行显示省略号