强化学习Double DQN方法玩雅达利Breakout游戏完整实现代码与评估pytorch
1. 实验环境
1.1 硬件配置
- 处理器:2*AMD EPYC 7773X 64-Core
- 内存:1.5TB
- 显卡:8*NVIDIA GeForce RTX 3090 24GB
1.2 工具环境
- Python:3.10.12
- Anaconda:23.7.4
- 系统:Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)
- IDE:VS Code 1.85.1
- gym:0.26.2
- Pytorch:2.1.2
2. 实现
2.1 Breakout for Atari 2600
Breakout是一款经典的雅达利游戏,也就是我们所熟知的“打砖块”。玩家需要左右移动在屏幕下方的短平板子将一颗不断弹跳的小球反弹回屏幕上方,使其将一块块矩形砖块组成的六行砖块墙面打碎,并防止小球从屏幕底部掉落。在Atari 2600版本的Breakout中,玩家共有5次小球掉落机会,一旦用完就标志游戏结束,每打掉一块砖块得1分,全部打掉则游戏胜利结束。
在由OpenAI编写和维护的公开库Gym中,具备对Atari Breakout游戏的强化学习环境实现,无需自行编写。
2.2 Double Deep-Q Network
Deep-Q Network (DQN)方法是一种利用深度神经网络进行动作价值函数近似的Q-Learning强化学习方法。从价值函数学习的角度来说,在最朴素的Q-Learning方法中,对于状态空间和动作空间离散且简单的环境,可以使用Q table直接学习动作价值函数,从而使用贪心策略从Q table中选择动作价值最高的动作。然而更多情况下的动作价值函数并不能由Q table直接表示,因此衍生出了动作价值函数近似方法,可以引入多样的近似手段实现动作价值函数的近似逼近,这些手段包括简单的线性函数近似、更为强大的神经网络、决策树以及基于傅里叶或小波变换的方法等。而本节所实现的DQN,就是使用深度神经网络来近似动作价值函数。从经验采样学习的角度来说,对动作价值函数的近似可以在蒙特卡洛 (Monte Carlo)方法和时序差分 (Temporal Difference, TD)方法上进行实现,而其中蒙特卡洛方法需要采样完整的一幕后才能进行学习,而时序差分方法可以只采样部分步骤,特别是TD(0)时序差分方法,在每步都可以进行价值函数更新。而本节所实现的DQN就是一种TD(0)时序差分方法。
下面将具体介绍如何实现Double Deep-Q Network (DDQN)强化学习方法,用于在Breakout游戏上进行训练和评估。
2.2.1 基于卷积神经网络的Deep Q Network实现
Deep Q Network (DQN)的输入连续4帧游戏屏幕图像的4通道84*84图像,进入三个卷积层,在最后的全连接层展平输出动作概率,每层后均使用ReLU激活函数激活。详细的DQN神经网络结构参数如表2-1和图2-2所示。
| 层类型\参数名称 | 输入通道数/特征数 | 输出通道数/特征数 | 核尺寸 | 步长 |
|---|---|---|---|---|
| Conv1 | 4 | 32 | 8 | 4 |
| Conv2 | 32 | 64 | 4 | 2 |
| Conv3 | 64 | 64 | 3 | 1 |
| Dense | 7764 | 512 | \ | \ |
| Out | 512 | 4 | \ | \ |

2.2.2 Double DQN agent
在普通的DQN agent中,只有一个Q-Network用于估计动作价值函数时,存在过估计问题,会导致学习到的策略不稳定。Hasselt等人2015年提出的Double Q-Learning很好缓解了过估计问题[ Deep Reinforcement Learning with Double Q-learning]。其中agent使用主网络和目标网络,主网络用于计算当前状态下每个动作的估计值,而目标网络则用于计算下一个状态的最大动作价值的估计值。
动作选择方面,采用的是典型的epsilon-greedy策略。每步在当前状态下以的概率选择随机动作,以
(
1
?
?
)
(1-\epsilon)
(1??)的概率通过贪心策略选择主网络给出的最大动作价值对应的动作。
遵循DQN agent的经典设置,本节也采用了经验回放缓冲区 (Experience Replay Buffer)方法,用于在训练时将采样的
(
s
,
a
,
r
,
s
′
)
(s,a,r,s')
(s,a,r,s′)轨迹缓存,并提供随机批量采样供给网络进行小批量学习,可以有效提高训练稳定性和效率[ Playing Atari with Deep Reinforcement Learning]。本节Double DQN方法中的经验缓冲区在缓存满前并不开始训练,具有冷启动特征。
对于主网络的学习,使用SmoothL1Loss,使用目标网络的价值估计结果作为监督,与主网络的价值估计结果计算loss,并对主网络进行梯度反向传播更新参数。
L i ( θ i ) = E ( s , a , r , s ′ ) ~ D [ S m o o t h L 1 L o s s ( y i , Q ( s , a ; θ i ) ) ] L_i(\theta _i) = \mathbb{E}_{(s,a,r,s') \sim D} [SmoothL1Loss(y_i,Q(s,a;\theta_i))] Li?(θi?)=E(s,a,r,s′)~D?[SmoothL1Loss(yi?,Q(s,a;θi?))]
y i = E ( s , a , r , s ′ ) ~ D [ r + γ max ? a ′ Q ( s ′ , a ′ ; θ c ? ? i / c ? ) ] y_i=\mathbb{E}_{(s,a,r,s') \sim D} [r+\gamma \max_{a'}Q(s',a';\theta_{c* \lfloor i/c \rfloor })] yi?=E(s,a,r,s′)~D?[r+γa′max?Q(s′,a′;θc??i/c??)]
S m o o t h L 1 L o s s ( x , y ) = 1 n ∑ j = 1 n { 0.5 ( x j ? y j ) 2 i f ∣ x j ? y j ∣ < δ δ ? ∣ x j ? y j ∣ ? 0.5 ? δ 2 o t h e r w i s e SmoothL1Loss(x,y)=\frac{1}{n} \sum^n_{j=1} \left\{ \begin{aligned} & 0.5(x_j-y_j)^2 & if |x_j-y_j|<\delta\\ & \delta * |x_j-y_j|-0.5*\delta^2 &otherwise \end{aligned} \right. SmoothL1Loss(x,y)=n1?j=1∑n?{?0.5(xj??yj?)2δ?∣xj??yj?∣?0.5?δ2?if∣xj??yj?∣<δotherwise?
其中 Q ( s , a ; θ i ) Q(s,a;\theta_i) Q(s,a;θi?)是主网络在第 i i i次迭代时,在状态 s s s下采取动作 a a a所估计的动作价值, y i y_i yi?是由奖励 r r r和目标网络计算组合得到的目标值。特别地,由于目标网络每隔 c c c次迭代与主网络参数同步一次,因此除了初始时相同,其余时候的目标网络参数为上次同步,即第 c ? ? i / c ? c* \lfloor i/c \rfloor c??i/c?次迭代的参数。
2.2.3 模型训练技巧
平衡探索与利用:这是强化学习方法中几乎无法避开的主题,探索和利用的平衡牵涉到模型性能和训练效率,因此需要设置合适地训练策略来使得agent平衡探索和利用。在本节的实现中,探索与利用的平衡主要通过训练时选择动作所使用的epsilon-greedy策略来实现,更具体而言是由参数epsilon控制。本节方法首先在前期一定步数内只进行完全随机动作选择来进行探索。此外还采用了指数衰减式的动态epsilon,使得训练前期可以进行最大化的探索,而在后期则最大化利用agent学习的策略。如下式,在第
t
t
t步时的定义为:
?
t
=
?
E
N
D
+
(
?
S
T
A
R
T
?
?
E
N
D
)
?
e
?
t
/
?
D
E
C
A
Y
\epsilon_t = \epsilon _{END} + (\epsilon _{START}-\epsilon _{END})*e^{-t/\epsilon _{DECAY}}
?t?=?END?+(?START???END?)?e?t/?DECAY?
其中
?
S
T
A
R
T
\epsilon _{START}
?START?为epsilon在起步时的最大值,\epsilon _{END}为衰减结束时的最小值,
?
D
E
C
A
Y
\epsilon _{DECAY}
?DECAY?为衰减过程控制系数,
?
D
E
C
A
Y
\epsilon _{DECAY}
?DECAY?越大,衰减过程越长。当
t
t
t不断增大,$\epsilon_t $的值将不断逼近。
Gym环境配置:Gym提供了wrapper方式对环境进行修改配置,结合训练效率方面的考虑,需要对环境的可观测状态进行和每幕结束时机进行修改。
在Breakout-v5环境中,可观测状态主要是一幅三通道彩色图像,形状为(210, 160, 3),值为[0,255]的8bit无符号整数。由于彩色在此游戏中并没有特殊含义,去除后不影响游戏进行,因此首先将将图像的三通道彩色通过OpenCV库处理为单通道灰度图,形状为(210, 160)。进一步地,为了节省存储空间,加快训练速度,将该灰度图压缩变形为(84, 84)的方形图像。此外,在Breakout游戏中,玩家每次有5次机会,当小球第5次掉落时游戏结束,只能重置。为了使得agent学习到不让小球掉落的重要性,训练时将每次小球掉落作为一幕的结束,而本文若无特殊说明,则一幕仍指以第5次小球掉落为结束的一局游戏。
3. 分析评估
本节将分析介绍2.2和2.3小节实现的Double DQN方法在2.1小结介绍的Breakout游戏上的训练和评估表现。
设置超参数如表3-1所示,本节所有针对Double DQN的实验除特殊说明外所有超参数均相同。
| 超参数名称 | 值 | 作用 |
|---|---|---|
| BATCH_SIZE | 32 | 批量大小 |
| GAMMA | 0.99 | 折扣系数 |
| EPS_START | 1 | 见2.3节描述 |
| EPS_END | 0.02 | 见2.3节描述 |
| EPS_DECAY | 1e6 | 见2.3节描述 |
| EPS_RANDOM_COUNT | 5e4 | 见2.3节描述 |
| LR | 1e-4 | 优化器学习率 |
| INITIAL_MEMORY | 1e4 | Replay Buffer初始大小 |
| MEMORY_SIZE | 1e5 | Replay Buffer存储上限大小 |
| N_EPISODE | 1e5 | 训练幕数(一次生命为一幕) |
| TARGET_UPDATE | 1e3 | 目标网络更新频率 |
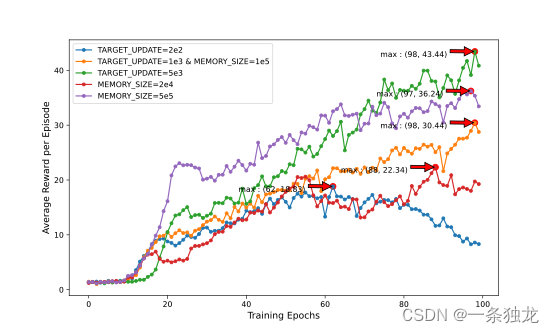
首先设置实验定量定性地探究Double DQN的Replay Buffer和fixed target对于模型性能的影响。因此利用单一变量原则,只设置MEMORY_SIZE,分别为2e4、1e5和5e5各进行一次训练;此外只设置TARGET_UPDATE,分别为2e2、1e5和5e3各进行一次训练。上述训练均以100幕(一次生命为一幕)为一个Epoch,得到如下表3-2的6组实验结果(TARGET_UPDATE=1e3的已经在MEMORY_SIZE=1e5实验训练过,因此两个实验的结果相同)。
| DQN模型超参数 | 100 Epochs | ||
|---|---|---|---|
| 训练耗时(分钟) | 最高Epoch平均幕回报 | 最高单幕回报与所在幕数 | |
| TARGET_UPDATE=2e2 | 1224 | 18.83 | 51 at 14495 ep |
| TARGET_UPDATE=1e3 | 1950 | 30.44 | 85 at 19715 ep |
| TARGET_UPDATE=5e3 | 1677 | 43.44 | 265 at 15186 ep |
| MEMORY_SIZE=2e4 | 1014 | 22.34 | 67 at 17609 ep |
| MEMORY_SIZE=1e5 | 1950 | 30.44 | 85 at 19715 ep |
将上述训练过程的每个Epoch的平均幕奖励绘制为折线图,如图3-1所示。结合图表,可见TARGET_UPDATE越大,模型表现越好,且收敛时间与之并非正相关。当TARGET_UPDATE为5e3时模型收敛最好,收敛速度适中。而MEMORY_SIZE参数同样也是越大模型效果越好,但是其训练耗时同样存在很大的增长,相差5倍的MEMORY_SIZE在收敛时间上相差近1000分钟。综合模型收敛效果和速度,在合适的MEMORY_SIZE下适当增加TARGET_UPDATE可以获得最优的收敛性能。
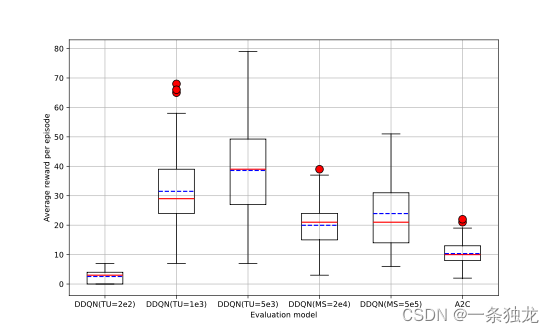
对Double DQN方法的不同超参数训练分支,均使用历史最优模型进行评估测试,即每个模型进行100幕游戏,并统计每个模型的最高、最低和平均单幕得分,同时绘制每幕得分的箱线图。
| 模型 | 平均奖励 | 最低幕奖励 | 最高幕奖励 |
|---|---|---|---|
| DDQN(TU=2e2) | 7.5 | 3.0 | 23.0 |
| DDQN(TU=1e3) | 31.5 | 7.0 | 68.0 |
| DDQN(TU=5e3) | 38.6 | 7.0 | 79.0 |
| DDQN(MS=2e4) | 20.0 | 3.0 | 39.0 |
| DDQN(MS=5e5) | 24.0 | 6.0 | 51.0 |
*DDQN指Double DQN; TU指TARGET_UPDATE; MS指MEMORY_SIZE;
图3-3描绘了Double DQN在不同超参数下训练的模型在100幕Breakout游戏上评估所得单幕回报的箱线图。从中可以发现Double DQN方法在目标网络更新频率为5e3时的评估效果总体最好,得分上限最高,但相对不稳定;而Double DQN在目标网络更新频率为2e2时的评估效果虽然稳定但总体最差。这一结论与根据图3-1得出的结论基本一致。
4.结论与展望
通过实验过程和结果的分析,我们可以得出以下结论:
Double DQN的超参数选择影响模型性能:在实验中,我们发现Double DQN方法在目标网络更新频率为5e3时表现最好,具有最高的平均幕回报。同时,实验结果还表明MEMORY_SIZE参数的增加可以提升模型性能,但同时也导致训练时间的显著增加。在选择超参数时,需要平衡模型性能和训练效率。
Double DQN在不同超参数下的评估结果有较大差异: 尽管在目标网络更新频率为5e3时Double DQN表现最好,但其评估结果相对不稳定,具有较大的方差。这提示我们在选择超参数时不仅要考虑性能指标的提升,还要关注模型的稳定性。
平衡探索与利用的重要性:在强化学习中,平衡探索和利用是一个重要的主题。在实验中,我们使用了epsilon-greedy策略在DQN中来平衡探索和利用。通过调整epsilon的衰减方式,我们可以在训练的不同阶段进行不同程度的探索和利用,从而提高模型的学习效率。
基于上述的结论和对本次整个实验过程的分析总结,在此对未来的工作和本文不足之处进行以下总结展望。
进一步优化超参数:未来的工作可以通过更系统地调整超参数,尤其是对于Double DQN方法中的其他超参数,来寻找更优的组合,以提高模型性能和训练效率。
尝试其他强化学习算法:除了DQN,还有许多其他强化学习算法可以尝试,例如PPO、DDPG等。对比不同算法在相同环境下的表现,有助于更全面地了解它们的优劣势。
探索更复杂的游戏环境:在本实验中,我们使用了Atari 2600版本的Breakout游戏作为测试环境。未来的工作可以尝试在更复杂的游戏环境中验证模型的性能,以更好地适应现实世界的复杂任务。
深入研究模型稳定性:对于Double DQN在不同超参数下评估结果不稳定的问题,未来的研究可以更深入地探讨如何提高模型的稳定性,以确保在不同训练阶段都能取得良好的性能。
5. 代码
import time
import random
import numpy as np
import ale_py
# import gymnasium as gym
import gym
import torch
import torch.nn as nn
from torch import optim
from torch.autograd import Variable
import torch.nn.functional as F
from collections import deque,namedtuple
from tqdm import tqdm
import matplotlib.pyplot as plt
import cv2
from itertools import count
import random, pickle, os.path, math, glob
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
Transition = namedtuple('Transion', ('state', 'action', 'next_state', 'reward'))
## 超参数
# epsilon = 0.9
BATCH_SIZE = 32
GAMMA = 0.99
EPS_START = 1
EPS_END = 0.02
EPS_DECAY = 1000000
EPS_RANDOM_COUNT = 50000 # 前50000步纯随机用于探索
TARGET_UPDATE = 1000 # steps
RENDER = False
lr = 1e-4
INITIAL_MEMORY = 10000
MEMORY_SIZE = 10 * INITIAL_MEMORY
n_episode = 100000#10000000
MODEL_STORE_PATH = './models'#+'DQN_pytorch_pong'
modelname = 'DQN_Breakout'
madel_path = MODEL_STORE_PATH + 'DQN_Breakout_episode60.pt'#+ '/' + 'model/'
## 超参数
# epsilon = 0.9
BATCH_SIZE = 32
GAMMA = 0.99
EPS_START = 1
EPS_END = 0.02
EPS_DECAY = 1000000
EPS_RANDOM_COUNT = 50000 # 前50000步纯随机用于探索
TARGET_UPDATE = 1000 # steps
RENDER = False
lr = 1e-4
INITIAL_MEMORY = 10000
MEMORY_SIZE = 10 * INITIAL_MEMORY
n_episode = 100000#10000000
MODEL_STORE_PATH = './models'#+'DQN_pytorch_pong'
class ReplayMemory(object):
def __init__(self, capacity):
self.capacity = capacity
self.memory = []
self.position = 0
def push(self, *args):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(*args)
self.position = (self.position + 1) % self.capacity #移动指针,经验池满了之后从最开始的位置开始将最近的经验存进经验池
def sample(self, batch_size):
return random.sample(self.memory, batch_size)# 从经验池中随机采样
def __len__(self):
return len(self.memory)
class DQN(nn.Module):
def __init__(self, in_channels=4, n_actions=14):
"""
Initialize Deep Q Network
Args:
in_channels (int): number of input channels
n_actions (int): number of outputs
"""
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 32, kernel_size=8, stride=4)
# self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2)
# self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
# self.bn3 = nn.BatchNorm2d(64)
self.fc4 = nn.Linear(7*7*64, 512)
self.head = nn.Linear(512, n_actions)
def forward(self, x):
# print(x)
# print(x.shape)
# cv2.imwrite("test_x.png",x.cpu().numpy()[0][0])
x = x.float() / 255
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(x.size(0), -1) # 将卷积层的输出展平
x = F.relu(self.fc4(x)) #.view(x.size(0), -1)
out = self.head(x)
# print(out)
return out
class DQN_agent():
def __init__(self,in_channels=4, action_space=[], learning_rate=1e-4, memory_size=10000, epsilon=1, trained_model_path=''):
self.in_channels = in_channels
self.action_space = action_space
self.action_dim = self.action_space.n
self.memory_buffer = ReplayMemory(memory_size)
self.stepdone = 0
self.DQN = DQN(self.in_channels, self.action_dim).to(device)
self.target_DQN = DQN(self.in_channels, self.action_dim).to(device)
# 加载之前训练好的模型,没有预训练好的模型时可以注释
if(trained_model_path != ''):
self.DQN.load_state_dict(torch.load(trained_model_path))
self.target_DQN.load_state_dict(self.DQN.state_dict())
self.optimizer = optim.RMSprop(self.DQN.parameters(),lr=learning_rate, eps=0.001, alpha=0.95)
def select_action(self, state):
self.stepdone += 1
state = state.to(device)
epsilon = EPS_END + (EPS_START - EPS_END)* \
math.exp(-1. * self.stepdone / EPS_DECAY) # 随机选择动作系数epsilon 衰减,也可以使用固定的epsilon
# epsilon-greedy策略选择动作
if self.stepdone<EPS_RANDOM_COUNT or random.random()<epsilon:
action = torch.tensor([[random.randrange(self.action_dim)]], device=device, dtype=torch.long)
else:
action = self.DQN(state).detach().max(1)[1].view(1,1) # 选择Q值最大的动作并view
return action
def learn(self):
# 经验池小于BATCH_SIZE则直接返回
if self.memory_buffer.__len__()<BATCH_SIZE:
return
# 从经验池中采样
transitions = self.memory_buffer.sample(BATCH_SIZE)
'''
batch.state - tuple of all the states (each state is a tensor) (BATCH_SIZE * channel * h * w)
batch.next_state - tuple of all the next states (each state is a tensor) (BATCH_SIZE * channel * h * w)
batch.reward - tuple of all the rewards (each reward is a float) (BATCH_SIZE * 1)
batch.action - tuple of all the actions (each action is an int) (BATCH_SIZE * 1)
'''
batch = Transition(*zip(*transitions))
actions = tuple((map(lambda a: torch.tensor([[a]], device=device), batch.action)))
rewards = tuple((map(lambda r: torch.tensor([r], device=device), batch.reward)))
# 判断是不是在最后一个状态,最后一个状态的next设置为None
non_final_mask = torch.tensor(
tuple(map(lambda s: s is not None, batch.next_state)),
device=device, dtype=torch.uint8).bool()
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None]).to(device)
state_batch = torch.cat(batch.state).to(device)
action_batch = torch.cat(actions)
reward_batch = torch.cat(rewards)
# 计算当前状态的Q值
state_action_values = self.DQN(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE, device=device)
next_state_values[non_final_mask] = self.target_DQN(non_final_next_states).max(1)[0].detach()
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
loss = F.smooth_l1_loss(state_action_values, expected_state_action_values.unsqueeze(1))
self.optimizer.zero_grad()
loss.backward()
for param in self.DQN.parameters():
param.grad.data.clamp_(-1, 1)
self.optimizer.step()
class Trainer():
def __init__(self, env, agent, n_episode):
self.env = env
self.n_episode = n_episode
self.agent = agent
# self.losslist = []
self.rewardlist = []
self.avg_rewardlist = []
# 获取当前状态,将env返回的状态通过transpose调换轴后作为状态
def get_state(self,obs):
# print(obs.shape)
state = np.array(obs)
# state = state.transpose((1, 2, 0)) #将2轴放在0轴之前
state = torch.from_numpy(state)
return state.unsqueeze(0) # 转化为四维的数据结构
# 训练智能体
def train(self):
for episode in range(self.n_episode):
obs = self.env.reset()
# print('============obs = self.env.reset()============')
# state = self.img_process(obs)
state = np.stack((obs[0], obs[1], obs[2], obs[3]))
# print(state.shape)
state = self.get_state(state)
# print(state.shape)
episode_reward = 0.0
# print('episode:',episode)
for t in count():
# print(state.shape)
action = self.agent.select_action(state)
if RENDER:
self.env.render()
obs,reward,done,_,_ = self.env.step(action)
episode_reward += reward
if not done:
# next_state = self.get_state(obs)
# next_state = self.img_process(obs)
next_state = np.stack((obs[0], obs[1], obs[2], obs[3]))
next_state = self.get_state(next_state)
else:
next_state = None
# print(next_state.shape)
reward = torch.tensor([reward], device=device)
# 将四元组存到memory中
'''
state: batch_size channel h w size: batch_size * 4
action: size: batch_size * 1
next_state: batch_size channel h w size: batch_size * 4
reward: size: batch_size * 1
'''
self.agent.memory_buffer.push(state, action.to('cpu'), next_state, reward.to('cpu')) # 里面的数据都是Tensor
# print('========memory_buffer.push=========')
# print(state.shape)
# print(action.shape)
# print(next_state.shape)
# print(reward)
# cv2.imwrite("test_1.png",state[0].numpy()[0])
# cv2.imwrite("test_2.png",state[0].numpy()[1])
# cv2.imwrite("test_3.png",state[0].numpy()[2])
# cv2.imwrite("test_4.png",state[0].numpy()[3])
# time.sleep(0.1)
state = next_state
# 经验池满了之后开始学习
if self.agent.stepdone > INITIAL_MEMORY:
self.agent.learn()
if self.agent.stepdone % TARGET_UPDATE == 0:
print('======== target DQN updated =========')
self.agent.target_DQN.load_state_dict(self.agent.DQN.state_dict())
if done:
break
agent_epsilon = EPS_END + (EPS_START - EPS_END)* math.exp(-1. * self.agent.stepdone / EPS_DECAY)
print('Total steps: {} \t Episode/steps: {}/{} \t Total reward: {} \t Avg reward: {} \t epsilon: {}'.format(
self.agent.stepdone, episode, t, episode_reward, episode_reward/t, agent_epsilon))
if episode % 20 == 0:
torch.save(self.agent.DQN.state_dict(), MODEL_STORE_PATH + '/' + "{}_episode{}.pt".format(modelname, episode))
# print('Total steps: {} \t Episode: {}/{} \t Total reward: {}'.format(self.agent.stepdone, episode, t, episode_reward))
self.rewardlist.append(episode_reward)
self.avg_rewardlist.append(episode_reward/t)
self.env.close()
return
#绘制单幕总奖励曲线
def plot_total_reward(self):
plt.plot(self.rewardlist)
plt.xlabel("Training epochs")
plt.ylabel("Total reward per episode")
plt.title('Total reward curve of DQN on Skiing')
plt.savefig('DQN_train_total_reward.png')
plt.show()
#绘制单幕平均奖励曲线
def plot_avg_reward(self):
plt.plot(self.avg_rewardlist)
plt.xlabel("Training epochs")
plt.ylabel("Average reward per episode")
plt.title('Average reward curve of DQN on Skiing')
plt.savefig('DQN_train_avg_reward.png')
plt.show()
# reward clip
class ClipRewardEnv(gym.RewardWrapper):
def __init__(self, env):
gym.RewardWrapper.__init__(self, env)
def reward(self, reward):
"""Bin reward to {+1, 0, -1} by its sign."""
return np.sign(reward)
# image frame process
class WarpFrame(gym.ObservationWrapper):
def __init__(self, env, width=84, height=84, grayscale=True):
"""Warp frames to 84x84 as done in the Nature paper and later work."""
gym.ObservationWrapper.__init__(self, env)
self.width = width
self.height = height
self.grayscale = grayscale
if self.grayscale:
self.observation_space = gym.spaces.Box(low=0, high=255,
shape=(self.height, self.width, 1), dtype=np.uint8)
else:
self.observation_space = gym.spaces.Box(low=0, high=255,
shape=(self.height, self.width, 3), dtype=np.uint8)
def observation(self, frame):
if self.grayscale:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
frame = cv2.resize(frame, (self.width, self.height), interpolation=cv2.INTER_AREA)
if self.grayscale:
frame = np.expand_dims(frame, -1)
return frame
class ScaledFloatFrame(gym.ObservationWrapper):
def __init__(self, env):
gym.ObservationWrapper.__init__(self, env)
self.observation_space = gym.spaces.Box(low=0, high=1, shape=env.observation_space.shape, dtype=np.float32)
def observation(self, observation):
# careful! This undoes the memory optimization, use
# with smaller replay buffers only.
return np.array(observation).astype(np.float32) / 255.0
# Frame Stacking
class FrameStack(gym.Wrapper):
def __init__(self, env, k):
"""
Stack k last frames.
Returns lazy array, which is much more memory efficient.
See Also
--------
baselines.common.atari_wrappers.LazyFrames
"""
gym.Wrapper.__init__(self, env)
self.k = k
self.frames = deque([], maxlen=k)
shp = env.observation_space.shape
self.observation_space = gym.spaces.Box(low=0, high=255, shape=(shp[:-1] + (shp[-1] * k,)), dtype=env.observation_space.dtype)
def reset(self):
ob = self.env.reset()
if isinstance(ob, tuple): # obs is tuple in newer version of gym
ob = ob[0]
for _ in range(self.k):
self.frames.append(ob)
return self._get_ob()
def step(self, action):
ob, reward, done, truncated, info = self.env.step(action)
if isinstance(ob, tuple):
ob = ob[0]
self.frames.append(ob)
return self._get_ob(), reward, done, truncated, info
def _get_ob(self):
assert len(self.frames) == self.k
return LazyFrames(list(self.frames))
class EpisodicLifeEnv(gym.Wrapper):
def __init__(self, env):
"""Make end-of-life == end-of-episode, but only reset on true game over.
Done by DeepMind for the DQN and co. since it helps value estimation.
"""
gym.Wrapper.__init__(self, env)
self.lives = 0
self.was_real_done = True
def step(self, action):
obs, reward, done, truncated, info = self.env.step(action)
self.was_real_done = done
# check current lives, make loss of life terminal,
# then update lives to handle bonus lives
lives = self.env.unwrapped.ale.lives()
if lives < self.lives and lives > 0:
# for Qbert sometimes we stay in lives == 0 condition for a few frames
# so it's important to keep lives > 0, so that we only reset once
# the environment advertises done.
done = True
self.lives = lives
return obs, reward, done, truncated, info
def reset(self, **kwargs):
"""Reset only when lives are exhausted.
This way all states are still reachable even though lives are episodic,
and the learner need not know about any of this behind-the-scenes.
"""
if self.was_real_done:
obs, info = self.env.reset(**kwargs)
else:
# no-op step to advance from terminal/lost life state
obs, _, _, _, info = self.env.step(0)
self.lives = self.env.unwrapped.ale.lives()
return obs, info
class LazyFrames(object):
def __init__(self, frames):
"""
This object ensures that common frames between the observations are only stored once.
It exists purely to optimize memory usage which can be huge for DQN's 1M frames replay
buffers.
This object should only be converted to numpy array before being passed to the model.
You'd not believe how complex the previous solution was.
"""
self._frames = frames
self._out = None
def _force(self):
if self._out is None:
self._out = np.concatenate(self._frames, axis=-1)
self._frames = None
return self._out
def __array__(self, dtype=None):
out = self._force()
if dtype is not None:
out = out.astype(dtype)
return out
def __len__(self):
return len(self._force())
def __getitem__(self, i):
return self._force()[..., i]
def env_wrap_deepmind(env, episode_life=True, clip_rewards=True, frame_stack=True, scale=True):
"""
Configure environment for DeepMind-style Atari.
"""
if episode_life:
env = EpisodicLifeEnv(env)
env = WarpFrame(env)
if scale:
env = ScaledFloatFrame(env) # scale the frame image
if clip_rewards:
env = ClipRewardEnv(env) # clip the reward into [-1,1]
if frame_stack:
env = FrameStack(env, 4) # stack 4 frame to replace the RGB 3 chanels image
return env
# create environment and warp it into DeepMind style
env = env_wrap_deepmind(gym.make("ALE/Breakout-v5"), episode_life=True, clip_rewards=False, frame_stack=True, scale=False)
action_space = env.action_space
# use 4 stacked chanel
agent = DQN_agent(in_channels = 4, action_space = action_space, learning_rate = lr, memory_size=MEMORY_SIZE)
trainer = Trainer(env, agent, n_episode) # 这里应该用超参数里的n_episode
trainer.train()
trainer.plot_total_reward()
# trainer.plot_avg_reward()
# save total reward list
np.save('total_reward_list_breakout_1e5.npy',np.array(trainer.rewardlist))
np.save('avg_reward_list_breakout_1e5.npy',np.array(trainer.avg_rewardlist))
print('The training costs {} episodes'.format(len(trainer.rewardlist)))
print('The max episode reward is {}, at episode {}'.format(
max(trainer.rewardlist),
trainer.rewardlist.index(max(trainer.rewardlist))
))
# 合并5 episodes为1episode
assert(len(trainer.rewardlist)%5==0)
reshaped_reward_array = np.array(trainer.rewardlist).reshape((int(len(trainer.rewardlist)/5), 5))
# 沿着第二个维度求和
summed_rewawrd_array = reshaped_reward_array.sum(axis=1)
print('Now takes 5 episodes as 1, the training cost {} complete episodes'.format(len(summed_rewawrd_array)))
print('The max episode return is {}, at episode {}'.format(
max(summed_rewawrd_array),
np.where(summed_rewawrd_array == max(summed_rewawrd_array))
))
# 合并200 episodes为1episode
assert(len(summed_rewawrd_array)%200==0)
reshaped_reward_array_200 = summed_rewawrd_array.reshape((int(len(summed_rewawrd_array)/200), 200))
# 沿着第二个维度求和
summed_rewawrd_array_200 = reshaped_reward_array_200.sum(axis=1)
avg_rewawrd_array_200 = summed_rewawrd_array_200/200.0
np.save('avg_rewawrd_array_200_breakout_1e5.npy',avg_rewawrd_array_200)
print('The following graph takes 1000 games as 1 epoch where 5 games equals to 1 episode as stated before')
max_idx = np.argmax(avg_rewawrd_array_200)
max_y = max(avg_rewawrd_array_200)
print('The best average return per epoch is {}, at epoch {}'.format(max_idx,max_y))
plt.figure(figsize=(10,6))
plt.plot(avg_rewawrd_array_200,marker='o',markersize=4)
plt.xlabel("Training Epochs",fontsize=12)
plt.ylabel("Average Reward per Episode",fontsize=12)
plt.scatter(max_idx, max_y, color='red', s=60)
plt.annotate(f'max avg return: ({max_idx}, {max_y:.2f})', xy=(max_idx, max_y), xytext=(max_idx-40, max_y-1),
arrowprops=dict(facecolor='red', shrink=0.05))
# plt.title('Average Reward of DQN on Breakout')
plt.savefig('DQN_train_total_reward_Breakout.svg')
plt.show()
Reference:
https://blog.csdn.net/libenfan/article/details/117395547
https://zhuanlan.zhihu.com/p/80185628
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux内存管理:(八)页面迁移
- 笙默考试管理系统-MyExamTest----codemirror(64)
- 网络安全35个框架合集
- layui文本编译器支持多图上传,图片上传排序,删除图片功能
- Design Pattern——Heuristic Benchmark
- 【江科大】STM32:(超级详细)定时器输出比较
- 读书笔记-《数据结构与算法》-摘要5[归并排序]
- 学习python第八天
- 游戏素材永不缺,免费在线AI工具Scenario功能齐全,简单易用
- 文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《基于混合博弈的配电网与多综合能源微网优化运行》