kylin3集群问题和思考(单机转集群)
发布时间:2024年01月12日
????????
? ? ?
目录
单机改集群注意事项
????????之前是使用的单机版,但后面查询压力过大,一个方案是改成集群。
????????由于是同一个集群的,元数据没有变化,所以,直接将原本的kylin使用scp的方式发送到其他节点即可。hive客户端也是,也要保证有hbase、zookeeper等。
? ? ? ? 需要修改的配置如下(截图官网):
????????
? ? ? ? 下面说一下需要注意的地方。
- ????????-name '*jackson*',需要加在find-hive-dependency.sh和find-spark-dependency.sh里面,不然就会导致kylin启动出问题。
- ????????还有一点,我看了很多其他博客,都没写一点,每台的kylin.env.zookeeper-base-path=这个配置必须修改为不同的路径。不然会出现读取加锁错误。(这里有些不同,我测了几个版本。部分需要改路径,部分不用改。如果出现报错再改吧)
我在第一台设置的kylin.server.mode=job,第二台配置的kylin.server.mode=all,第三台配置了第二台配置的kylin.server.mode=query
所以我在第一台查询就出现了:
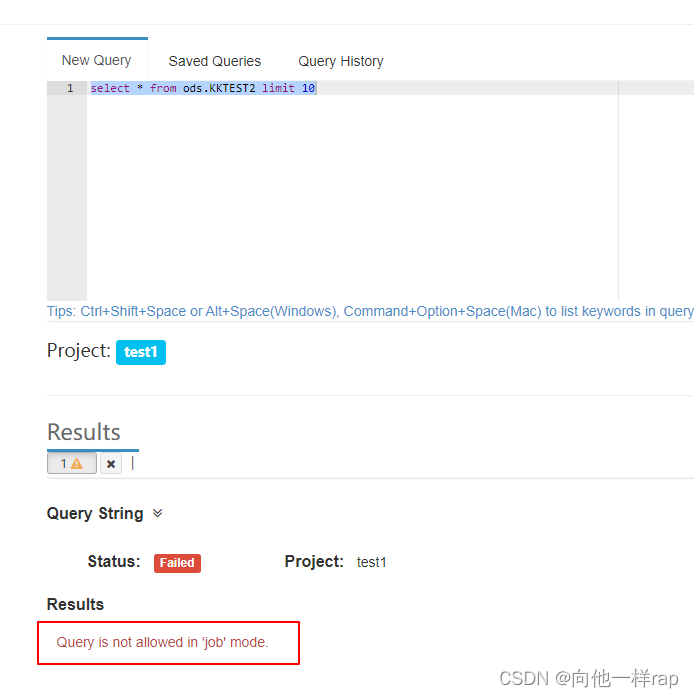
而构建cube在每一台都可以。
问题
? ? ? ? 由于第三台设置的query,所以构建cube时,不会出现Built By XXX@第三台ip。只可能在第一、第二台进行built。
? ? ? ? 我试过很多次,构建分别在第一台第二台都测试过,我发现如下
- 设置kylin.server.mode=job 在上面进行built的几率比kylin.server.mode=all大。
思考
- 这是配置原因吗?让job>all
- 不是配置原因,是根据负载均衡原因,但我没配置这些啊,而且两台资源相当。
- kylin有个自己的选择算法,选择合适的机器上面进行cube构建。
建议
????????不要设置job,只设置query,all。多数query,少数all。毕竟使用kylin,更多是用的查询,构建放少数机器上即可。而且yarn也不可能给你分配很多队列,让你一个节点构建cube进入一个队列。
请看下篇,kylin集群使用nginx代理:
后面将持续更新和修改kylin集群部分,遇到问题欢迎留言,谢谢。
? ? ? ?
文章来源:https://blog.csdn.net/qq_40209679/article/details/135510961
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【STM32】STM32学习笔记-LED闪烁 LED流水灯 蜂鸣器(06-2)
- IOS-高德地图隐私合规示例-Swift
- 深入浅出:Go 语言中值传递与引用传递的原理解析
- 基于ssm+vue的宠物医院系统(前后端分离)
- 面试题:如何停止一个正在运行的线程?
- redis介绍与数据类型(一)
- (酒驾检测、人脸检测、疲劳检测、模拟口罩数据集制作、防酒驾)-常用的论文所用的python代码总结
- 美格智能LXC容器化解决方案,轻松玩转多系统虚拟化
- 函数式编程-Consumer
- 勒索病毒最新变种.[steloj@mailfence.com].steloj勒索病毒来袭,如何恢复受感染的数据?