NodeJs导出xlsx,行列合并,内容居中,字体颜色,字体加粗,字体大小,批量任务
发布时间:2023年12月24日
(要学会游泳,就必须下水。——列宁)

Nodejs Xlsx
这次我们将演示如何使用NodeJs将一组数据使用以下样式导出
- 行列合并
- 内容居中
- 字体颜色
- 字体加粗
- 字体大小
导出结果
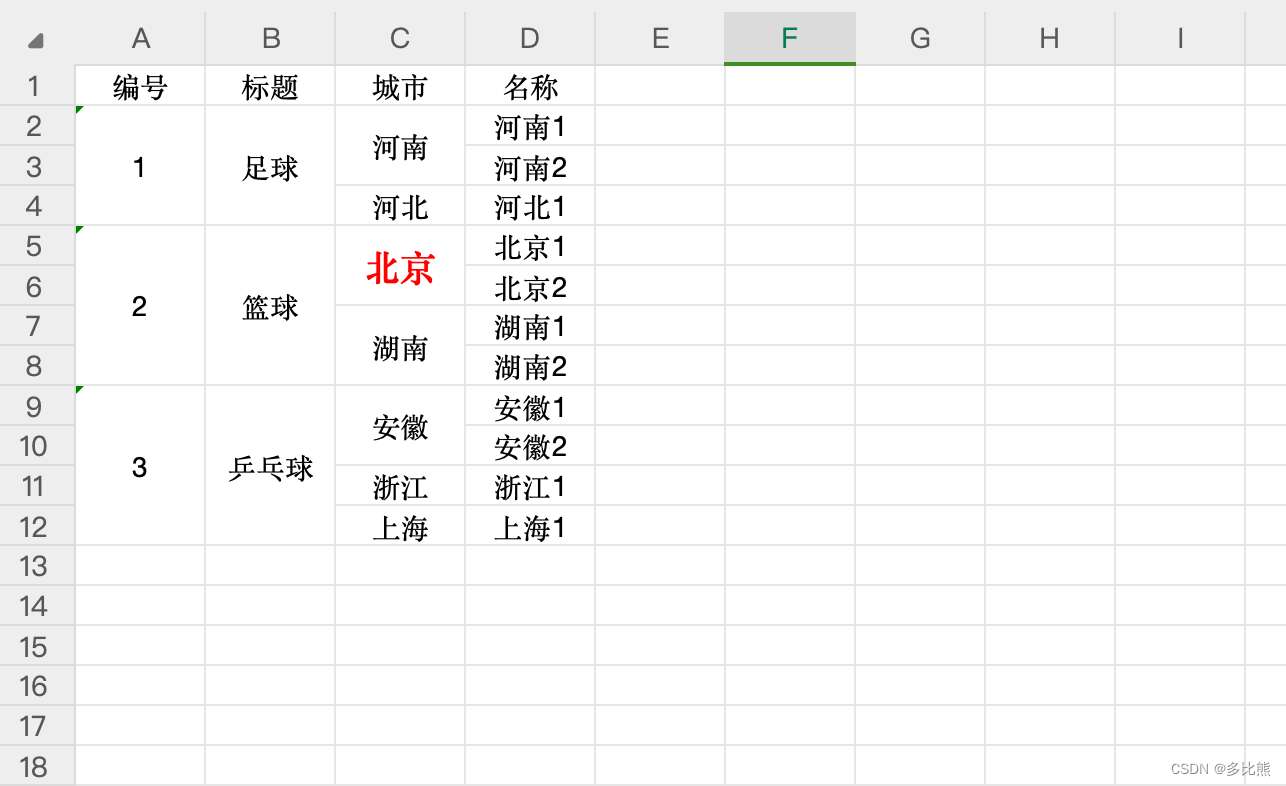
示例代码
const _ = require('lodash');
const bluebird = require('bluebird');
const xlsx_style = require('xlsx-style');
const fs = require('fs');
// 目标:对相同活动编号的行进行合并
// 如果活动编号相同,则合并行,包括活动名称。并且其子集数据中的城市和名称也要进行合并
// 并对北京地区进行标红
// 模拟数据库已存储的数据
const list = [
{
campaignNumber: '1',
campaignTitle: '足球',
child: [
{
city: '河南',
name: '河南1'
},
{
city: '河南',
name: '河南2'
},
{
city: '河北',
name: '河北1'
}
]
},
{
campaignNumber: '2',
campaignTitle: '篮球',
child: [
{
city: '北京',
name: '北京1'
},
{
city: '北京',
name: '北京2'
},
{
city: '湖南',
name: '湖南1'
},
{
city: '湖南',
name: '湖南2'
}
]
},
{
campaignNumber: '3',
campaignTitle: '乒乓球',
child: [
{
city: '安徽',
name: '安徽1'
},
{
city: '安徽',
name: '安徽2'
},
{
city: '浙江',
name: '浙江1'
},
{
city: '上海',
name: '上海1'
}
]
}
];
// 定义分组数组
const groupList = [];
// 将活动编号相同的行进行分开存储
for (const item of list) {
for (const childItem of item.child) {
const data = {
campaignNumber: item.campaignNumber,
campaignTitle: item.campaignTitle,
city: childItem.city,
name: childItem.name
};
groupList.push(data);
}
}
// 模拟从数据库查询列表
const getDataList = async (skip, limit) => {
return new Promise((resolve) => {
// eslint-disable-next-line no-promise-executor-return
return resolve(groupList.slice(skip, limit))
})
};
// 模拟从数据库获取总数
const getDataListCount = async () => {
return groupList.length;
}
const generateXlsx = async (
) => {
// 控制批次,这里演示就每次一个,实际还需要根据业务情况考量
const batchSize = 1;
// 表格合并开始下标
let startIndex = 0;
// 表格合并结束下标
let endIndex = 0;
// 记录xlsx属性位置
let xlsxI = 0;
let dataExport = {};
let dataGroup = [];
const totalCount = await getDataListCount();
const chunk = _.chunk(_.times(totalCount), batchSize);
// eslint-disable-next-line complexity
const getMerges = (list) => {
const merges = [];
// 如果表格只有一行表头,则直接返回
if (list.length === 1) {
return merges;
}
for (let i = 0; i < list.length; i++) {
// 获取当前行的活动编号
const currentCampaignNumber = list[i].campaignNumber;
// 获取下一行的活动编号
const nextCampaignNumber = list[i + 1]?.campaignNumber;
// 对比当前行和下一行的活动编号是否相同,+1是因为实际从xlsx第二行开始计算的
if (currentCampaignNumber === nextCampaignNumber) {
endIndex = i + 1;
}
// 如果当前行和下一行的活动编号相同但不是最后一个,则跳出继续循环
if (currentCampaignNumber === nextCampaignNumber && i !== list.length - 1) {
continue;
}
// 开始计算活动编号的合并数据
// 如果不同,则进行合并结算
// 如果开始下标大于结束下标,则证明是孤立值,不需要处理
// 这里需要额外+1,因为合并是从第二行开始的,第一行是表头
if (startIndex < endIndex) {
// s指的是开始合并的位置
// e指的是结束合并的位置
_.times(2, (i) => {
merges.push({
s: {
r: startIndex + 1,
c: i,
},
e: {
r: endIndex + 1,
c: i,
},
});
});
}
// 开始计算一组活动编号数据内城市相同的合并数据
let startFormatIndex = 0;
let endFormatIndex = 0;
const cloneList = _.cloneDeep(list).slice(
startIndex,
endIndex + 1,
);
for (let j = 0; j < cloneList.length; j++) {
const currentCity = cloneList[j].city;
const nextCity = cloneList[j + 1]?.city;
if (currentCity === nextCity) {
endFormatIndex = j + 1;
}
if (currentCity === nextCity && j !== cloneList.length - 1) {
continue;
}
if (startFormatIndex < endFormatIndex) {
// r的累加是为了分批执行
_.times(1, (i) => {
merges.push({
s: {
r: startFormatIndex + 1 + startIndex,
c: i + 2,
},
e: {
r: endFormatIndex + 1 + startIndex,
c: i + 2,
},
});
});
}
// 然后再从下一行开始
startFormatIndex = j + 1;
}
// 然后再从下一行开始
startIndex = i + 1;
}
return merges;
};
// 源数据需要获取的字段
const _headersMapping = [
'campaignNumber',
'campaignTitle',
'city',
'name',
];
// 字段中文映射
const _header = ['编号', '标题', '城市', '名称'];
const header = _header.
map((v, i) =>
_.assign({}, { v: v, position: String.fromCharCode(65 + i) + 1 }),
).
reduce(
(prev, next) => _.assign({}, prev, { [next.position]: { v: next.v } }),
{},
);
let page = 1;
let limit = batchSize;
await bluebird.Promise.map(chunk, async () => {
// 模拟从数据库分页获取
const list = await getDataList((page - 1) * limit, page * limit);
const tempDataGroupResult = list.
map((v, i) => {
return _headersMapping.map((k, j) => {
return _.assign(
{},
{
v: v[k],
position: String.fromCharCode(65 + j) + (xlsxI + i + 2),
},
);
});
}).
reduce((prev, next) => prev.concat(next)).
reduce(
(prev, next) => {
let s = {};
if (next.v === '北京') {
s = {
font: {
sz: 15,
bold: true,
color: {
rgb: 'FF0000',
},
},
};
}
const data = _.assign({}, prev, {
[next.position]: {
v: next.v,
s
},
});
return data;
},
{},
);
dataExport = {
...dataExport,
...tempDataGroupResult,
};
dataGroup = [...dataGroup, ...list];
page += 1;
xlsxI += list.length;
}, { concurrency: 1 });
// 合并 headersExport 和 dataExport
const output = _.assign({}, header, _.cloneDeep(dataExport));
// 所有单元格内容都是垂直水平居中
// 和样式进行合并
// eslint-disable-next-line guard-for-in
for (const key in output) {
output[key].s = {
...output[key].s,
...{
alignment: {
vertical: 'center',
horizontal: 'center',
},
}
};
}
// 获取所有单元格的位置
const outputPos = _.keys(output);
// 计算出范围
const ref = outputPos[0] + ':' + outputPos[outputPos.length - 1];
if (!output['!merges']) {
output['!merges'] = [];
}
output['!merges'] = [
...output['!merges'],
...getMerges(_.cloneDeep(dataGroup)),
];
// 构建 workbook 对象
const workbook = {
SheetNames: ['Sheet'],
Sheets: {
Sheet: _.assign({}, output, { '!ref': ref }),
},
};
// 获取文件流
// 可以写成文件,也可以作为文件流上传至云端
const buffer = xlsx_style.write(workbook, { bookType: 'xlsx', type: 'buffer' });
fs.writeFileSync(`${__dirname}/export.xlsx`, buffer);
}
generateXlsx();
文章来源:https://blog.csdn.net/qq_42427109/article/details/135183084
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!