神经网络激活函数--Sigmoid、Tanh、Relu、Softmax
本文主要总结了Sigmoid、Tanh、Relu、Softmax 四种函数;给出了函数的形式,优缺点和图像。
sigmoid和Tanh函数的导数简单,但是可能出现梯度弥散。
ReLU函数仅保留正元素,有良好的特性。
Softmax一般是用于分类最后一层的归一化。
目录
1.Sigmoid 函数
形式:
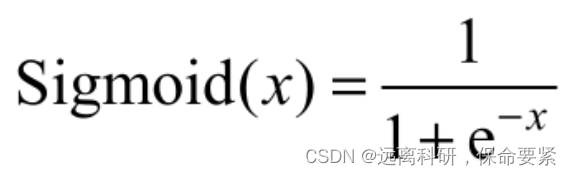
特点:
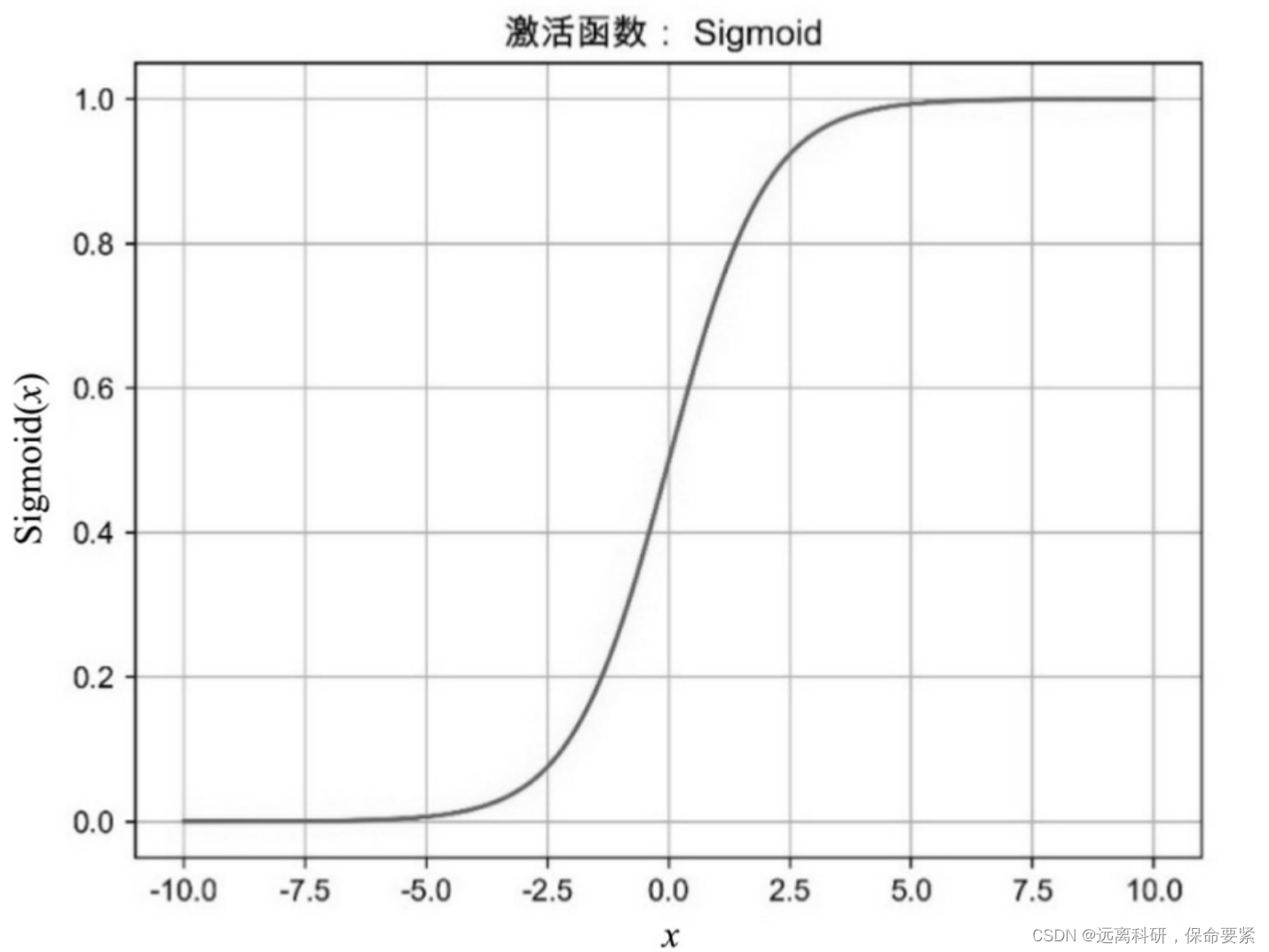
Sigmoid函数通常称为挤压函数(Squashing Function),它可以将(-inf,inf)范围中的任意实数映射到(0,1)范围内,输入值越大,压缩后越趋近于1,输入值越小,压缩后越趋近0,这两种情况在物理意义上最接近生物神经元的休眠和激活状态
适用于:
Sigmoid函数可以用在深度学习模型长短期记忆(Long Short-Term Memory,LSTM)中的各种门(Gate)上,模拟门的关闭和开启状态。此外,Sigmoid函数还可以用于表示概率,并且可以用于输入的归一化处理。
优缺点:
导数简单:
![]()
缺点:
1. 存在饱和性,即当输入数据x很大或很小时,Sigmoid函数的导数迅速趋近于0。这种情况就意味着,它很容易产生所谓的梯度弥散现象。
2. 不是以0为中心的。
2.Tanh函数?
形式:
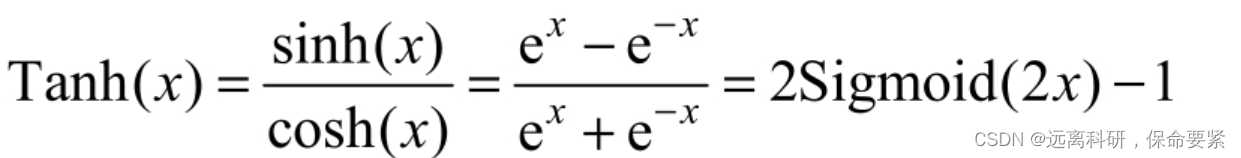
特点:
它将一个实数输入映射到(-1,1)范围内。当输入为0时,Tanh函数输出为0,这符合我们对激活函数的要求。
适用于:
Tanh函数也可以作为“开关”调节输入信息,在LSTM网络中也有广泛应用
优缺点:
导数:

缺点:
Tanh函数和Sigmoid函数之间存在一定的线性关系,因此两者的形状是类似的,只是尺度和范围不同。Tanh函数存在与Sigmoid函数类似的缺点——梯度弥散,导致训练效率不高
3.Relu函数
形式:
标准的ReLU函数非常简单,即f(x)=max(x,0)。简单来说,当x>0时,输出为x;当x≤0时,输出为0。通俗地说,ReLU函数可以通过将相应的激活值设为0从而仅保留正元素,并“毫不留情”地抛弃所有负元素。
导数:
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。值得注意的是,当输入值恰好等于0时,ReLU函数不可导。
优点:
(1)单侧抑制。当输入小于0时,神经元处于抑制状态;反之,当输入大于0时,神经元处于激活状态。ReLU函数相对简单,求导计算方便。这导致ReLU函数的随机梯度下降(Stochastic Gradient Descent,SGD)的收敛速度比Sigmoid函数或Tanh函数快得多。而且ReLU函数减轻了以往困扰神经网络的梯度弥散问题。
(2)相对宽阔的兴奋边界。观察Sigmoid函数的激活状态(Sigmoid函数的取值范围)集中在中间的狭小空间(0,1)内,Tanh函数有所改善,但也局限于(-1,1)内,而ReLU函数则不同,只要输入大于0,神经元就一直处于激活状态。
(3)稀疏激活。相比Sigmoid之类的激活函数,稀疏性是ReLU函数的优势所在。Sigmoid函数将处于抑制状态的神经元设置为一个非常小的值,但即使这个值再小,后续的计算也少不了它们的参与,这样的操作计算负担很大。但ReLU函数直接将处于抑制状态的神经元“简单粗暴”地设置为0,这样一来,这些神经元不再参与后续的计算,从而使网络保持稀疏性。
4.Softmax函数
形式:

适用于:
对于多分类(设为k分类数)任务,神经网络的最后一个全连接线性层通常会给出k个输出值,通常也称为logits[插图],这个logits值有大有小,有正有负。人们对这个值的大小正负并不那么在乎,更在乎的是分类概率的大小,然后择其大者作为分类判定的依据。
对于一个长度为k的logits向量[z1,z2,…,zk],利用Softmax函数可以输出一个长度为k的向量[q1,q2,…,qk]。如果一个向量想成为一种概率描述,那么它的输出至少要满足两个条件:一是每个输出值qi(概率)都在[0,1]之间;二是这些输出值之和∑iqi=1。
四种函数的图像:



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 本地如何使用PHP搭建简单Imagewheel云图床,结合内网穿透实现在外远程访问?
- 代码随想录算法训练营第11天 | 20.有效的括号 , 1047. 删除字符串中的所有相邻重复项 ,150. 逆波兰表达式求值
- 小程序如何设置客服
- Web实战丨基于django+html+css的在线购物商城
- echarts -- 柱状图之柱状条如何显示白色侧阴影且鼠标移入时高亮
- 【华为OD机试真题2023C&D卷 JAVA&JS】虚拟游戏理财
- React实现拖拽效果
- 骨传导耳机排行榜,高性价比骨传导耳机排行榜品牌推荐
- 毕业设计论文|基于SSM的网络教学系统设计与实现
- 李宏毅LLM——机器学习基础知识