07、Kafka ------ 消息生产者(演示 发送消息) 和 消息消费者(演示 监听消息)
目录
Kafka — 消息生产者
★ 消息
简单来说,就是一个数据项。
▲ 消息就是 Kafka 所记录的数据节点,消息在 Kafka 中又被称为记录(record)或事件(event)。
从存储上来看,消息就是存储在分区文件(有点类似于List)中的一个数据项,消息具有 key、value、时间戳 和 可选的元数据头。
▲ 下面是一个示例事件:
key: “fkjava”
value: “publish a new Book”
timestamp: “Feb. 15, 2021 at 2:06 p.m.”
★ 消息的分发机制
【注意:】当程序向主题发送消息时,该消息会被立即分给该主题下某一个领导者分区。
▲ 消息生产者向消息主题发送消息,这些消息将会立即分发给该主题下某一个分区(此处说的都是领导者分区)来保存
▲ 主题下的每条消息只会保存在一个领导者分区中,而不会在多个领导者分区中保存多份。
消息实际上是存在分区中的,往主题发送消息只是一种逻辑说法。
当生产者发送一条消息到一个主题的时候,实际上这个消息马上就会被直接分发到对应的某一个领导者分区当中。
非领导者分区只是领导者分区的后备,也就是备份而已,当领导者分区挂掉的时候,非领导者分区就有可能成为领导者分区。
但是真正能够直接与客户进行交互的,就是直接接收用户的数据,或者让用户来消费数据的只能是领导者分区。
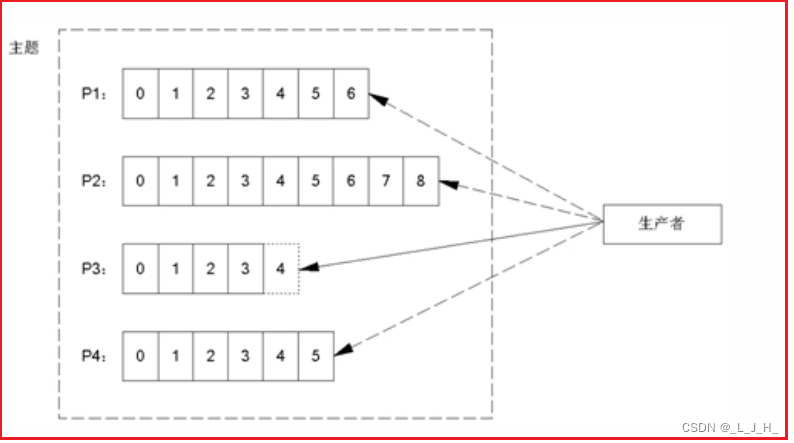
★ 分发到哪个分区
当生产者发送一条消息时,它会按如下规则来决定该消息被分发到哪个分区:
优先级:
最优先:(1)如果在发送消息时指定了分区,则消息分发到指定的分区。
(2)如果发送消息时没有指定分区,但消息的key不为空,则基于key的hashCode来选择一个分区。
此处暗示了:在一段时间内:同一个key的多条消息,通常会被分发到同一个分区
最次:(3)如果既没有指定分区,且消息的key也是空,则用轮询策略(round-robin)来选择一个分区。
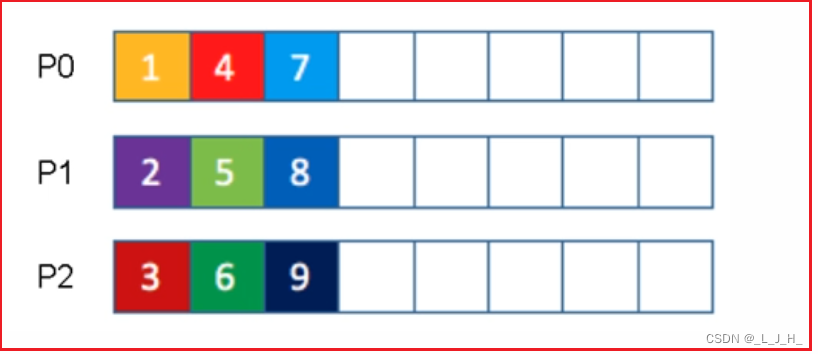
★ 轮询策略(round-robin)
轮询策略(round-robin)就是按顺序来分发消息,
比如下面一个主题有P0、P1、P2三个分区,
那么第一条消息被分发到P0分区,
第二条消息被分发到P1分区,
第三条消息被分发到P2分区,
以此类推,第四条消息又被分发到P0分区。
★ 使用命令行工具发送消息
Kafka提供了kafka-console-producer.bat(.sh)工具来发送消息,例如执行如下命令:
下面命令发送带key的消息:
kafka-console-producer.bat ^
--bootstrap-server localhost:9092 ^
--topic test2 ^
--property parse.key=true
上面命令指定向test2这个主题发送消息,并通过“parse.key=true”指定发送消息时会解析消息的key,
默认解析规则为:制表符(Tab键)之前的是key,制表符(Tab键)之后的是value。
如果不指定“parse.key=true”属性,则默认不解析消息的key,也就是发送不带key的消息。
下面命令发送不带key的消息:
kafka-console-producer.bat ^
--bootstrap-server localhost:9092 ^
--topic test2
演示添加消息
因为演示过程中,我弄的3个节点老是只有一个能存活,所以把 kafka和zookeeper的存储数据的文件夹都删除了,重新启动,就好了。方便演示。
删除Kaka和zookeeper的存储数据的文件夹,重新启动
现在3个节点就能正常存活了。
接下来继续演示:
添加 不带key 和带key的消息,演示生产者发送消息:
解释:
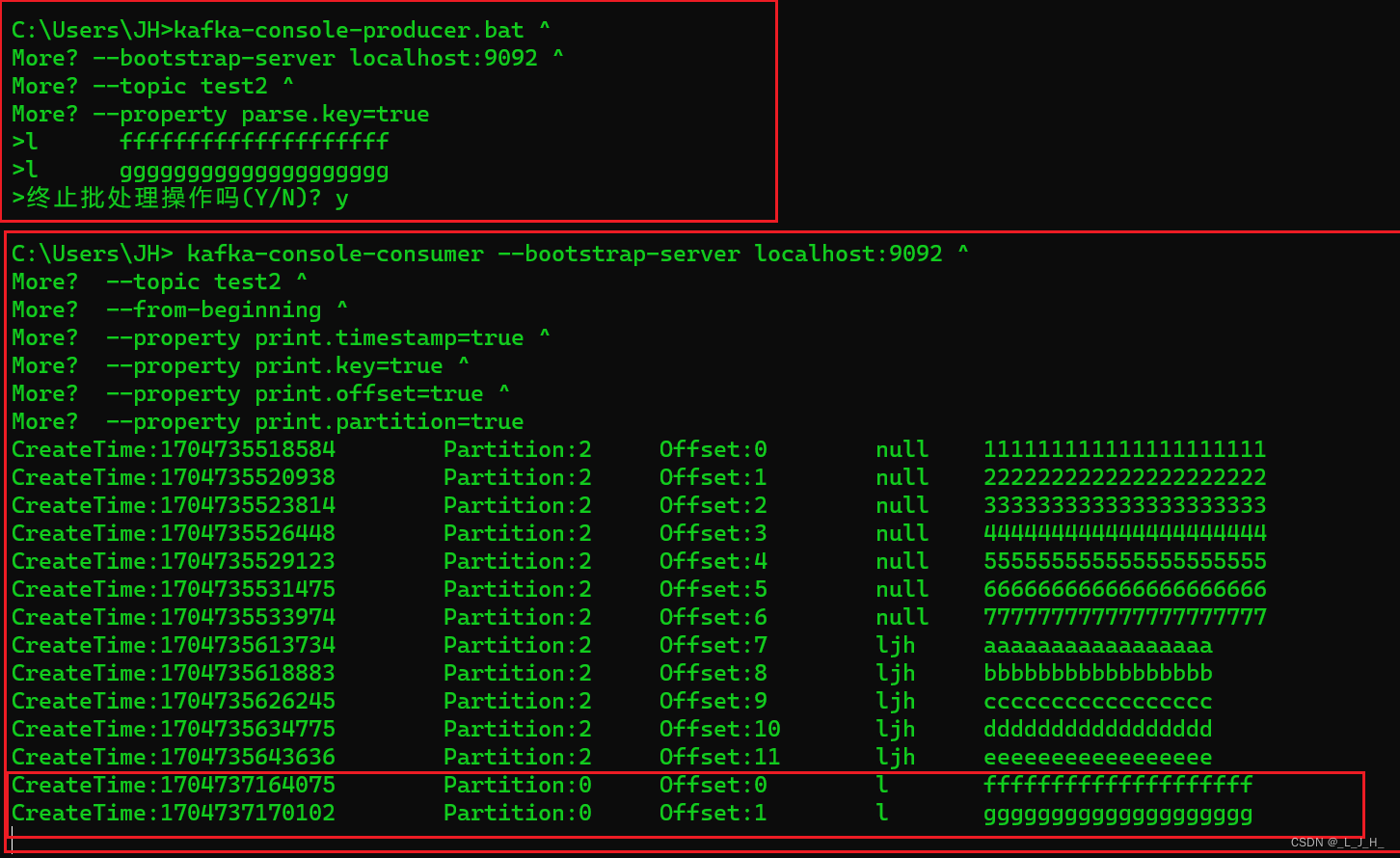
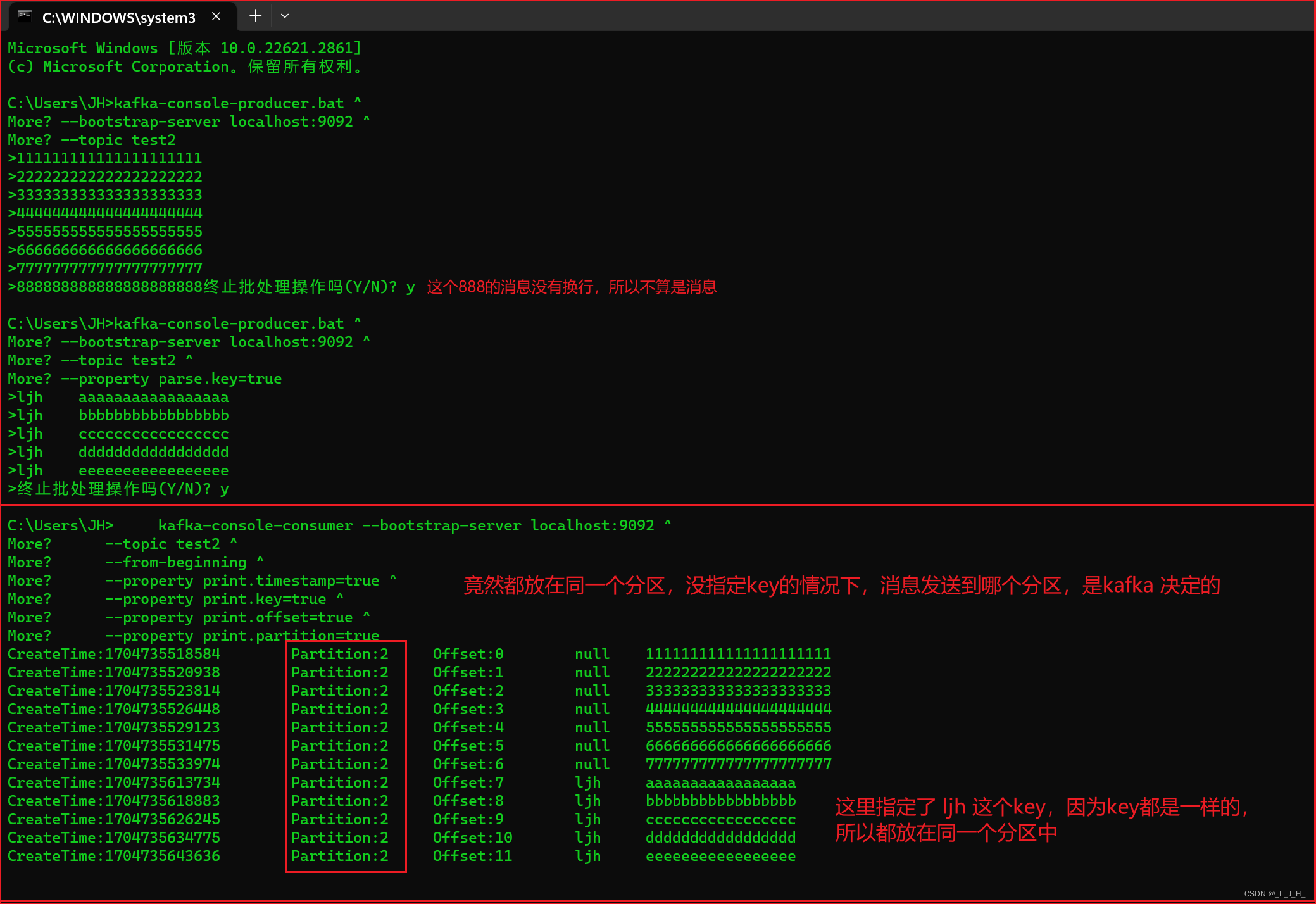
1、演示生产者发送消息,消息发送到主题 test2 那里
2、发送没有带 key 的消息,kafka 采用的是轮询的策略,把消息存放到不同的分区里面;如图,test2 主题有4个分区(属于领导者分区),那么这8条消息就会轮询的发送到这4个分区里面
3、发送带key的消息,如图,key 是 ljh,kafka就会计算 ljh 这个key的hashcode 值,然后存放都某一个分区里面,因为key都是一样的,所以这几个key为ljh的消息都会被发到同一个分区里面。
但是具体发送到哪个分区,是无法指定的。
4、发送带key的消息,如图,key 和 value 之间要间隔一个 Tab 键,不要弄成空格键。
命令在上面

我自己再添加不同key的消息,可以看出新添加的两条消息,是存放在0分区的。
Kafka — 消息消费者
★ 消息消费者命令
消费者用于从消息主题读取消息,Kafka提供了kafka-console-consumer.bat工具命令从指定主题、甚至指定分区读取消息。
该工具支持如下常用选项:
--bootstrap-server:指定要连接的Kafka主机和端口。
--from-beginning:指定从开始读取消息。
--group:指定组ID。
--offset <String: consume offset>:指定从特定下标开始读取消息,
比如将该选项设为1,表明从第2条消息开始读取;
该选项还支持earliest和latest两个字符串值,
其中earliest表示从最开始处读取(类似于--from-beginning选项的作用),
latest表示从最新处开始读取、即不读取之前的消息,latest是默认值。
--partition <Integer: partition>:指定哪个分区。
--property:用于指定一些额外属性,
比如 print.timestamp=true 指定要输出时间戳,
print.key=true表示输出消息key,
print.offset=true表示打印消息的下标,
print.partition=true表示打印分区信息。
--topic:指定哪个主题。
▲ 监听 【指定主题】 的所有消息:
这个监听命令,运行后是一直存在的,会一直监听,有新消息会马上监听出来的。
kafka-console-consumer --bootstrap-server localhost:9092 ^
--topic test2 ^
--from-beginning ^
--property print.timestamp=true ^
--property print.key=true ^
--property print.offset=true ^
--property print.partition=true
可以看到消息都成功存放在分区里面。
可以看到指定主题 test2 下的所有消息
但是目前还演示出轮询存放,先不理。
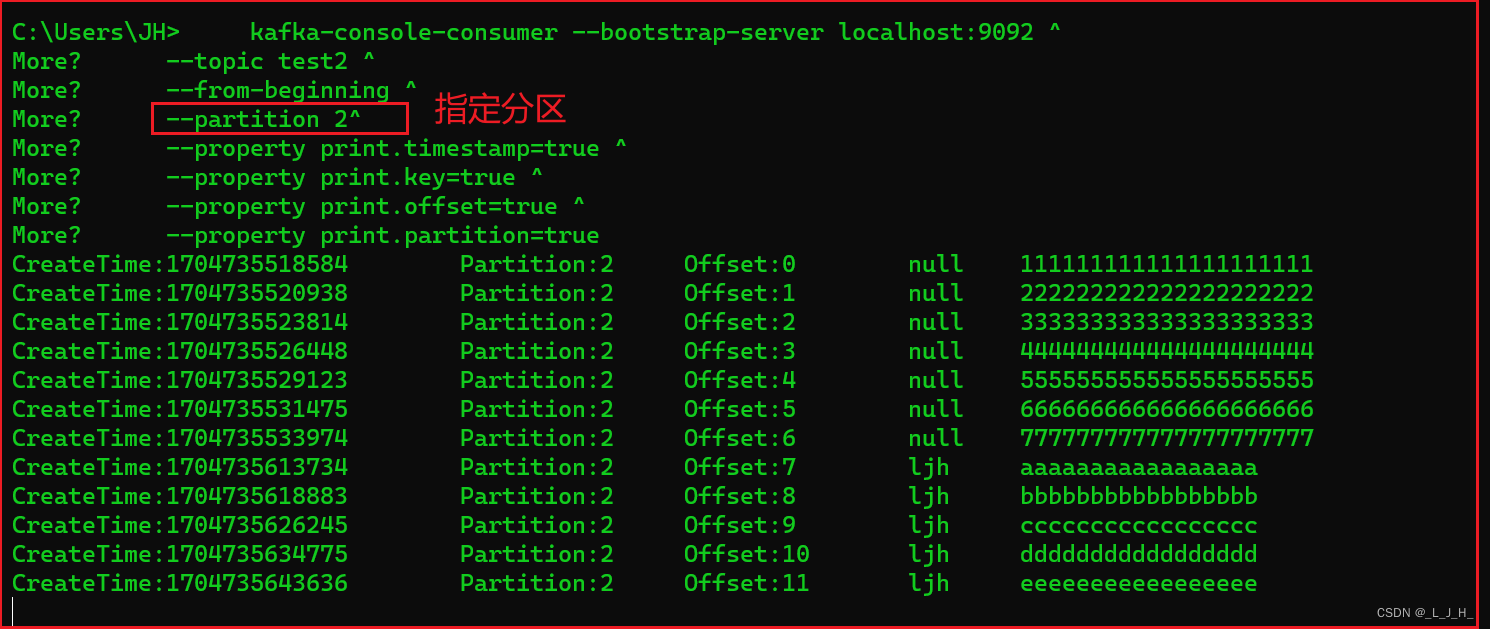
▲ 监听 【指定主题、指定分区】的所有消息:
看看分区2下的所有消息
kafka-console-consumer --bootstrap-server localhost:9092 ^
--topic test2 ^
--from-beginning ^
--partition 2^
--property print.timestamp=true ^
--property print.key=true ^
--property print.offset=true ^
--property print.partition=true
看看分区3下的所有消息
kafka-console-consumer --bootstrap-server localhost:9092 ^
--topic test2 ^
--from-beginning ^
--partition 3^
--property print.timestamp=true ^
--property print.key=true ^
--property print.offset=true ^
--property print.partition=true
分区3没有消息,所以没有任何显示:正确

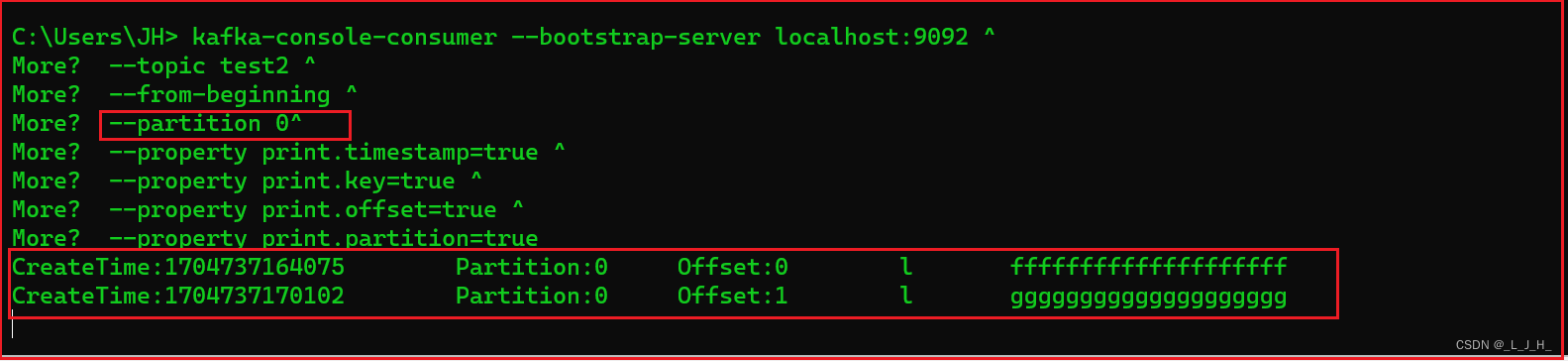
查看分区0的消息:
有两条,正确
注意点:
–from-beginning:指定从开始读取消息。
添加这个命令,就是一直都会读取到从一开始就添加的消息,这样演示不够真实,因为我们消息消费之后,正常情况下我们不需要再查出来,所以可以用offset这个命令:
–offset <String: consume offset>:指定从特定下标开始读取消息。
下面就来演示这个offset命令:
--offset <String: consume offset>:指定从特定下标开始读取消息,
比如将该选项设为1,表明从第2条消息开始读取;
该选项还支持earliest和latest两个字符串值,
其中
earliest表示从最开始处读取(类似于--from-beginning选项的作用),
latest表示从最新处开始读取、即不读取之前的消息,latest是默认值。
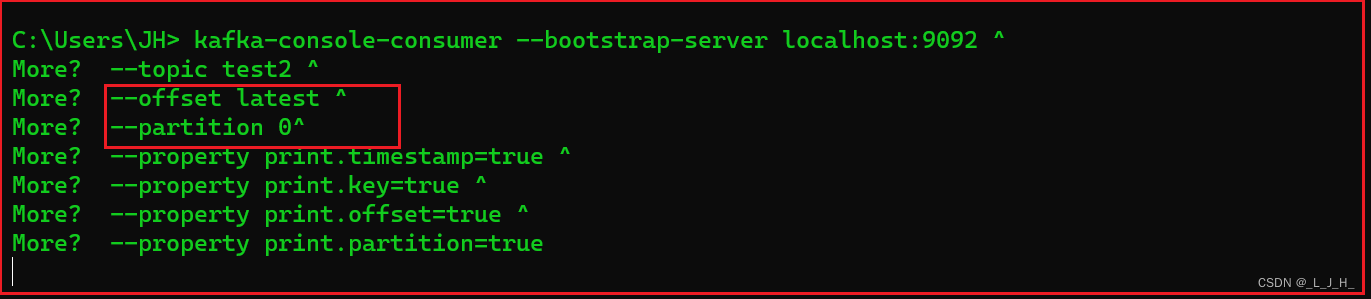
▲ 监听【指定主题、指定分区】的【新】消息:
(模拟传统的ActiveMQ、RabbitMQ的消息模型):
kafka-console-consumer --bootstrap-server localhost:9092 ^
--topic test2 ^
--offset latest ^
--partition 0^
--property print.timestamp=true ^
--property print.key=true ^
--property print.offset=true ^
--property print.partition=true
演示 latest 从最新处开始读取、即不读取之前的消息,latest是默认值。
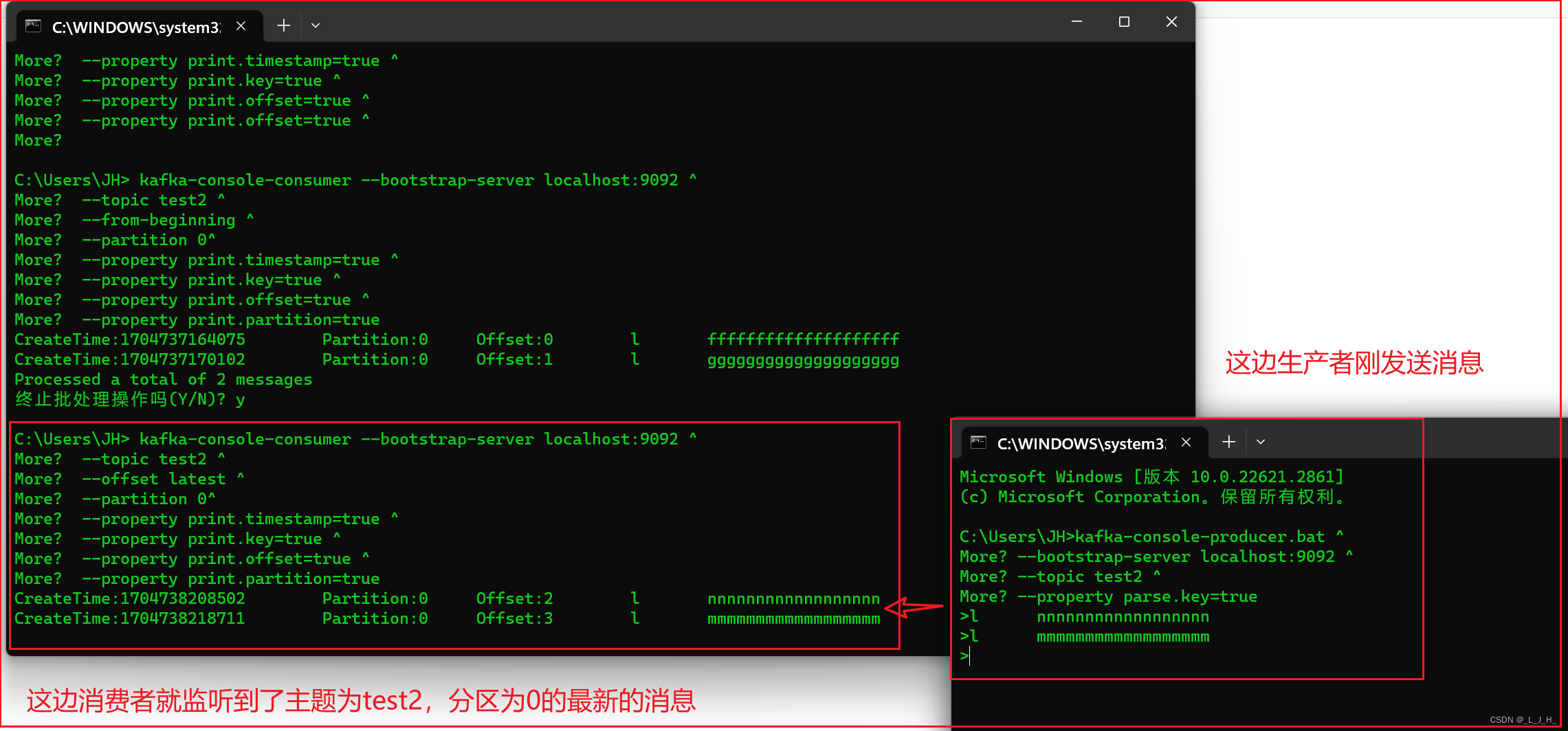
如图:现在从最新开始出监听消息,为了演示能监听最新消息,我们再打开一个命令行小黑窗,来往这个 0 分区发送消息。
因为上面key 为 l 的消息是发送到 0 分区,所以接下来发送的消息key也设置为l
如图:生产者刚发送消息,消费者这边马上就监听到主题为test2,分区为0 的最新的消息。
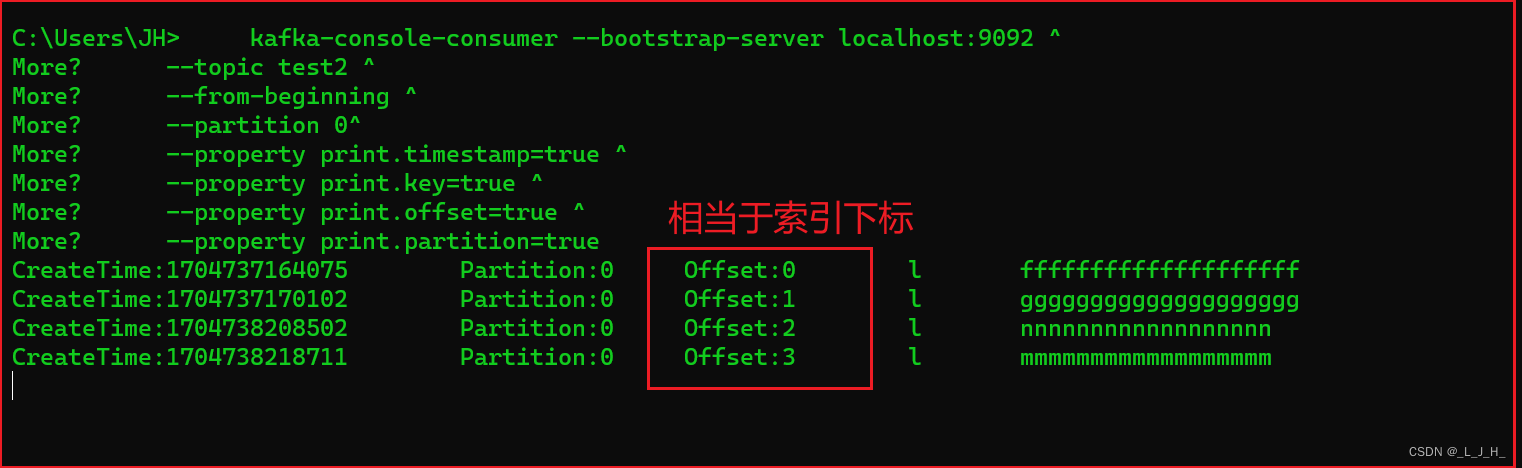
▲ 监听【指定主题、指定分区的、指定下标及之后】的所有消息:
这个 --offset 2 ^ 指定下标,查出来的消息是包括索引下标2 这条消息的。
先查出主题test2,分区0的所有消息,用来对比:
kafka-console-consumer --bootstrap-server localhost:9092 ^
--topic test2 ^
--from-beginning ^
--partition 0^
--property print.timestamp=true ^
--property print.key=true ^
--property print.offset=true ^
--property print.partition=true
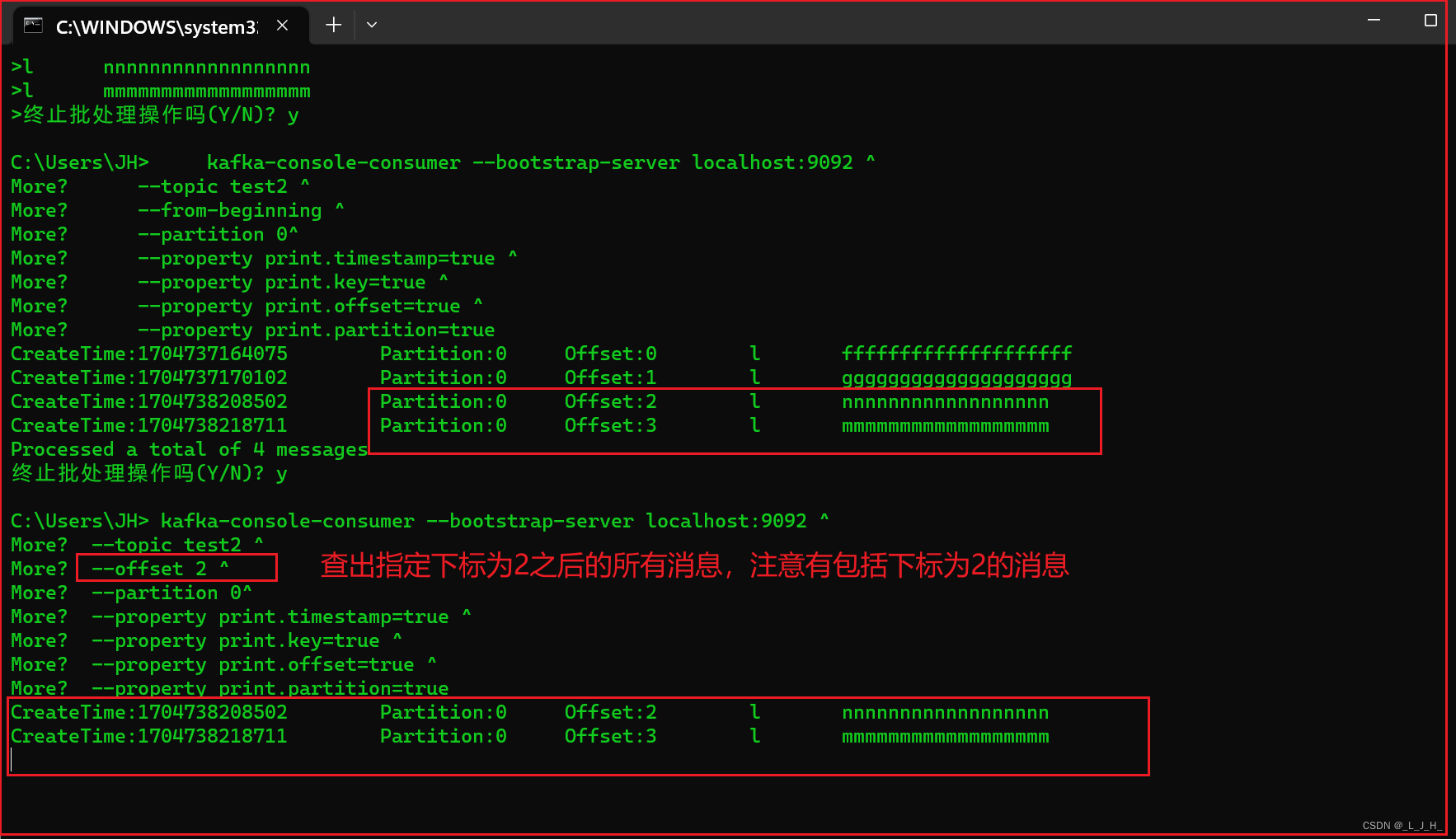
再查出 【主题test2,分区0,指定索引下标为2及之后】 的所有消息,用来对比:
kafka-console-consumer --bootstrap-server localhost:9092 ^
--topic test2 ^
--offset 2 ^
--partition 0^
--property print.timestamp=true ^
--property print.key=true ^
--property print.offset=true ^
--property print.partition=true
上面有4条消息,所以2及之后的消息,应该有2条,为索引2 nnnnnnnnnn,索引3 mmmmmmmm
kafka灵活之处:
灵活之处, --offset latest ^ 这个设置,默认就是latest ,就是从最新处开始读取、不读取之前的消息,始终读取最新的消息,以前用过的消息就不会管了。
因为 kafka 内部有一个偏移主题来存储每一个分区里面的消息及消息曾经被读取到哪一条(哪个位置)。
更灵活之处:
我们可以通过 --offset 加上指定的索引下标,非常灵活的读取我们想要读取的哪个位置的消息。
从上面的消息监听可以看出,消息是一直保存在分区当中的,意味着消息被消费之后,并没有立即从分区中被删除,还可以被重复的使用,这就是kafka非常灵活的地方。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Qt 5.15.2 (MSVC 2019)编译 QWT 6.2.0 : 编译MingW或MSVC遇到的坑
- 服务续约-向天再借五百年
- 【机器学习】调配师:咖啡的完美预测
- C语言之static关键字
- 【网络安全】上网行为代理服务器Network Agent配置
- 深度学习|4.1 深L层神经网络 4.2 深层网络的正向传播
- [Linux] Ubuntu install Miniconda
- UM2003A 一款200 ~ 960MHz ASK/OOK +18dBm 发射功率的单发射芯片
- 代码随想录算法训练DAY27|回溯3
- 使用nodejs定时备份mysql数据库与恢复