Python接口自动化-参数关联(超详细的)
发布时间:2024年01月06日
前言
我们用自动化发帖之后,要想接着对这篇帖子操作,那就需要用参数关联了,发帖之后会有一个帖子的id,获取到这个id,继续操作传这个帖子id就可以了
(博客园的登录机制已经变了,不能用账号和密码登录了,换个网站,或者用cookie登录吧)
一、删除草稿箱
1.我们前面讲过登录后保存草稿箱,那可以继续接着操作:删除刚才保存的草稿

2.用fiddler抓包,抓到删除帖子的请求,从抓包结果可以看出,传的json参数是postId
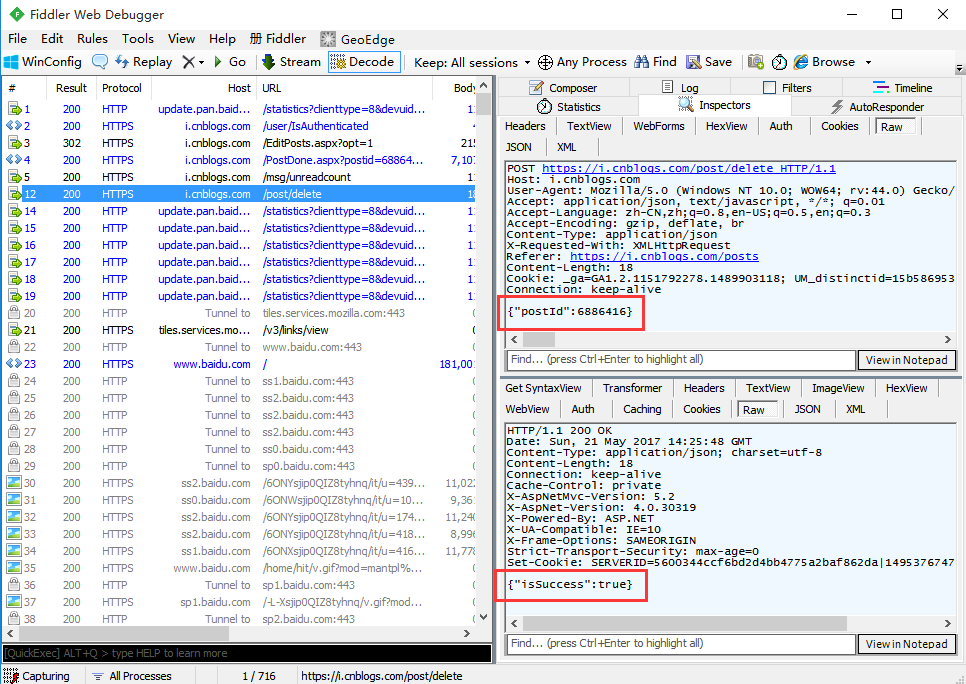
3.这个postId哪里来的呢?可以看上个请求url地址

4.也就是说保存草稿箱成功之后,重定向一个url地址,里面带有postId这个参数。那接下来我们提取出来就可以了
二、提取参数
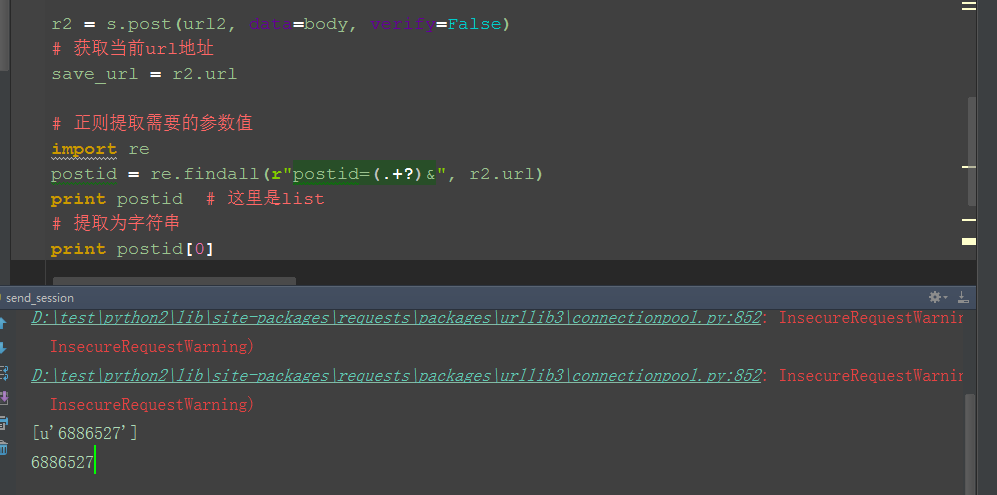
1.我们需要的参数postId是在保存成功后url地址,这时候从url地址提出对应的参数值就行了,先获取保存成功后url
2.通过正则提取需要的字符串,这个参数值前面(postid=)和后面(&)字符串都是固定的
3.这里正则提出来的是list类型,取第一个值就可以是字符串了(注意:每次保存需要修改内容,不能重复)
三、传参
1.删除草稿箱的json参数传上面取到的参数:{"postId": postid[0]}
2.json数据类型post里面填json就行,会自动转json
3.接着前面的保存草稿箱操作,就可以删除成功了

四、参考代码
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
print s.cookies
# 添加登录需要的两个cookie
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', '这里是抓到的') # 填上面抓包内容
c.set('.Cnblogs.AspNetCore.Cookies','这里是抓到的') # 填上面抓包内容
c.set('AlwaysCreateItemsAsActive',"True")
c.set('AdminCookieAlwaysExpandAdvanced',"True")
s.cookies.update(c)
print s.cookies
# -----------登录全部走cookie登录---
# 第二步:保存草稿
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是3111",
"Editor$Edit$EditorBody":"<p>这里111:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$Advanced$txbEntryName":"",
"Editor$Edit$Advanced$txbExcerpt":"",
"Editor$Edit$Advanced$tbEnryPassword":"",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
# 获取当前url地址
print r2.url
# 第三步:正则提取需要的参数值
import re
postid = re.findall(r"postid=(.+?)&", r2.url)
print postid # 这里是list
# 提取为字符串
print postid[0]
# 第四步:删除草稿箱
url3 = "https://i.cnblogs.com/post/delete"
json3 = {"postId": postid[0]}
r3 = s.post(url3, json=json3, verify=False)
print r3.json()同时,在这我为大家准备了一份软件测试视频教程(含面试、接口、自动化、性能测试等),就在下方,需要的可以直接去观看,也可以直接【点击文末小卡片免费领取资料文档】
软件测试视频教程观看处:
【2024最新版】Python自动化测试15天从入门到精通,10个项目实战,允许白嫖。。。
文章来源:https://blog.csdn.net/huace3740/article/details/135425921
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- habitat challenge rearrangement代码复现细节及踩坑实录
- 251.【2023年华为OD机试真题(C卷)】5G网络建设(最小生成树算法-Java&Python&C++&JS实现)
- Linux git命令
- ssm/php/node/python针对患者的寻医问药系统
- 关于 contentEditable 可编辑DIV 实现在光标处插入自定义图片【已解决,可直接使用】
- so-vits-svc的使用
- java读取json文件并解析并修改
- PostgreSQL数据库的json操作
- 6.4.3合并文件
- NeRF 其二:Mip-NeRF